






输入数据如下所示:
该数据来源于:https://rp5.ru/,取2017-2021的五年数据。
31.12.2021 23:00;5.6;770.3;773.8;;47;从东方吹来的风;4;;8;100%.; ;;;;10.2;;;;;;13.0;-4.8;无降水;6;;;;;
31.12.2021 20:00;6.8;771.1;774.5;;41;从东方吹来的风;2;;7;90 或者更多,但不为100%; ;;;-1.2;10.2;;;;;;8.0;-5.5;无降水;6;;;;;
26.01.2020 20:00;4.3;765.1;768.6;1.3;100;从北方吹来的风;2;;8;100%.;间歇性雨,不冻,在观测时较弱 ;雨;雨;4.3;6.3;;;300-600;;;9.0;4.3;16.0;12;;;;;
26.01.2020 17:00;5.3;763.8;767.2;;100;从东北偏北方向吹来的风;3;;8;100%.;间歇性雨,不冻,在观测时中度 ;雨;雨;4.5;6.3;;;300-600;;;7.0;5.3;9.0;6;;;;;
31.12.2019 23:00;0.1;774.3;777.8;;72;从东方吹来的风;1;;6;无云; ;;;-3.1;5.1;;;;;;13.0;-4.5;无降水;6;;;;;
31.12.2019 20:00;0.6;774.1;777.6;-0.7;68;从东北偏东方向吹来的风;2;;6;无云;云量发展情况没有进行观测或无法观测。
31.12.2018 17:00;3.2;778.5;779.9;3.1;65;从北方吹来的风;1;;;100%.; ;;;;;;100%.;1000-1500;;;18.0;-2.9;;;;;;;
31.12.2018 14:00;3.7;775.4;778.9;-4.1;65;从东北方吹来的风;1;;;40%.; ;;;-4.6;;;40%.;600-1000;;;15.0;-2.3;;;;;;;
12.01.2017 23:00;4.5;765.5;766.9;2.5;87;从西方吹来的风;1;;;由于雾和/或其他气象现象,天空不可见。; ;;;;;;;;;;2.3;2.5;;;;;;;
12.01.2017 20:00;5.5;763.0;766.4;-1.8;81;从西南偏西方向吹来的风;1;;;无云;薄雾
** 输出结果(只给出了三年的结果)**
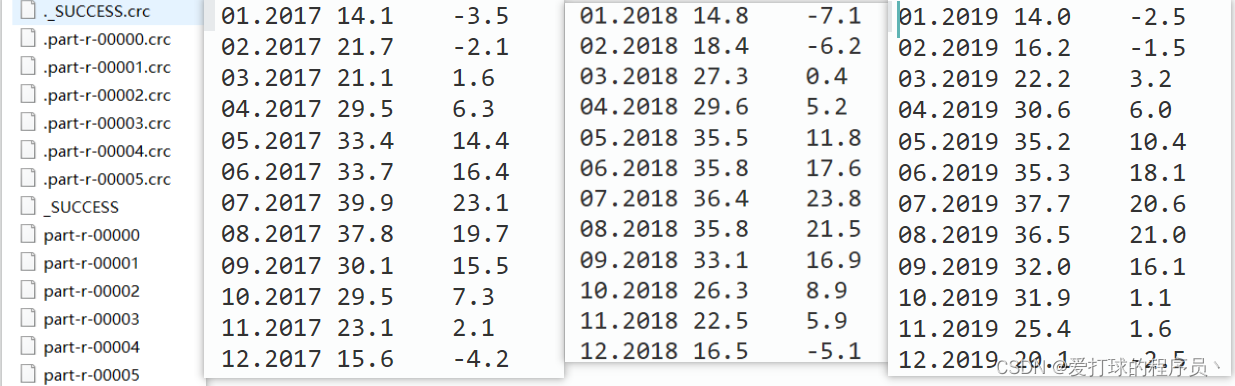
思路:
1、定义一个Bean对象,其中包括最高温度和最低温度。
2、map阶段的输出key为年月的时间,value为该年月的最高温度和最低温度(自定义的bean对象)。
3、定义一个分区,不同年份的数据进入到不同的分区。
4、reduce阶段定义两个变量最高温0度和最低温1000度,遍历相同的key(相同年相同月)的数据得到最高温和最低温后封装到bean对象,输出key为当前Text对象key,value为封装的bean对象(最高温和最低温)。
5、driver阶段的话设置至少五个以上ReduceTask,因为有五年数据,所以至少五个分区。
job.setNumReduceTasks(6);
Bean对象
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class MaxAndMinTempBean implements Writable {
private double MaxTemperature; //最高温度
private double MinTemperature; //最低温度
public MaxAndMinTempBean(){}
public double getMaxTemperature() {
return MaxTemperature;
}
public void setMaxTemperature(double maxTemperature) {
MaxTemperature = maxTemperature;
}
public double getMinTemperature() {
return MinTemperature;
}
public void setMinTemperature(double minTemperature) {
MinTemperature = minTemperature;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeDouble(MaxTemperature);
dataOutput.writeDouble(MinTemperature);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.MaxTemperature = dataInput.readDouble();
this.MinTemperature = dataInput.readDouble();
}
@Override
public String toString() {
return ""+MaxTemperature + '\t' + MinTemperature+"" ;
}
}
Map阶段
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MaxAndMinTempMapper extends Mapper<LongWritable, Text,Text, DoubleWritable> {
Text outK = new Text();
DoubleWritable outV = new DoubleWritable();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 数据切割
String[] words = line.split(";");
// 3 过滤温度为空的数据
boolean result = filterData(words);
//4. 数据为空则跳出
if (!result){
return;
}
// 4. 获取天气日期 和 温度
String word = words[0];
String date = word.substring(3, 10);
double temperature = Double.parseDouble(words[1]);
// 5. 输出
outK.set(date);
outV.set(temperature);
context.write(outK, outV);
}
//过滤温度为空的数据
private boolean filterData(String[] words) {
return !"".equals(words[1]);
}
}
Partition分区
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class MaxAndMinTempPartition extends Partitioner<Text, DoubleWritable> {
@Override
public int getPartition(Text text, DoubleWritable doubleWritable, int i) {
// 获取年份 12.2021
String yearnum = text.toString();
String year = yearnum.substring(3,7);
//定义一个分区号变量partition,根据prePhone设置分区号
int partition;
switch (year) {
case "2017":
partition = 0;
break;
case "2018":
partition = 1;
break;
case "2019":
partition = 2;
break;
case "2020":
partition = 3;
break;
case "2021":
partition = 4;
break;
default:
partition = 5;
break;
}
//最后返回分区号partition
return partition;
}
}
Reduce阶段
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MaxAndMinTempReducer extends Reducer<Text, DoubleWritable, Text, MaxAndMinTempBean> {
MaxAndMinTempBean outV = new MaxAndMinTempBean();
@Override
protected void reduce(Text key, Iterable<DoubleWritable> values, Context context) throws IOException, InterruptedException {
double maxvalue=-1;
double minvalue=999;
for (DoubleWritable value : values) {
if (maxvalue<value.get()){
maxvalue = value.get();
}
if (minvalue>value.get()){
minvalue = value.get();
}
// 封装Bean对象
outV.setMaxTemperature(maxvalue);
outV.setMinTemperature(minvalue);
}
// 输出
context.write(key, outV);
}
}
Driver阶段
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class MaxAndMinTempDriver {
public static void main(String[] args) throws InterruptedException, IOException, ClassNotFoundException {
// 1 获取job信息
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 加载jar包
job.setJarByClass(MaxAndMinTempMapper.class);
// 3 关联map和reduce
job.setMapperClass(MaxAndMinTempMapper.class);
job.setReducerClass(MaxAndMinTempReducer.class);
// 4 设置Mapper输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DoubleWritable.class);
// 5 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(MaxAndMinTempBean.class);
//6 指定自定义分区器
job.setPartitionerClass(MaxAndMinTempPartition.class);
//7 同时指定相应数量的ReduceTask
job.setNumReduceTasks(6);
// 8 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path("datas/17-21TQdatas.csv"));
// FileInputFormat.setInputPaths(job, new Path("datas/datas.csv"));
FileOutputFormat.setOutputPath(job, new Path("output/outputemperature"));
// FileInputFormat.setInputPaths(job,new Path("hdfs://192.168.22.102:8020/graduation-design/origin-datas/StockPaQu.csv"));
// FileOutputFormat.setOutputPath(job,new Path("hdfs://192.168.22.102:8020/graduation-design/output/market"));
// 9 提交
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









