







目录
operator 部署是基于已经编写好的 yaml 文件,可以将 prometheus server、altermanager、grafana、node-exporter 等组件一键批量部署。
此次是部署在 k8s-v1.25.4 环境。
一、环境准备
1.1 选择版本
kube-prometheus 官方地址:https://github.com/prometheus-operator/kube-prometheus
选择与 k8s 对应的版本:

1.2 过滤镜像
#1. 克隆项目到本地
[root@k8s-master1 ~]# git clone -b release-0.12 https://github.com/prometheus-operator/kube-prometheus.git
#2. 过滤需要的镜像
[root@k8s-master1 ~]# cd kube-prometheus/manifests
[root@k8s-master1 ~/kube-prometheus/manifests]# grep image: ./* -R
1.3 修改 yaml 镜像
有两个镜像地址为 registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.7.0、registry.k8s.io/prometheus-adapter/prometheus-adapter:v0.10.0 是下载不到的,我们得修改下对应的 yaml 文件:
[root@k8s-master1 ~/kube-prometheus/manifests]# vim kubeStateMetrics-deployment.yaml
image: bitnami/kube-state-metrics:2.7.0
name: kube-state-metrics
[root@k8s-master1 ~/kube-prometheus/manifests]# vim prometheusAdapter-deployment.yaml
image: registry.cn-hangzhou.aliyuncs.com/ialso/prometheus-adapter:v0.10.0
livenessProbe:
failureThreshold: 51.4 移动 *networkPolicy*.yaml
[root@k8s-master1 ~/kube-prometheus/manifests]# mkdir networkPolicy.bak
[root@k8s-master1 ~/kube-prometheus/manifests]# mv *networkPolicy*.yaml networkPolicy.bak/1.5 修改 service 文件
#1. 暴露 grafana 的 NodePort 端口
[root@k8s-master1 ~/kube-prometheus/manifests]# vim grafana-service.yaml
spec:
type: NodePort
ports:
- name: http
port: 3000
targetPort: http
nodePort: 30300
#2. 暴露 prometheus 的 NodePort 端口
[root@k8s-master1 ~/kube-prometheus/manifests]# vim prometheus-service.yaml
spec:
type: NodePort
ports:
- name: web
port: 9090
targetPort: web
nodePort: 30900
- name: reloader-web
port: 8080
targetPort: reloader-web
nodePort: 308001.6 提前下载镜像并推送到私有镜像仓库
PS:也可以直接使用我已经上传到阿里云的镜像!
# 使用脚本执行下载镜像并推送
[root@k8s-master1 ~/kube-prometheus]# vim images.sh
#!/bin/bash
# 定义目录变量
MANIFESTS_DIR="/root/kube-prometheus/manifests"
ALIYUN_REPO="registry.cn-hangzhou.aliyuncs.com/kube-prometheus_v012/kube-prometheus_v012"
# 登录阿里云容器镜像仓库
echo -e "\033[36m开始登录阿里云容器镜像仓库...\033[0m"
if ! sudo docker login --username=zfhxxx registry.cn-hangzhou.aliyuncs.com --password-stdin <<< "xxx."; then
echo -e "\033[31m登录失败,请检查密码的正确性。\033[0m"
exit 1
fi
# 过滤并提取镜像名称
echo -e "\033[36m正在提取镜像列表...\033[0m"
images=$(grep -ohr "image: \S*" $MANIFESTS_DIR | awk '{print $2}' | sort | uniq)
# 成功下载的镜像列表
successful_images=()
# 检查并下载镜像
for image in $images; do
if [ ! -z "$image" ]; then
echo -e "\033[36m正在下载镜像: $image\033[0m"
if docker pull $image; then
echo -e "\033[32m成功下载镜像: $image\033[0m"
successful_images+=($image)
else
echo -e "\033[31m镜像下载失败: $image\033[0m"
continue
fi
fi
done
# 处理成功下载的镜像
for image in "${successful_images[@]}"; do
# 修改镜像格式,将 ":" 替换为 "-"
image_name_with_version=$(echo $image | sed 's|.*/||;s|:|-|')
new_image="$ALIYUN_REPO:$image_name_with_version"
docker tag $image $new_image
echo -e "\033[36m正在推送镜像: $new_image\033[0m"
if ! docker push $new_image; then
echo -e "\033[31m镜像推送失败: $new_image\033[0m"
exit 1
fi
done
# 替换 yaml 文件中的镜像名称
echo -e "\033[36m正在更新 yaml 文件中的镜像名称...\033[0m"
for image in "${successful_images[@]}"; do
# 修改原镜像名称格式,将 ":" 替换为 "-"
image_name=$(echo $image | sed 's|.*/||')
version=$(echo $image_name | sed 's|.*:||;s|:|-|')
name=$(echo $image_name | sed "s|:$version||")
new_image_format="$ALIYUN_REPO:$name-$version"
find $MANIFESTS_DIR -type f -name '*.yaml' -exec sed -i "s|$image|$new_image_format|g" {} +
done
echo -e "\033[32m处理完成。\033[0m"
[root@k8s-master1 ~/kube-prometheus]# chmod +x images.sh
[root@k8s-master1 ~/kube-prometheus]# sh images.sh 1.7 修改镜像(可选)
如果是在内网环境下,则需要执行此步骤!
如果是在内网环境,会发现 alertmanager 和 prometheus 起不来,查看详细信息会发现还需要额外拉取一个镜像:quay.io/prometheus-operator/prometheus-config-reloader:v0.62.0
[root@idc-master-01 ~]# kubectl get pods -n monitoring
[root@idc-master-01 ~]# kubectl get statefulsets.apps -n monitoring
NAME READY AGE
alertmanager-main 0/3 16h
prometheus-k8s 0/2 16h
[root@idc-master-01 ~]# kubectl describe pods -n monitoring alertmanager-main-0
[root@idc-master-01 ~]# kubectl describe pods -n monitoring prometheus-k8s-0 
#1. 下载镜像并推送至私有 Harbor 仓库
[root@idc-master-01 ~]# docker pull quay.io/prometheus-operator/prometheus-config-reloader:v0.62.0
[root@idc-master-01 ~]# docker images |grep prometheus-config
quay.io/prometheus-operator/prometheus-config-reloader v0.62.0 e31159f5e80c 15 months ago 12.5MB
[root@idc-master-01 ~]# docker tag e31159f5e80c 10.0.x.xxx/google_containers/prometheus-config-reloader:v0.62.0
[root@idc-master-01 ~]# docker push 10.0.x.xxx/google_containers/prometheus-config-reloader:v0.62.0
#2. 查找这个镜像实在哪个文件里
[root@idc-master-01 ~]# grep -Rl "quay.io/prometheus-operator/prometheus-config-reloader:v0.62.0" /root/kube-prometheus/manifests
/root/kube-prometheus/manifests/prometheusOperator-deployment.yaml
#3. 修改镜像名称
[root@idc-master-01 ~]# vim /root/kube-prometheus/manifests/prometheusOperator-deployment.yaml
containers:
- args:
- --kubelet-service=kube-system/kubelet
- --prometheus-config-reloader=10.0.x.xxx/google_containers/prometheus-config-reloader:v0.62.0
image: 10.0.4.145/google_containers/prometheus-operator:v0.62.0
name: prometheus-operator二、执行创建
注意:每个 kube-prometheus 版本的执行部署命令可能有差异,具体看官方 github!
#1. 先创建资源
[root@k8s-master1 ~/kube-prometheus]# kubectl apply --server-side -f manifests/setup
#2. 创建服务
[root@k8s-master1 ~/kube-prometheus]# kubectl apply -f manifests/
# 卸载
# kubectl delete --ignore-not-found=true -f manifests/ -f manifests/setup三、查看 pod 状态
[root@k8s-master1 ~/kube-prometheus]# kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 1 (2m43s ago) 2m56s
alertmanager-main-1 2/2 Running 1 (2m19s ago) 2m56s
alertmanager-main-2 2/2 Running 1 (2m43s ago) 2m56s
blackbox-exporter-5d65c768db-79m2p 3/3 Running 0 3m48s
grafana-8444df4945-mqqr5 1/1 Running 0 3m47s
kube-state-metrics-565d4b86d6-frmj2 3/3 Running 0 3m47s
node-exporter-8qb4p 2/2 Running 0 3m46s
node-exporter-pb5wq 2/2 Running 0 3m46s
node-exporter-w6bqp 2/2 Running 0 3m46s
prometheus-adapter-74648d74c7-f2ffp 1/1 Running 0 3m45s
prometheus-adapter-74648d74c7-n8k5j 1/1 Running 0 3m45s
prometheus-k8s-0 2/2 Running 0 2m54s
prometheus-k8s-1 2/2 Running 0 2m54s
prometheus-operator-69f4bff8-ppbv9 2/2 Running 0 3m45s
[root@k8s-master1 ~/kube-prometheus]# kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main ClusterIP 10.99.205.58 <none> 9093/TCP,8080/TCP 4m14s
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 3m21s
blackbox-exporter ClusterIP 10.110.84.60 <none> 9115/TCP,19115/TCP 4m14s
grafana NodePort 10.107.147.245 <none> 3000:30300/TCP 112s
kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 4m12s
node-exporter ClusterIP None <none> 9100/TCP 4m11s
prometheus-adapter ClusterIP 10.109.105.103 <none> 443/TCP 4m11s
prometheus-k8s NodePort 10.99.213.212 <none> 9090:30900/TCP,8080:30800/TCP 37s
prometheus-operated ClusterIP None <none> 9090/TCP 3m19s
prometheus-operator ClusterIP None <none> 8443/TCP 4m10s四、访问 prometheus、grafana 页面
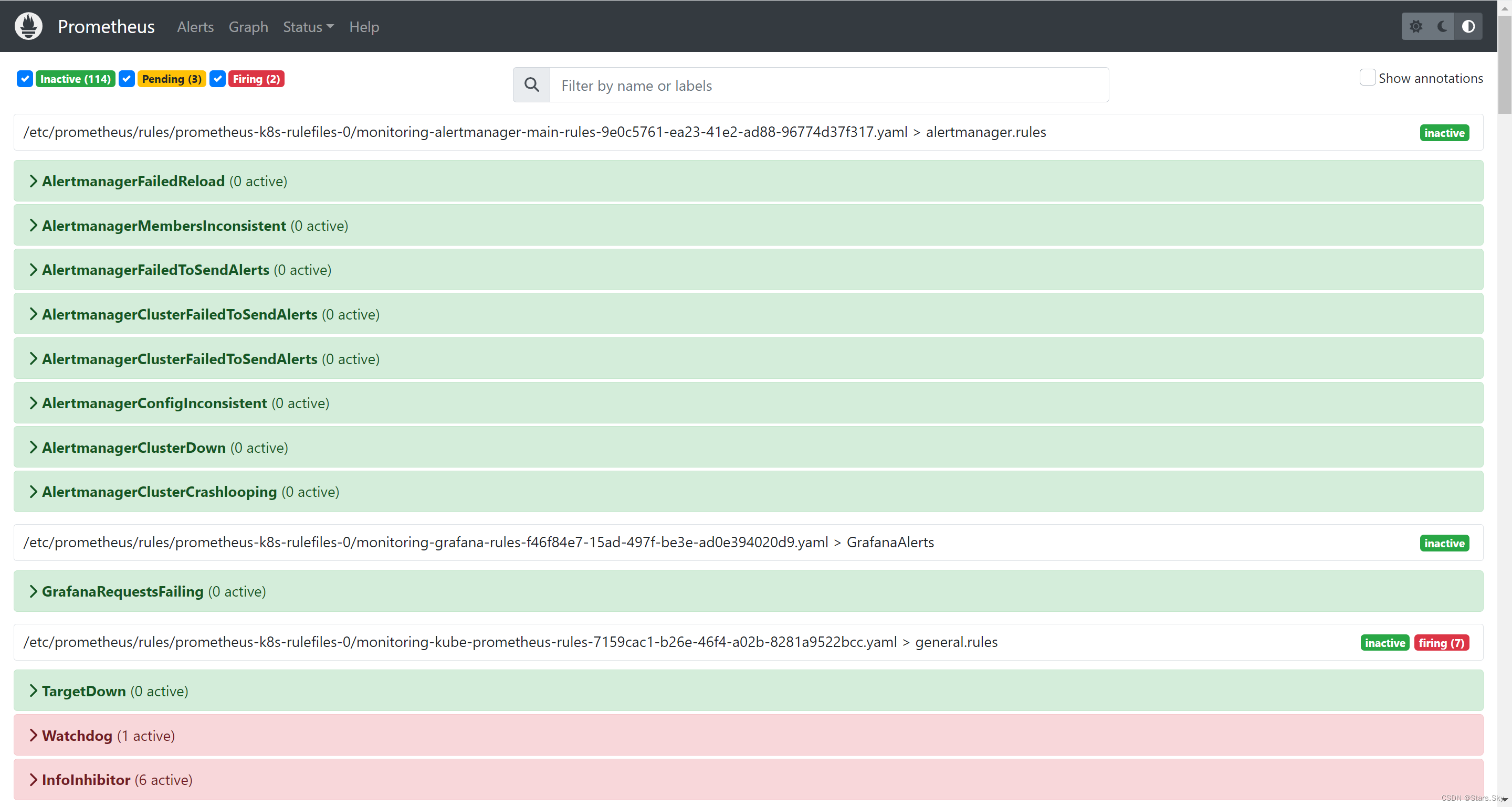
4.1 访问 prometheus
访问连接:http://192.168.170.141:30900/
4.2 访问 grafana
访问连接:http://192.168.170.141:30300/
账号:admin
密码:admin
里面已经定义好大量的模板:

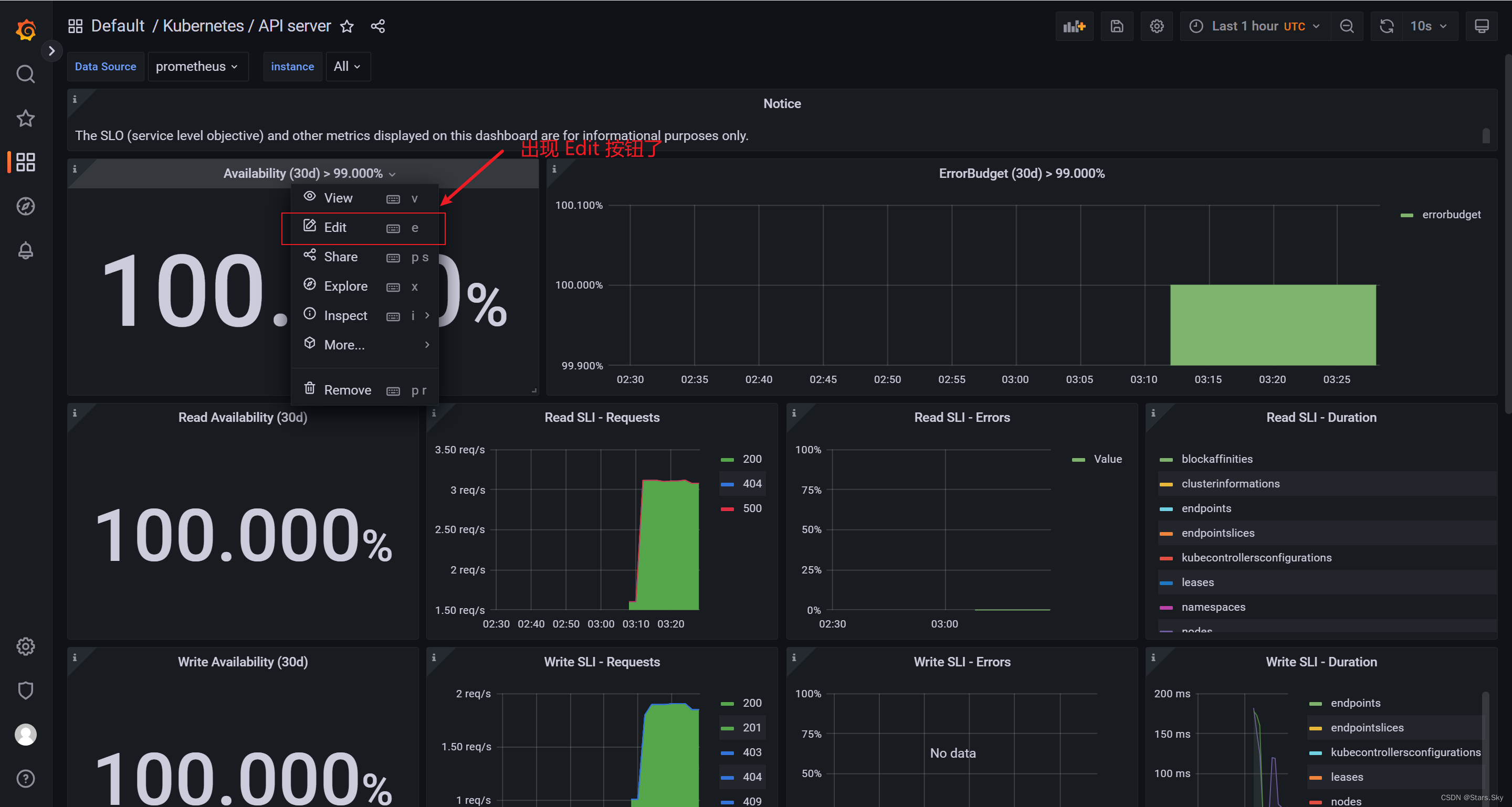
4.2.1 获取可编辑权限
里面有些模版是没有 Edit 编辑按钮的:

解决办法:
点击右上角的设置:
 点击 Make editable:
点击 Make editable:

回到模板页面,重新点击模块,出现 Edit 按钮:
上一篇文章:【云原生 | Kubernetes 实战】01、K8s-v1.25集群搭建和部署基于网页的 K8s 用户界面 Dashboard_kubeadm1.25需要最低配置是啥-CSDN博客
















 757
757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











