







论文全称:Asynchronous Spatio-Temporal Memory Network for Continuous Event-Based Object Detection
有一个想法:时间相机拍摄的是光照强度的变化,拍出来的结果用正负极性区分,那能不能在变化中增加区间,类似于正向变化0-50,50-100分别用不同颜色表现,即二进制极性变成四进制,以此来表现事件发生的突变程度?0-(-50),-50-(-100)负向变化也同理。
Adaptive emporal sampling (ATS),
Temporal attention convolutional network (TACN),
temporal convolutional network (TCN)
Spatio-Temporal memory modules.
简介
本文提出一种新颖的异步时空记忆网络(ASTMNet),它在处理之前直接消耗异步事件,可以很好地以连续方式检测对象。ASTMNet 通过采用自适应时间采样策略和时间注意力卷积模块,从连续事件流中学习异步注意力嵌入(即提出了一种异步注意力嵌入,它通过自适应时间采样策略和时间注意力卷积模块保留来自连续事件流的时空信息)。此外,时空记忆模块旨在通过轻量级但高效的交织循环卷积架构来利用丰富的时间线索。实验表明该方法在三个数据集上远远优于使用基于前馈帧的检测器的最先进方法(即 KITTI 模拟数据集中的 7.6%,Gen1 汽车数据集中的 10.8%, 1Mpx 检测数据集中为 10.5%)。
1.理论基础
辅助理解:人类可以从时间维度中找到一个与当前对象高度相似的不同对象,然后将它们分配在一起。利用跨多个相邻帧的时间线索,本文方法直接消耗异步事件并通过轻量级但高效的交织来利用丰富的时间线索循环卷积架构。
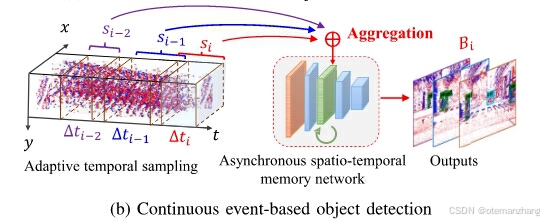
1.1事件表示
连续事件流S首先被分为有效的时间仓S={S1,S2,…Sn}作为基本处理单元。一个时间仓内核函数将点集转换为连续的测量值,即通过数学方法在空间和时间上对点集进行平滑或插值,生成一个定义在连续域上的函数F (x, y, t)。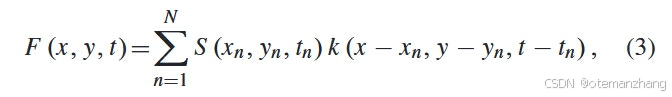
其中S (x, y, t)是一个时间仓(Temporal Bin),S映射到F,F中保留了S中的时空信息。其中k(x,y,t)是核函数,它可以采用手工函数或神经网络架构。
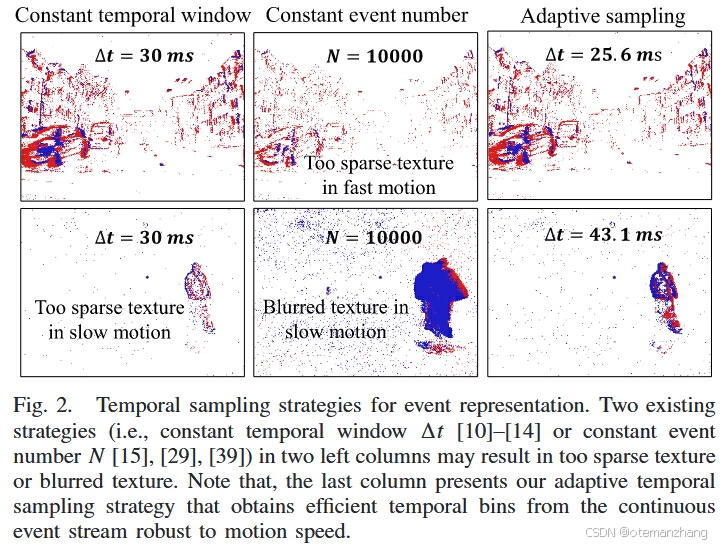
现有的检测器直接将异步事件映射到具有恒定时间窗口t或恒定事件数N的类似图像的2D表示。显然,这些方法在时间采样和事件表示方面有两个弱点。前一种是指时间采样策略在 t 或 N 的前缀值下工作,其中每个时间仓的纹理在快运动中可能太稀疏,或者在慢运动中太密集(见图 2)。后一种方法是在输入检测器之前将异步事件集成或投影到类似图像的二维表示中,这意味着这些简单的转换很难充分利用原始事件流中的时空属性。
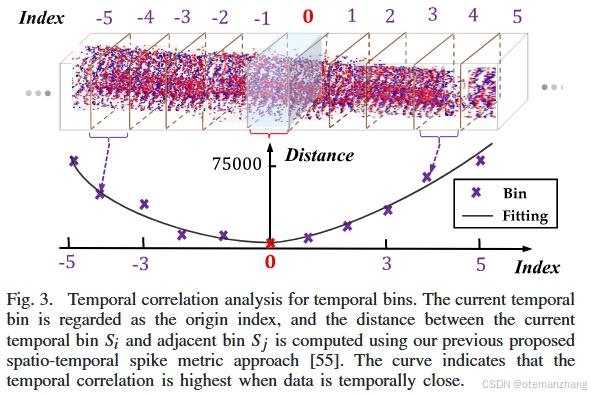
1.2事件流时间相关性
一种时空尖峰度量方法来定量评估时间区间{S1,S2,... }之间的距离,两个时间区间 Si 和 S j 之间的距离 || ||Si − S j || || 可以通过在再生核希尔伯特空间中引入内积 ε (Si , S j ) 来计算:

用上述方法来测量图 3 中时间仓之间的距离,该曲线清楚地表明距离随着远离当前时间仓的索引而增加。换句话说,当数据在时间上接近时,时间相关性最高。实际上,检测器可以从时间维度中找到与当前对象具有高度相似性的不同对象,并将它们分配在一起。尚未利用丰富的时间线索。
本文提出如下定义2:让异步事件流被分成一组有效的时间容器S = {S1,S2…Sn},对应的物体信息B = {B1,B2…Bn} 可以通过下式计算: Bi = D (Si−k . . . Si ) ,其中每个 Bi ={(xi, j , yi, j , wi, j , hi, j , li, j , ti, j )} j ∈[1,M] 是对应于时间仓 Si 的 M 个边界框位置和类预测的列表,其中 [xi, j , yi, j ]是第 j 个边界框左上角的空间坐标,[wi, j , hi, j ] 是其宽度和高度,li, j 和 ti, j 分别是对象类和时间戳。函数 D 指的是基于事件的检测器,并且 Sk i = {Si−k , . 。 。 , Si } 是最多数量为 k + 1 的多个时间仓的子集。
2.论文方法
2.1ASTMNet网络结构
最开始,使用自适应时间采样 策略将连续事件流分割成有效的时间仓作为基本处理单元。然后,TACN 模块执行一维因果卷积来处理每个像素的每个序列,并将整个像素合并成类似图像的表示(即注意力嵌入)。最后,时空记忆模块旨在通过轻量级交织循环卷积架构(即 Rec-Conv)来利用丰富的时间线索,,该架构通过融合相邻的时间区间 = {
…
} 来生成边界框
。
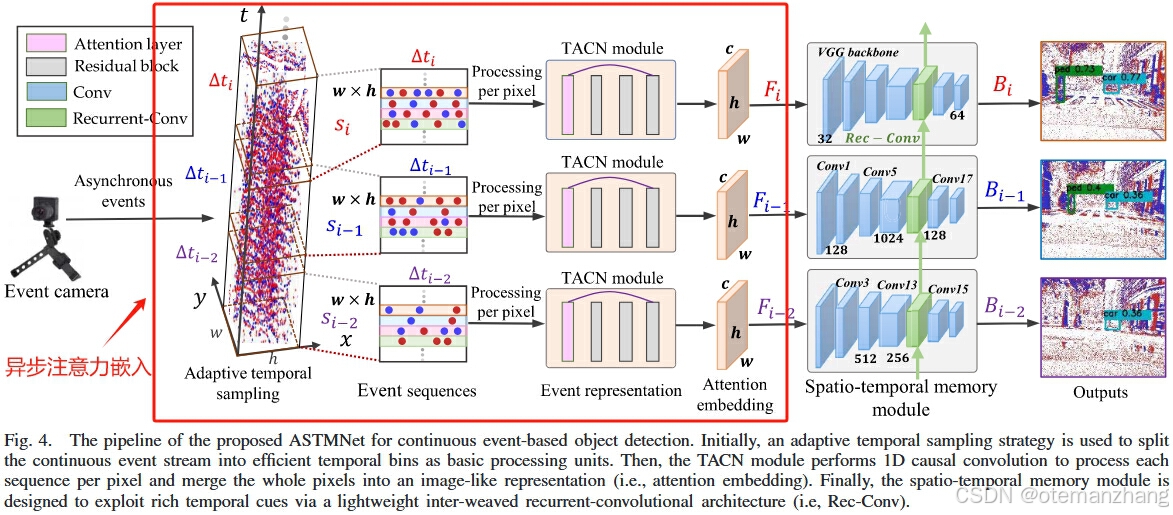
2.2异步注意力嵌入
2.2.1自适应采样
从每个标签的时间戳反向计数事件数 Ni ,一旦 Ni 接近自适应阈值而不是 t 或 N 的前缀值,就会触发一个新的时间 bin,如公式6。
![]()
其中Δti 是生成时间 bin 的持续时间,单位为微秒 (μs)。 # { }为时空窗口i内的计数,θ为预设阈值,η为保持时间一致性而作为调整{t1,t2…tn}的时间反馈控制参数。对于其初始化,我们将 η 设置为 0,一旦事件编号 N0 达到 θ,它就会触发第一个 bin。这些时间仓允许不连续或彼此重叠。
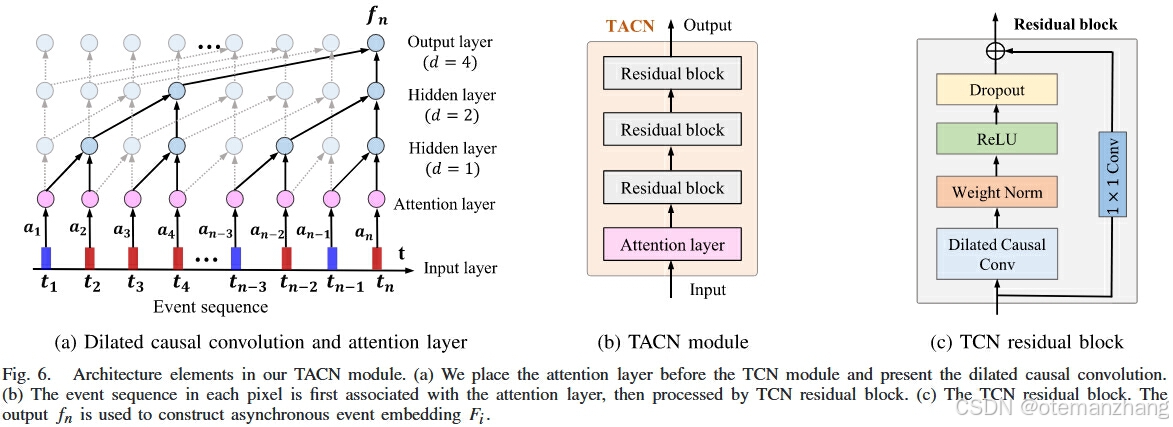
2.2.2时间注意力卷积(TACN)
TACN直接以时间仓 Si 作为输入,输出宽为 w 的异步注意力嵌入 Fi ∈ ,高度h,通道数c。如图 6 所示, TACN 集成了两部分:使用注意力层通过关注全局信息,聚焦于重点时间的重点事件的特征,过滤掉稀疏或无关的噪声也就是增加注意力权重,并对通过时间卷积网络(TCN)的事件序列的时间依赖性进行建模。注意力层帮助模型 优化了输入特征的质量,从而使得后续的时间卷积层能够 更有效地捕捉动态事件的模式。
TCN中的因果卷积仅回顾一定的历史大小,因此我们使用r扩张卷积层来扩大感受野(见图6(a)),d是膨胀因子。为了促进深度 TCN 的训练,我们进一步在卷积单元之间添加残差连接(见图6(b)和图6(c))TCN 残差块由扩张随意卷积、权重归一化、ReLU 激活函数和 dropout 操作组成。输出 fn 用于构造异步事件嵌入 Fi 。
补充:
因果卷积确保每个时间步的输出仅依赖于当前时间步及其之前的时间步,而不是未来的时间步。这在时序数据处理任务中非常重要,因为模型不能访问未来的输入数据。
扩张卷积是指在卷积过程中,卷积核的元素之间引入一定的间隔, 扩展了卷积核的感受野。通过扩张,卷积可以在更大的时间跨度上进行特征提取,而不需要增加计算复杂度。
权重归一化 是一种 规范化技术,用于加速神经网络的训练过程并提高模型的稳定性。其工作原理是对网络的权重进行重新参数化,通常是通过将权重分解为 幅度部分和 方向部分。通过这种方式,训练过程中的 梯度更新 会更加稳定。
ReLU 激活函数:增加网络的非线性能力,解决梯度消失问题,提升表达能力。由于负值被“剪切”掉,ReLU 激活函数在正数域内产生稀疏的激活,有助于减少计算负担。
Dropout 是一种正则化技术,常用于 防止过拟合。在训练过程中,Dropout 会随机 丢弃 网络中的部分神经元(即将其输出设置为0),减少模型对特定神经元的依赖,从而提高网络的泛化能力。
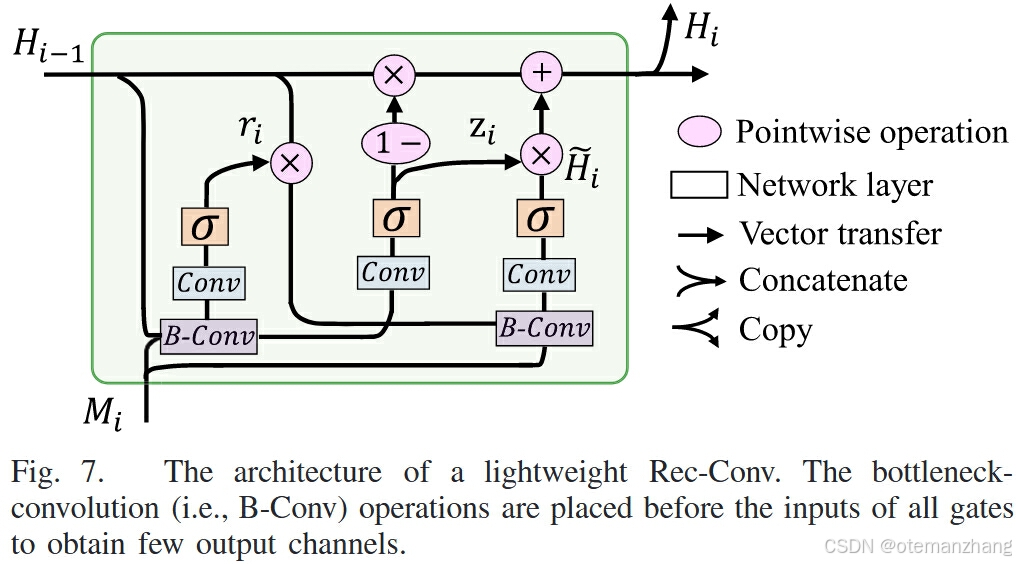
2.2.3时空记忆模块(Spatio-Temporal Memory Module)
尝试在第 m 个卷积层(计算量较低的特征图之后)之后放置一个轻量级的 Rec-Conv R,Rec-Conv R 将特征图 和先前时间仓的记忆状态
作为输入,然后输出当前状态
和时空特征图
,圆中一点表示逐元素乘法,激活函数 σ(·),用深度可分离卷积*来减少计算量。引入瓶颈卷积来获得很少的输出通道,本文时空存储模块在计算复杂度上优于标准的循环卷积结构的原因。
补充:
Pointwise Operation(逐点操作)逐点操作是 逐元素的操作,这意味着它对每个元素单独进行计算,而不涉及其他元素的交互。对于卷积层中的每个位置,逐点操作常常指的是 1x1卷积,这种卷积核大小为1x1,主要用于 调整特征图的深度,而不会影响空间维度(宽度和高度)。在深度学习中,1x1卷积被广泛用于 通道融合、维度压缩、特征重映射等。
Bottleneck Convolution(瓶颈卷积)瓶颈卷积是指在 卷积神经网络 中使用的某种卷积层结构,通常会采用 1x1卷积 来实现 维度压缩,减少通道数或特征图的深度,从而减少计算量和模型复杂度。瓶颈结构常用于提高网络的 效率 和 速度。在ResNet中的应用:瓶颈卷积通常指 通过1x1卷积 来 压缩通道数,然后再通过 3x3卷积 来提取特征,最后通过 1x1卷积 还原通道数。这种方式通过瓶颈层的设计,显著减少了卷积操作的 计算量 和 参数数量,提高了模型的 效率。
3.结果分析
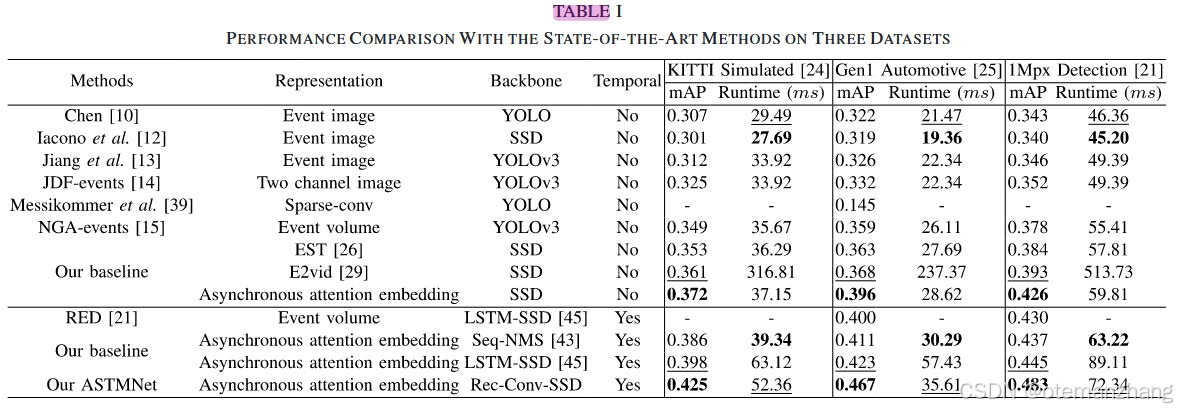
在三个数据集上的定量评估:如表1所示,黑体和下划线分别表示最佳和次最佳的性能。值得注意的是,ASTMNet获得了比现有的基于事件的目标检测器和五个基线更好的性能。例如,与NGA - Events 相比,ASTMNet在KITTI模拟数据集、Gen1汽车数据集和1Mpx检测数据集上分别提高了7.6 %、10.8 %和10.5 %。与大多数现有的前馈检测器 不同,ASTSMNet引入了一种交织的循环卷积结构,利用相邻时间片之间丰富的时间线索。ASTMNet可以在相对增加计算复杂度的同时显著地提高性能。同时,表1表明,ASTMNet优于RED 和两个基线(也就是说,两个视频对象检测器 , 使用异步注意力嵌入代替帧)。这是因为ASTMNet采用了轻量级的Rec - Conv架构,比后处理策略(即Seq - NMS )更高效,也更简单。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









