







爬虫的步骤:
(1)申请自己的公众号
(2)使用fiddler抓包工具
(3)pycharm
(一)申请公众号
官网:微信公众平台
填入相关信息创建微信公众号
进入公众号界面如下:
找到新的创作-图文信息
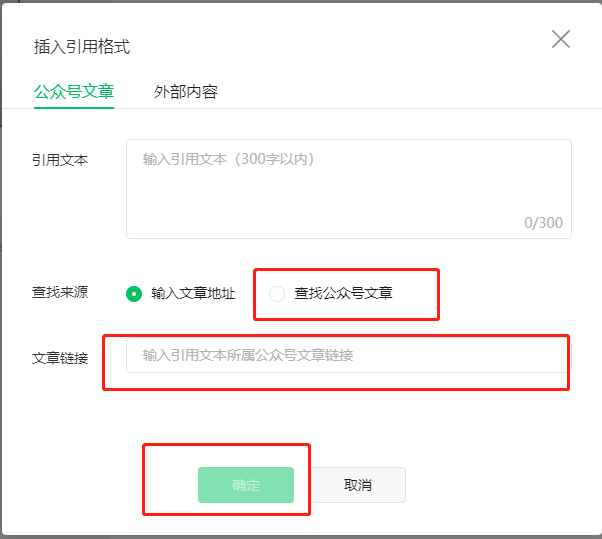
在弹出的界面中查找公众号文章-输入公众号名称-确定
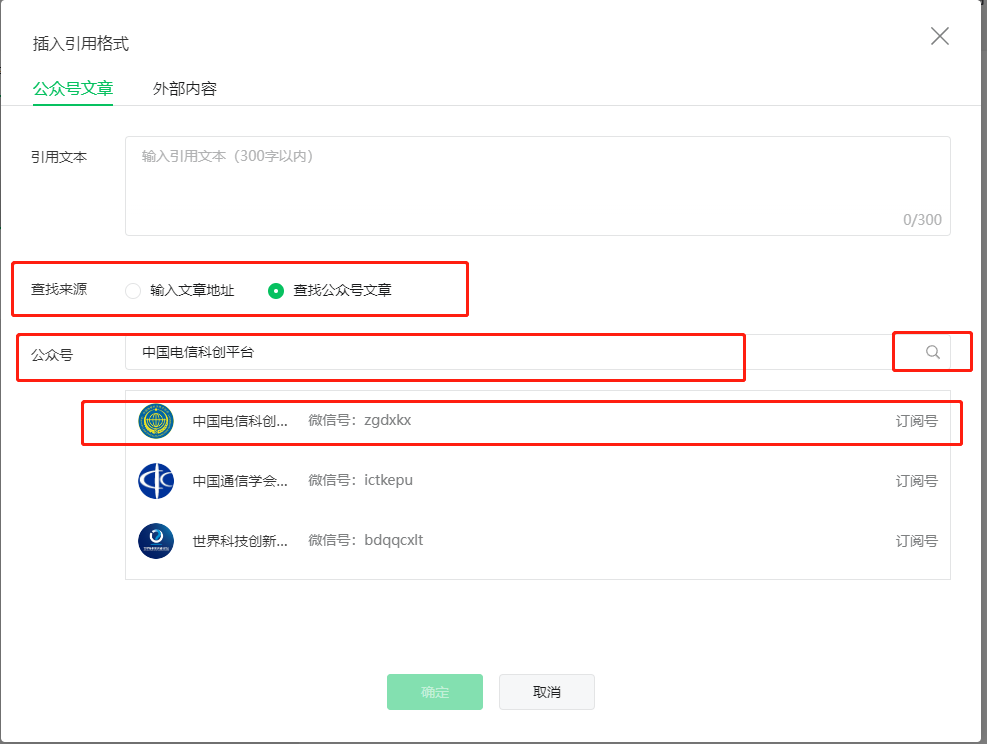
点击确认之后,进入公众号,可以查看相应文章。
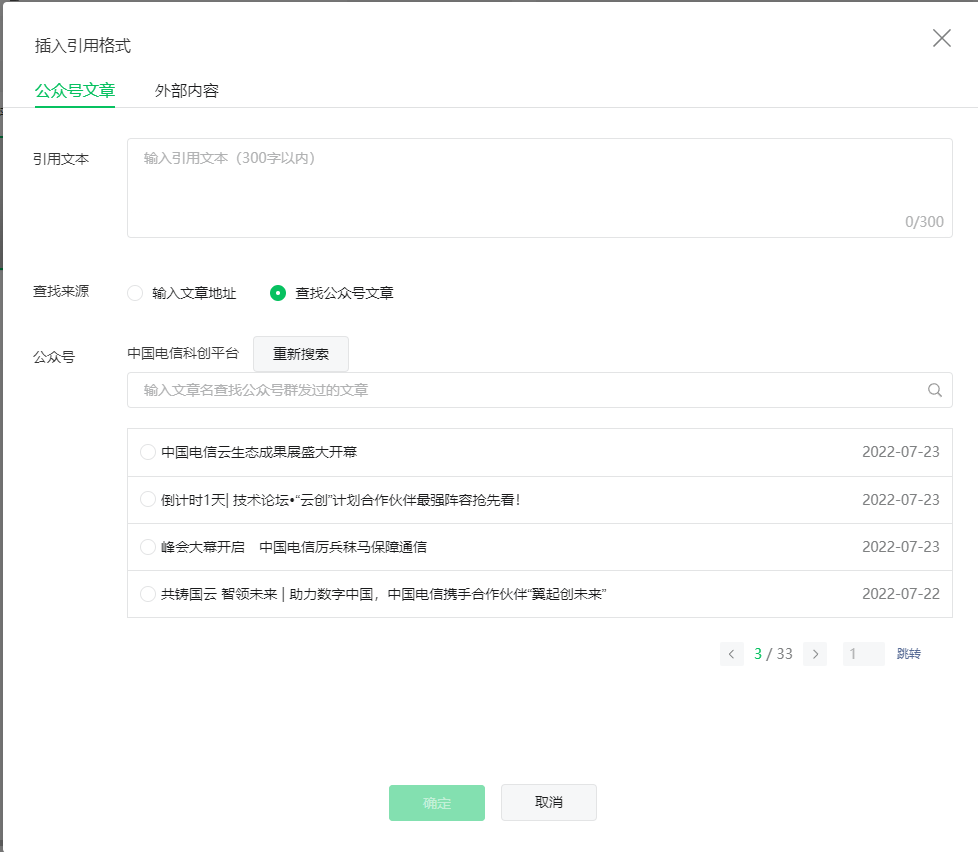
右键单击空白处,选择检查-网络,显示界面如下:
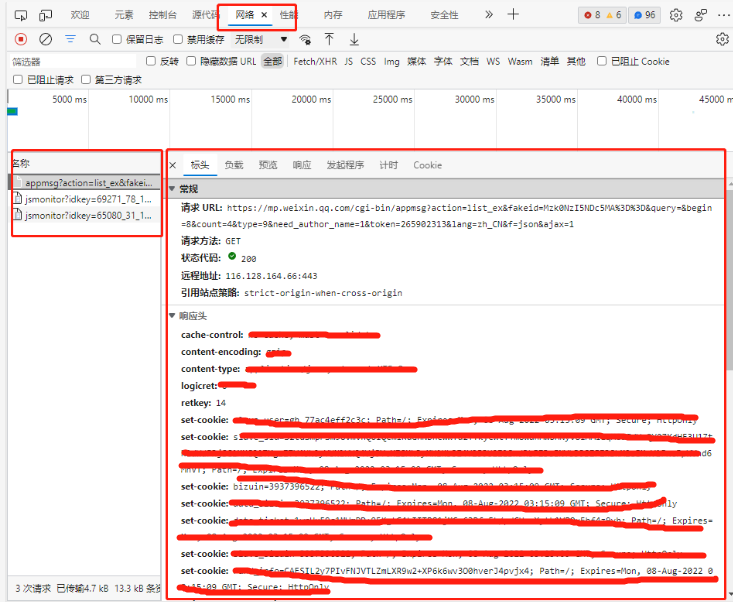
在请求标头中获取cookie和user-agent
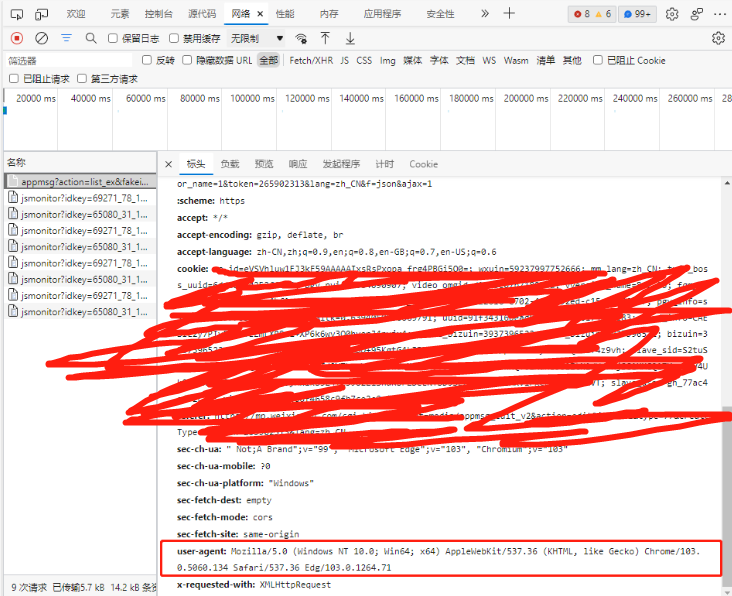
同时还需要获取Fakeid 和token
fakeid:是公众号独一无二的一个id
token:是自己的公众号独有的id
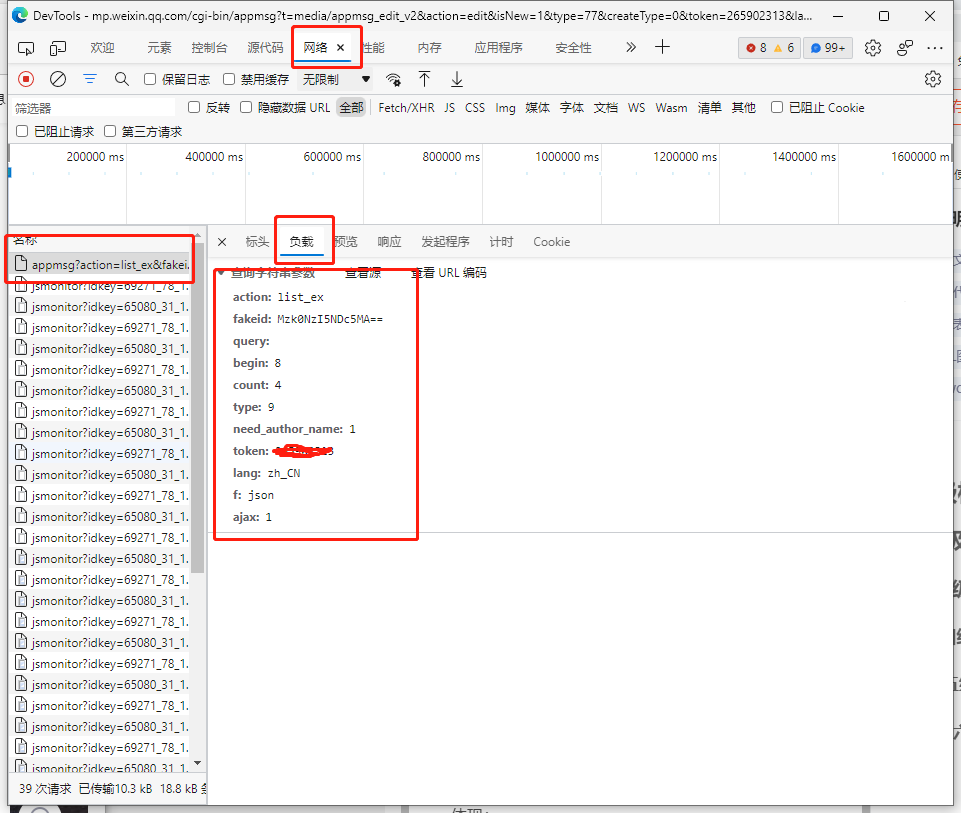
以上已经获取到了电脑端需要的4个重要参数:
Cookies、user-Agent 、fakeid 、token
爬取点赞数和阅读数:
在之前查找公众号的文章时,可以在相应信息中查找到文章的相关信息:
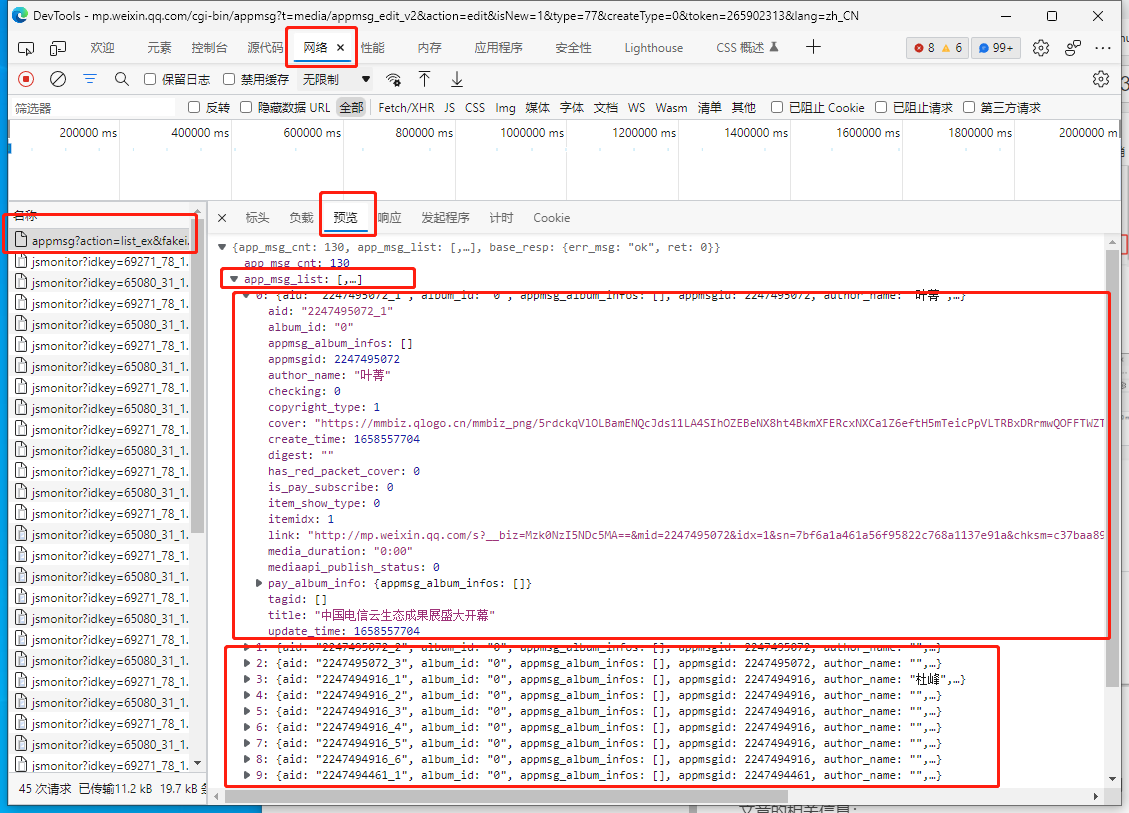
观察这些信息,可以在信息中找到公众号的文章标题,文章对应的链接

将文章链接复制到浏览器中,可以看到对应的公众号文章:
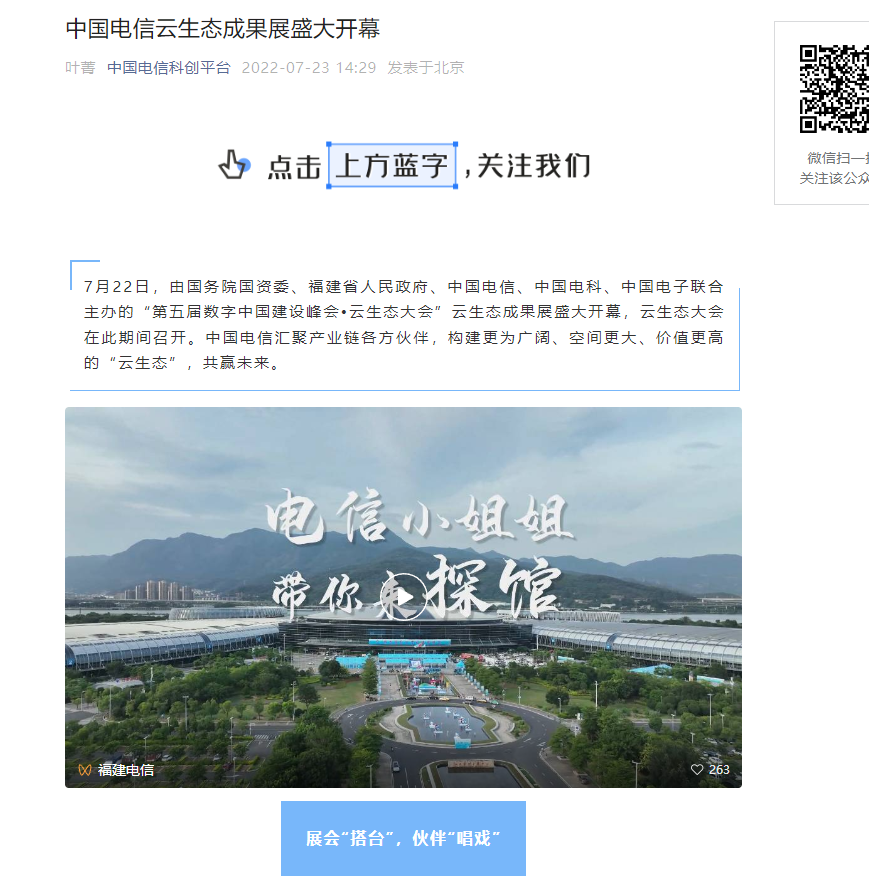
得到文章的链接之后,需要从链接中找到pass_ticket 、 appmsg_tojen 、 cookies 、user-Agent 、key。
通过fiddler抓包,得到这些参数
打开fiddler,选择过滤器

设置以下参数,点击action,设定只抓取关于微信公众相关的包
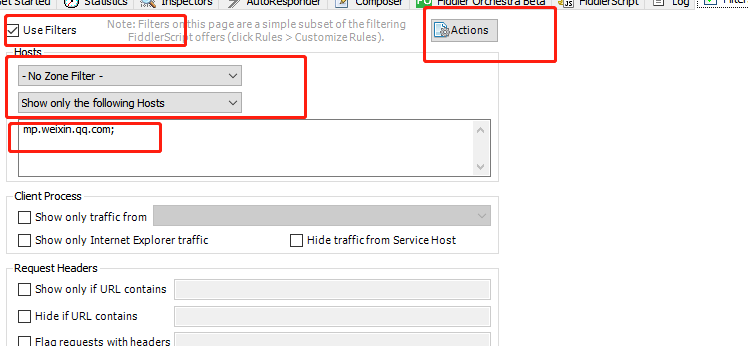
之后进入自己的微信客户端-选择公众号-查看历史信息-点开公众号的文章。
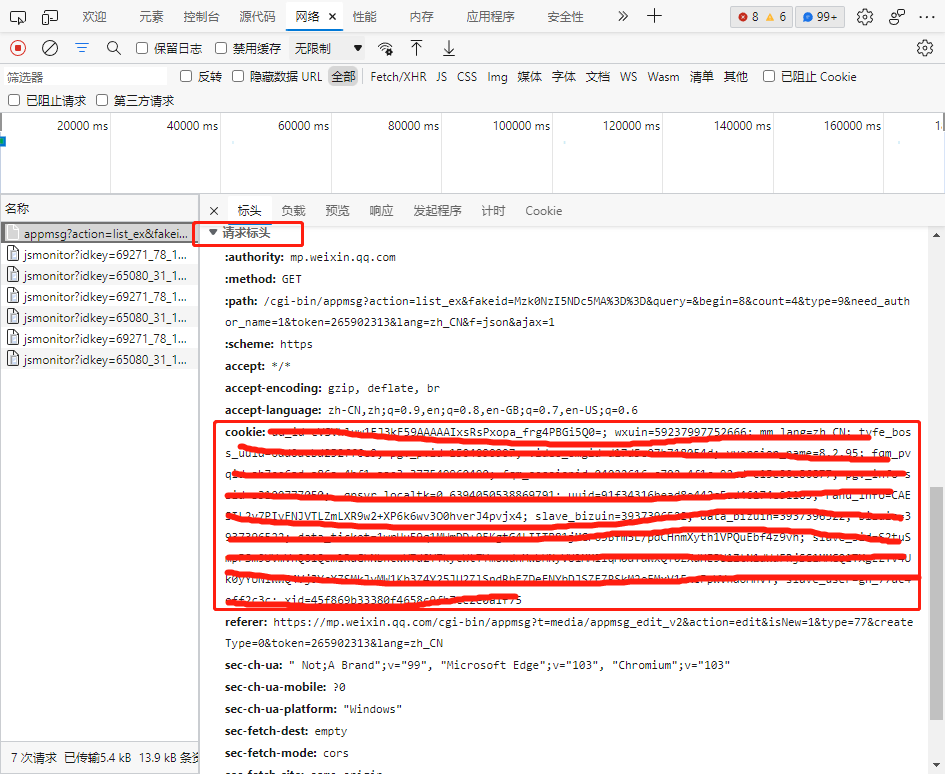
这时可以看到fiddler中出现一系列的包,依次点击抓取的包,在inspectors中查看以下信息,获取 pc微信端cookie 和user-agent
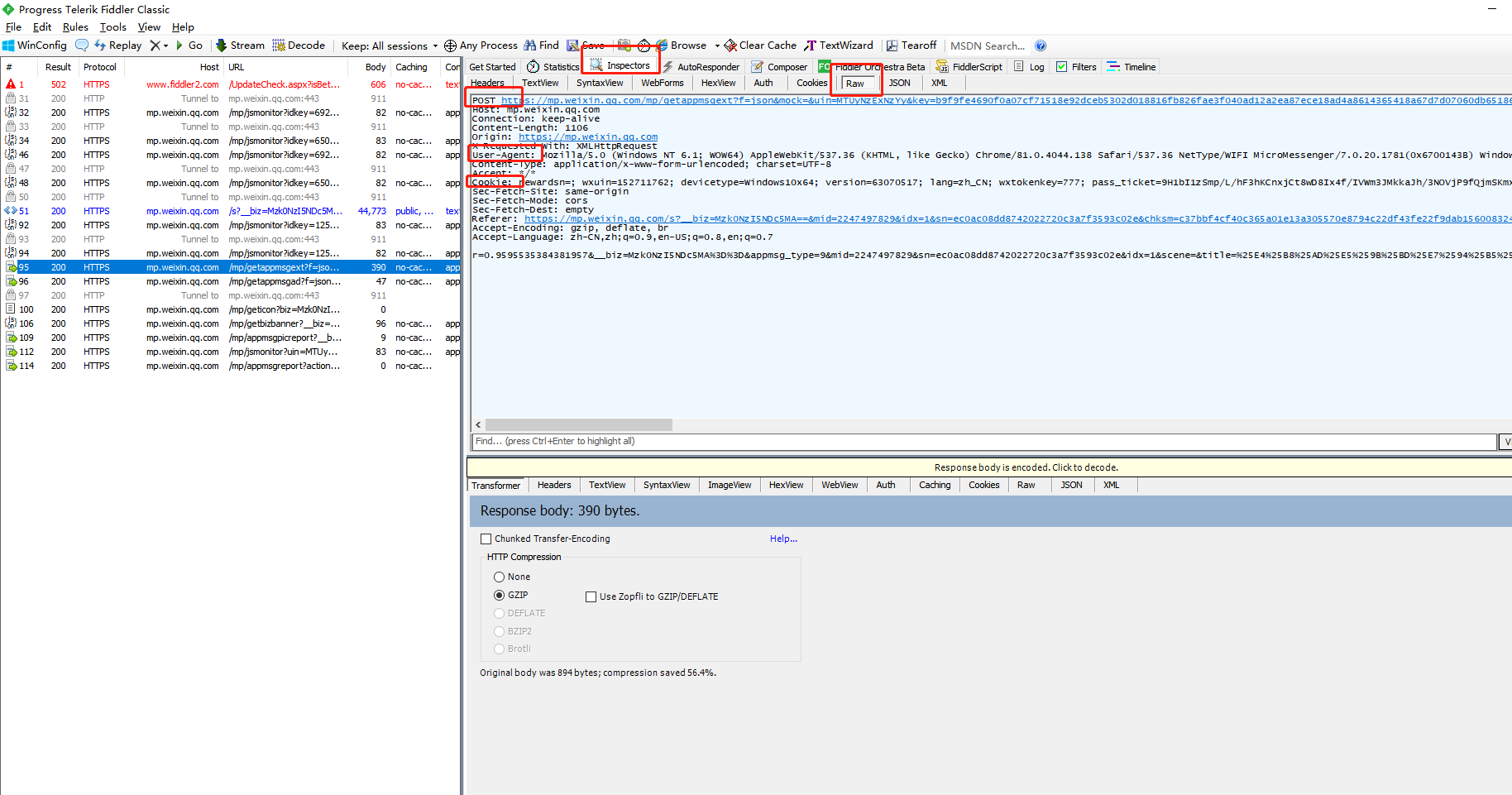
切换点击界面,可以看到如下信息:
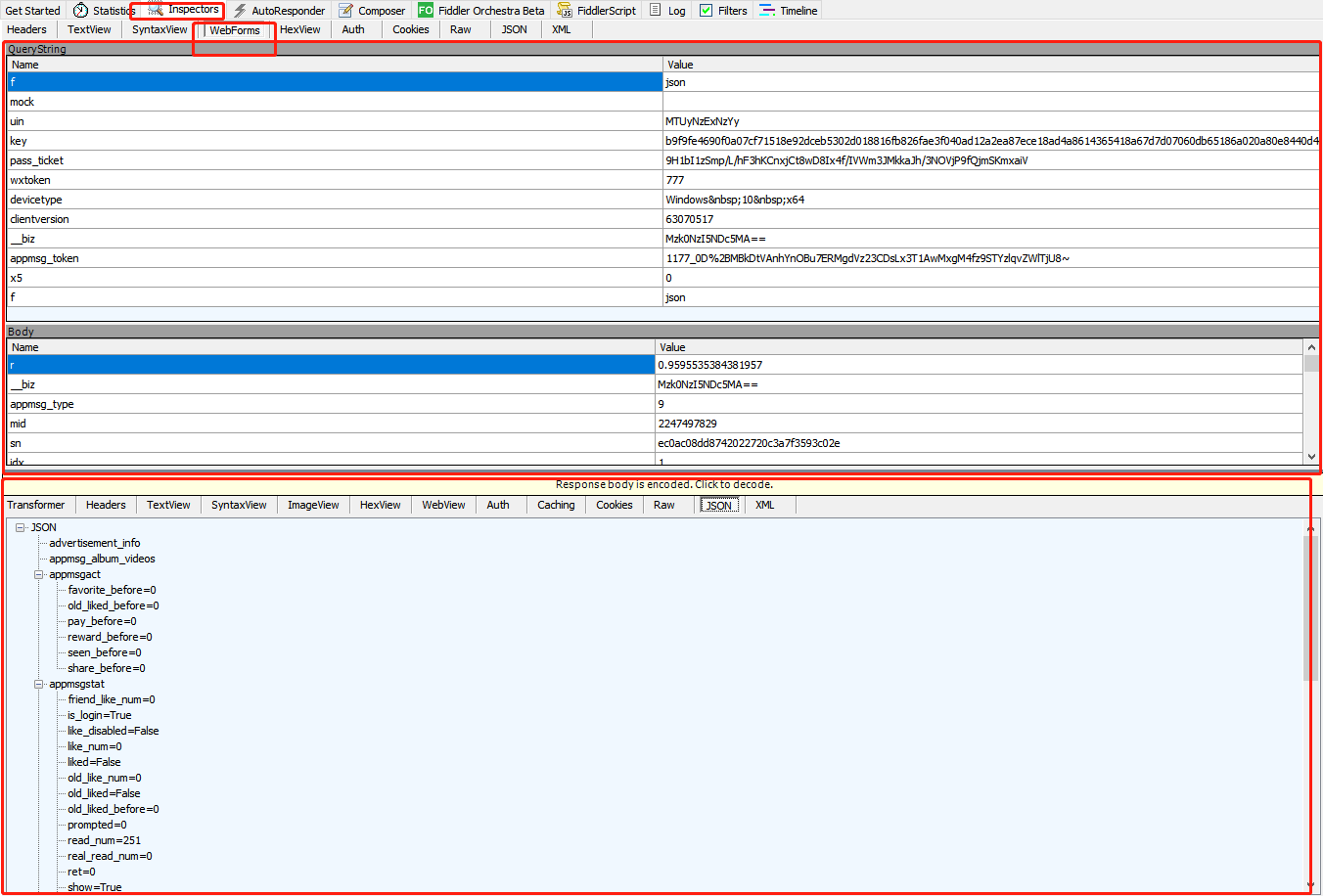
可以从上面的界面中找到需要保存的参数:
更换公众号爬虫只需要更换PC微信的Key、 pass_ticket、 appmsg_tojen以及公众号的Fakeid。对某一公众号爬虫时,KEY大约20-30分钟会失效。可以再次打开fiddler重新进行获取。
贴一下我的代码:
# -*- coding: utf-8 -*-
import requests
import time
import json
from openpyxl import Workbook
import random
# 目标url
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
Cookie = "自己的cookies"
# 使用Cookie,跳过登陆操作
headers = {
"Cookie": Cookie,
"User-Agent": "自己的user-agent",
}
"""
需要提交的data
以下个别字段是否一定需要还未验证。
注意修改yourtoken,number
number表示从第number页开始爬取,为5的倍数,从0开始。如0、5、10……
token可以使用Chrome自带的工具进行获取
fakeid是公众号独一无二的一个id,等同于后面的__biz
"""
token = "自己公众号的token"#公众号
fakeid = "Mzk0NzI5NDc5MA%3D%3D"#公众号对应的id
type = '9'
#爬虫网址中的参数
data1 = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin":  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1515
1515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









