







1、Flink CDC 1.x 2.x 区别 实现原理
参考链接:1
2、Hudi mor cow 读取流程
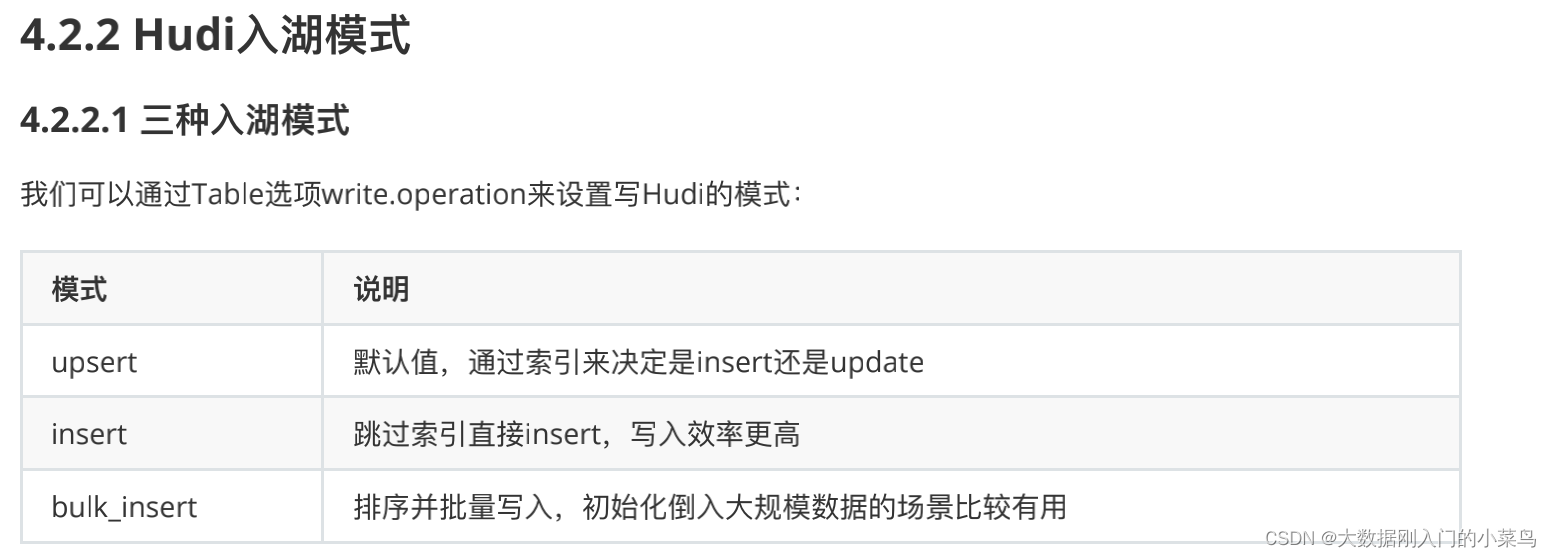






3、Spark shuffle 类型及区别
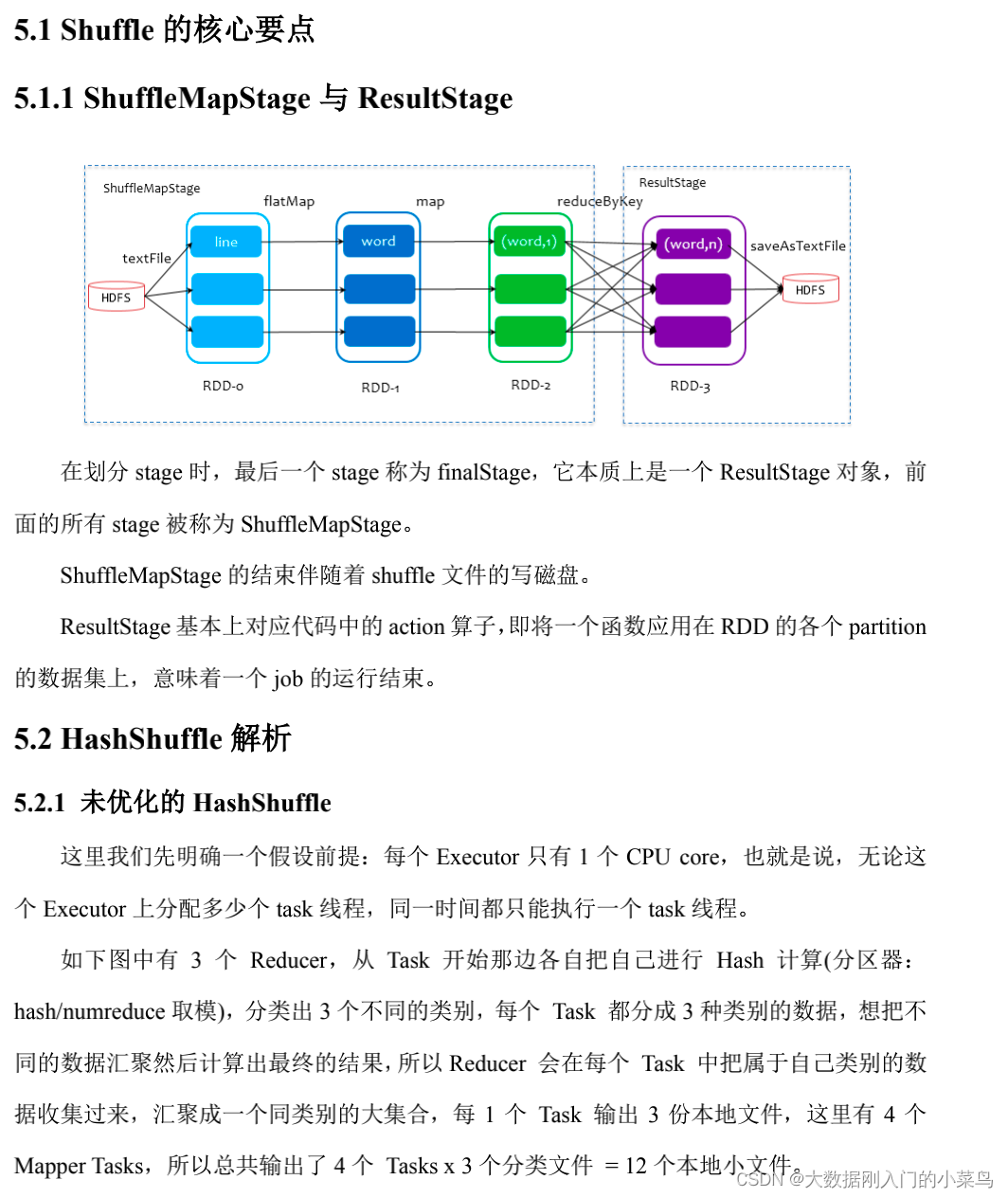
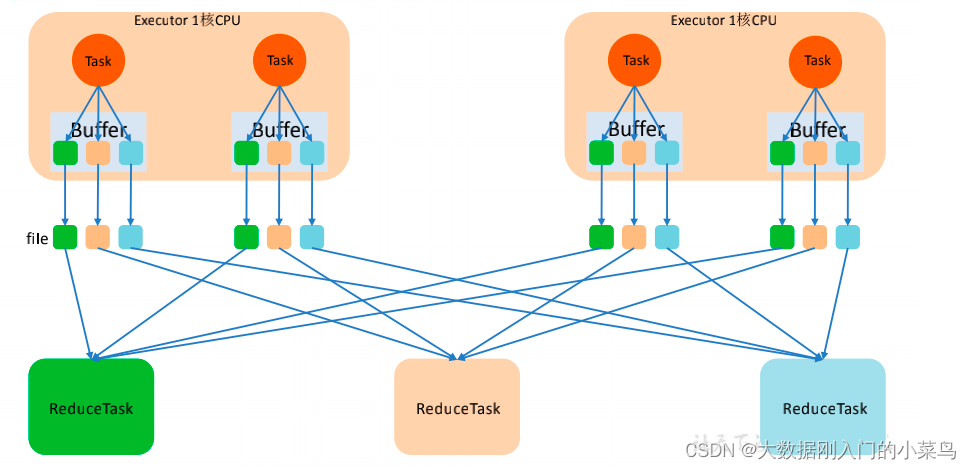

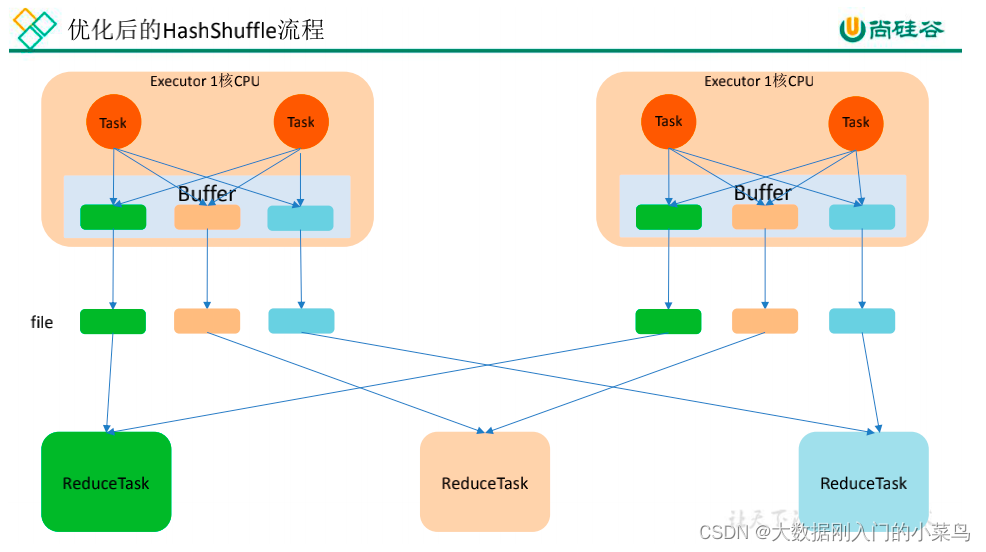
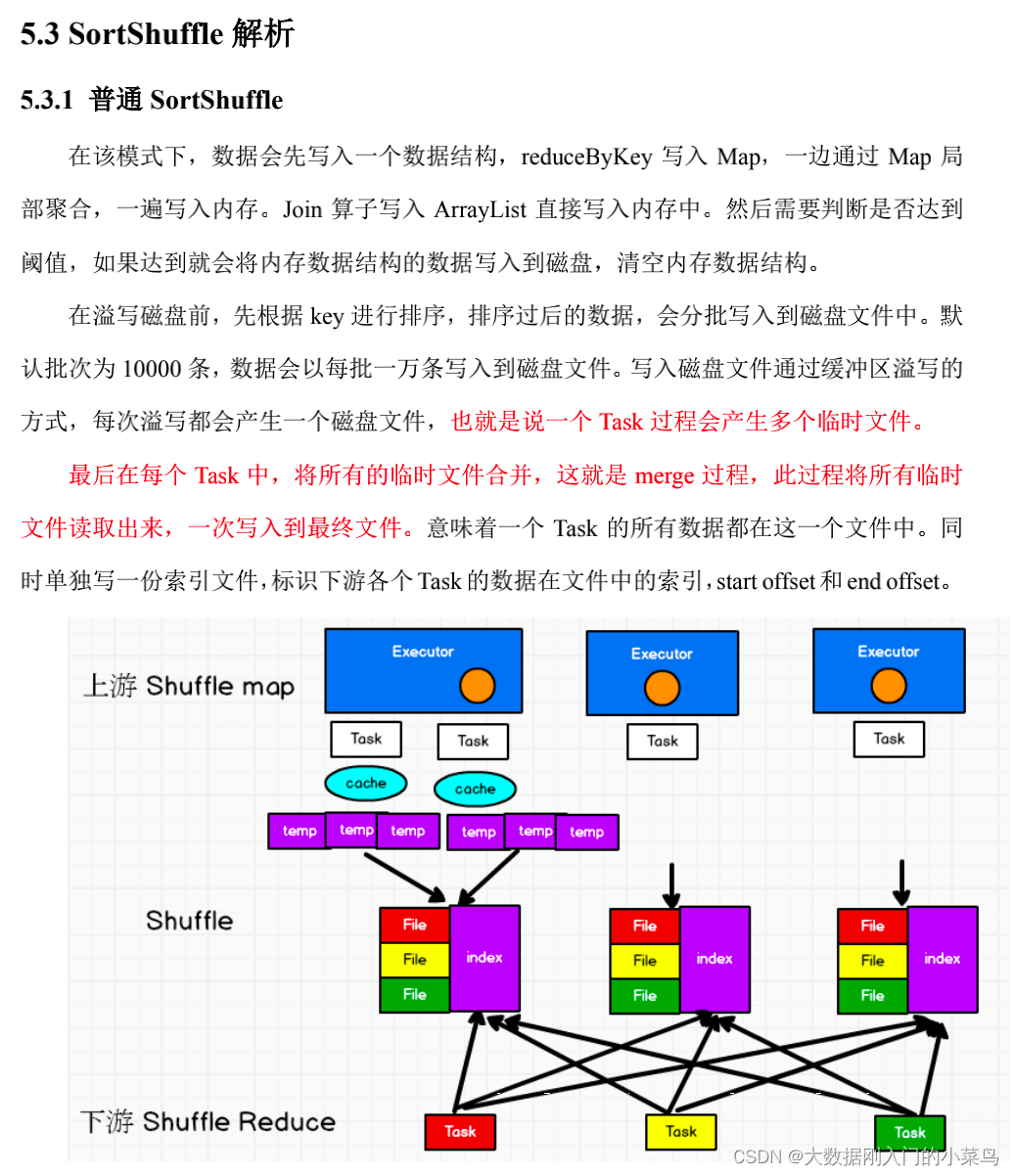

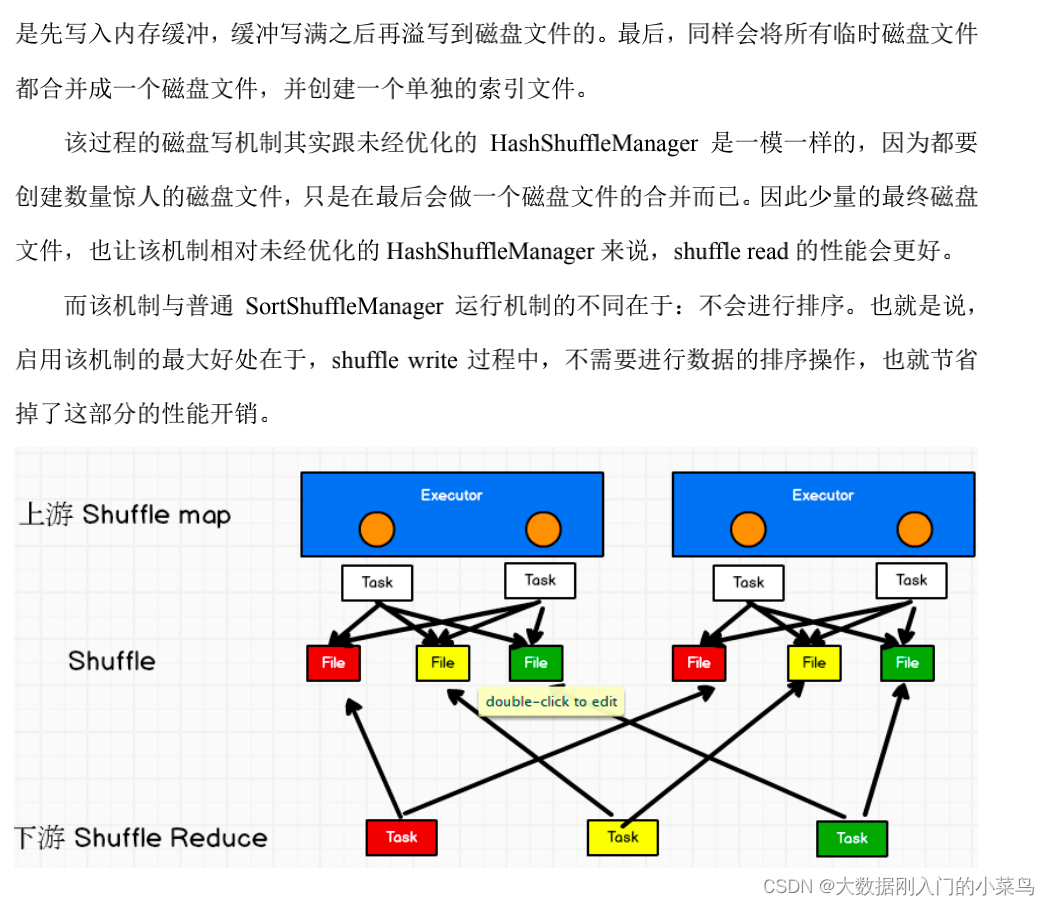
8、Flink 反压处理优化 Flink taskmanager 内存
9、Spark 宽依赖 窄依赖 shuffle
10、Flink 内存管理

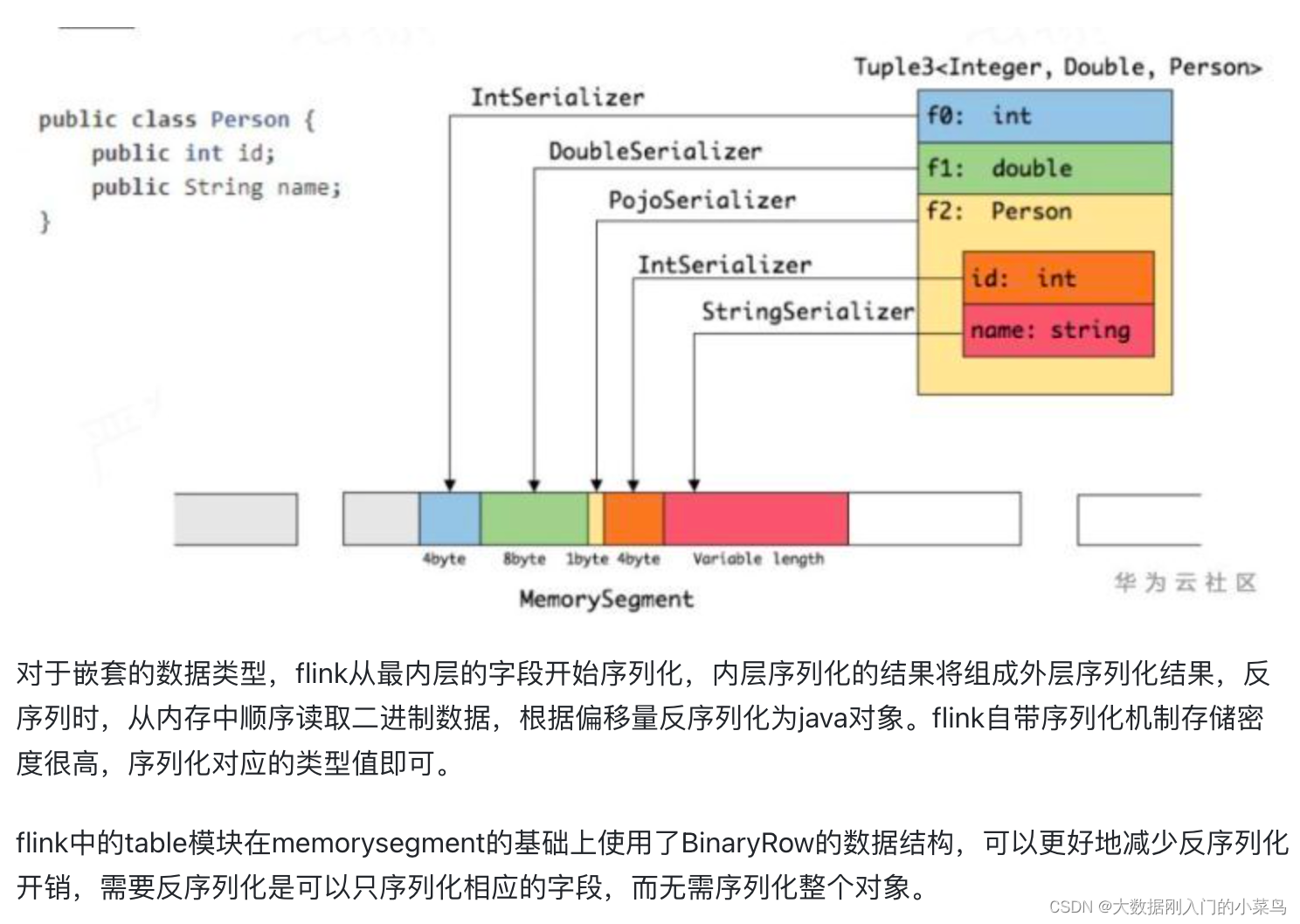
Flink是jvm之上的大数据处理引擎,jvm存在java对象存储密度低、full gc时消耗性能,gc存在stw的问题,同时omm时会影响稳定性。同时针对频繁序列化和反序列化问题flink使用堆内堆外内存可以直接在一些场景下操作二进制数据,减少序列化反序列化的消耗。同时基于大数据流式处理的特点,flink定制了自己的一套序列化框架。flink也会基于cpu L1 L2 L3高速缓存的机制以及局部性原理,设计使用缓存友好的数据结构。
flink内存管理和spark的tungsten的内存管理的出发点很相似。
flink使用内存划分为堆内内存和堆外内存。按照用途可以划分为task所用内存,network memory、managed memory、以及framework所用内存,其中task network managed所用内存计入slot内存。framework为taskmanager公用。
堆内内存包含用户代码所用内存、heapstatebackend、框架执行所用内存。
堆外内存是未经jvm虚拟化的内存,直接映射到操作系统的内存地址,堆外内存包含框架执行所用内存,jvm堆外内存、Direct、native等。
Direct memory内存可用于网络传输缓冲。network memory属于direct memory的范畴,flink可以借助于此进行zero copy,从而减少内核态到用户态copy次数,从而进行更高效的io操作。
jvm metaspace存放jvm加载的类的元数据,加载的类越多,需要的空间越大,overhead用于jvm的其他开销,如native memory、code cache、thread stack等。
Managed Memory主要用于RocksDBStateBackend和批处理算子,也属于native memory的范畴,其中rocksdbstatebackend对应rocksdb,rocksdb基于lsm数据结构实现,每个state对应一个列族,占有独立的writebuffer,rocksdb占用native内存大小为 blockCahe + writebufferNum * writeBuffer + index ,同时堆外内存是进程之间共享的,jvm虚拟化大量heap内存耗时较久,使用堆外内存的话可以有效的避免该环节。但堆外内存也有一定的弊端,即监控调试使用相对复杂,对于生命周期较短的segment使用堆内内存开销更低,flink在一些情况下,直接操作二进制数据,避免一些反序列化带来的开销。如果需要处理的数据超出了内存限制,则会将部分数据存储到硬盘上。
内存管理
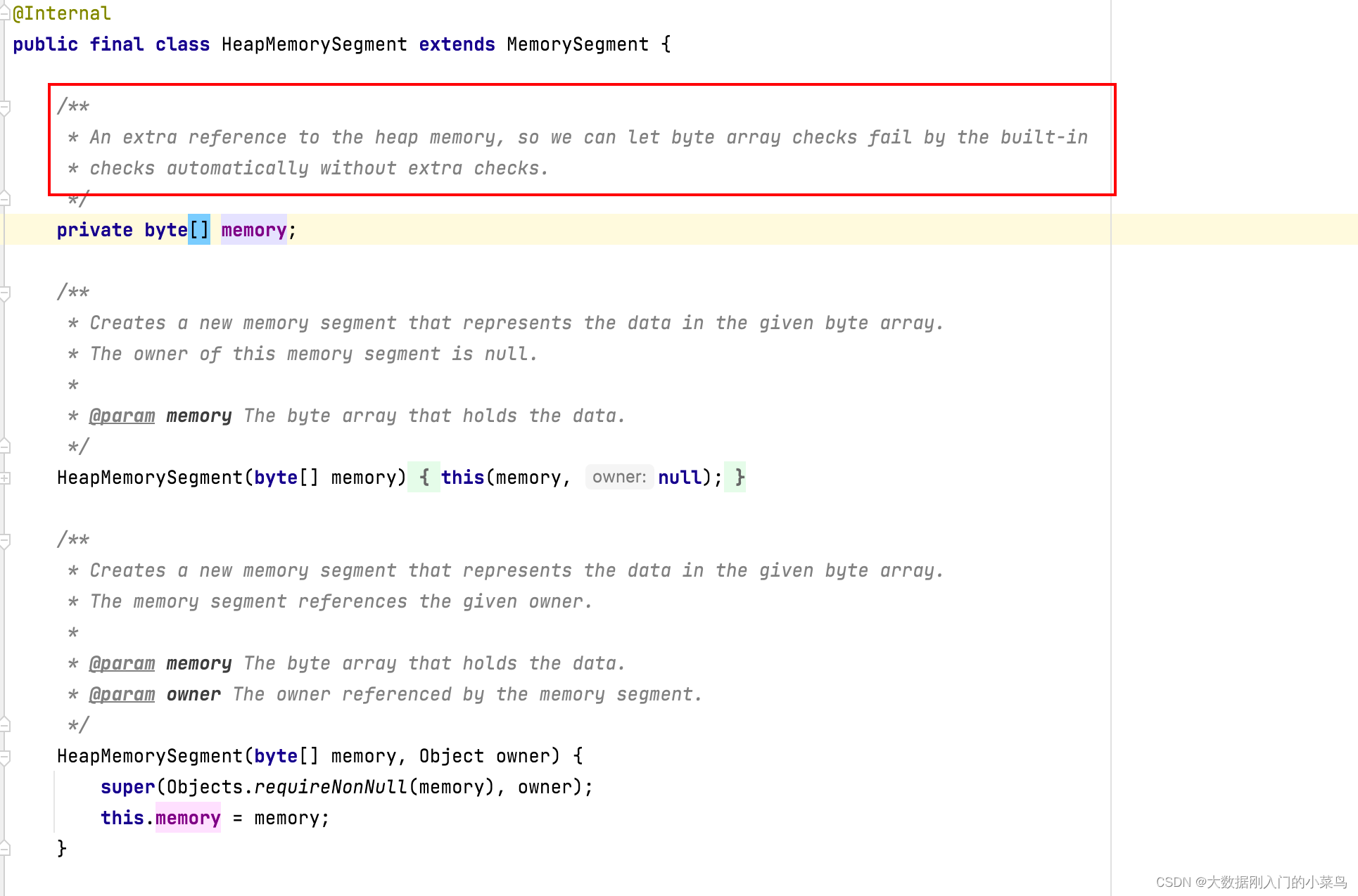
类似于OS中的page机制,flink模拟了操作系统的机制,通过page来管理内存,flink对应page的数据结构为dataview和MemorySegment,memorysegment是flink内存分配的最小单位,默认32kb,其可以在堆上也可以在堆外,flink通过MemorySegment的数据结构来访问堆内堆外内存,借助于flink序列化机制(序列化机制会在下一小节讲解),memorysegment提供了对二进制数据的读取和写入的方法,flink使用datainputview和dataoutputview进行memorysegment的二进制的读取和写入,flink可以通过HeapMemorySegment 管理堆内内存,通过HybridMemorySegment来管理堆内和堆外内存,MemorySegment管理jvm堆内存时,其定义一个字节数组的引用指向内存端,基于该内部字节数组的引用进行操作的HeapMemorySegment。
public abstract class MemorySegment { /**
* The heap byte array object relative to which we access the memory.
* 如果为堆内存,则指向访问的内存的引用,否则若内存为非堆内存,则为null
* <p>Is non-<tt>null</tt> if the memory is on the heap, and is <tt>null</tt>, if the memory is
* off the heap. If we have this buffer, we must never void this reference, or the memory
* segment will point to undefined addresses outside the heap and may in out-of-order execution
* cases cause segmentation faults. */
protected final byte[] heapMemory; /**
* The address to the data, relative to the heap memory byte array. If the heap memory byte
* array is <tt>null</tt>, this becomes an absolute memory address outside the heap.
* 字节数组对应的相对地址 */
protected long address;
}
HeapMemorySegment用来分配堆上内存。
HybridMemorySegment即支持onheap和offheap内存,flink通过jvm的unsafe操作,如果对象o不为null,为onheap的场景,并且后面的地址或者位置是相对位置,那么会直接对当前对象(比如数组)的相对位置进行操作。如果对象o为null,操作的内存块不是JVM堆内存,为off-heap的场景,并且后面的地址是某个内存块的绝对地址,那么这些方法的调用也相当于对该内存块进行操作。
public final class HybridMemorySegment extends MemorySegment {
.........
@Override
public ByteBuffer wrap(int offset, int length) {
if (address <= addressLimit) {
if (heapMemory != null) {
return ByteBuffer.wrap(heapMemory, offset, length);
}
else {
try {
ByteBuffer wrapper = offHeapBuffer.duplicate();
wrapper.limit(offset + length);
wrapper.position(offset);
return wrapper;
}
catch (IllegalArgumentException e) {
throw new IndexOutOfBoundsException();
}
}
}
else {
throw new IllegalStateException("segment has been freed");
}
}
.........
}
flink通过MemorySegmentFactory来创建memorySegment,memorySegment是flink内存分配的最小单位。对于跨memorysegment的数据方位,flink抽象出一个访问视图,数据读取datainputView,数据写入dataoutputview。
@Public
public interface DataInputView extends DataInput {
/**
* Skips {@code numBytes} bytes of memory. In contrast to the {@link #skipBytes(int)} method,
* this method always skips the desired number of bytes or throws an {@link java.io.EOFException}.
*
* @param numBytes The number of bytes to skip.
*
* @throws IOException Thrown, if any I/O related problem occurred such that the input could not
* be advanced to the desired position.
*/
void skipBytesToRead(int numBytes) throws IOException;
/**
* Reads up to {@code len} bytes of memory and stores it into {@code b} starting at offset {@code off}.
* It returns the number of read bytes or -1 if there is no more data left.
*
* @param b byte array to store the data to
* @param off offset into byte array
* @param len byte length to read
* @return the number of actually read bytes of -1 if there is no more data left
* @throws IOException
*/
int read(byte[] b, int off, int len) throws IOException;
/**
* Tries to fill the given byte array {@code b}. Returns the actually number of read bytes or -1 if there is no
* more data.
*
* @param b byte array to store the data to
* @return the number of read bytes or -1 if there is no more data left
* @throws IOException
*/
int read(byte[] b) throws IOException;
}
dataoutputview是数据写入的视图,outputview持有多个memorysegment的引用,flink可以顺序的写入segment。
/**
* This interface defines a view over some memory that can be used to sequentially write contents to the memory.
* The view is typically backed by one or more {@link org.apache.flink.core.memory.MemorySegment}.
*/
@Public
public interface DataOutputView extends DataOutput {
/**
* Skips {@code numBytes} bytes memory. If some program reads the memory that was skipped over, the
* results are undefined.
*
* @param numBytes The number of bytes to skip.
*
* @throws IOException Thrown, if any I/O related problem occurred such that the view could not
* be advanced to the desired position.
*/
void skipBytesToWrite(int numBytes) throws IOException;
/**
* Copies {@code numBytes} bytes from the source to this view.
*
* @param source The source to copy the bytes from.
* @param numBytes The number of bytes to copy.
*
* @throws IOException Thrown, if any I/O related problem occurred, such that either the input view
* could not be read, or the output could not be written.
*/
void write(DataInputView source, int numBytes) throws IOException;
}
上一小节中讲到的managedmemory内存部分,flink使用memorymanager来管理该内存,managedmemory只使用堆外内存,主要用于批处理中的sorting、hashing、以及caching(社区消息,未来流处理也会使用到该部分),在流计算中作为rocksdbstatebackend的部分内存。memeorymanager通过memorypool来管理memorysegment。
// ------------------------------------------------------------------------
// Memory allocation and release
// ------------------------------------------------------------------------
/**
* Allocates a set of memory segments from this memory manager.
*
* <p>The total allocated memory will not exceed its size limit, announced in the constructor.
*
* @param owner The owner to associate with the memory segment, for the fallback release.
* @param numPages The number of pages to allocate.
* @return A list with the memory segments.
* @throws MemoryAllocationException Thrown, if this memory manager does not have the requested amount
* of memory pages any more.
*/
public List<MemorySegment> allocatePages(Object owner, int numPages) throws MemoryAllocationException {
List<MemorySegment> segments = new ArrayList<>(numPages);
allocatePages(owner, segments, numPages);
return segments;
}
/**
* Allocates a set of memory segments from this memory manager.
*
* <p>The total allocated memory will not exceed its size limit, announced in the constructor.
*
* @param owner The owner to associate with the memory segment, for the fallback release.
* @param target The list into which to put the allocated memory pages.
* @param numberOfPages The number of pages to allocate.
* @throws MemoryAllocationException Thrown, if this memory manager does not have the requested amount
* of memory pages any more.
*/
public void allocatePages(
Object owner,
Collection<MemorySegment> target,
int numberOfPages) throws MemoryAllocationException {
// sanity check
Preconditions.checkNotNull(owner, "The memory owner must not be null.");
Preconditions.checkState(!isShutDown, "Memory manager has been shut down.");
Preconditions.checkArgument(
numberOfPages <= totalNumberOfPages,
"Cannot allocate more segments %d than the max number %d",
numberOfPages,
totalNumberOfPages);
// reserve array space, if applicable
if (target instanceof ArrayList) {
((ArrayList<MemorySegment>) target).ensureCapacity(numberOfPages);
}
long memoryToReserve = numberOfPages * pageSize;
try {
memoryBudget.reserveMemory(memoryToReserve);
} catch (MemoryReservationException e) {
throw new MemoryAllocationException(String.format("Could not allocate %d pages", numberOfPages), e);
}
Runnable pageCleanup = this::releasePage;
allocatedSegments.compute(owner, (o, currentSegmentsForOwner) -> {
Set<MemorySegment> segmentsForOwner = currentSegmentsForOwner == null ?
new HashSet<>(numberOfPages) : currentSegmentsForOwner;
for (long i = numberOfPages; i > 0; i--) {
MemorySegment segment = allocateOffHeapUnsafeMemory(getPageSize(), owner, pageCleanup);
target.add(segment);
segmentsForOwner.add(segment);
}
return segmentsForOwner;
});
Preconditions.checkState(!isShutDown, "Memory manager has been concurrently shut down.");
}
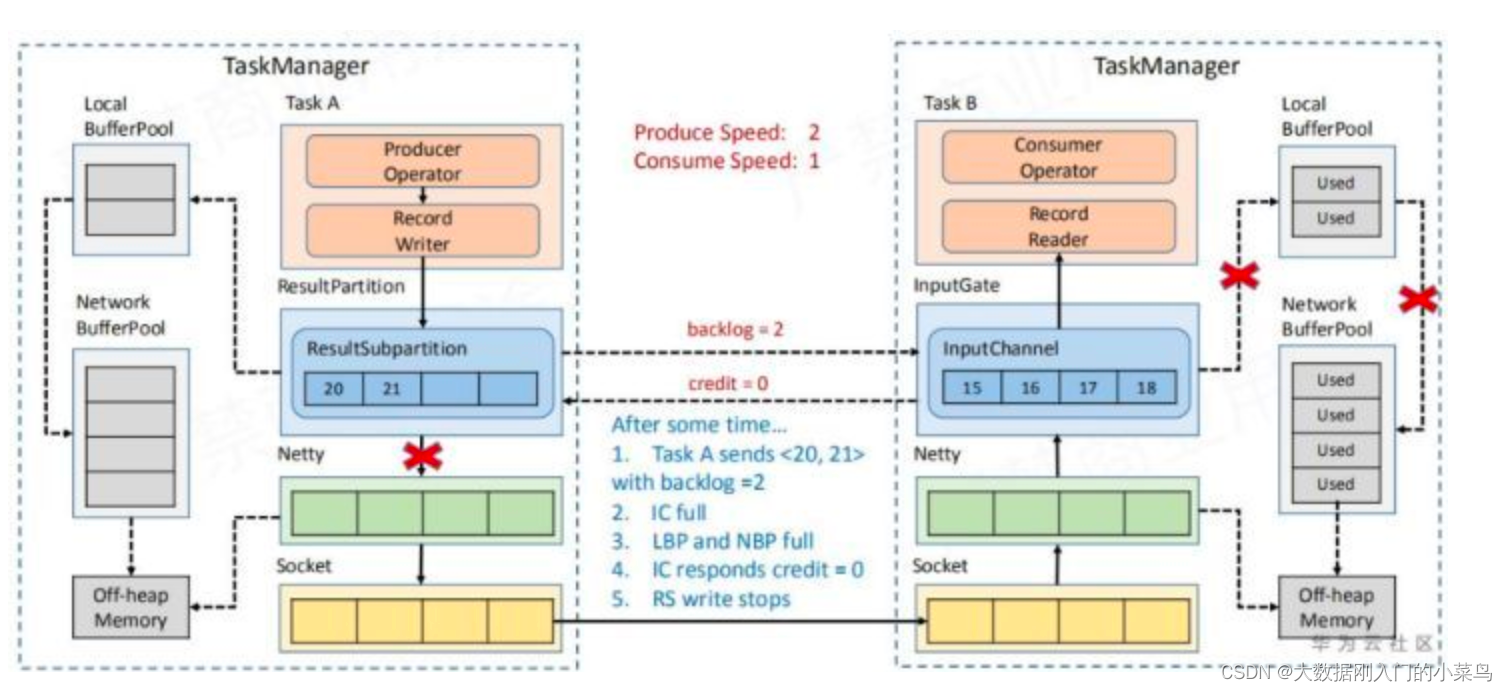
对于上一小节中提到的NetWorkMemory的内存,flink使用networkbuffer做了一层buffer封装。buffer的底层也是memorysegment,flink通过bufferpool来管理buffer,每个taskmanager都有一个netwokbufferpool,该tm上的各个task共享该networkbufferpool,同时task对应的localbufferpool所需的内存需要从networkbufferpool申请而来,它们都是flink申请的堆外内存。
上游算子向resultpartition写入数据时,申请buffer资源,使用bufferbuilder将数据写入memorysegment,下游算子从resultsubpartition消费数据时,利用bufferconsumer从memorysegment中读取数据,bufferbuilder与bufferconsumer一一对应。同时这一流程也和flink的反压机制相关。如图
class LocalBufferPool implements BufferPool {
private static final Logger LOG = LoggerFactory.getLogger(LocalBufferPool.class);
private static final int UNKNOWN_CHANNEL = -1;
/** Global network buffer pool to get buffers from. */
private final NetworkBufferPool networkBufferPool;
/** The minimum number of required segments for this pool. */
private final int numberOfRequiredMemorySegments;
/**
* The currently available memory segments. These are segments, which have been requested from
* the network buffer pool and are currently not handed out as Buffer instances.
*
* <p><strong>BEWARE:</strong> Take special care with the interactions between this lock and
* locks acquired before entering this class vs. locks being acquired during calls to external
* code inside this class, e.g. with
* {@link org.apache.flink.runtime.io.network.partition.consumer.BufferManager#bufferQueue}
* via the {@link #registeredListeners} callback.
*/
private final ArrayDeque<MemorySegment> availableMemorySegments = new ArrayDeque<MemorySegment>();
/**
* Buffer availability listeners, which need to be notified when a Buffer becomes available.
* Listeners can only be registered at a time/state where no Buffer instance was available.
*/
private final ArrayDeque<BufferListener> registeredListeners = new ArrayDeque<>();
/** Maximum number of network buffers to allocate. */
private final int maxNumberOfMemorySegments;
/** The current size of this pool. */
@GuardedBy("availableMemorySegments")
private int currentPoolSize;
public abstract class ResultPartition implements ResultPartitionWriter {
protected static final Logger LOG = LoggerFactory.getLogger(ResultPartition.class);
private final String owningTaskName;
private final int partitionIndex;
protected final ResultPartitionID partitionId;
/** Type of this partition. Defines the concrete subpartition implementation to use. */
protected final ResultPartitionType partitionType;
protected final ResultPartitionManager partitionManager;
protected final int numSubpartitions;
private final int numTargetKeyGroups;
// - Runtime state --------------------------------------------------------
private final AtomicBoolean isReleased = new AtomicBoolean();
protected BufferPool bufferPool;
private boolean isFinished;
private volatile Throwable cause;
private final SupplierWithException<BufferPool, IOException> bufferPoolFactory;
/** Used to compress buffer to reduce IO. */
@Nullable
protected final BufferCompressor bufferCompressor;
protected Counter numBytesOut = new SimpleCounter();
protected Counter numBuffersOut = new SimpleCounter();
public ResultPartition(
String owningTaskName,
int partitionIndex,
ResultPartitionID partitionId,
ResultPartitionType partitionType,
int numSubpartitions,
int numTargetKeyGroups,
ResultPartitionManager partitionManager,
@Nullable BufferCompressor bufferCompressor,
SupplierWithException<BufferPool, IOException> bufferPoolFactory) {
this.owningTaskName = checkNotNull(owningTaskName);
Preconditions.checkArgument(0 <= partitionIndex, "The partition index must be positive.");
this.partitionIndex = partitionIndex;
this.partitionId = checkNotNull(partitionId);
this.partitionType = checkNotNull(partitionType);
this.numSubpartitions = numSubpartitions;
this.numTargetKeyGroups = numTargetKeyGroups;
this.partitionManager = checkNotNull(partitionManager);
this.bufferCompressor = bufferCompressor;
this.bufferPoolFactory = bufferPoolFactory;
}
/**
* Registers a buffer pool with this result partition.
*
* <p>There is one pool for each result partition, which is shared by all its sub partitions.
*
* <p>The pool is registered with the partition *after* it as been constructed in order to conform
* to the life-cycle of task registrations in the {@link TaskExecutor}.
*/
@Override
public void setup() throws IOException {
checkState(this.bufferPool == null, "Bug in result partition setup logic: Already registered buffer pool.");
this.bufferPool = checkNotNull(bufferPoolFactory.get());
partitionManager.registerResultPartition(this);
}
public String getOwningTaskName() {
return owningTaskName;
}
@Override
public ResultPartitionID getPartitionId() {
return partitionId;
}
public int getPartitionIndex() {
return partitionIndex;
}
@Override
public int getNumberOfSubpartitions() {
return numSubpartitions;
}
public BufferPool getBufferPool() {
return bufferPool;
}
/**
自定义序列化框架
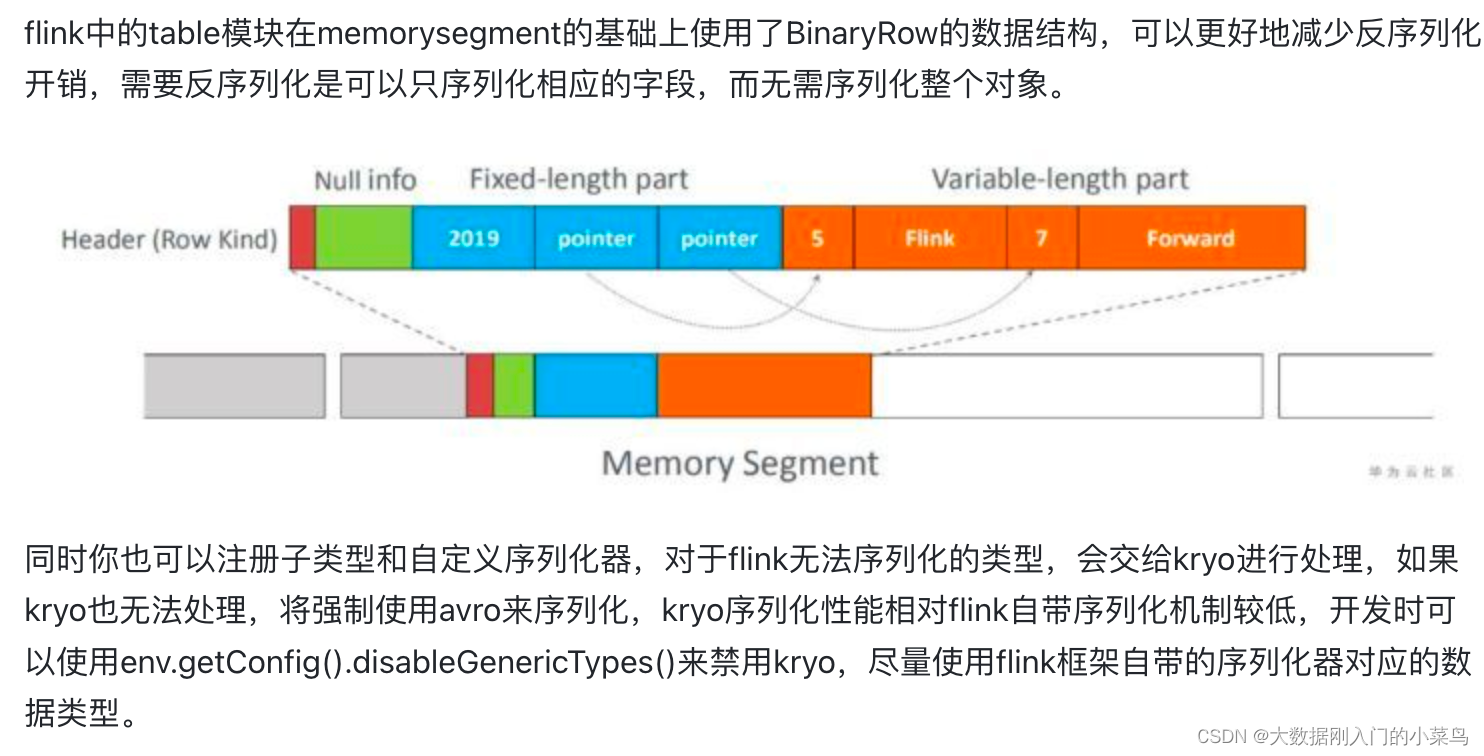
flink对自身支持的基本数据类型,实现了定制的序列化机制,flink数据集对象相对固定,可以只保存一份schema信息,从而节省存储空间,数据序列化就是java对象和二进制数据之间的数据转换,flink使用TypeInformation的createSerializer接口负责创建每种类型的序列化器,进行数据的序列化反序列化,类型信息在构建streamtransformation时通过typeextractor根据方法签名类信息等提取类型信息并存储在streamconfig中。
* Creates a serializer for the type. The serializer may use the ExecutionConfig
* for parameterization.
* 创建出对应类型的序列化器
* @param config The config used to parameterize the serializer.
* @return A serializer for this type. */ @PublicEvolving public abstract TypeSerializer<T> createSerializer(ExecutionConfig config); /**
A utility for reflection analysis on classes, to determine the return type of implementations of transformation
functions. / @Public public class TypeExtractor { /*
Creates a {@link TypeInformation} from the given parameters.
* If the given {@code instance} implements {@link ResultTypeQueryable}, its information
* is used to determine the type information. Otherwise, the type information is derived
* based on the given class information.
* @param instance instance to determine type information for
* @param baseClass base class of {@code instance}
* @param clazz class of {@code instance}
* @param returnParamPos index of the return type in the type arguments of {@code clazz}
* @param <OUT> output type
* @return type information */ @SuppressWarnings("unchecked")
@PublicEvolving public static <OUT> TypeInformation<OUT> createTypeInfo(Object instance, Class<?> baseClass, Class<?> clazz, int returnParamPos) { if (instance instanceof ResultTypeQueryable) { return ((ResultTypeQueryable<OUT>) instance).getProducedType();
} else { return createTypeInfo(baseClass, clazz, returnParamPos, null, null);
}
}
















 966
966











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









