







前言
若执于空,空亦为障。 --彼得·马西森《雪豹》
堆结构是一种非常重要的基础数据结构,也是算法的重要内容,很多题目甚至只能通过用堆来进行,所以我们必须明确什么类型的题目可以使用堆,以及如何使用堆来解决。由于堆的结构和维护的过程很复杂,因此一般面试不需要手写堆的实现,但是在Java、python、C++已经提供了一些工具,因此需要知道思路就可以了。
这里主要简介堆的使用,如何进行增删改查,不用管代码怎么写,后面我们会继续介绍怎么使用堆解决问题的。
堆的概念和特征
堆是将一组数据按照完全二叉树的存储顺序(推荐⭐⭐⭐: 算法通过村第六关-树青铜笔记|中序后序_师晓峰的博客-CSDN博客),将数据存储在一个一维数组中的结构。堆有两种结构,一种称为大顶堆,一种称为小顶堆,如图下:
- 小顶堆:任意节点的值均小于它的左右孩子,并且最小值位于堆顶,即根节点处。
- 大顶堆:任意节点的值均大于它的左右孩子,并且最大值位于堆顶,即根节点处。
当然有些地方叫大根堆,小根堆,或者最大堆、最小堆都是一个意思。大小的特征都是类似的,只是比较的时候按照大的来点定还是按照小的来定。我们这里介绍先按照最大堆来进行,后面的题目我们根据条件来定。
小顶堆:
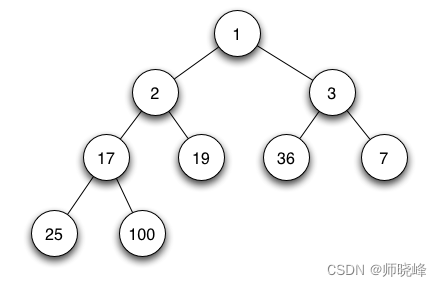
大顶堆:
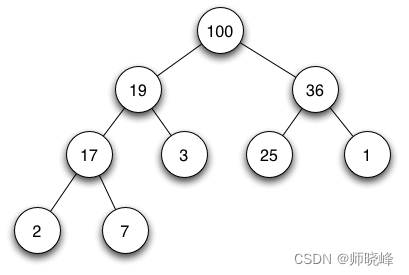
既然是将一组数据按照树的结构存储在一堆数组中,而且还是完全二叉树,那么父子之间的关系的建立就很重要了。
有个概念需要注意一下,我们在做题的时候经常会看到有地方叫做堆,有些地方叫优先队列,两者是什么关系呢?
优先队列:说到底还是一种队列,他的工作就是poll()/peek()出队列中的最大或者最小的那个元素,所以叫做带有优先级别的队列。能够实现这样的功能的策略不一定是堆。例如:二项堆、平衡树、线段树、C++里面还用二进制分组vector来实现一个优先队列。
堆:是一个很大的概念,它并不一点是完全二叉树。我们之前用完全二叉树是因为这个容易呗数组存储,但是除了这种二叉堆之外,还有二项堆、斐波那契堆。这种堆就不属于二叉树了。
所以说,优先队列和堆不是一个同level的概念,但是Java中PriorityQueue就是采用堆实现的,因此在Java的领域中,我们可以认为堆就是优先队列,优先队列也就是堆,换个场景的话就不太行了。
堆的构成过程
使用数组构建堆时,就是按照层次将所有元素依次放入二叉树中,使其成为二叉树,然后再不断的调整,最终使其符合堆的结构。
这里我们先假设一个节点下标为 i:
- 当 i == 0 时, 为根节点。
- 当 i >= 1 时, 父节点为 (i - 1) / 2;
size 就是元素的个数,从 1 开始计数。
下面就看一下怎么建立一个大顶堆:
将元素依次排到完全二叉树节点上,如左图所示:
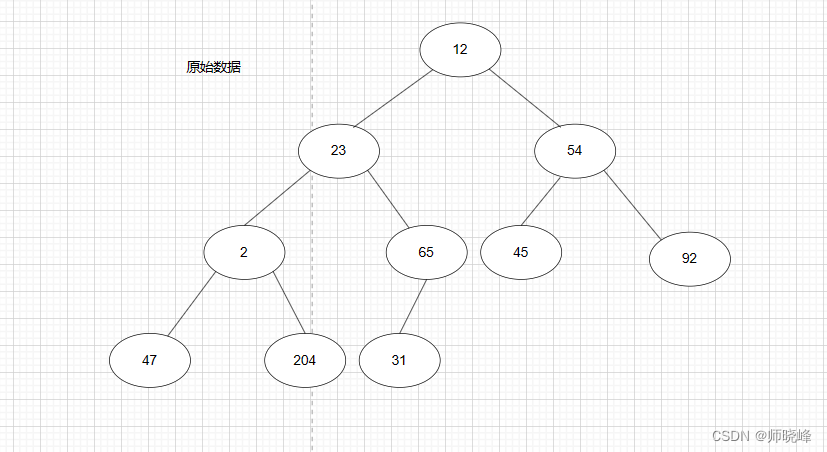
- int i = (size - 2) / 2 = 4 (思考这里为什么使用 size - 2 而不是size - 1)。 找到数组下标 4
号,65 大于取其孩子,满足大顶堆的性质,不用交换。如下图:
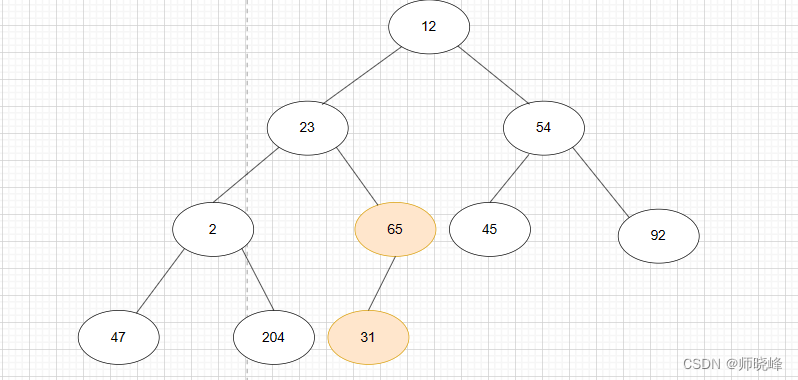
- 然后 i = i- 1;然后用 2 和其他孩子比较, 2 和 204 交换。交换之后 204 所在的子树满足大顶堆,如下图所示:
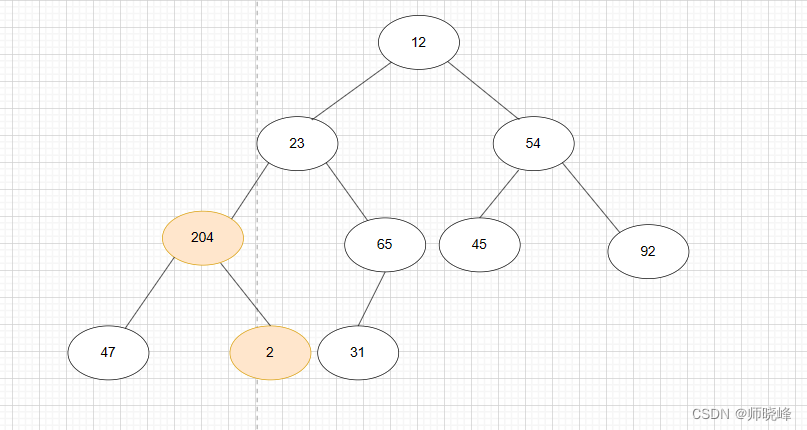
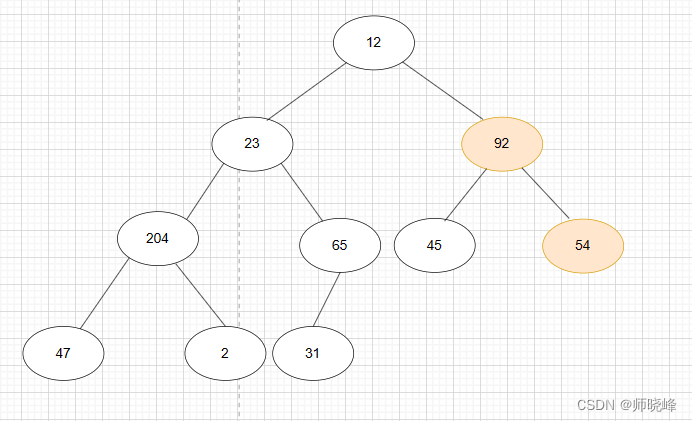
- 54 和其他孩子比较,54 和 92 交换,此时92 所在子树满足大顶堆,如下图:
-
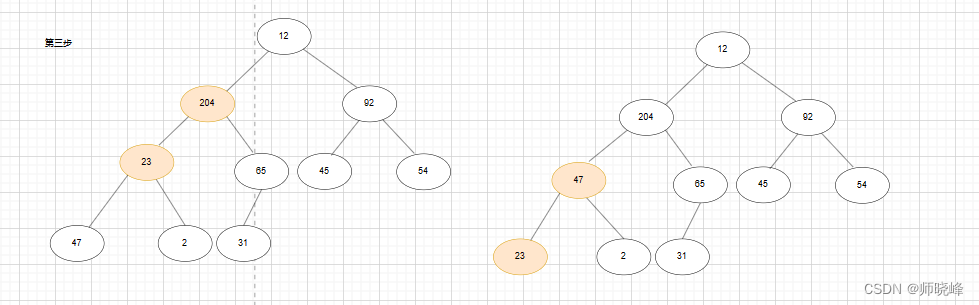
继续,23 和其他孩子比较,23 和 204 交换,交换完之后,23 的子树却不满足了需要再调整如下图:
-
12 和 204 交换,然出现不平衡的情况,依次类推,知道根节点也满足要求就完毕了。
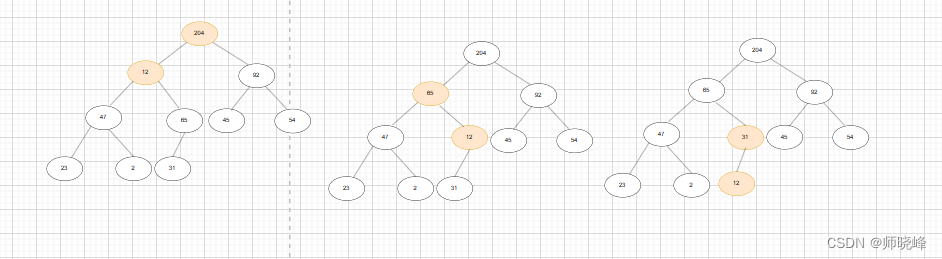
这样我们就建好了一个大顶堆,从图中可以看到,根元素是整个树中值最大的那个,二第二大和第三大就是其左右子树,具体那个更大是未知数,需要比较一下才知道。
另外,对于同一组数据,如果输入的序列不一样,最终的构造的树是否也会不一样呢?非常有可能,那么这样的树有什么意义呢?我们再往后面看看你,这里你已经理解怎么构建了对吧。
插入操作
从上面可以看到根节点和其左右节点是堆的老大老二老三,其他节点则是没有太明显的规律,那么如果要插入一个新的元素呢,该怎么办?直接说规则了:
将元素插入到保持其完全二叉树的最后一个位置,然后顺着这支一直向上调整,每前进一层就要保证其他子树都满足堆的要求,否则去调整子树,直到全部满足要求。
看一个例子,如下图,要插入 300 ,我们将其插入到 31的右孩子位置,然后不断向上爬, 31 < 300 ,所以两者需要交换,再向上 300 比 65 大,所以两者也要交换。最后 300 比根元素 204 大,两者也要交换,最后得到了新的堆。完整的过程如下:
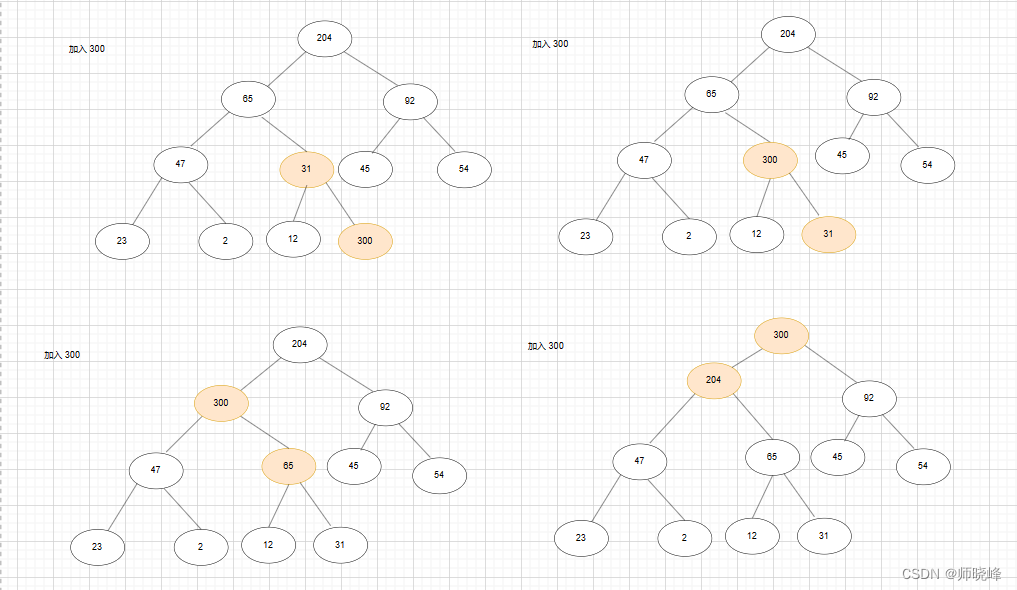
删除操作
堆本身比较特殊,一般对堆中的数据进行操作都是针对堆顶的元素,即每次都从堆中获取得到最大或者最小值,其他得不关心,所以我们删除得时候,也删除堆顶元素。如果直接删掉堆顶,整个结果被破坏,群龙无首。所以实际策略是先将堆中最后一个元素,(假如为A)和堆顶元素进行替换,然后再删除堆中最后一个元素,之后再从跟开始逐步与之左右比较,谁得更大谁上位。然后A再继续与子树比较,如果有更大得继续交换,直到自己所在得子树也满足大顶堆得要求。
(上面得过程可以理解为:皇帝突然驾崩了,然后先找个顾命大臣维持局面,大臣先看看那个皇子更强大,谁就是老大。然后大臣就逐步隐退,找到属于自己得位置)
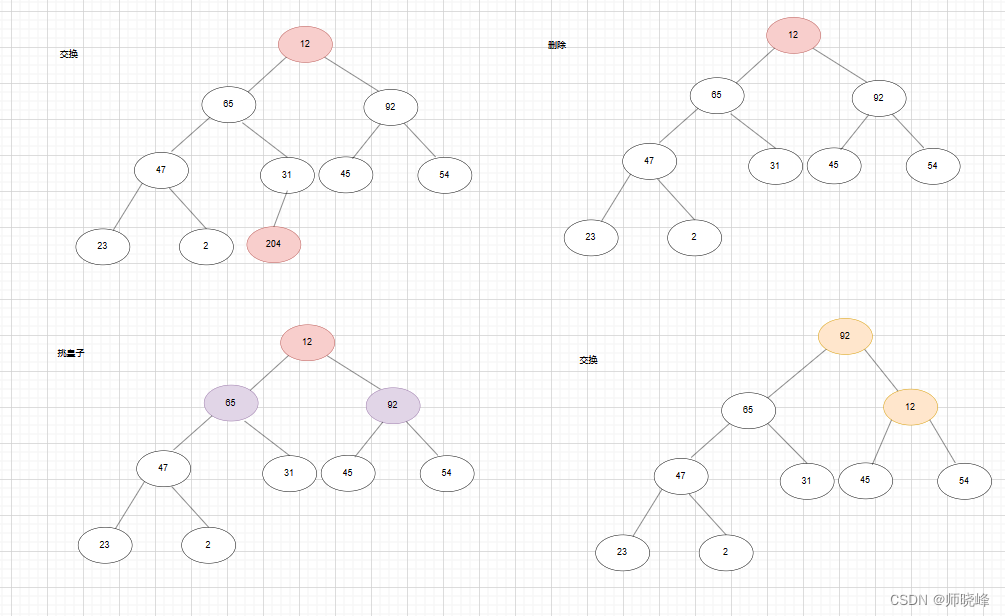
最后调整一下位置,满足堆得性质:

说了这么多,你觉得他得价值再哪里呢?价值在于大顶堆得根节点是整个树最大得那个,增加时会根据根得大小来决定要不要加,而删除操作只删除根元素。这个特征可以再很多场景下有巧妙得应用,后面得算法题目大多都是基于此得。
这里可能有很多人有疑问,感觉不管时插入还是删除,堆得操作都不简单,那么为什么还说堆得效率比较高呢?
这是因为堆元素得数量时有限制得,一般不用将所有得元素都放入堆里。后面题目中可以看到这些,在序列中找K大,则堆得大小就是k。如果K个链表合并,那么堆就是K。原理后面再展开详细展开。
说了这么多堆得性质了,我们来看看堆是怎么解决问题得。关于堆得问题,记住这里(我有秘法传于世间💕:
查找:找大用小,大的进;找小用大,小的进。
排序:升序用小,降序用大。
查找的方法就是:找 k 大, 则用小顶堆,后序的数据只有比根元素更大时才允许进入堆。如果找 k 小,则反过来。这我们后面接着分析。留个疑惑。
总结
提示:堆结构;堆的特性;堆的构造;堆的插入操作;堆的删除操作:
如果有帮助到你,请给题解点个赞和收藏,让更多的人看到 ~ ("▔□▔)/
如有不理解的地方,欢迎你在评论区给我留言,我都会逐一回复 ~
也欢迎你 关注我 ,喜欢交朋友,喜欢一起探讨问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











