






第一部分 语法基础篇
第1章 概述
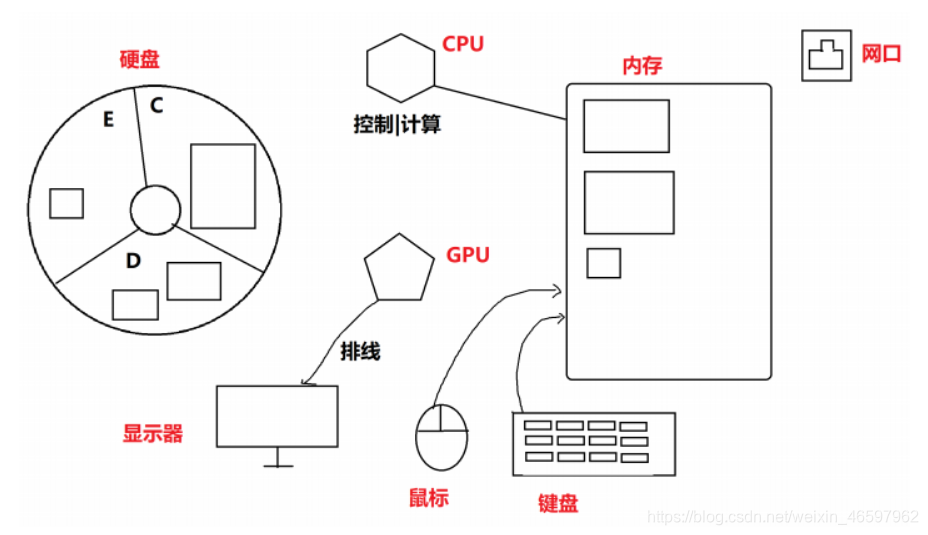
1.1 计算机组成部分
计算机的组成主要分为两大类:硬件,软件
硬件是可以看的到的一些物理部分,都是一些电子元器件
软件是看不得到的部分,它是一些列的指令,这些指令主要用于控制硬件来完成一些列特定的工作 常见的硬件:
- CPU:Center Processing Unit 中央处理器 主要指令控制和数值计算功能(日常工作任务)
- 内存:临时性存储数据的存储设备RAM,当内存不通电的时候,这数据也就消失了
- 显卡GPU:Graphic Processing Unit 图形图像处理单元 主要用于计算图形数据(图形图像任 务)
- 存储设备:永久性存储设备ROM 任何数据都是以二进制的形式存储的
- 机械硬盘
- 固态硬盘
- U盘
- 光盘
- 移动硬盘
- 输入输出设备
- 键盘:输入字符数据
- 鼠标:输入定位数据
- 显示器:输出图形图像数据
- 扬声器:输出声音数据
- 麦克风:输入声音数据
- 打印机:输出图形图像文本数据
- 扫描仪:输入图形图像文本数据
- 网络设备
- 输入:从互联网上下载数据
- 输出:从本地上传数据到互联网
1.2 人机交互方式
我们如何与计算机打交道的
- 图形化界面操作方式:操作简单,表现直观,容易上手操作,步骤繁琐,占用空间大
- 命令行操作方式 CMD(Command win+R 输入cmd回车)窗口:操作复杂,命令较多,不容易 上手,步骤简单,占用空间小,适合远程操作
常用dos命令
- c: 进入C盘根目录
- d: 进入D盘根目录
- cd xxx 进入xxx目录
- dir 查看当前目录下有什么文件和目录
- cd / 进入到当前所在盘符的根目录
- cd … 返回上一级目录
- cls 清屏
- exit 退出cmd窗口
1.3 计算机语言
计算机本身就是有一系列物理硬件组成的,它们之间的沟通方式就是电信号,高低电压-二进制数据
所以和计算机之间打交道,就得通过二进制来做,早期的编程语言/命令都是以二进制形式存在
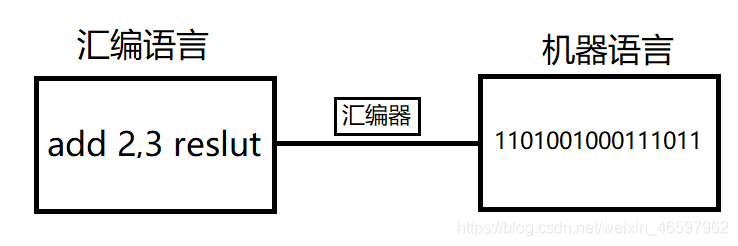
机器语言
根据平台的不同其所表现的形式也不同,为了让计算机能够懂得人类的目的,人类必须以二进制的 形式向计算机输入数据。计算机能懂,人不太懂,对初学者十分不友好的。比如要计算两个数字的加法
1101001000111011
汇编语言
通过一些单词也叫助记符,将一些常用的操作用单词表示,在程序中慢慢出现了人类的语言。比如 计算2+3的结果,在汇编语言里是以下结果。这种代码计算机读不懂,还得将这些助记符包括数据转换 成对应的二进制提交给计算机进行计算。转换的工具,称之为汇编器。汇编语言它的计算方式,还是依 赖于计算机的计算方式的。想学好汇编语言,还得事先了解计算机的工作原理。
add 2,3 reslut
高级编程语言
从20世纪50年代产生,第一个众所周知的高级编程语言:C语言->C++语言->Java语言->C#-Python 高级编程语言完全由单词,符号和数字组成,并且书写流程也是符号人类流程。比如计算2+3如下 代码所示,更容易让人类去理解。同样计算机不能够读懂这段代码,还得将代码进行转换二进制提交给 计算机。转换的形式:编译,解释
int a = 2 + 3;
- 静态编译语言:
- C C++ Java 静态:在定义变量的时候有明确的数据类型的区分
- 编译:将源代码全部进行编译 生成一个可执行的二进制文件 计算机去执行这个二进 制文件来运行程序。
- 动态解释语言:Python JS
- 动态:在定义变量的时候没有明确的数据类型的区分
- 解释:将源代码从头到尾 读取一行 编译一行 运行一行
1.4 软件与软件开发
软件的定义
软件是指一系列按照特定顺序组织的计算机数据与指令的集合
说明:再用编程去解决一个问题的时候,先去获取该问题所需要的数据,然后再根据数据讨 论计算的具体流程,最后再用编程语言去实现这个计算的流程
软件的分类
分为两类:
-
系统软件:也称之为是操作系统,主要是用来控制和管理底层硬件的一套指令,操作系统为用 户提供最基本的计算机功能。
-
应用软件:基于系统软件之上的,为用户带了特定领域服务的软件
软件开发
软件开发的定义就是去编写上述软件,软件开发的流程是什么?
- 需求分析
- 编码实现
- 测试编码
- 上线运维
- 更新迭代
- 下线
软件岗位
- 移动端软件研发 Anroid IOS - 物联网
- Web前端研发 - 数据可视化工程师
- PC端研发
- 后端研发
1.5 Java语言介绍
Java语言的前身Oak(橡树),1994年詹姆斯高斯林和他的团队开发出来的嵌入式编程语言。随着 互联网的发展,紧随潮流编程互联网应用程序开发语言(面向对象),一直到2010年Sun公司被Oracle 收购,Java就属于Oralce的子产品。
Oracle公司主要业务:
- 数据库 Oralce数据库 随后也把民间产品MySQL也收购了
- Linux服务器操作系统Solaris(redhat Ubuntu 深度 SUSE)
- 编程语言Java
Microso公司主要业务:
- SQL Server
- Windows/Windows Server
- C++/C#
Java技术架构
- JavaSE Java Standard Edition Java标准版:桌面型应用程序
- JavaEE Java Enterprise Edition Java企业版:服务器应用程序
- JavaME Java Micro Edition Java微型版:嵌入式应用程序
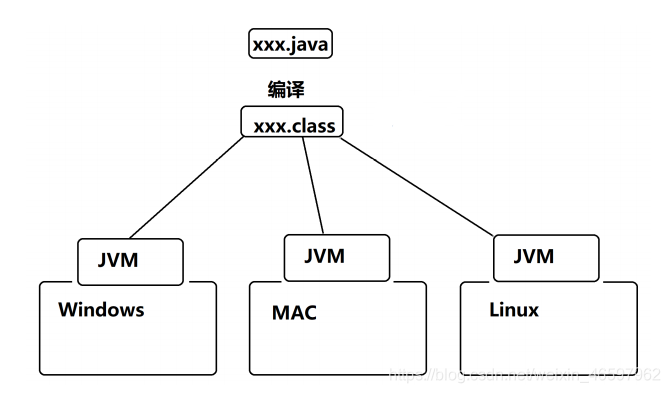
Java最大的特点——跨平台
跨平台的意思就是说,一个软件可以在多个平台上运行,而不用更改软件的内容。
是因为JVM的功劳:JVM(Java Virtual Machine)Java虚拟机。
Java源代码文件后缀名为xxx.java 所编译出来的二进制文件后缀名为xxx.class
JVM主要负责将java语言的字节码文件转换为本地操作系统指令的一个工具软件。
所以,最终是字节码文件在跨平台!
1.6 Java开发环境搭建
JRE与JDK
JRE(Java Runtime Environment)Java运行环境:如果我们的计算机仅仅想运行Java程序的话,装 这个软件即可。JRE = JVM + 核心类库。
JDK(Java Development Kit)Java开发工具包:如果我们的计算机想要去开发一个Java程序的话, 装这个软件即可。JDK = 开发工具 + JRE。
JDK的下载与安装
-
先登录注册Oracle
-
去Oralce官网下载JDK,最新JDK15,我们目前用JDK8 https://www.oracle.com
-
点击Products
-
点击SoWare下的Java
-
右上角DownloadJava
-
找到JavaSE8 点击JDK Download
-
下拉 在下载列表中选择Windows X64
-
双击打开jdk安装程序
-
点击下一步
-
JDK不需要更改目录 直接下一步
-
JRE不需要更改目录 直接下一步
-
安装完成 点击关闭即可
-
验证jdk是否安装成功
-
win+r 打开cmd 输入
java -version
java version "1.8.0_77"
Java(TM) SE Runtime Environment (build 1.8.0_77-b03)
Java HotSpot(TM) 64-Bit Server VM (build 25.77-b03, mixed mode)
jdk安装目录介绍
-
bin目录:binary放的都是开发工具
- javac.exe:java编译工具
- java.exe:java运行工具
-
db目录:放的是支持数据库开发的一些工具包
-
include目录:放的是一些链接底层的一些C头文件代码
-
jre目录:jdk自带的运行环境 lib目录:
-
library 存放的是一些第三方Java库
-
javafx-src.zip:javafx图形化界面开发的源码包
-
src.zip:Java本身的源代码包
配置path环境变量
- 复制jdk中bin目录的绝对地址 C:\Program Files\Java\jdk1.8.0_77\bin
- 右键此电脑 点击属性
- 点击高级系统设置
- 点击环境变量
- 系统变量中选择Path
- 右上角 新建 将地址复制进去即可
- 一路确定出去
- 重启cmd 再去尝试javavc java
1.7 运行Java程序
VSCode代码编辑器 https://code.visualstudio.com/
汉化:左下角管理 Extension 搜索Chinese 选择Chinese中文简体汉化包 点击绿色install 右下角提示 重启 重启即可
主题:管理 颜色主题 自选
编码:管理 设置 文本编辑器 文件 Encoding 选择gbk结尾
字体:管理 设置 文本编辑器 字体 font size
关联代码所在的文件夹:文件 打开文件夹 选择JavaDay01
步骤一:新建Java源代码文件并写入类
点击新建文件按钮,输入Java源代码文件名称和后缀名,例如Sample01.java
在文件中写入如下代码:
步骤二:编译该源代码文件
打开控制台窗口cmd,将目录切换到JavaDay01目录下
再输入 javac Sample01.java 对源代码文件进行编译
如果没有任何输出,则表明编译成功,并生成同名的字节码文件 Sample01.class
步骤三:运行该字节码文件
输入 java Sample01 即可
1.8 常见错误
语法错误
指在编译的过程中出现的一些错误,这种错误的原因主要由那些因素产生呢?
- 单词评写
- 遗漏分号
- 使用中文符号的问题
- 大括号不匹配
- 遗漏关键字单词
运行错误
是指编译能够通过,但是在运行期间出现的问题
逻辑错误
代码的运行结果和自己认为的结果不一样!
**遗漏括号 **
**遗漏分号 **
遗漏引号
**非法使用中文符号 **
单词拼写错误
第2章 基本数据与运算
2.1 关键字
关键字是指被高级编程语言赋予特殊含义的一些单词,关键字一般都是由小写字母组成。好比是汉 语当中的一些专有名词:北京,天安门,兵马俑。不能乱用。
- 用于定义数据类型的关键字:byte short int long float double char boolean void class interface
- 用于定义数据类型值的关键字:true false null
- 用于定义流程控制语句的关键字:if else switch case default while do for break continue return
- 用于定义访问权限修饰符的关键字:public protected private
- 用于定义继承关系的关键字:extends implements
- 用于定义实例对象的关键字:new this super instanceof
- 用于定义函数类型的关键字:static final abstract synchronized
- 用于处理异常的关键字:try catch finally throw throws
- 用于包的关键字:package import
- 其他的一些修饰关键字:native assert volatile transient
2.2 标识符
标识符指的是我们在程序中对变量、函数、类、接口、常量所定义的名称,也就是说这些名称是我 们自定义的。
标识符必须满足以下组成规则:
- 标识符可以由数字、字母、下划线 _ 、美元符 $ 组成
- 标识符不能以数字开头,当然下划线和美元符其实是可以开头的,但不推荐
- 标识符不能是关键字
- 标识符也不能是Java内置类的名称
- 标识符可以为任意长度,但必须是一个连续的词
- 标识符严格区分大小写
标识符命名的规范:
- 大驼峰式:主要针对类名,接口名。所有单词的首字母大写
- 小驼峰式:主要针对于变量名,函数名。除了第一个单词之外,其他单词首字母大写
- 常量规范:所有单词字母大写,单词与单词之间用下划线
_分隔 - 包名规范:所有单词字母小写,单词与单词之间用句号
.分隔
2.3 注释
注释是用于注解和说明程序的一些程序中的内置文本信息的,但这些内置文本不属于代码的范畴。 所以在对含有注释的源代码进行编译时,所生成的字节码中不含有注释。注释给人看的!
注释主要有三种:
- 单行注释
//注释内容直到换行为止 - 多行注释
/* 注释内容 内部可以进行换行 */ - 文档注释
/** 注释内容 内部可以进行换行 */:文档注释可以被编译器识别,并生成相应 的程序说明书。对某一个类进行文档生成时,该类必须是public型
2.4 常量与进制
常量就是指在程序中直接出现的一些数据,也叫字面量
常量都有哪些:
- 整数常量
- 小数常量
- 字符常量:由一个字母、数字、符号被单引号
( '' )标识的数据 - 字符串常量:由若干个字母、数字、符号被双引号
( "" )标识的数据 - 布尔类型常量
- null常量
2.5 变量
指的是变化的量
- 变量的本质就是在内存中程序所处的进程中的一个临时存储区域
- 该区域的存储值有限制的
- 该区域值的变化必须是同类型的或向下兼容的
- 该区域有其自身的物理内存地址-指针
该区域中 存储值的限制 和 数据的变化类型 由 数据类型 来决定
该区域中 其空间的分配 和 空间的物理内存地址 由计算机底层来决定
2.6 数据类型
在Java当中,数据类型主要分为两大类:
- 基本数据类型:在变量的空间中存储数据
- 整型
- byte 1字节 2^8 256 -128~127 -2^7 ~ 2^7 - 1
- short 2字节 2^16 65536 -32768~32767 -2^15 ~ 2^15 - 1
- int 4字节 long 8字节
- 浮点型
- float 4字节
- double 8字节
- 字符型
- char 2字节
- 布尔型
- boolean 不确定
- 整型
- 引用数据类型:数据是在堆内存中存储,变量仅仅存放的是数据在堆内存中的地址
- 字符串
- 数组
- 对象
2.7 运算符
算术运算符
| 算数运算符 | 含义 | 备注 |
|---|---|---|
| + | 加法 | 如果加号左右有字符串 则加号为连接符 |
| - | 减法 | |
| * | 乘法 | |
| / | 除法 | 如果除号两边都是整数 结果为整数;有小数 结果为小 数 |
| % | 取余 | |
| a++ | 后置自增 | a自身加一,使用原来的值 |
| ++a | 前置自增 | a自身加一,使用加之后的值 |
| a– | 后置自减 | a自身减一,使用原来的值 |
| –a | 前置自减 | a自身减一,使用加之后的值 |
赋值运算符
+=-=*=/=%=
比较运算符
运算的结果为布尔类型
<大于<小于>=大于等于<=小于等于!=不等于
逻辑运算符
&单与|单或^异或!非&&双与||双或
&& 如果左边为假 则右边不用执行
|| 如果左边为真 则右边不用执行
位运算符
&位与|位或^位异或>>右移<<左移
三目运算符
数据类型 变量名 = 布尔表达式?值1:值2;
2.8 常见错误
未声明变量,未初始化变量而使用变量
整型溢出问题
取整错误
一个是小数的问题,小数主要去的是近似值 想要得到一个0.5这个值的话 有可能会得到0.4999999
一个是整数的问题,1/3 = 0.3333 * 3 = 0.99999 数学上1
超出预期的除法问题
/左右两边是整数,结果为整数,如果出现小数则结果为小数
额外冗余的输入对象
第3章 流程控制语句
3.1 if条件语句
单分支if语句
...CodeA
if (布尔表达式) {
语句组;
}
...CodeB
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZpjYtZmg-1610689755742)(C:\Users\10690\AppData\Roaming\Typora\typora-user-images\image-20210115133107377.png)]](https://i-blog.csdnimg.cn/blog_migrate/dbd3dfe4b9700c9a32d0437550ea7330.png)
双分支if-else语句
...CodeA
if (布尔表达式) {
语句组A;
} else {
语句组B;
}
....CodeB
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HGXGOtqF-1610689755750)(C:\Users\10690\AppData\Roaming\Typora\typora-user-images\image-20210115134036946.png)]](https://i-blog.csdnimg.cn/blog_migrate/068b9058593e52984fec1269b9e93e99.png)
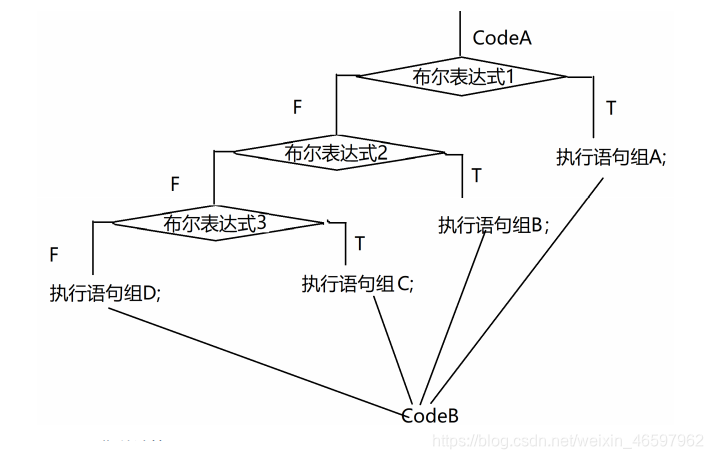
多分支if-else-if语句
...CodeA
if (布尔表达式1) {
语句组A;
} else if (布尔表达式2) {
语句组B;
} else if (布尔表达式3) {
语句组C;
} else {
语句组D;
}
...CodeB
3.2 switch分支语句
与if分支语句一样,都是对条件的判断。switch一般用在条件较多的情况下,但是有一个重要的细节 及时,if语言可以对区间值或固定值进行判断,switch只能对固定值进行判断。
switch (变量) {
case 值1: //if (变量==值1) {语句组A;}
语句组A;
break;
case 值2:
语句组B;
break;
...
case 值n: //if (变量==值n) {语句组N;}
语句组N;
break;
default: // else {语句组N+1;}
语句组N+1;
break;
switch的一些使用细节
- switch所传入的变量,char,byte,short,int,String或者枚举类型
- 值1,值2,一直到值n,这几个值必须是同一个数据类型的
- 当变量匹配的相关case的值的时候,执行case中的语句,直到遇到break结束;如果该case语句 中没有break,则继续向下执行,直到遇到另外一个break结束
3.3 for循环语句
循环主要解决具有规律性的且具有重复性的代码问题,避免程序冗余
循环四要素
- 1循环的初始化:循环的第1次执行从哪里开始
- 2循环的继续条件:循环从当前轮是否向后执行下一轮
- 3循环体:需要被循环执行的部分
- 4循环的步长、周期:当前循环到下一轮循环之间的变化
我们常见的循环问题可以分为两大类:
- 已知循环次数的 一般用for语句做
- 未知循环次数但是已知循环结束条件 一般用while语句做
for (1循环的初始化;2.循环的继续条件;4.循环的步长) {
3.循环体
}
//执行步骤:1-2-3-4-2-3-4-2-3-4-2不满足则结束循环
3.4 while循环语句
while循环主要用于解决循环次数未知,但循环结束条件已知的情况。
while其实和for循环是可以相互转换的,是因为都逃不开循环四要素
while的语法格式
1.循环的初始化
while (2.循环继续条件) {
3.循环体
4.循环的步长、周期
}
3.5 break、continue跳转语句
break在循环语句中叫做终止语句,终止的是break最近的一层循环
continue在循环语句中叫做跳过语句,跳过本次循环开启下一轮循环
第4章 常用类
4.1 Msth类
Math类是用于数学计算的工具类
大部分成员都是静态的static
常量
自然对数: static double E
圆 周 率: static double PI
取整
向上取整: static double ceil(double a)
使用说明:
number = Math.ceil(3.1);
向下取整: static double floor(double a)
使用说明:
number = Math.floor(3.1);
四舍五入: static long round(double a)
使用说明:
number = Math.round(3.1);
三角函数
返回值均为double型近似值
参数为弧度值
正弦函数、余弦函数、正切函数:
static double sin、cos、tan(double a)
使用说明:
number = Math.sin(Math.PI/6);
反正弦函数、反余弦函数、反正切函数:
static double asin、acos、atan(double a)
使用说明:
number = Math.asin(Math.PI/6);
弧度转角度:static double toDegrees(double a):
使用说明:
number = Math.toDegrees(Math.PI/6);
参数为角度值
角度转弧度:static double toRadians(double angles)
使用说明:
number = Math.toRadians(60);
指数函数
a的平方根:static double sqrt(double a)
使用说明:
number = Math.sqrt(2);
a的立方根:static double cbrt(double a)
使用说明:
number = Math.cbrt(2);
a的b次幂:static double pow(double a, double b)
使用说明:
number = Math.pow(2,3);
其他
a的绝对值:static double abs(double a)
使用说明:
number = Math.abs(-2);
两点间距离:static double hypot(double deltX, double deltY)
使用说明:
number = Math.hypot(0 - 1, 0 - 1);
两数最大值、最小值:
static double max、min(a,b)
使用说明:
number = Math.max(1, 2);
[0,1)之间的随机小数:static double random()
使用说明:
number = Math.random();
4.2 Scanner类
使用时需导入Scanner包
import java.util.Scanner;
主要用于负责数据输入得类
获取字符串
遇到空格结束:String next()
使用说明:
String line = input.next();
遇到回车结束:String nextLine()
使用说明:
String line = input.nextLine();
获取整数
buyte型、short型、long型、int型:
buyte nexBuyte()
short nexShort()
long nexLong()
int nexInt ()
获取boolean型数据:
boolean nexBoolean()
获取浮点型数据
获取float型数据:float nexFloat()
获取double型数据:double nexDouble()
使用说明:
double x1 = input.nextDouble();
4.3 Random类
主要用于生成随机数
生成布尔值:boolean nexBoolean()
使用说明:
number = random.nextBoolean() ;
生成0.0~1.0之间的小数:double nexDouble()
使用说明:
number = random.nextDouble() ;
生成0~2^32的整数:int nextInt()
使用说明:
number = random.nextInt() ;
生成[0,n)的整数:int nextInt(int n)
使用说明:
number = random.nextInt(6) ;
4.4 String类
String是一个类,它描述的是字符串。在Java代码当中,所有字符串常量都是 String类的一个实例对象。并且,字符串一旦创建,则不可修改!不可修改其长度,不可修改其内容。所 以将来对字符串内容的改变,不能在原地改,只能重新创建一个字符串。
使用时需导入Random包
import java.util.Random;
获取相关
char charAt(int index):获取指定角标index处的字符
int indexOf(int ch):获取指定字符(编码)在字符串中第一次(从左到右)出现的地方返回的是 角标。如果是-1 表示不存在
int lastIndexOf(int ch):获取指定字符(编码)在字符串中第一次(从右到做)出现的地方返回的 是角标
int indexOf(String str):获取指定字符串在本字符串中第一次(从左到右)出现的地方返回的是 角标
int lastIndexOf(String str):获取指定字符串在本字符串中第一次(从右到左)出现的地方返回 的是角标
int length():获取字符串的长度(字符的个数)
String[] split(String regex):将字符串按照regex的定义进行切割(regex指的是正则表达式)
String substring(int beginIndex):截取一段子字符串,从beginIndex开始到结尾
String substring(int beginIndex, int endIndex):截取一段子字符串,从beginIndex开始到 endIndex(不包含)
判断相关
int compareTo(String anotherString):按照字典顺序比较两个字符串的大小
boolean contains(String another):判断当前字符串中是否包含指定字符串another
boolean equals(String another):比较当前字符串与指定字符串的内容是否相同
boolean isEmpty():判断当前字符串是否为空,length() == 0
boolean startsWith(String prefix):判断该字符串是否以prefix开头
boolean endsWith(String suix):判断该字符串是否已suix结尾
修改相关
String toLowerCase():将字符串中所有的英文字母全部变为小写
String toUpperCase():将字符串中所有的英文字母全部变为大写 String trim():将字符串中两端的多余空格进行删除
String replace(char oldCh,char newCh):将字符串中oldCh字符替换成newCh字符
import java.util.Random;
public class Sample {
public static void main(String[] args) {
String str = "banana orange apple watermelon";
System.out.println(str.charAt(1)); //'a'
System.out.println(str.indexOf('o')); //7
System.out.println(str.lastIndexOf(97));//21
System.out.println(str.length());
System.out.println(str.substring(6));
System.out.println(str.substring(9,13));
String[] arr = str.split(" ");
System.out.println(arr[2]);
String s1 = "abc";
String s2 = "abe";
System.out.println(s1.compareTo(s2));
//结果<0 s1在s2之前 ==0 s1和s2一样 >0 s1在s2之后
System.out.println("hehe".compareTo("hehe"));
System.out.println("abcbc".contains("bcb"));
System.out.println("lala".equals("lala"));
String s3 = "abcdef";
System.out.println(s3.endsWith("def"));
System.out.println(s3.startsWith("abc"));
String s4 = "Happy Boy Happy Girl";
System.out.println(s4.toLowerCase());
System.out.println(s4.toUpperCase());
System.out.println(s4);
System.out.println(" 123123 321321 ".trim());
String s5 = "旺财是只狗";
System.out.println(s5.replace('狗','猫'));
System.out.println(s5.replace("旺财","小强"));
}
}
4.5 Character类
Character它是char基本数据类型的 包装类 ,有这么几个静态方法我可目前可以使用到的
static boolean isDigit(char ch):判断字符是否是数字
static boolean isLetter(char ch):判断字符是否是字母
static boolean isLetterOrDigit(char ch):判断字符是否是数字或字母
static boolean isLowerCase(char ch):判断是否是小写字母
static boolean isUpperCase(char ch):判断是否是大写字母
static boolean isSpaceChar(char ch):判断是否空白字母(空格 制表符 回车)
第5章 函数
5.1 函数的概念
函数是指一段具有独立功能的代码。
目的是减少代码冗余,提高程序的利用率和效率。
函数的定义
需要一个封闭的空间,将这段独立性的代码进行封装,使用一对大括号
需要对每一个封闭的空间进行命名,定义函数名
函数所需要的一些原始数据,参数
函数所产生的一些结果数据,返回值
语法格式
修饰符 函数类型 返回值类型 函数名(数据类型 数据1,数据类型 数据2,...) {
独立功能的代码片段;
return 函数的计算结果;
}
修饰符:指的是函数的访问权限,public private 默认 protected
函数类型:函数的分类,本地函数native,静态函数static,同步函数 synchronized
返回值类型:指的就是函数计算结果的数据类型 如果函数没有返回值 则为void
函数名:就是函数的名称
参数列表:指的是外界向函数传入的数据(实际参数),由这些参数变量进行接收(形式参 数)
函数体:具有独立功能的代码片段;
return:表示函数结束!如果函数有返回值,则return后跟返回值;如果没有返回值,则 return可以不写,但是是存在的(隐藏的 在最后一行)
根据形参和返回值函数可分为以下几个分类
有参数有返回值
有参数无返回值
无参数有返回值
无参数无返回值
总结定义函数时需要考虑的内容
明确参数和结果
函数需要哪些参数,它的类型。
函数的结果是否需要返回
明确内容和返回
函数要实现的功能
函数要返回的内容,及它的类型
5.2 函数的运行原理
函数的运行是基于栈运行的
栈:是一种先进后出的容器,我们这里面所说的栈是指JVM中的栈内存空间
每一个函数,叫做栈帧,栈帧中所包含的内容有函数的定义,参数列表,函数的执行内容代码
每一个函数要运行,就相当于这个栈帧进入到栈内存中 即 入栈
如果一个函数即将结束,将这个栈帧从栈顶移出 即 出栈
如果栈内存中有多个栈帧,运行的是最上面的栈帧,底下的栈帧暂停运行,直到该栈帧为栈顶元素
5.3 函数重载
同一个类中可以出现多个同名函数,这个现象就叫做函数的重载(overload)
如何来区分同名函数是否是重载关系呢?前提必须是同名,和返回值类型无关(返回值类型只和函 数的计算功能相关),和权限也没有关系,和形式参数的名称也无关!只和形式参数的数据类型有关
public static void show(int a ,float b ,char c){}
//下列哪些是该函数的重载:
int show(int x, float y, char z){} //不算重载 数据类型都是int float char
void show(float b,int a,char c){} //算重载,顺序不一样float int char
void show(int a,int b,int c){} //算重载,顺序不一样int int int
double show(){} //算重载,参数不一样
寻找重载函数的流程:
- 看是否有确切的参数定义匹配,int int 找 int int
- 是否有可兼容的参数定义匹配,int int找double double或int double或double int
- 如果可兼容的参数定义匹配较多,会报引用确定报错 引用不明确
5.4 函数的递归
函数的递归就是指函数自身调用自身。
但凡迭代能够解决的问题,递归都可以解决;递归能够解决的问题,迭代不一定可以解决
相对而言,从内存的角度而言,函数如果过多的自我调用,势必会对内存不友好,会占用过多内存
通常来讲,同样的问题用递归写要比用迭代写代码量较少
写递归时,一定要先确定递归结束条件-递归边界
迭代的,数学归纳法的问题可以使用递归
第6章 数组
6.1 数组的概念及定义
数组主要用于解决大量数据计算与存储的问题
比如:输入100个数字,统计其中的最大值和最小值并计算平均值,创建100个变量,会有一堆if-else语句,比较麻烦。
数组是Java提供的一种最简单的数据结构,可以用来存储一个元素 个数固定 且 类型相同 的有序集合。
数组在内存中的情况
栈:主要用于运行函数的内存
堆:主要用于存储数据对象的内存
每一个数组而言,都是存在堆内存当中,每一个数组都是一个对象
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WOeiMmMQ-1611295459309)(C:\Users\10690\AppData\Roaming\Typora\typora-user-images\image-20210121171135764.png)]
数组本质上就是在堆内存中一系列地址连续且空间大小相等的存储空间(变量),每一个存 储空间用来存储数据(基本,引用)
数组是在堆内存中存储,称之为是一个对数对象,并且在堆内存中存储的数据都有默认初始化的流程。所以数组创建之初,每一个存储空间里面都会被JVM初始化该数据类型对应的零值。
数组的地址是连续的,所以通过公式:An=A1+(n-1)*d可以快速访问到其他的元素,所以对于 数组而言查找元素比较快的。将元素的真实物理地址转换成对应的角标获取元素。
通过一个变量存储该数组在堆内存当中的首元素的地址调用数组。
当数组一旦定义出来,其长度不可变,存储空间的内容是可变的
我们在定义数组的时候,要么把长度固定,要么直接输入相关的元素。
数组的定义方式
//创建一个指定长度且指定数据类型的一维数组,名称为数组名,虽然没有指定元素,但是会有默认值
数据类型[] 数组名 = new 数据类型[长度];
//创建一个指定元素且指定数据类型的一维数组,名称为数组名,虽然有指定元素,还是有默认初始化这个步骤的!
数据类型[] 数组名 = new 数据类型[]{数据1,数据2,...,数据n};
//简写
数据类型[] 数组名 = {数据1,数据2,...,数据n};
6.2 常用数组操作
数组遍历问题
public class Sample {
public static void main(String[] args) {
int[] arr = new int[]{1,2,3,4,5,6,7,8,9};
//String str str.length()-函数
//int[] arr arr.length-属性
for (int i = 0; i < arr.length; i++) {
arr[i] = arr[i] * 10;
System.out.println(arr[i]);
}
//通过角标遍历 可以在遍历的过程中对指定的元素进行修改
//foreach遍历 主要针对的是一些可迭代对象 Iterable
/*
for (数据类型 变量名 : 可迭代容器) {
}
*/
for (int num : arr) {
//num -> arr[i]
num = num / 10;
System.out.println(num);
}
//这种遍历方式 只能获取元素,不能修改元素
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}
}
数组最值问题
public class Sample {
public static void main(String[] args) {
int[] arr = new int[]{3,6,8,2,9,4,5,1,7};
int min = arr[0];
int max = arr[0];
for (int i = 1; i < arr.length; i++) {
if (arr[i] < min) {
min = arr[i];
}
if (arr[i] > max) {
max = arr[i];
}
}
System.out.println(max);
System.out.println(min);
}
}
数组扩容问题
public class Sample {
public static void main(String[] args) {
int[] arr = new int[]{1,2,3,4,5};
arr = add(arr,6);
arr = add(arr,6);
arr = add(arr,6);
arr = add(arr,6);
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}
//在指定的数组arr中添加元素element
public static int[] add(int[] arr, int element) {
int[] newArr = new int[arr.length + 1];
for (int i = 0; i < arr.length; i++) {
newArr[i] = arr[i];
}
newArr[newArr.length - 1] = element;
return newArr;
}
}
选择排序算法
选择排序是一种简单直观的排序算法,无论什么数据进去都是 O(n²) 的时间复杂度。所以用到它的时候,数据规模越小越好。唯一的好处可能就是不占用额外的内存空间了吧。
1. 算法步骤
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。
再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
重复第二步,直到所有元素均排序完毕。
2. 动图演示
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-m5a2PNNj-1611295459320)(D:\java\selectionSort.gif)]
<图片来源于菜鸟教程>
3.代码实现
public class Sample {
//选择排序
public static void main(String[] args) {
int[] arr = {8,9,2,6,7,1,4,5,3};
for (int i = 0; i < arr.length - 1; i++) { //-1 n个数字没有第n轮
for (int j = i + 1; j < arr.length; j++) {
if (arr[i] > arr[j]) {
swap(arr,i,j);
}
}
}
print(arr);
}
//[1, 2, 3, 4, 5]
public static void print(int[] arr) {
System.out.print("[");
for (int i = 0; i < arr.length;i++) {
System.out.print(arr[i]);
if (i == arr.length - 1) {
System.out.println("]");
} else {
System.out.print(", ");
}
}
}
public static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
冒泡排序算法
冒泡排序(Bubble Sort)也是一种简单直观的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢"浮"到数列的顶端。
作为最简单的排序算法之一,冒泡排序给我的感觉就像 Abandon 在单词书里出现的感觉一样,每次都在第一页第一位,所以最熟悉。冒泡排序还有一种优化算法,就是立一个 flag,当在一趟序列遍历中元素没有发生交换,则证明该序列已经有序。但这种改进对于提升性能来
说并没有什么太大作用。
1. 算法步骤
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
2. 动图演示
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PyybGhNi-1611295459326)(D:\java\bubbleSort.gif)]
<图片来源于菜鸟教程>
3.代码实现
public class Sample {
//冒泡排序
public static void main(String[] args) {
int[] arr = {8,9,2,6,7,1,4,5,3};
for (int i = 0; i <arr.length - 1; i++) {//-1 表示n个数字只有n-1轮
for (int j = 0; j < arr.length - 1 - i; j++) {//-1 避免重复比较(当前最大和上一轮最大)
if (arr[j] > arr[j + 1]) {
swap(arr,j,j+1);
}
}
}
print(arr);
}
public static void print(int[] arr) {
System.out.print("[");
for (int i = 0; i < arr.length;i++) {
System.out.print(arr[i]);
if (i == arr.length - 1) {
System.out.println("]");
} else {
System.out.print(", ");
}
}
}
public static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
插入排序算法
插入排序的代码实现虽然没有冒泡排序和选择排序那么简单粗暴,但它的原理应该是最容易理解的了,因为只要打过扑克牌的人都应该能够秒懂。插入排序是一种最简单直观的排序算法,它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
插入排序和冒泡排序一样,也有一种优化算法,叫做拆半插入。
1. 算法步骤
将第一待排序序列第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。
从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。)
2. 动图演示
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ahQZh84P-1611295459337)(D:\java\insertionSort.gif)]
<图片来源于菜鸟教程>
3.代码实现
public class Sample {
//插入排序
public static void main(String[] args) {
int[] arr = {8,9,2,6,7,1,4,5,3};
for (int i = 1; i < arr.length; i++) {
int e = arr[i];
int j = 0;
for (j = i; j > 0 && arr[j - 1] > e; j--) {
arr[j] = arr[j - 1];
}
arr[j] = e;
}
print(arr);
}
public static void print(int[] arr) {
System.out.print("[");
for (int i = 0; i < arr.length;i++) {
System.out.print(arr[i]);
if (i == arr.length - 1) {
System.out.println("]");
} else {
System.out.print(", ");
}
}
}
}
计数排序算法
计数排序的核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。
1、计数排序的特征
当输入的元素是 n 个 0 到 k 之间的整数时,它的运行时间是 Θ(n + k)。计数排序不是比较排序,排序的速度快于任何比较排序算法。
由于用来计数的数组C的长度取决于待排序数组中数据的范围(等于待排序数组的最大值与最小值的差加上1),这使得计数排序对于数据范围很大的数组,需要大量时间和内存。例如:计数排序是用来排序0到100之间的数字的最好的算法,但是它不适合按字母顺序排序人名。但是,计数排序可以用在基数排序中的算法来排序数据范围很大的数组。
通俗地理解,例如有 10 个年龄不同的人,统计出有 8 个人的年龄比 A 小,那 A 的年龄就排在第 9 位,用这个方法可以得到其他每个人的位置,也就排好了序。当然,年龄有重复时需要特殊处理(保证稳定性),这就是为什么最后要反向填充目标数组,以及将每个数字的统计减去 1 的原因。
算法的步骤如下:
- (1)找出待排序的数组中最大和最小的元素
- (2)统计数组中每个值为i的元素出现的次数,存入数组C的第i项
- (3)对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加)
- (4)反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1
2. 动图演示

<图片来源于菜鸟教程>
代码实现
public class Sample {
//计数排序
public static void main(String[] args) {
int[] arr = {-2,9,-1,12,8,-3,6,7,4,5,2,1,0,8,6,7,4,-3,-2,-1,-1,7};
int min = arr[0];
int max = arr[0];
//O(n)
for (int i = 1; i < arr.length; i++) {
if (arr[i] < min) {
min = arr[i];
}
if (arr[i] > max) {
max = arr[i];
}
}
int[] temp = new int[max - min + 1];
//对应关系 index = number - min number = index + min
//O(n)
for (int i = 0; i < arr.length; i++) {
temp[arr[i] - min]++;
}
//temp[index] 表示index对应的数字number出现的次数
int k = 0;
//O(n)
for (int index = 0; index < temp.length; index++) {
while (temp[index] != 0) {
arr[k] = index + min;
k++;
temp[index]--;
}
}
print(arr);
}
public static void print(int[] arr) {
System.out.print("[");
for (int i = 0; i < arr.length;i++) {
System.out.print(arr[i]);
if (i == arr.length - 1) {
System.out.println("]");
} else {
System.out.print(", ");
}
}
}
}
基数排序算法
基数排序是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。
1. 基数排序 vs 计数排序 vs 桶排序
基数排序有两种方法:
这三种排序算法都利用了桶的概念,但对桶的使用方法上有明显差异:
- 基数排序:根据键值的每位数字来分配桶;
- 计数排序:每个桶只存储单一键值;
- 桶排序:每个桶存储一定范围的数值;
2. LSD 基数排序动图演示

<图片来源于菜鸟教程>
代码实现
import java.util.LinkedList;
public class Sample {
//基数排序
public static void main(String[] args) {
int[] arr = {102,203,321,13,12,78,96,34,37,28,6,8,5,6};
//1.先找到最大值 决定轮数
int max = arr[0];
for (int i = 0; i < arr.length; i++) {
if (arr[i] > max) {
max = arr[i];
}
}
int radex = (max + "").length();
//2.创建十个桶 每一个桶是LinkedList
LinkedList<Integer>[] queues = new LinkedList[10];
for (int i = 0; i < queues.length; i++) {
queues[i] = new LinkedList<Integer>();
}
//3.进行数字分类和规整
//r=0个位 r=1十位 r=2百位...
for (int r = 0; r < radex; r++) {
//先按照r进行分类
for (int i = 0; i < arr.length; i++) {
int index = getIndex(arr[i],r);
//获取数字的r位 返回该数字要去的桶的角标0~9
queues[index].offer(arr[i]);
}
//然后在重新规整到arr里
int k = 0;
for (int index = 0; index < queues.length; index++) {
while(!queues[index].isEmpty()) {
arr[k++] = queues[index].poll();
}
}
}
print(arr);
}
public static int getIndex(int number, int r) {
//123 r=0
//123 r=1
//123 r=2
int index = 0;
for (int i = 0; i <= r; i++) {
index = number % 10;
number /= 10;
}
return index;
}
public static void print(int[] arr) {
System.out.print("[");
for (int i = 0; i < arr.length;i++) {
System.out.print(arr[i]);
if (i == arr.length - 1) {
System.out.println("]");
} else {
System.out.print(", ");
}
}
}
}
二分查找算法
二分搜索是一种在有序数组中查找某一特定元素的搜索算法。搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组为空,则代表找不到。这种搜索算法每一次比较都使搜索范围缩小一半。
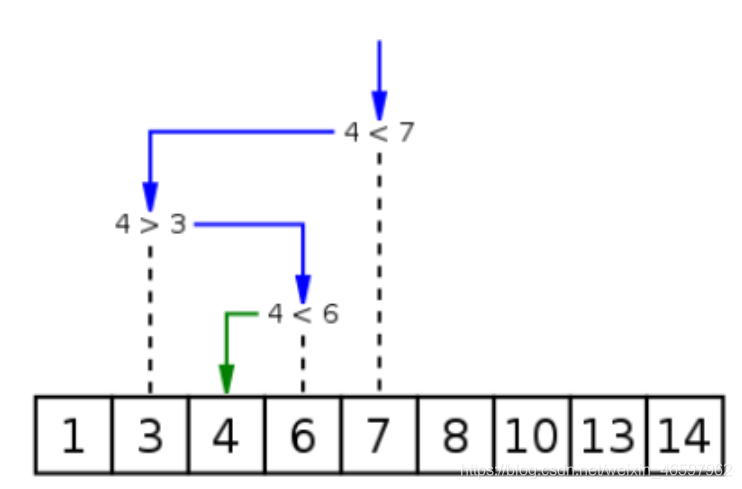
前提:所查找的数据集必须是有序的(升序,降序)
public class Sample {
//二分查找
public static void main(String[] args) {
int[] arr = {1,2,3,4,5,6,7,8,9};
int min = 0;
int max = arr.length - 1;
int mid = (min + max) / 2;
int key = 10;
while (arr[mid] != key) {
if (key < arr[mid]) {
max = mid - 1;
}
if (arr[mid] < key) {
min = mid + 1;
}
if (min > max) {
mid = -1;
break;
}
mid = (min + max) / 2;
}
System.out.println(mid);
}
}
可变长参数列表
在 Java 5 中提供了变长参数,允许在调用方法时传入不定长度的参数。变长参数是 Java 的一个语法糖,本质上还是基于数组的实现:
void foo(String... args);
void foo(String[] args);
//方法签名
([Ljava/lang/String;)V // public void foo(String[] args)
定义方法
在定义方法时,在最后一个形参后加上三点 …,就表示该形参可以接受多个参数值,多个参数值被当成数组传入。上述定义有几个要点需要注意:
-
可变参数只能作为函数的最后一个参数,但其前面可以有也可以没有任何其他参数
-
由于可变参数必须是最后一个参数,所以一个函数最多只能有一个可变参数
-
Java的可变参数,会被编译器转型为一个数组
-
变长参数在编译为字节码后,在方法签名中就是以数组形态出现的。这两个方法的签名是一致的,不能作为方法的重载。如果同时出现,是不能编译通过的。可变参数可以兼容数组,反之则不成立
public void foo(String...varargs){} foo("arg1", "arg2", "arg3"); //上述过程和下面的调用是等价的 foo(new String[]{"arg1", "arg2", "arg3"}); -
J2SE 1.5 中新增了**“泛型”**的机制,可以在一定条件下把一个类型参数化。例如,可以在编写一个类的时候,把一个方法的形参的类型用一个标识符(如T)来代表, 至于这个标识符到底表示什么类型,则在生成这个类的实例的时候再行指定。这一机制可以用来提供更充分的代码重用和更严格的编译时类型检查。不过泛型机制却不能和个数可变的形参配合使用。如果把一个能和不确定个实参相匹配的形参的类型,用一个标识符来代表,那么编译器会给出一个 “generic array creation” 的错误
public class Varargs { public static void test(String... args) { for(String arg : args) {//当作数组用foreach遍历 System.out.println(arg); } } //Compile error //The variable argument type Object of the method must be the last parameter //public void error1(String... args, Object o) {} //public void error2(String... args, Integer... i) {} //Compile error //Duplicate method test(String...) in type Varargs //public void test(String[] args){} }
可变参数方法的调用
调用可变参数方法,可以给出零到任意多个参数,编译器会将可变参数转化为一个数组。也可以直接传递一个数组,示例如下:
public class Varargs {
public static void test(String... args) {
for(String arg : args) {
System.out.println(arg);
}
}
public static void main(String[] args) {
test();//0个参数
test("a");//1个参数
test("a","b");//多个参数
test(new String[] {"a", "b", "c"});//直接传递数组
}
}
方法重载
优先匹配固定参数
调用一个被重载的方法时,如果此调用既能够和固定参数的重载方法匹配,也能够与可变长参数的重载方法匹配,则选择固定参数的方法:
匹配多个可变参数
调用一个被重载的方法时,如果此调用既能够和两个可变长参数的重载方法匹配,则编译出错:
public class Sample {
public static void main(String[] args) {
show(1);
show(1,2,3);
show("hehe","lala","haha","xixi","heihei");
}
public static void show(int ... nums) {
for (int i = 0; i < nums.length; i++) {
System.out.print(nums[i] + " ");
}
System.out.println();
}
public static void show(String ... strs) {
for (int i = 0; i < strs.length; i++) {
System.out.print(strs[i] + " ");
}
System.out.println();
}
}
6.3 二维数组
二维数组,在表现形式上就是一个表格,在操作表格的时候以行列来操作
二维数组,本质上就是一个一维数组,只不过该一维数组里面的元素是另一个一维数组
二维数组的定义
数据类型[][] 矩阵名 = new 数据类型[row][col];
数据类型[][] 矩阵名 = new 数据类型[][] {
{...},
{...},
{...}
};
数据类型[][] 矩阵名 = {
{...},
{...},
{...}
};

















 5136
5136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









