







 本文详细介绍如何在SpringBoot项目中使用MongoDB,包括配置、基本操作及关联查询技巧。通过示例展示了如何进行学生与班级间的关联查询,并介绍了分页查询的方法。
本文详细介绍如何在SpringBoot项目中使用MongoDB,包括配置、基本操作及关联查询技巧。通过示例展示了如何进行学生与班级间的关联查询,并介绍了分页查询的方法。
这里记录一下自己学习和使用mongodb的一些过程和经验。
话不多说,直接开始
新建一个springboot项目,导入mongo依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-validation</artifactId></dependency>yml文件加入mongo配置,有密码的加上密码
spring: #mongo配置 data: mongodb: database: testMongodb uri: mongodb://127.0.0.1:27017基本使用
写了个工具类,要用的时候,先实例化一下MongoClient,设置一下连接超时时间,最大等待时间,读取数据的超时时间,配置一下端口,ip。就可以连接上mongo数据库了。
MongoClient常用方法
getDatabase(String dbName) 获取数据库by name
就可以得到数据库MongoDatabase,然后就可以去数据了。
getCollection(String collectionName)
获取集合,相当于mysql中的表。
然后我们就可以进行增删改查了
一行数据是一个Document。它实现了Map,bson接口,底层其实就是一个类似json的结构,和map一样有key value。可以put(key,value),可以get(key)。
查出来以后是一个文档的集合,然后我们把它转成json字符串,然后再返回。
如果要插入的话,我们可要把每行数据弄成Document对象,然后插入。
关联查询
用过mongodb的应该都清楚,mongodb不能多表关联查询,不能子查询。但是实际工作中,经常会遇到要求关联查询的情况,我们也必须去想办法解决。比如现在有一个学生表,和一个班级表,学生表中没有班级名字段,一个学生只能对应一个班级,要求能够通过班级名,比如1501,查出这个班级的所有学生,并且查出来的学生对象中包含班级的信息。
这种情况用Mysql可以很轻松实现,一条sql的事,但是对于mongodb来讲却很费事,一般有两种思路,第一种硬关联。先把所有学生都查出来,再去关联对应的班级信息。这种方式在数据量大的时候肯定是不行的。第二种方式就是使用@DBRef去关联。有些人可能会想,我可以把班级对象作为字段插入,但是这样做的话会使得每条文档的占用很大,mongodb对每条文档的大小有限制。
所以我们选用@DBRef去关联,这种关联会把要关联的对象变成一种引用的方式,去指向对象,这样mongodb存储每条文档的时候的占用就不会太大。
接下来我们用代码演示:
学生类:
@NoArgsConstructor@AllArgsConstructor@Data@Document("student")public class Student implements Serializable { private String stuName; private int stuAge; private String stuSex; @DBRef private Clazz clazz;}班级类:
@NoArgsConstructor@AllArgsConstructor@Data@Document("class")public class Clazz { @Id private String id; private String className;}把学生数据和班级数据插入mongodb,要注意,必须先插入班级信息,不然插入学生数据时候没法引用。
注入MongoTemplate,就可以使用了
@Resource private MongoTemplate mongoTemplate;插入班级数据
ArrayList<Clazz> clazzes = new ArrayList<>(); Clazz clazz1 = new Clazz(ObjectId.get().toString(),"1501"); Clazz clazz2 = new Clazz(ObjectId.get().toString(),"1502"); Clazz clazz3 = new Clazz(ObjectId.get().toString(),"1503"); clazzes.add(clazz1); clazzes.add(clazz2); clazzes.add(clazz3); mongoTemplate.insertAll(clazzes);班级的id是我们自己定义的,没有使用mongodb自动生成的,这是因为班级的id要作为引用和student关联,班级实体类中就必须要有id字段,不然就会报错。id的生成方式,我们和mongodb
默认的方式一样。下面就是班级数据插入mongodb中的效果。
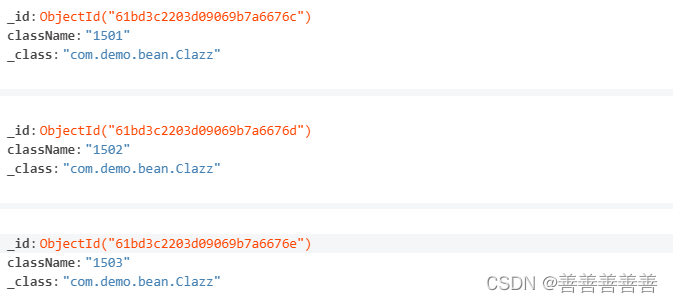
接下来我们插入学生数据,同时注入班级引用。
核心就是在引用的字段上加@DBRef注解。
Student stu1 = new Student("小刚",15,"男");Student stu2 = new Student("小明",12,"男");Student stu3 = new Student("小胖",18,"女");Student stu4 = new Student("小欢",13,"男");Student stu5 = new Student("小美",15,"女");Student stu6 = new Student("小方",16,"女");Clazz class1 = mongoTemplate.findOne(new Query(Criteria.where("className").is("1501")), Clazz.class);Clazz class2 = mongoTemplate.findOne(new Query(Criteria.where("className").is("1502")), Clazz.class);stu1.setClazz(class1);stu2.setClazz(class1);stu3.setClazz(class2);stu4.setClazz(class1);stu5.setClazz(class2);stu6.setClazz(class2);ArrayList<Student> students = new ArrayList<>();students.add(stu1);students.add(stu2);students.add(stu3);students.add(stu4);students.add(stu5);students.add(stu6);mongoTemplate.insertAll(students);这里可以看到,我们先通过班级名称查询出来班级,然后直接注入到了学生类中。
然后保存到mongodb中的样子是这样的,
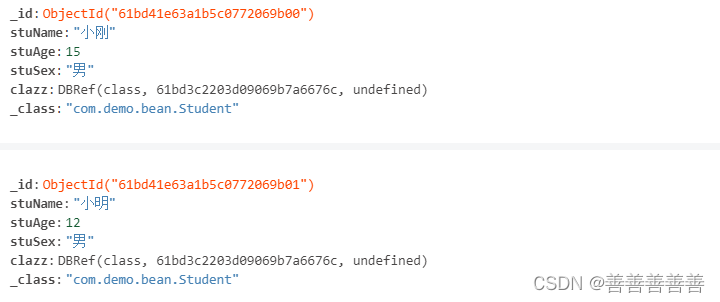
可以看出,班级信息是以DBRef方式引用的,所以占用不大。
接下来我们查询,查询出1501班的所有学生。
Clazz clazz = mongoTemplate.findOne(new Query(Criteria.where("className").is("1501")), Clazz.class);List<Student> stuList = mongoTemplate.find(new Query(Criteria.where("clazz.$id").is(new ObjectId(clazz.getId()))), Student.class);return Result.success(stuList,"查询成功",200);我们先把1501班查出来,然后再通过班级对象的id来查询出所有的学生。
这里要注意 "clazz.$id" 要用实体类中的字段,不能用mongo表中的字段,id字段要加$。后面的条件id要包装成ObjectId格式,因为mongodb中的_id就只能是ObjectId格式。
这样我们就能查出结果了,班级信息同时也查出来了。
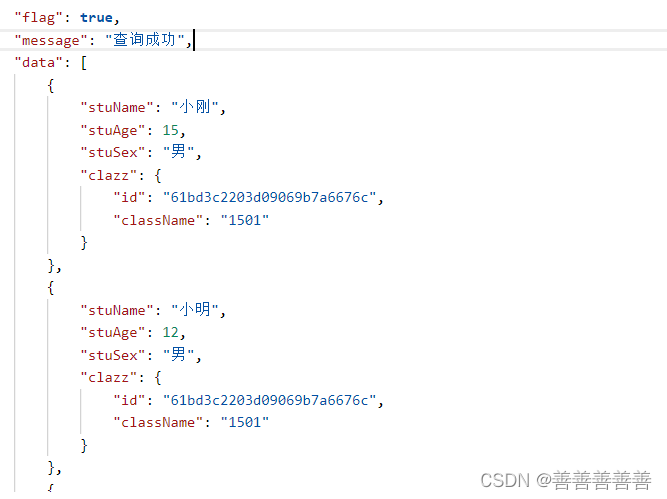
查询mongodb的分页
前端传参数时候会传过来一个pageNum,一个pageSize。我们在执行查询的时候,要使用skip和limit。
skip(( pageNum-1) × pageSize)
表示跳过这么多文档,从...开始查
limit( pageSize)
表示查这么多条文档
这样就可以查询到对应分页的数据。
返回的时候我们需要返回两个参数,一个total,一个pageNum。
total指的是不加分页条件能查出来的总条数。
可以用collection. countDocument( query)实现
pageNum=total/ pageSize。如果除不尽,就加一。

















 172
172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









