




历史文章
Spring AI:对接DeepSeek实战
Spring AI:对接官方 DeepSeek-R1 模型 —— 实现推理效果
Spring AI:ChatClient实现对话效果
Spring AI:使用 Advisor 组件 - 打印请求大模型出入参日志
Spring AI:ChatMemory 实现聊天记忆功能
Spring AI:本地安装 Ollama 并运行 Qwen3 模型
Spring AI:提示词工程
Spring AI:提示词工程 - Prompt 角色分类(系统角色与用户角色)
Spring AI:基于 “助手角色” 消息实现聊天记忆功能
Spring AI:结构化输出 - 大模型响应内容
Spring AI:Docker 安装 Cassandra 5.x(限制内存占用)&& CQL
Spring AI:整合 Cassandra - 实现聊天消息持久化
Spring AI:多模态 AI 大模型
本文中,我们来编写一个案例,通过填写对应关键词,然后调用阿里百炼平台的 “通义万相2.1-文生图” 大模型,生成一张相关的图片
添加依赖
由于 “通义万相2.1-文生图” 大模型未兼容 OpenAI 调用方式,通过 Spring AI 来调用,需要额外添加阿里百炼的 SDK。
编辑 pom 文件,添加依赖如下,写这篇文章的时候,SDK 最新版本为 2.20.6 ,可以在 Maven 中央仓库中查看:https://mvnrepository.com/artifact/com.alibaba/dashscope-sdk-java :
<!-- 阿里百炼 SDK -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>dashscope-sdk-java</artifactId>
<version>2.20.6</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
</exclusion>
</exclusions>
</dependency>
TIP: 上述依赖中,排除了 slf4j-simple 包,不然启动项目时,提示 “项目中同时存在多个 SLF4J 的实现”,错误信息具体如下:

依赖添加完成后,需要刷新一下 Maven, 将包下载到本地 Maven 仓库中。
挑选文生图模型
进入到阿里百炼模型广场中,筛选图片生成分类下的大模型,如下图所示,选择 “通义万相-文生图”:
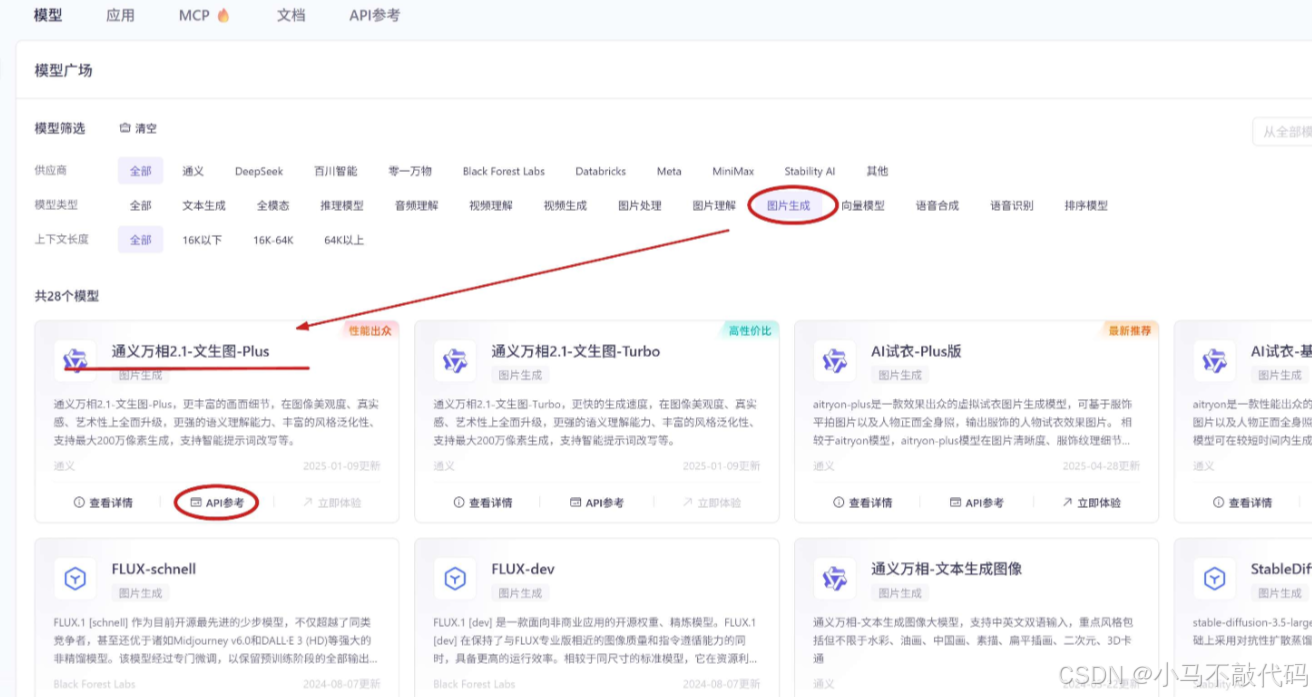
点击 “API参考”,查看模型对应的文档,复制出模型名称:
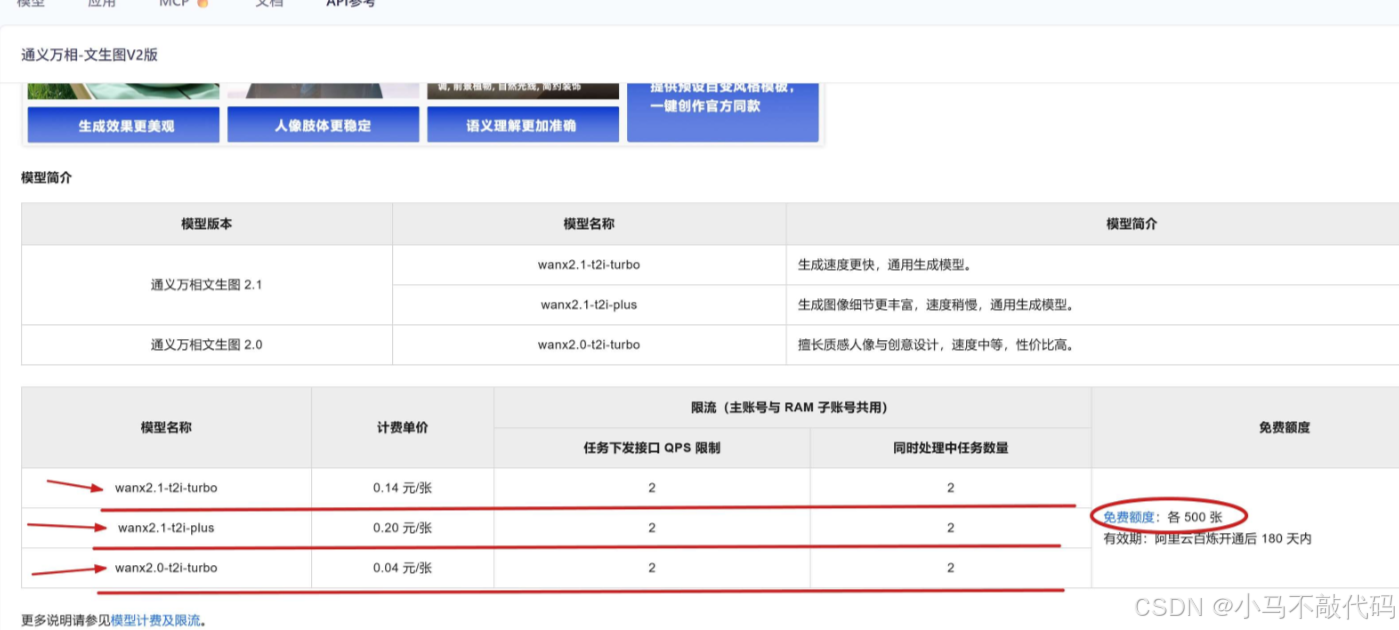
可以看到 “通义万相2.1” 共提供了 3 个模型,各自提供 500 张的免费额度,用完后的计费单价如下,:
- wanx2.1-t2i-turbo : 生成速度更快,通用生成模型, 0.14元/张;
- wanx2.1-t2i-plus: 生成图像细节更丰富,速度稍慢,通用生成模型, 0.20元/张;
- wanx2.0-t2i-turbo: 擅长质感人像与创意设计,速度中等,性价比高, 0.04元/张;
新增 Controller 控制器
spring.ai.openai.api-key的值获取你自己的阿里百练平台上的key,可以看上篇文章
Spring AI:多模态 AI 大模型
@RestController
@RequestMapping("/v10/ai")
@Slf4j
public class Text2ImgController {
@Value("${spring.ai.openai.api-key}")
private String apiKey;
/**
* 调用阿里百炼图生文大模型
* @param prompt 提示词
* @return
*/
@GetMapping("/text2img")
public String text2Image(@RequestParam(value = "prompt") String prompt) {
// 构建文生图参数
ImageSynthesisParam param = ImageSynthesisParam.builder()
.apiKey(apiKey) // 阿里百炼 API Key
.model("wanx2.1-t2i-plus") // 模型名称
.prompt(prompt) // 提示词
.n(1) // 生成图片的数量,这里指定为一张
.size("1024*1024") // 输出图像的分辨率
.build();
// 同步调用 AI 大模型,生成图片
ImageSynthesis imageSynthesis = new ImageSynthesis();
ImageSynthesisResult result = null;
try {
log.info("## 同步调用,请稍等一会...");
result = imageSynthesis.call(param);
} catch (ApiException | NoApiKeyException e){
log.error("", e);
}
// 返回生成的结果(包含图片的 URL 链接)
return JsonUtils.toJson(result);
}
}
测试
完成编码工作后,准备来测试一下效果,重启后端项目,浏览器请求地址如下,携带上具体的提示词:
http://localhost:8080/v10/ai/text2img?prompt=(最佳质量, 大师杰作, 超精细细节, 8K分辨率, HDR), (锐利聚焦, 电影灯光, 工作室级布光),
一张动漫风格的插画,描绘了一位灰发蓝眼的女孩。她戴着绿色的蝴蝶结头饰和彩色的耳环,穿着白色的衣服,并且有蓝色的指甲油。背景是一个涂鸦墙,上面有各种颜色和图案的涂鸦。女孩的表情看起来有些严肃或冷漠。

生成图片需要一定时间,等待生成完毕后,会返回相关参数,如上图所示
解释一下相关参数:
- orig_prompt : 原始的提示词,即我们填写的提示词;
- actual_prompt: 实际执行的提示词。因为 “通义万相” 预置了智能改写提示词功能,即使输入简单的提示词,也能出大片。
- url: 图片访问链接;
将 url 图片链接复制出来,通过浏览器单独访问,即可下载生成后的图片,生效效果如下



















 171
171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











