






SQL(结构化查询语言)
一、SQL通用语法
1、SQL注意事项
- SQL语句可以单行或者多行书写,以分号结尾。
- Mysql数据库的SQL语句不区分大小写,关键字建议用大写
- 注释
单行注释:–(这里有个空格) 注释内容 或者 #(这里可以不加空格) 注释内容
多行注释:/1* 注 释* /
2、SQL分类
- DDL(Data Definition Language)数据定义语言,用来定义数据对象:数据库、表、列等
- DML(Data Mainpulate Language)数据库操作语言,用来对数据库中的表进行增、删、改
- DQL(Data Query Language)数据查询语言,用于查询数据库中表的记录(数据)
- DCL(Data Control Language)数据控制语言,用于定义数据库中的访问 权限和安全级别,及创建用户
3、DDL(数据库定义语言)
DDL --操作数据库
#1:查询所有数据库
show databases;
#2:创建数据库
create database 数据库名称;#对创建数据库不存在的情况
create database if not exists 数据库名称;
#3:删除
#删除数据库
drop database 数据库名称;
#删除数据库(判断,如果存在则删除)
drop database if exists 数据库名称
#4:使用当前数据库
use 数据库名称;
#5:查看当前使用的数据库
select database();
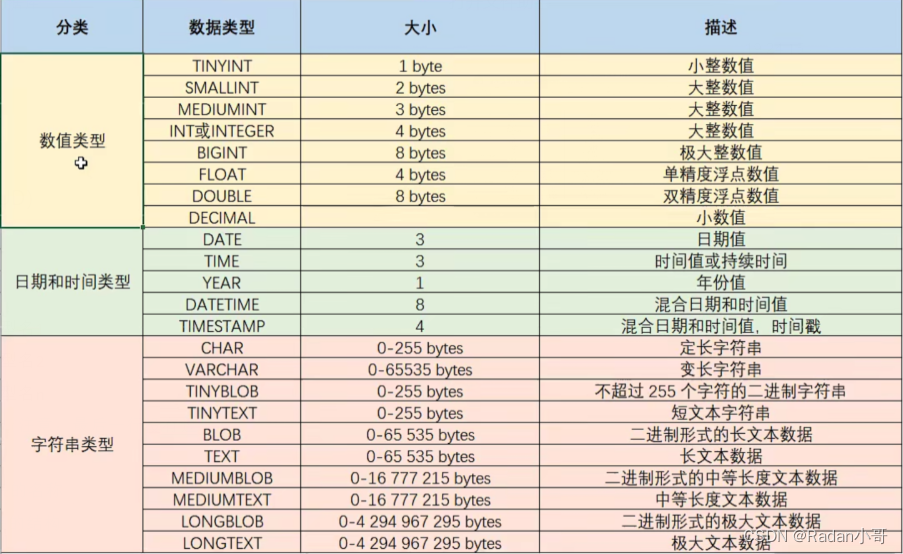
类型名
DDL–操作表(CRUD)
#创建(Create)
create table 表名(
字段名1 类型名1,
字段名2 类型名2,
字段名n 类型名n
);#建表语句(注意:最后一行没有逗号)
#查询(Retrieve)
show tables;#查询表的名称
desc 表名称;#查询表的结构
#修改(Update)
alter table 旧表名 rename to 新表名;#修改表的名称
alter table 表名 add 列名 数据类型;#给表添加一列
alter table 表名 modify 列名 新的数据类型;#修改表的已存在列的数据类型
alter table 表名 change 列名 新列名 新数据类型;#修改列名和数据类型
alter table 表名 drop 列名;#删除表的一列
#删除(Delete)
drop table 表名称;#不判断表是否存在
drop table if exists 表名;#存在则删除
4、DML(增删改)
#添加数据
insert into 表名(列名1,列名2,..)values(值1,值2,...); -- 添加单行数据
insert into 表名(列名1,列名2,..)values(值1,值2,...),(值1,值2,...),(值1,值2,...),(值1,值2,...),....;----批量添加数据
#修改数据
update 表名 set 列名1=值1,列名2=值2,...[where 条件]; -- 修改语句中如果不加条件,默认修改1所有的数据
#删除数据
delete from 表名 [where 条件]; -- 不加条件,就会删除表中的所有数据(清空表)
5、DQL(查询操作)
聚合函数:

#查询语法
select 字段列表 from 表名列表
where 条件列表 group by 分组字段
having 非组后的条件 order by 排序字段
limit 分页限定
#基础查询
select 字段名1,字段名2,.. from 表名;-- 查询表中的所选列 ‘*’建议不使用
select distinct 字段名1 from 表名; -- 去除重复记录 (distinct关键字)
select 字段名1 as 新别名1,字段名2 as 新别名2,...... from 表名; -- 起别名(方便阅读)
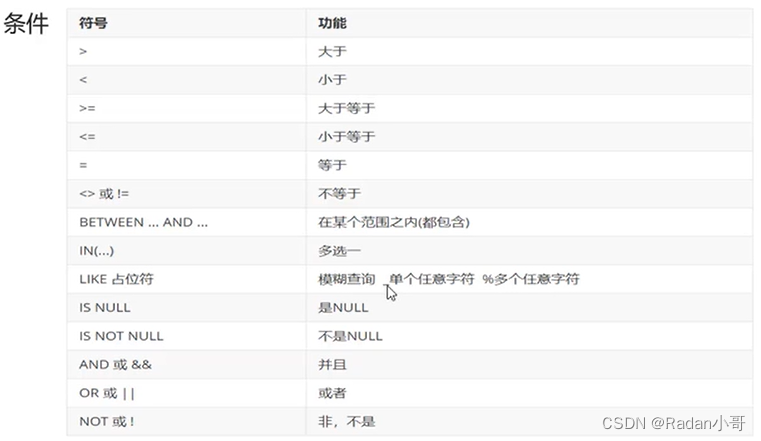
#条件查询
select * from 表名 where 条件;
-- 注意: null值的比较不能使用!=||=,需要使用 is 和is not来比较
-- !=等价于<>、集合比较用in关键字,范围比较用between and关键字
-- 模糊查询中 _:表示任意的单个字符 %:用来匹配任意多个字符
#排序查询中 desc:表示降序排序 asc:表示升序排列(默认方式)
select 字段列表 from 表名 order by 排序字段名1 [排序方式1],排序字段名2 [排序方式2]....;
-- 当有多个排序字段时,当前面的条件值一样时,才会根据第二个条件值进行排序,一层套一层。
# 聚合函数语法
select 聚合函数(列名) from 表名; -- null值不参加计算
#分组查询语法
select 字段列表 from 表名 [WHERE 分组的限定条件] group by 分组字段名 [having 分组后的条件过滤]
-- 分组之后,查询的字段为聚合函数和分组字段,查询其他字段没有任何意义
-- 执行顺序:where>聚合函数>having
-- where和having区别:
-- 执行时机不一样:where是分组之前进行限定,不满足where条件,则不参与分组,而having是分组之后对结果进行过滤。
-- 可判断的条件不一样:where不能对聚合函数进行判断,having可以。
#分页查询语法
select 字段列表 from 表名 limit 起始索引(),查询的条数(每页显示的数据);-- 起始索引从0开始 起始索引=(当前页码数-1)*查询的条数















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









