







之前已经学习过了SQL语句,学习了mysql,了解了Oracle数据库,接下来学习Redis数据库:
学习视频参考一
学习视频资料二
一、提前了解部分
1、软件的发展
(1)web1.0时代
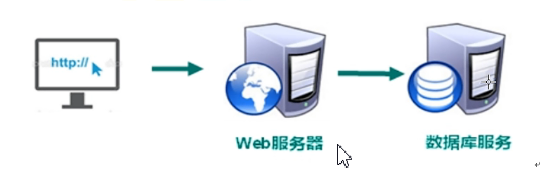
- 90年代,一个基本的网站访问量一般不会太大,单个数据库完全足够!那个时候,更多的去使用静态网页 Html~ 服务器根本没有太大的压力!
- 思考一下,这种情况下:整个网站的瓶颈是什么?
1、数据量如果太大、一个机器放不下了!
2、数据的索引 (B+ Tree),一个机器内存也放不下
3、访问量(读写混合),一个服务器承受不了~
只要你开始出现以上的三种情况之一,那么你就必须要晋级
(2)web2.0时代
- Memcached(缓存)+ mysql + 锤子拆分(读写分离)
- 优化数据结构和索引–> 文件缓存(IO)—>Memcached(当时最热门的技术!

(3)web3.0时代
- 分库分表+水平拆分+mysql集群
- 早些年MyISAM:表锁,十分影响效率,高并发下就会出现严重的锁问题。而Innodb:行锁
- 慢慢的就开始使用分库分表来解决压力!mysql在那个年代推出了表分区!这个并没有多少公司使用
- mysql的集群,很好满足哪个年代的所有需求

(4)最近的年代
- 2010–2020 十年之间,世界已经发生了翻天覆地的变化;(定位,也是一种数据,音乐,热榜!)
- MySQL 等关系型数据库就不够用了!数据量很多,变化很快~!
- MySQL 有的使用它来村粗一些比较大的文件,博客,图片!数据库表很大,效率就低了!如果有一种数
据库来专门处理这种数据, - MySQL压力就变得十分小(研究如何处理这些问题!)大数据的IO压力下,表几乎没法更大!
(5)现在一个基本的互联网项目

2、NoSQL
(1)什么是NoSQL
- NoSQL = Not Only SQL (不仅仅是SQL)
- 关系型数据库:表格 ,行 ,列
- 泛指非关系型数据库的,随着web2.0互联网的诞生!传统的关系型数据库很难对付web2.0时代!尤其是超大规模的高并发的社区! 暴露出来很多难以克服的问题,NoSQL在当今大数据环境下发展的十分迅速,Redis是发展最快的,而且是我们当下必须要掌握的一个技术!
- 很多的数据类型用户的个人信息,社交网络,地理位置。这些数据类型的存储不需要一个固定的格式!不需要多月的操作就可以横向扩展的 ! Map<String,Object> 使用键值对来控制!
(2)为什么用NoSQL
- 用户的个人信息,社交网络,地理位置。用户自己产生的数据,用户日志等等爆发式增长!
- 这时候我们就需要使用NoSQL数据库的,Nosql 可以很好的处理以上的情况!
(3)NoSQL特点
解耦
-
方便扩展(数据之间没有关系,很好扩展)
-
大数据高性能(Redis一秒8万次,读取11万次,NOSQL的缓存记录级,是一种细粒度的缓存,性能会比较高)
-
数据类型时多累心的!(不需要先设计数据库,随取随用,如果数据量十分大的表,很多就无法设计了)
-
传统的RDBMS和NoSql




-
NoSQL(NoSQL=Not only SQL),意思“不仅仅是SQL”,反之非关系型数据库。
-
NoSQL不依赖业务逻辑方式存储,而以简单的key-value模式存储,因此大大的增加了数据库的扩展能力。
(4)NoSQL应用场景
- 对数据高并发的读写
- 海量数据读写
- 对数据搞可扩展性
- 建议:用不着SQL的时候和用SQL也解决不了办法的时候。
(5)NOSQL数据库有哪些
- Memcache

- Redis

- MongoDB(和JSON存储格式一样)

3、Redis介绍和安装
(1)介绍
- Redis是一个开源的key-value类型的存储系统
- 和Memcached类似,它支持存储的value类型相关更多,包括String,list,set,zest(有序集合)和hash(hash类型)
- 这些数据类型都支持push/pop,add/remove及取并集和差集及更丰富的操作,而且这些操作都是原子性的。
- 在此基础上,Redis支持各种不同的方式排序
- 与mecached一样,为了保证效率,数据库缓存在内存中。
- 区别的是Redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件
- 实现了master-slave(主从)同步
(2)安装Redis数据库
https://blog.csdn.net/weixin_46635575/article/details/123906713
(3)redis的一些了解内容
- 默认端口号是6379,就是Merz【老手机对应的6379】

- redis是单线程+多线程IO复用技术


4、redis常用的数据类型操作
首先提醒一点我们现在了解的类型时value的类型,而不是key的类型
(1)redis的key键操作

此时就可以往里面设置数据了
-
设置key和value,并且查看

-
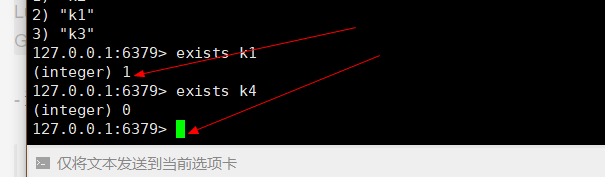
查询是否存在某一个key:exists key
-
查询键的类型:type key

-
删除key和value


-
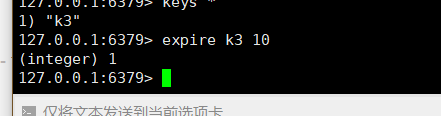
设置过期时间:expire key 时间(以秒为单位)
-
查看还有多少时间过期:ttl key

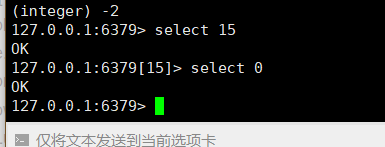
-1表示永不过期,-2表示已经过期了 -
切换你要使用的库【redis里面有十几个库,你可以任意之间进行切换】:select 【0-15】
-
查看当前库的key的数量:dbsize
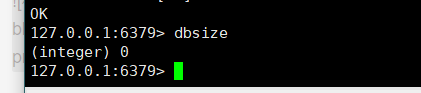
-
情况当前库:flushdb
-
清除所有的:flushall
(2)常用数据类型之String-1
介绍

常用命令
- 补充一点添加和取得
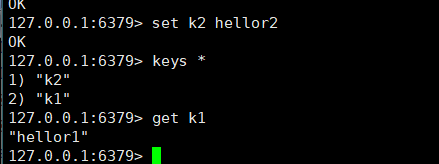
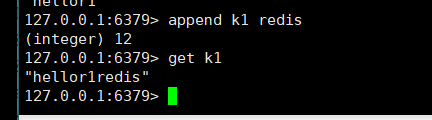
- append <key> <value>追加到原本值的末尾
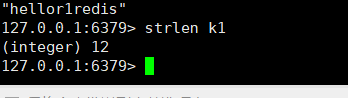
- strlen:得到值的长度
- 设置值:setnx 只有key不存在的时候才能设置,不然设置不成功【它和set的区别是因为set原来有的话,就替换之前的】

- 将key中存储的数字值增1,只能对数字操作,如果为空,新增值为1:incr key【它是原子性的】

- 将key中的值减少1:decr key

- 将key 通过加步长的方式:incrby key 步长

(3)redis的原子性操作

- 这里来个题目看看java中的i++是否是原子性的?
答案是不是。
比如i=0.两个线程分别对i进行++100次,值是多少?【它的答案是2到200】,原因是我们i++是可以分如下的:取值++复制三个步骤

取了之后被打断的话,就会出现问题。
(4)常用数据类型之String-2
-
一次性设置多个key和value:mset key1 value1 key 2 value2.。。。。。。。。。。。

-
msetnx:也是设置多个,如果你设置的key里面,已经存在接下来要设置的任何一个,都失败

-
一次性取出多个
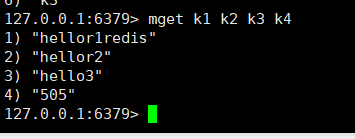
-
获取范围的值:getrange key 起始值 结束值
-
设置范围的值:setrange key 起始值 结束值

-
设置键的同时设置过期时间:setex key 过期时间 value
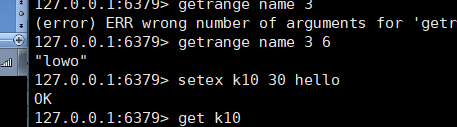
-
肯定对应一个getex key
-
总结


(5)常用数据类型之List

常用命令
-
lpush/rpush key value1 value2 value3…从左边添加或者从右边添加

-
lpop/rpop key 从左边或者右边取出一个值,值在键在,值光键没。

-
取出顺序的值:lrange key 开始 结束【如果设置key 0 -1就查询全部】

-
rpoplpush key1 key2 从key1列表右边弹出一个值,插入到key列表的左边

-
取出指定的下标的值:lindex key 下标
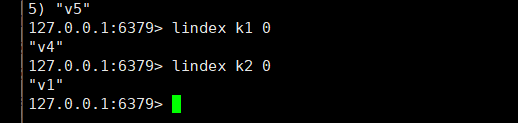
-
llen key 获取列表的长度
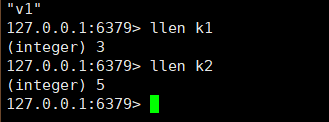
-
linsert key before/after value newvalue 在value后面插入一个新的value

-
lrem key n value 从左边删除第n个value(从左到右)

-
lset key index value:将列表key 下标为index的值特换为value

-
数据结构

(6)常用数据类型之Set集合
介绍


常用命令
-
sadd key value value2 value3【已经添加的value已经存在则忽略】

-
取出集合中的所有值:smembers key
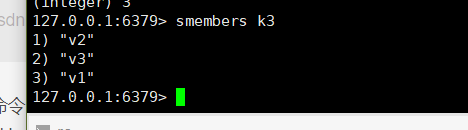
-
判断集合key是否存在某一个value值,有1,没有0:sismember key value
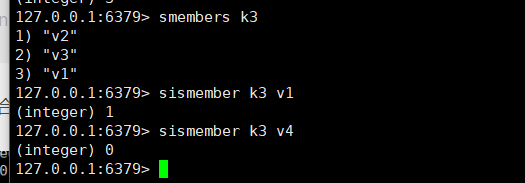
-
返回该集合的元素个数:scard key
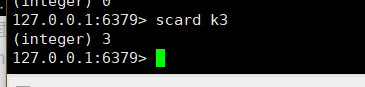
-
删除集合中的某个元素:srem k value value …

-
随机从集合中弹出一个值:spop key

-
随机从该集合中取出n个值,不会从集合中删除:srandmember key n
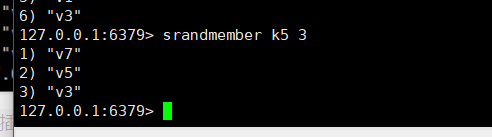
-
把集合中一个值从一个集合移动到另外一个集合:smove key1 key2

-
返回两个集合的交际元素:sinter key1 key2

-
返回两个集合的并集元素:sunion key1 key2

-
返回两个集合的差集元素:sdiff key1 key2 【返回的是key1,具体看哪个写在前面】
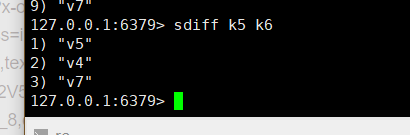
它的数据结构


(7)常用数据类型之Hash
-
介绍


左边这种存储比较容易,但是取出非常麻烦,右边又存储混乱。

所以来看这种方式【左边key就比如是个类,右边就是类的属性】

-
常用命令
- 给key集合中的field键赋值为value:hset key field value
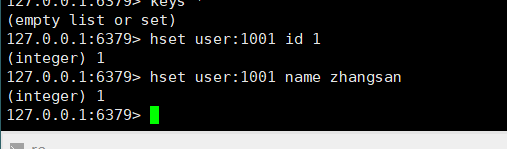
- 从key集合field取出value:hget key field
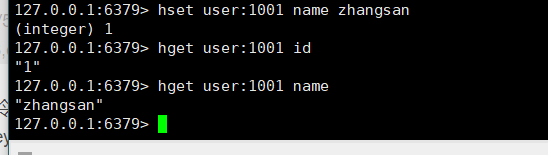
- 批量设置hash的值:hmset key field value field2 value2 …

- 查看哈希表key中,给定域field是否存在:hexists key field
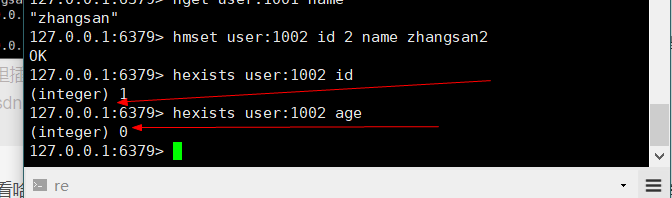
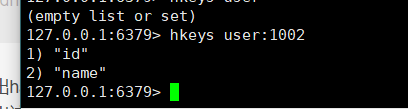
- 列出hash集合的所有field:hkeys key
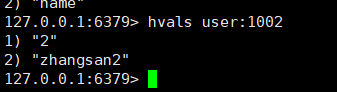
- 列出该hash集合的所有value:hvals key
- 为哈希表key中的域field的值加上增量1 -1:hincrby key field increment 【说白点就是你要修改】

- 将哈希表key中的field的值设置为value,并且仅当域field不存在:hsetnx key field value 【反正也是添加数据的,当存在已经添加的数据时候,返回0】

- 给key集合中的field键赋值为value:hset key field value
-
它的数据结构

(8)常用数据类型之Zset

常用命令
-
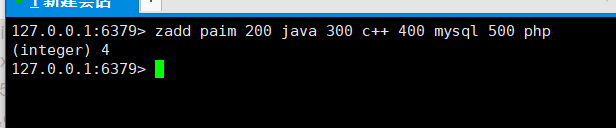
将一个或多个member元素及其score【平分】值加入到有序集合key当中:zadd key score1 value1 score2 value2
这里先复习一下,在我们命令行写多了,感觉看着累,可以用clear清空一下。
-
返回一个有序集合key中,下标在start stop 之间的元素:zrange key start stop [withsocores]【带withsocores,可以让分数一起和值返回到结果集】


-
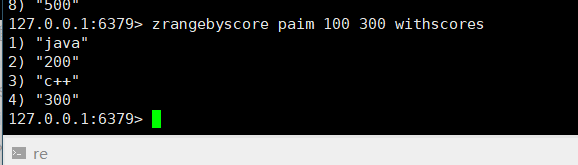
返回有序集key中,所有score值介于min到max之间(包括等于min和max)的成员:zrangebyscore key minmax [withscores] [limit offset count]
-
修改之前的升序排序改为降序排序:zrevrangebyscore key max min withscores

-
为元素的score加上一增量:zincrby key increment value

-
删除该集合下,指定的元素:zerm key value
-
统计该集合。分数区间内的元素个数:zcount key min max

-
返回该值在集合中的排名,从0开始:zrank key value
采用的数据结构
- 数据结构

- 跳跃表



















 407
407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









