







操作数据库
一 、关系型数据库
(一)整合Druid整理
1、数据源自动配置原理
(1)导入相关依赖
- 导入我们的依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
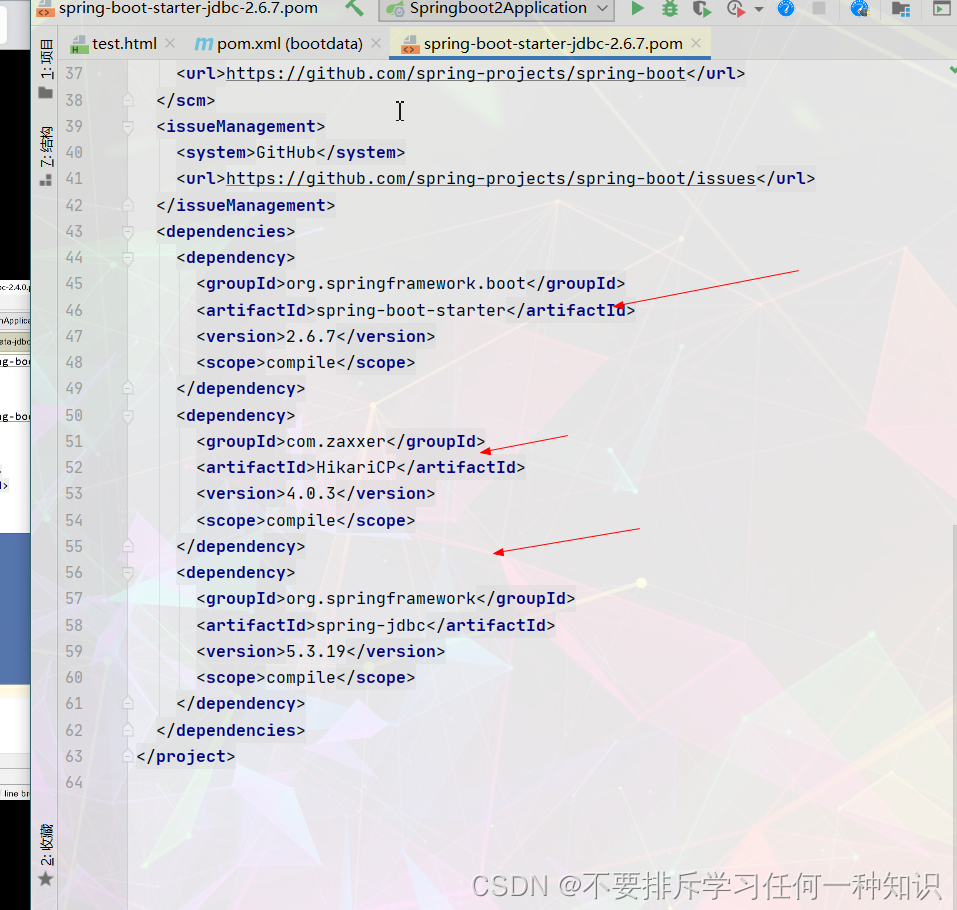
导入了如下的一个数据源(数据库连接池)
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>4.0.3</version>
<scope>compile</scope>
</dependency>
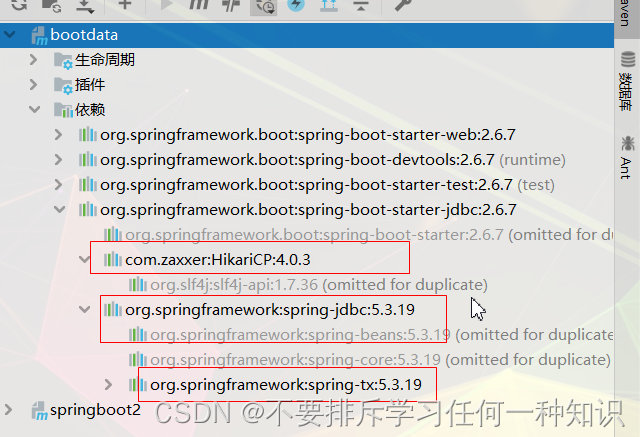
-
我们发现并没有导入驱动包,为什么呢
其实就是官方不知道你接下来操作什么数据库。 -
导入mysql的的驱动。
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
(2)这再次复习一下我们为什么不用导入版本
- 首先看看我们的项目结构
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
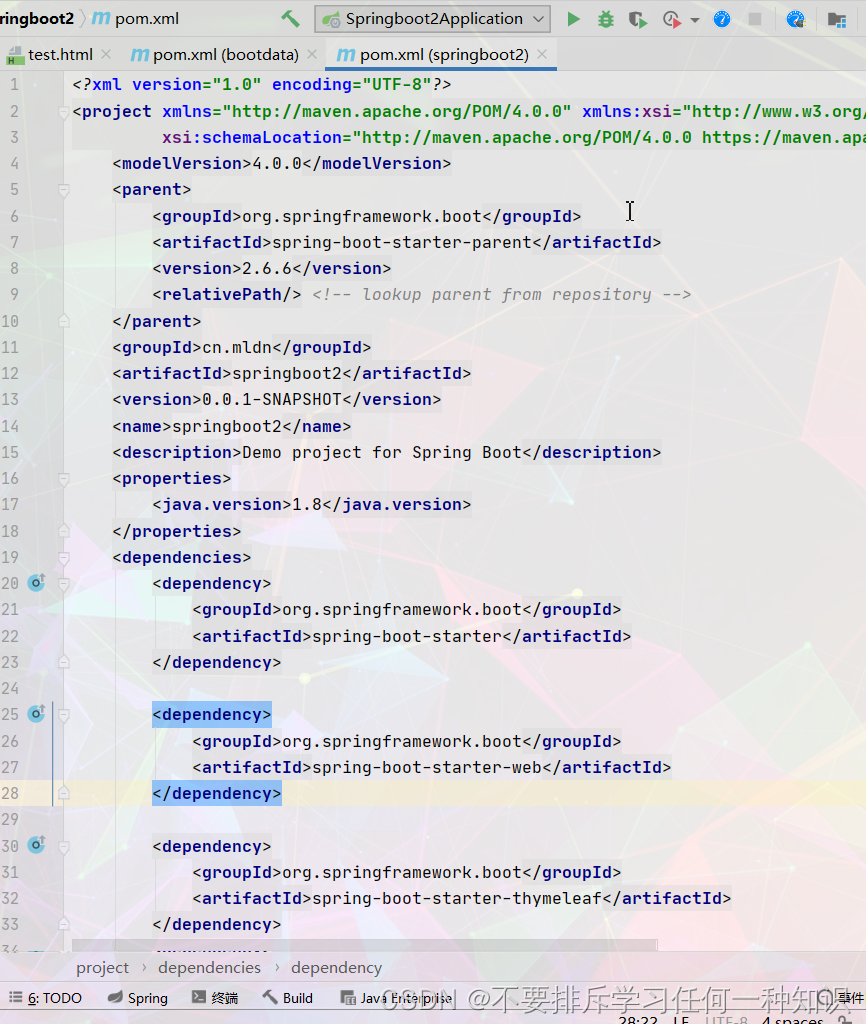
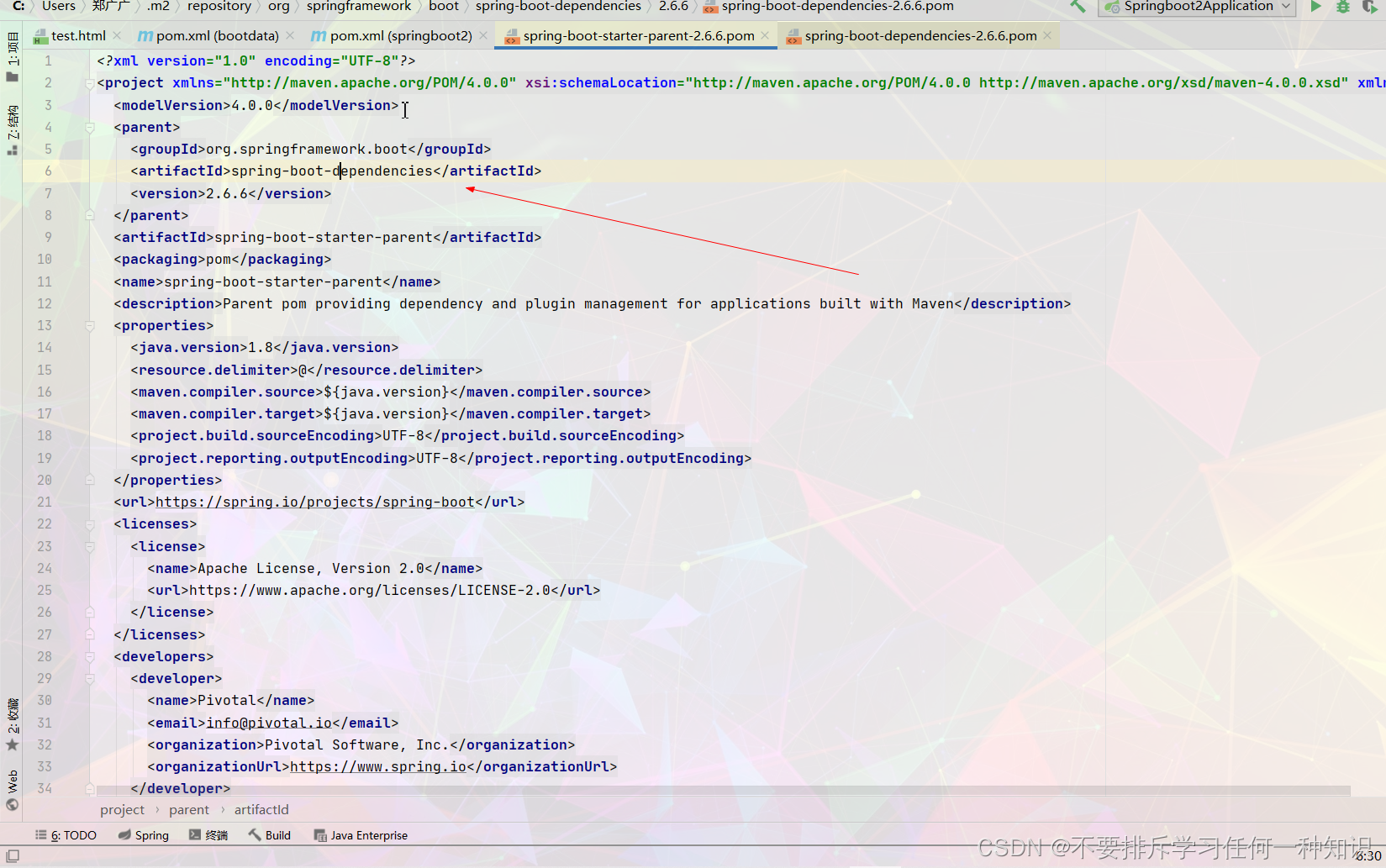
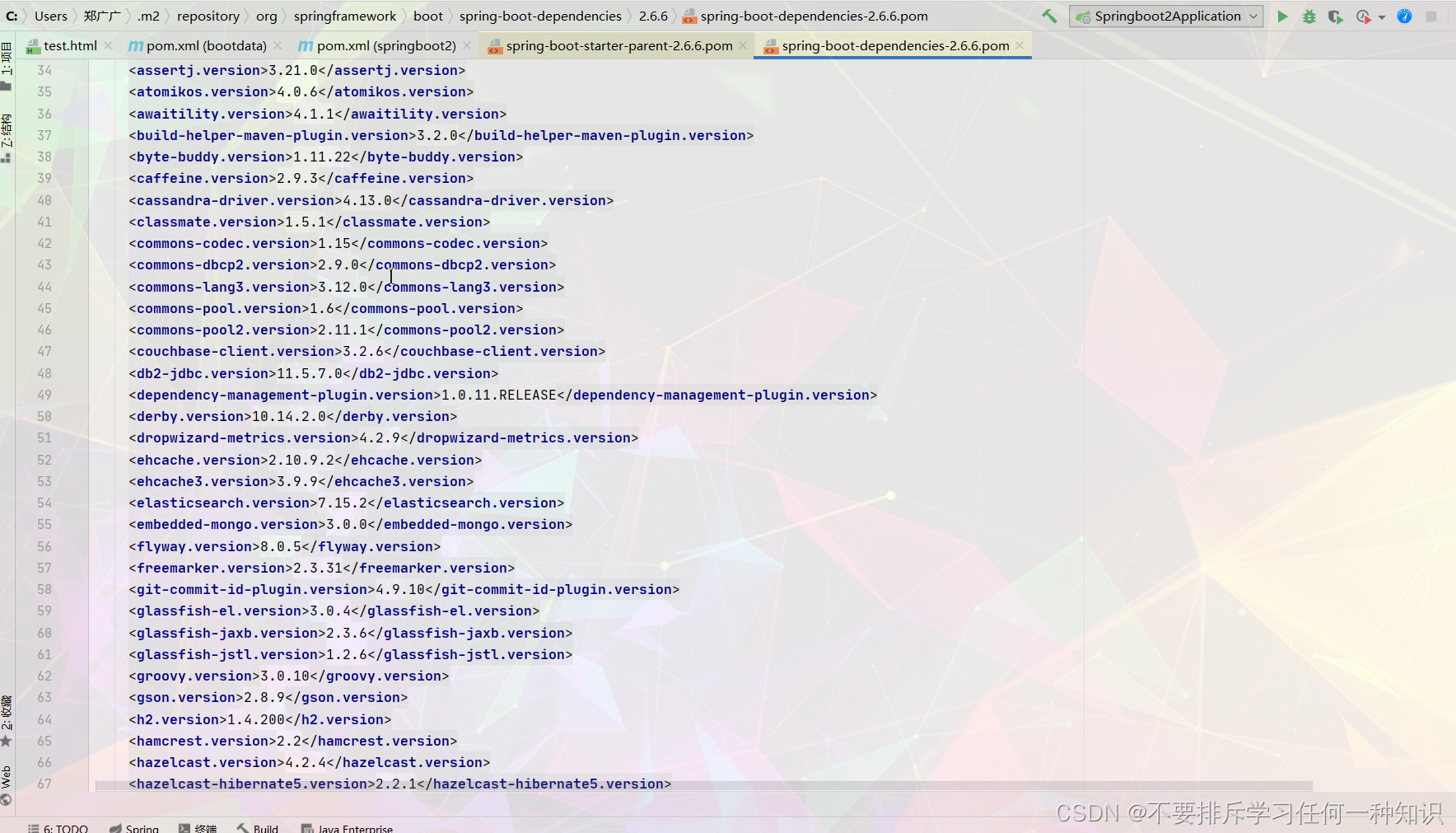
- 其实原理还是比较好理解的,我们的pom就是对我们的项目依赖版本管理,首先父项目的最高依赖里面就进行了版本仲裁,后续你就不用再配置,但是你也可以重新设置。你可以在如下的两个位置进行配置
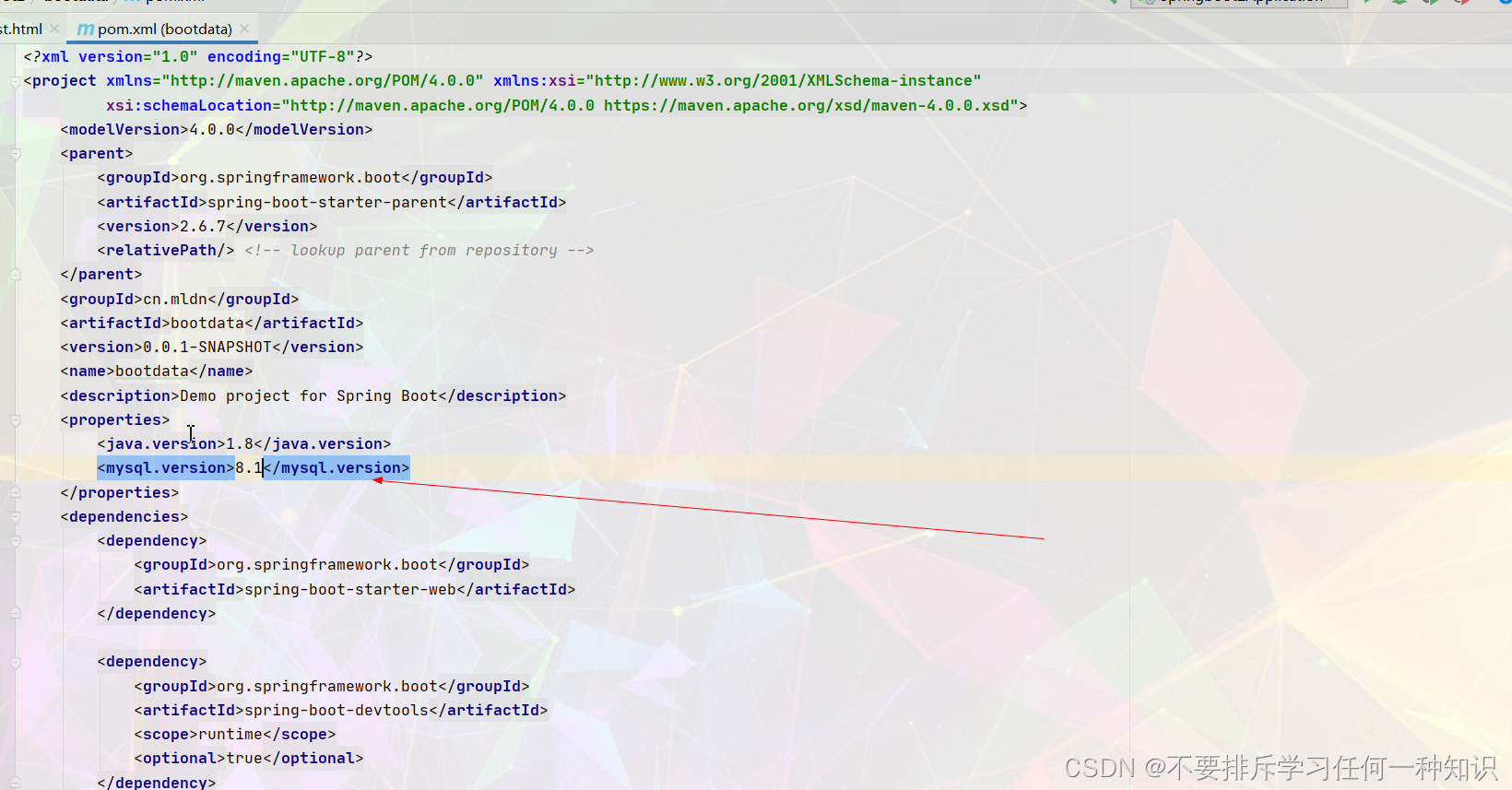

(3)来看看我们的自动配置,配置了哪些
-
来看看导入了jdbc的配置
- DataSourceAutoConfiguration对数据源进行配置
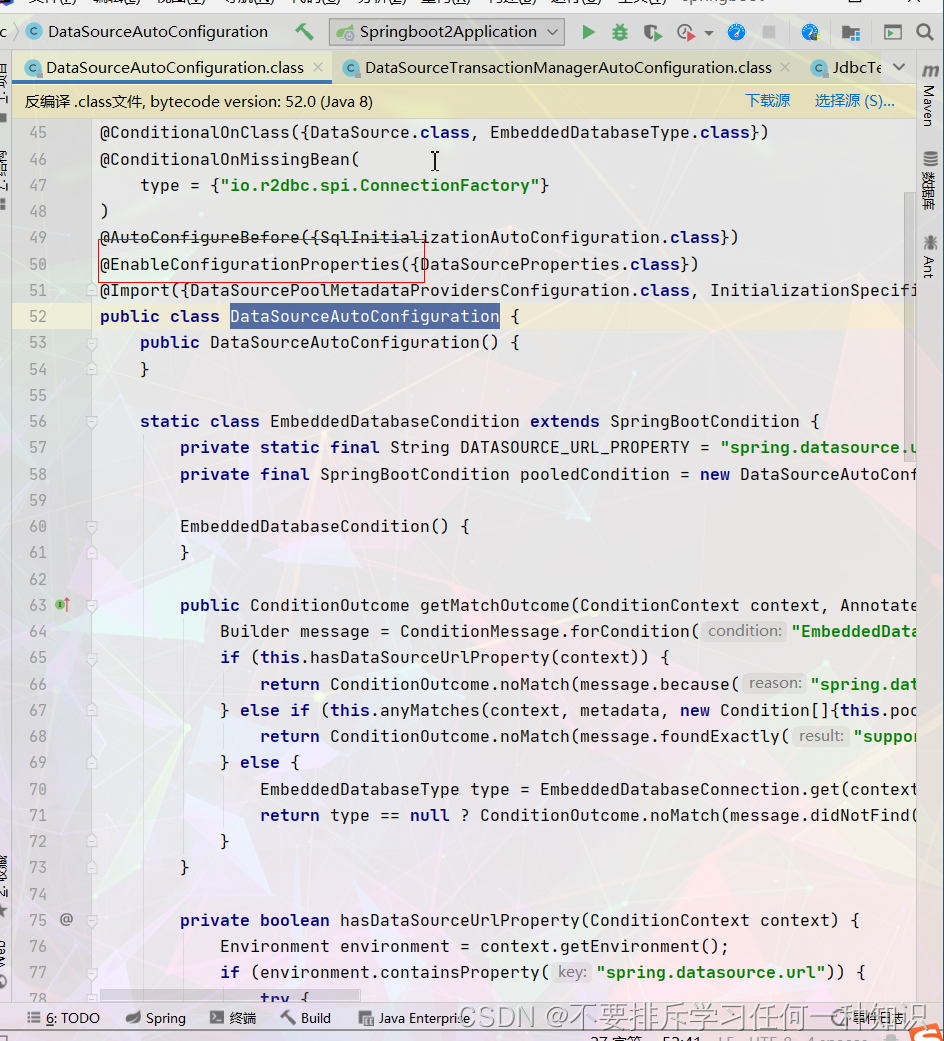
如果要进行配置,那就在配置文件就可以,这里开启了配值。
数据库连接池的配置
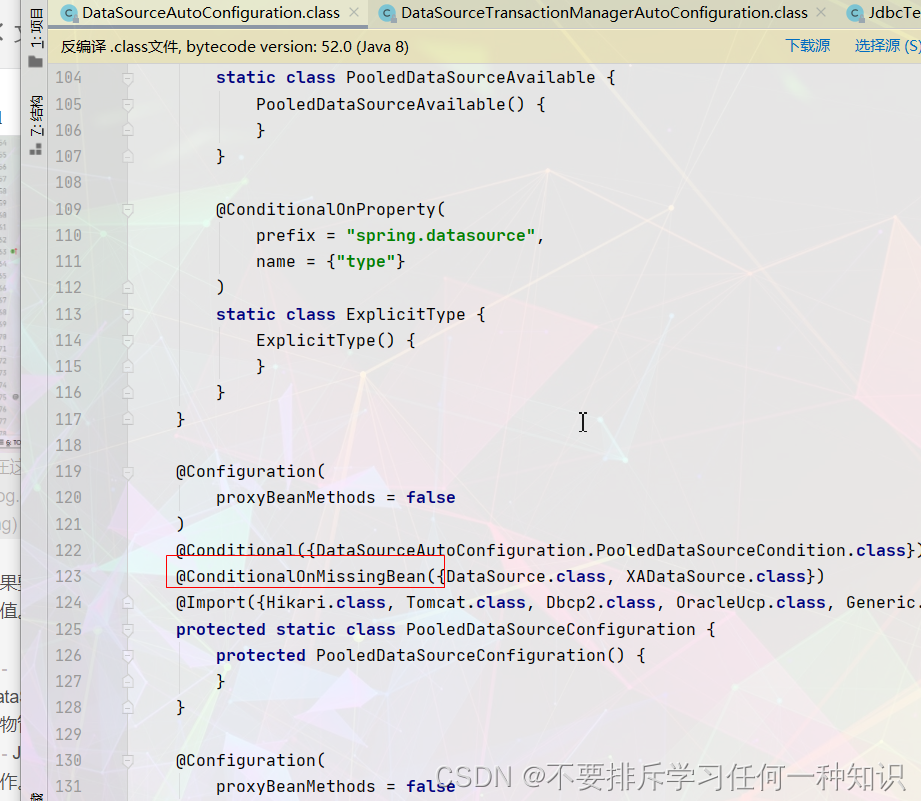
底层配置好的数据库连接池是Hikari
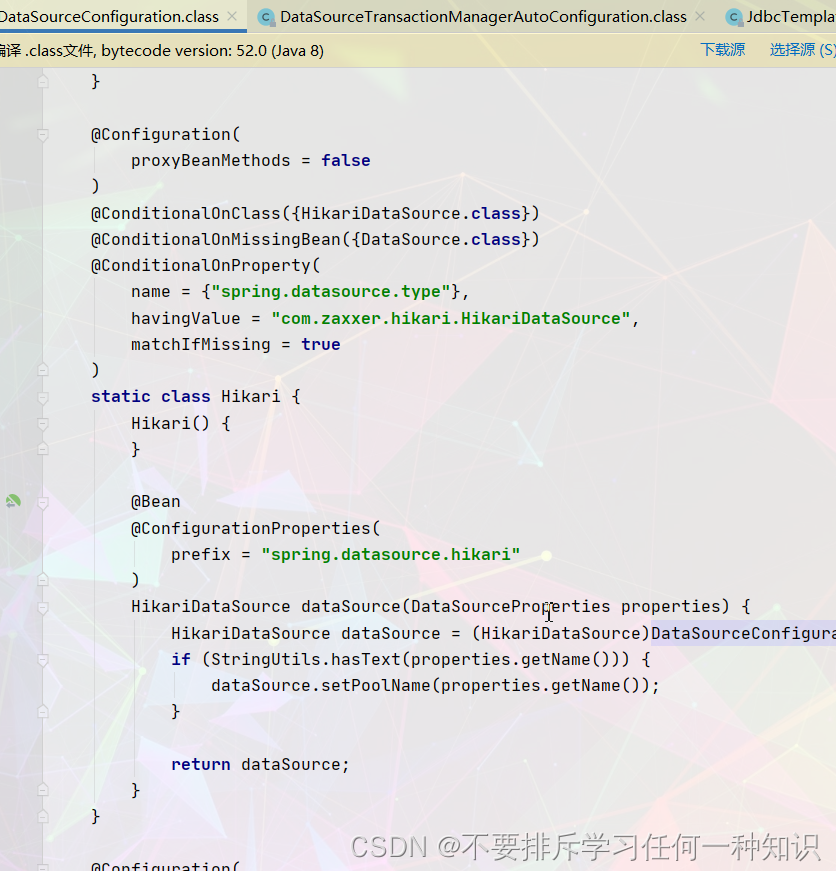
并且对其进行配置
- DataSourceTransactionManagerAutoConfiguration:对事物管理器进行配置
- JdbcTemplateAutoConfiguration:可以对数据库进行操作。可以通过spring.jdbc对配置文件进行配置。
- JndiDataSourceAutoConfiguration:JNDI的自动配置。
- XADataSourceAutoConfiguration:分布式事物。
- DataSourceAutoConfiguration对数据源进行配置
-
可以查询试一试
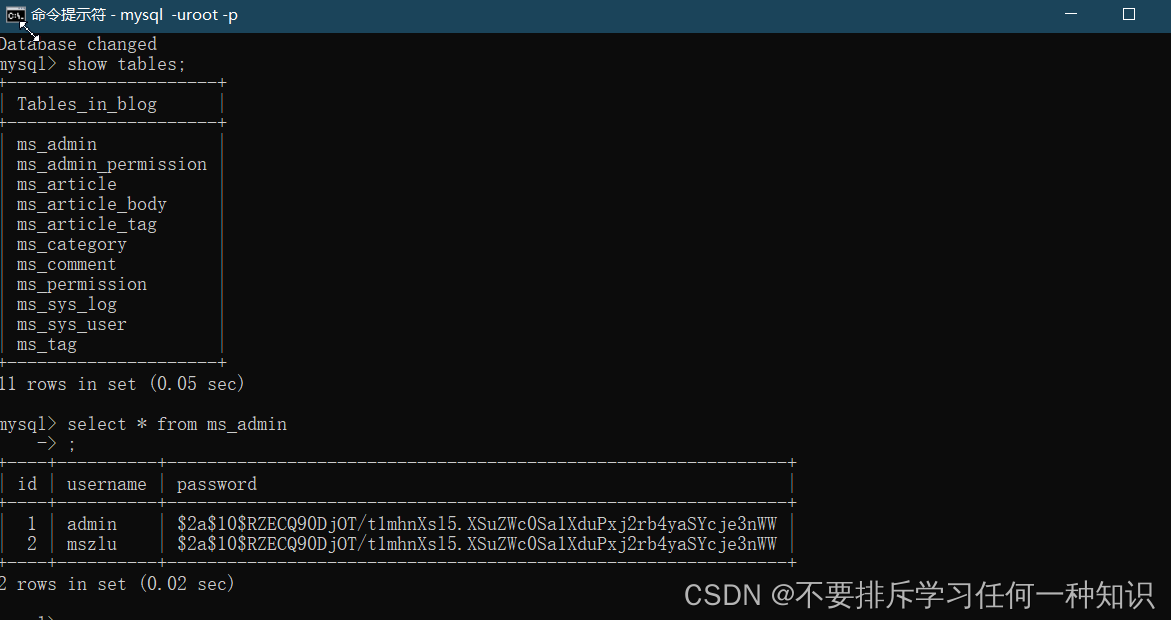
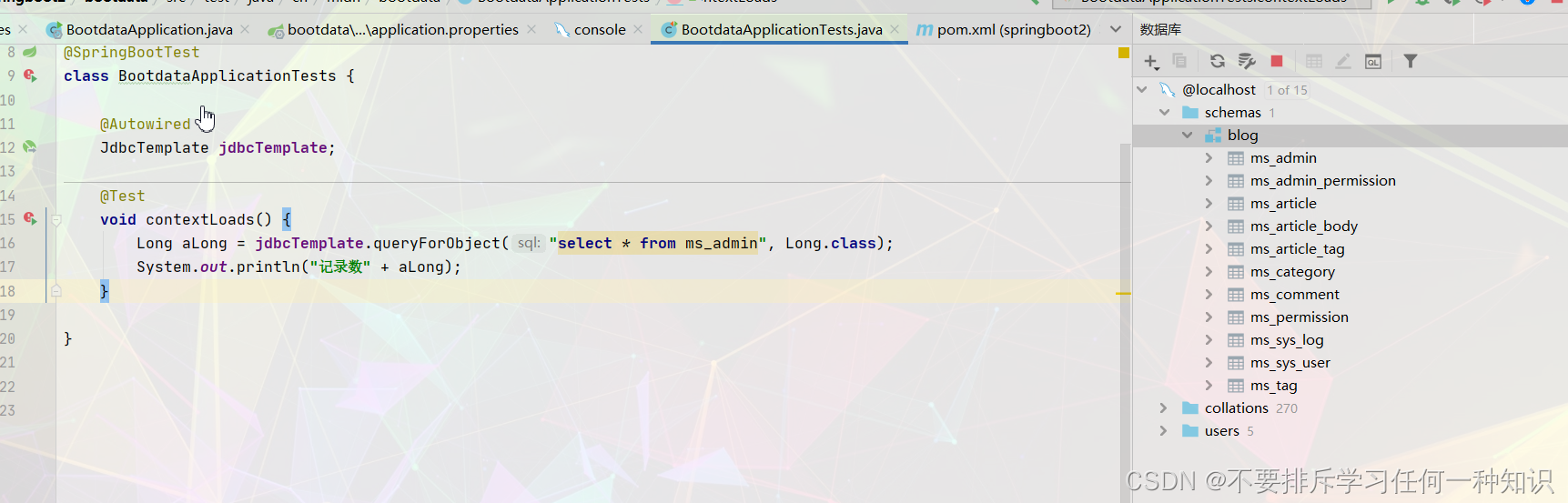
2、自定义整合Druid数据源
- 我们整合其他的框架的,我们SpringBoot有两种方式:自定义和找starter,先看看自定义方式。
- 官网:地址
(1)导入依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.21</version>
</dependency>
(2)编写配置类
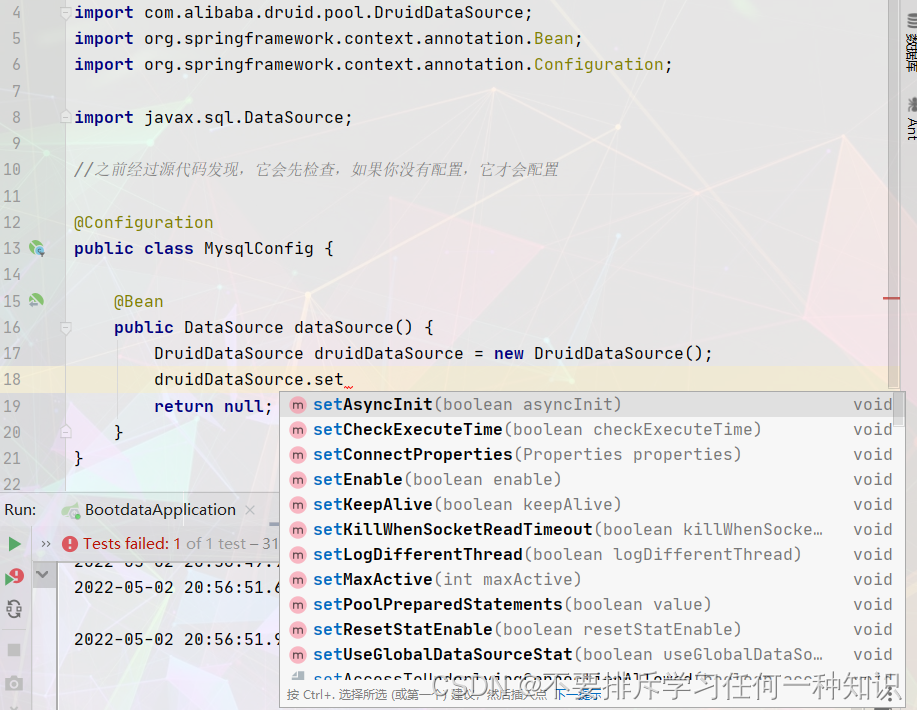
我们这里可以这样写死,但是不建议这样做,因为我们之前在配置文件里面配置了,通过如下方式更快。

说明我们配置生效
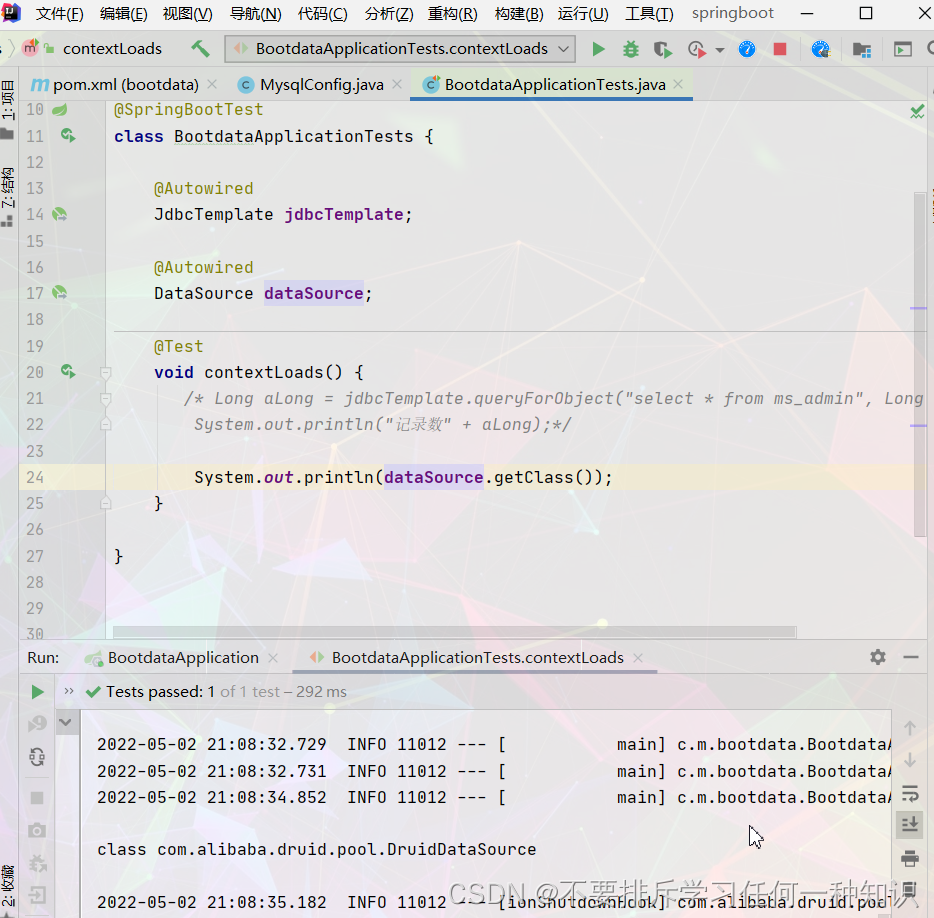
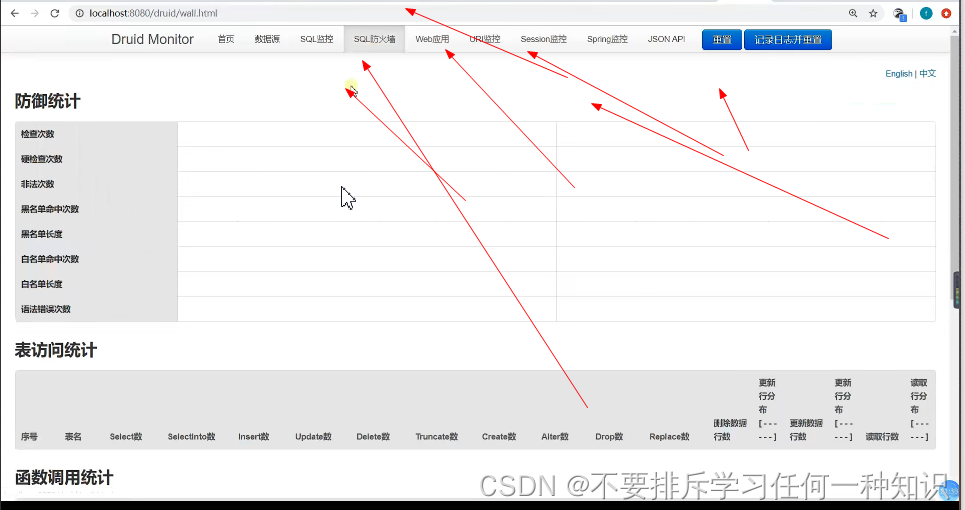
(3)配置监控页面
//之前经过源代码发现,它会先检查,如果你没有配置,它才会配置
@Configuration
public class MysqlConfig {
@ConfigurationProperties("spring.datasource")
@Bean
public DataSource dataSource() {
DruidDataSource druidDataSource = new DruidDataSource();
return druidDataSource;
}
/**
* 配置监控页
* @return
*/
@Bean
public ServletRegistrationBean servletRegistrationBean() {
StatViewServlet statViewServlet = new StatViewServlet();
return new ServletRegistrationBean<StatViewServlet>(statViewServlet,"/druid/*");
}
}
- 监控后要具体请求都要监控的话,那还得配置一下
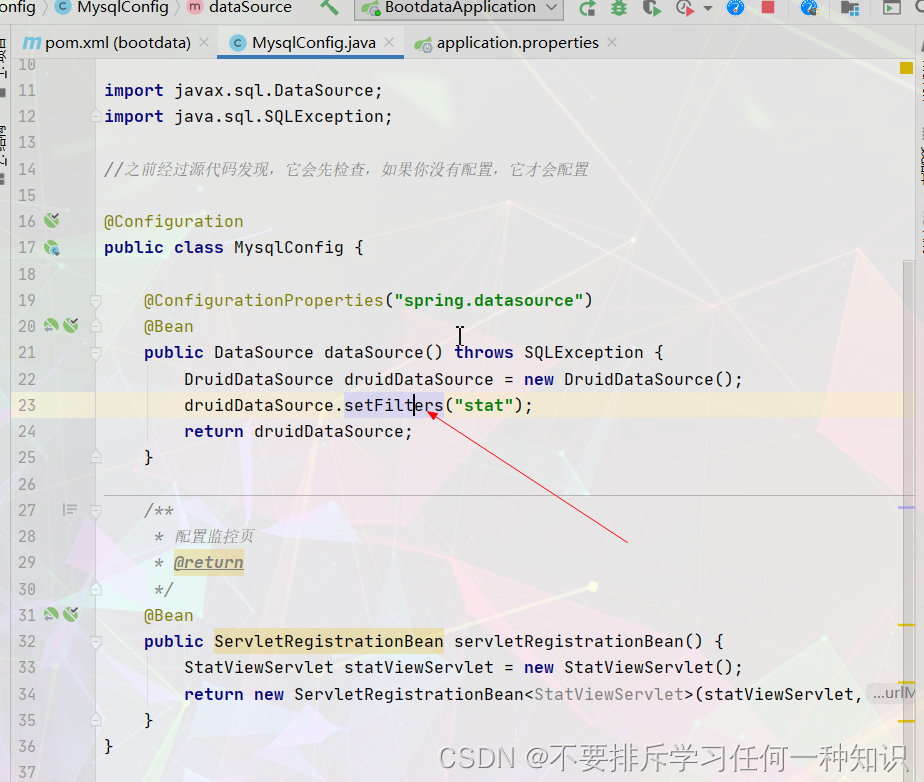
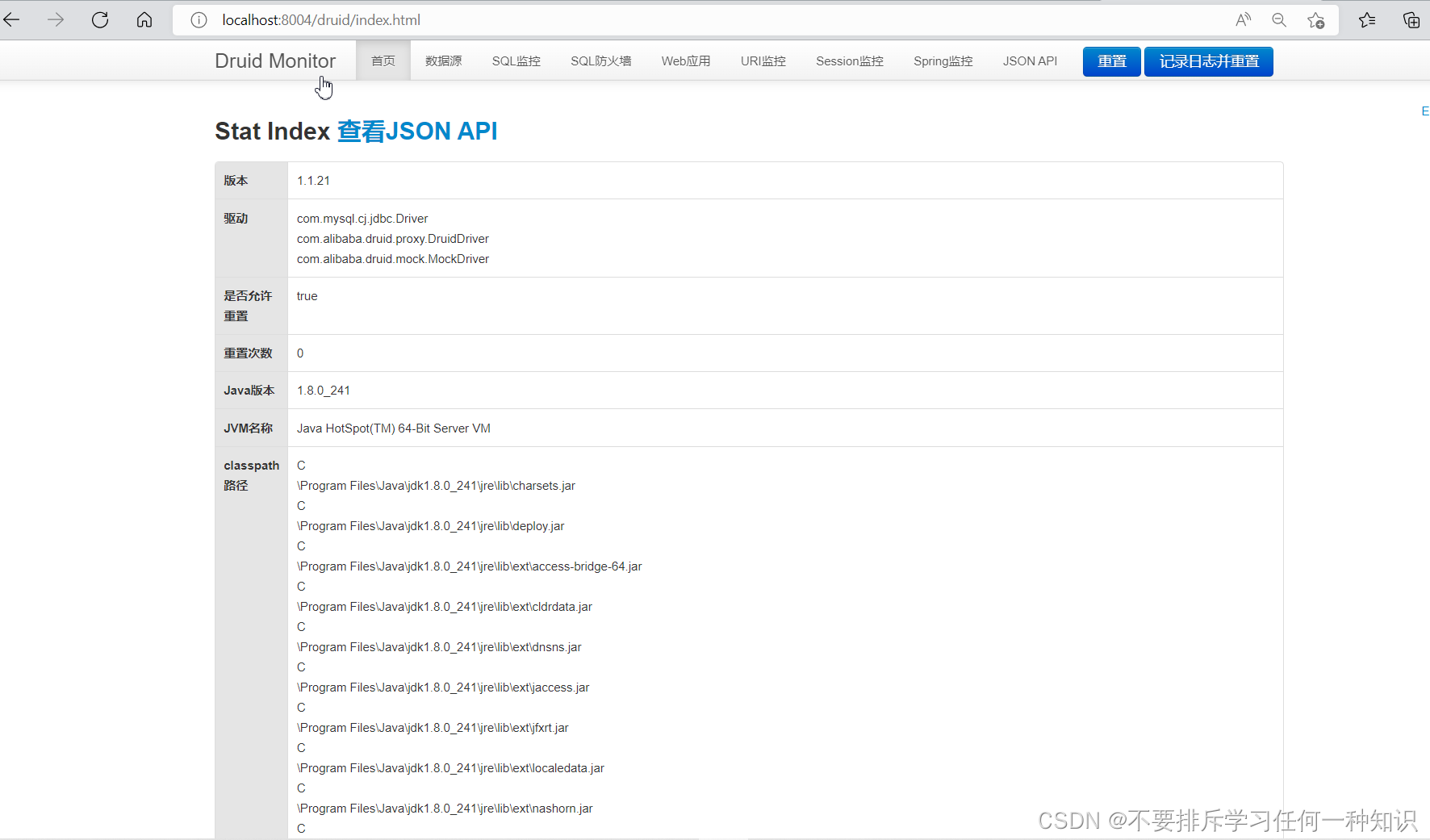
(4)其他配置
都可以去配置
3、导入starter操作Druid数据源
(1)使用过时注解
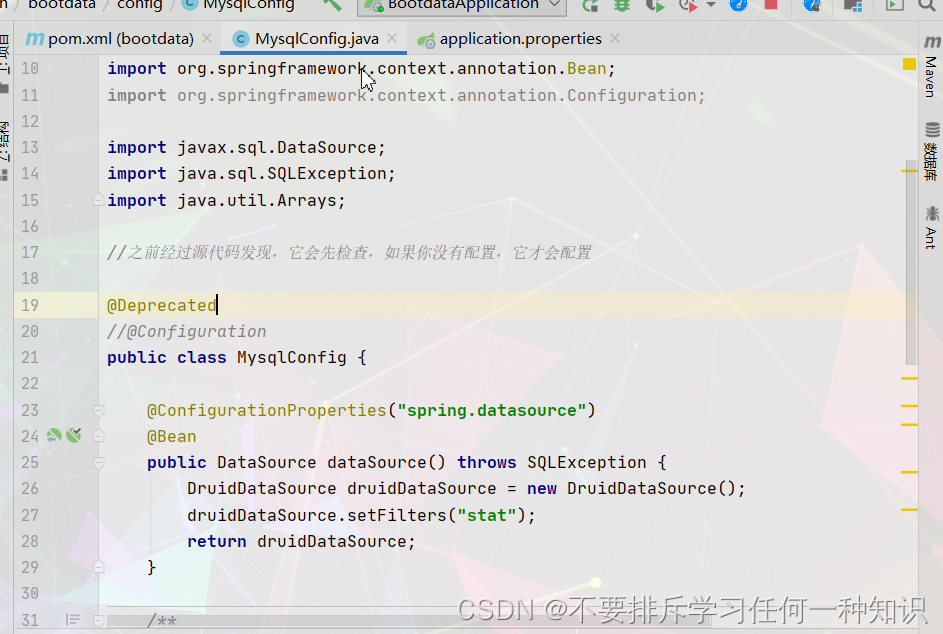
这样导入之后我们之前写的就没用了。
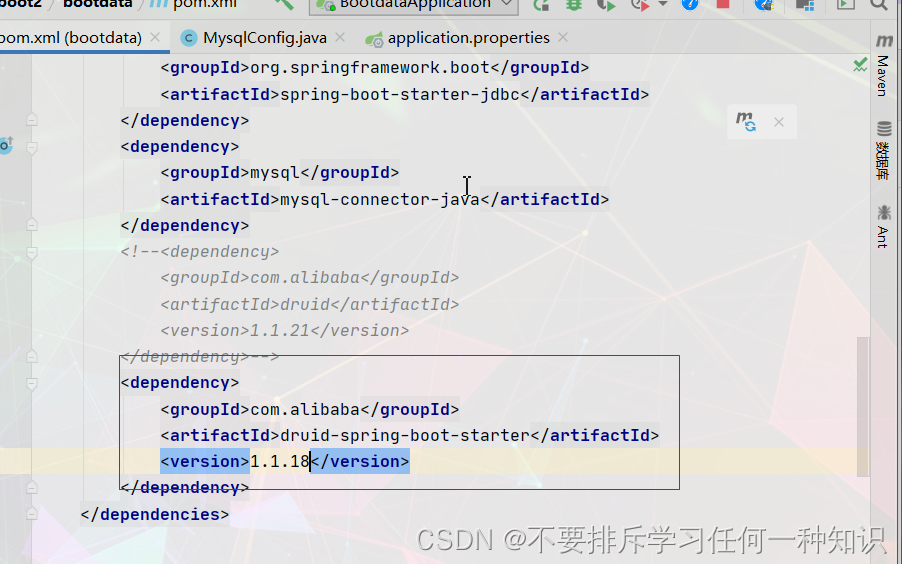
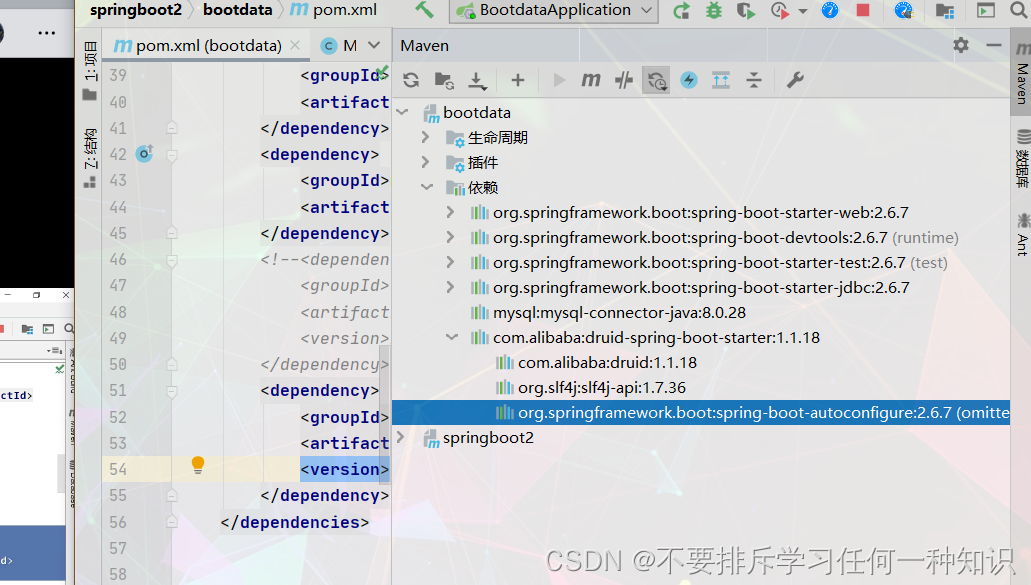
(2)导入依赖
(3)看一下Druid自动配置的原理
-
在这个位置
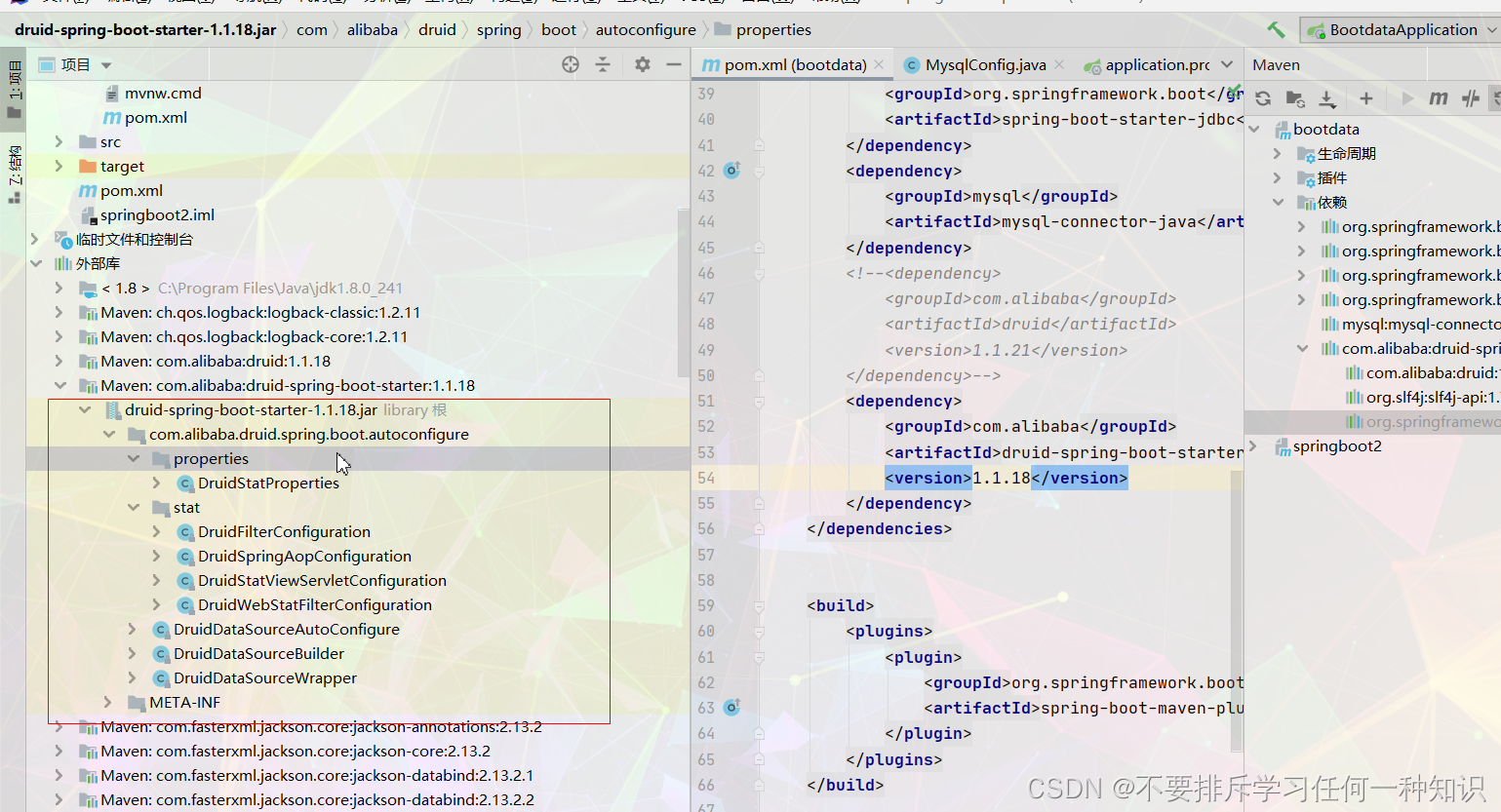
-
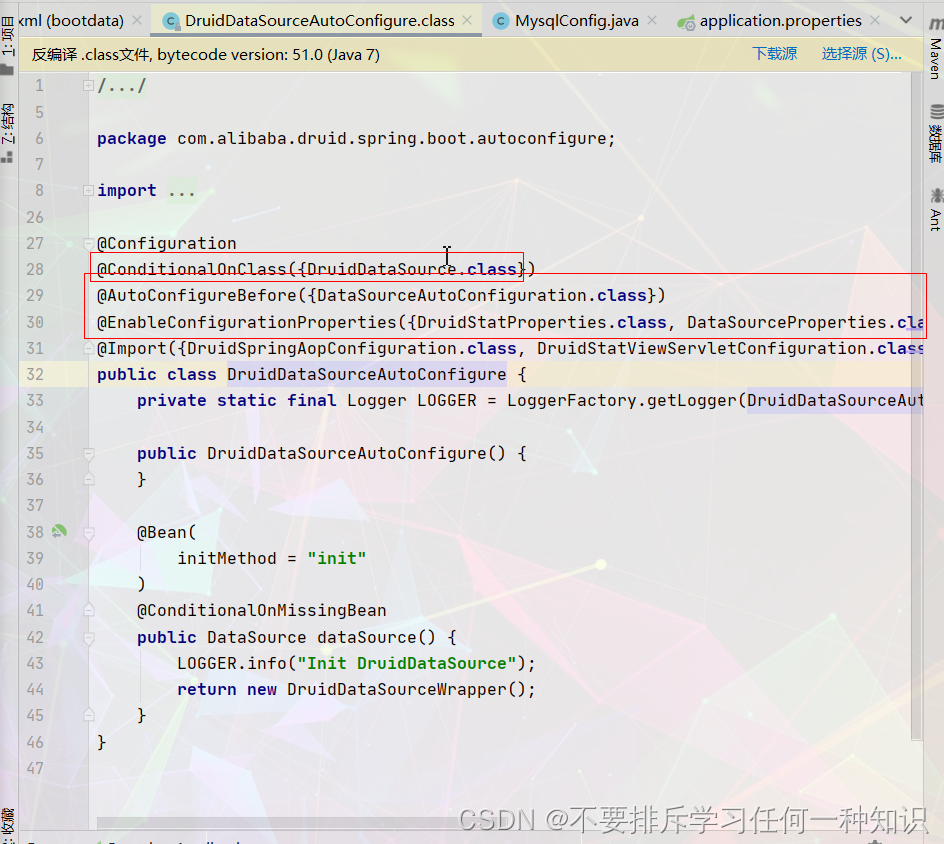
在底层加载spring默认提供的之前就加载
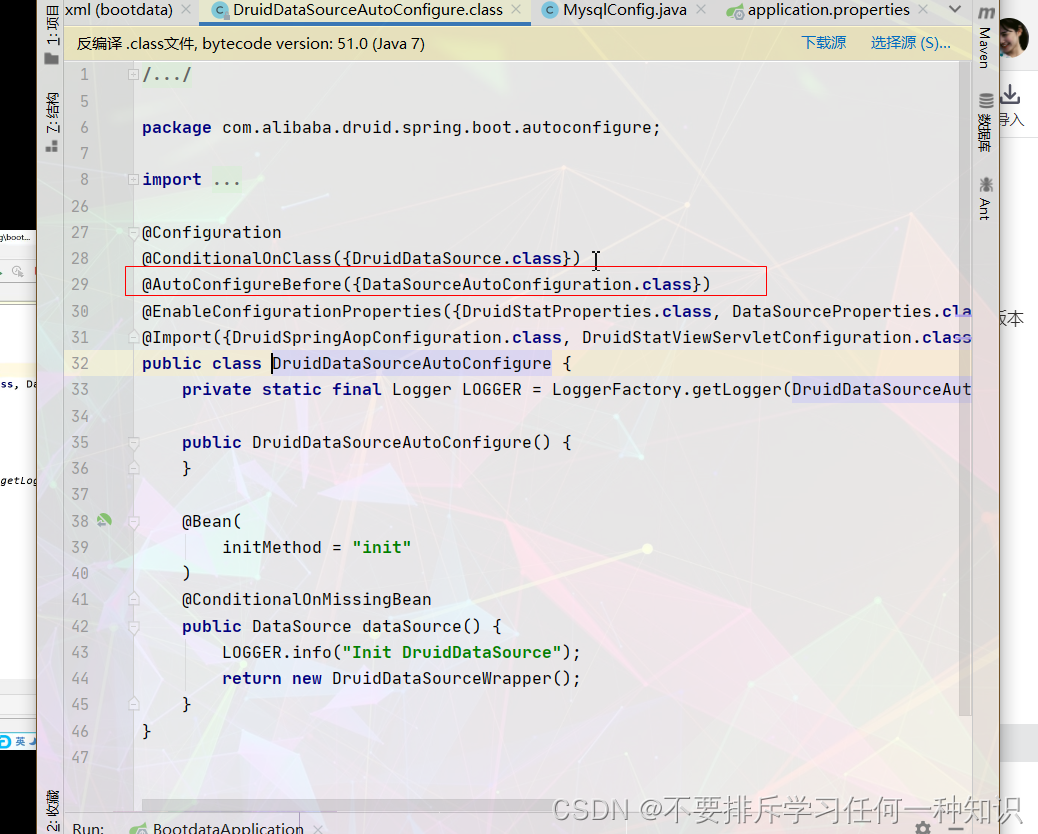
AutoConfigureBefore在我们的spring官方配置的之前,就会先加载我们阿里巴巴的,然后会替代spring自动配置的。 -
导入这些内容:这里就通过AOP配置监控页面。
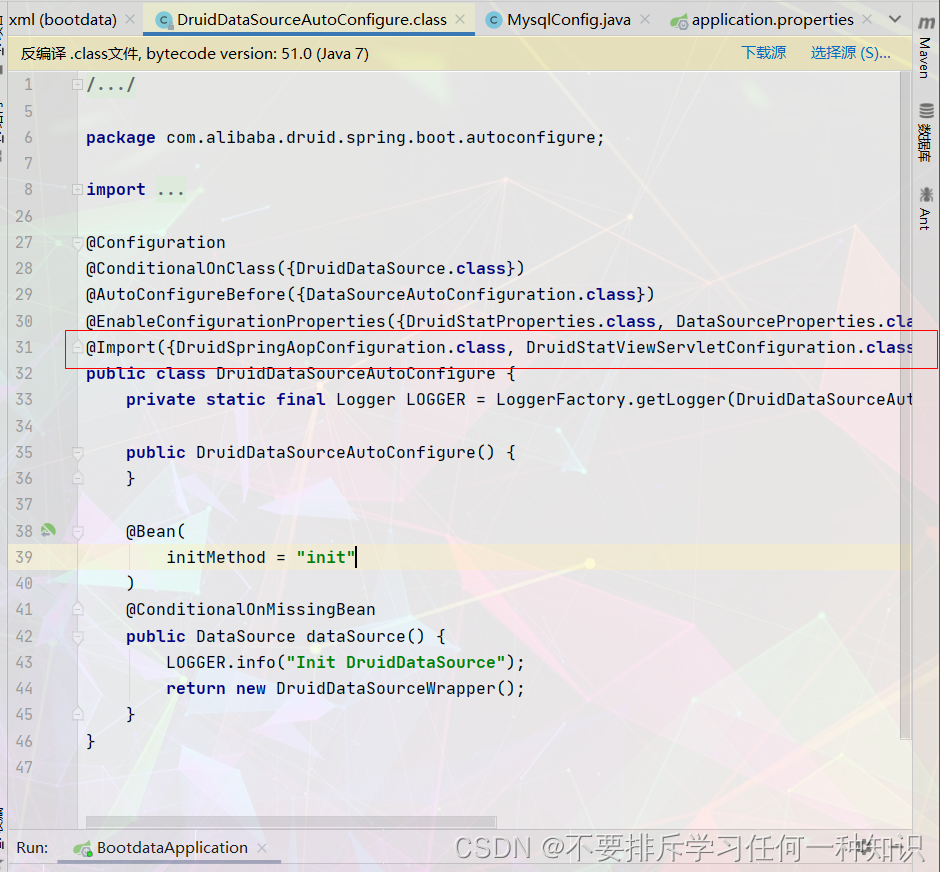
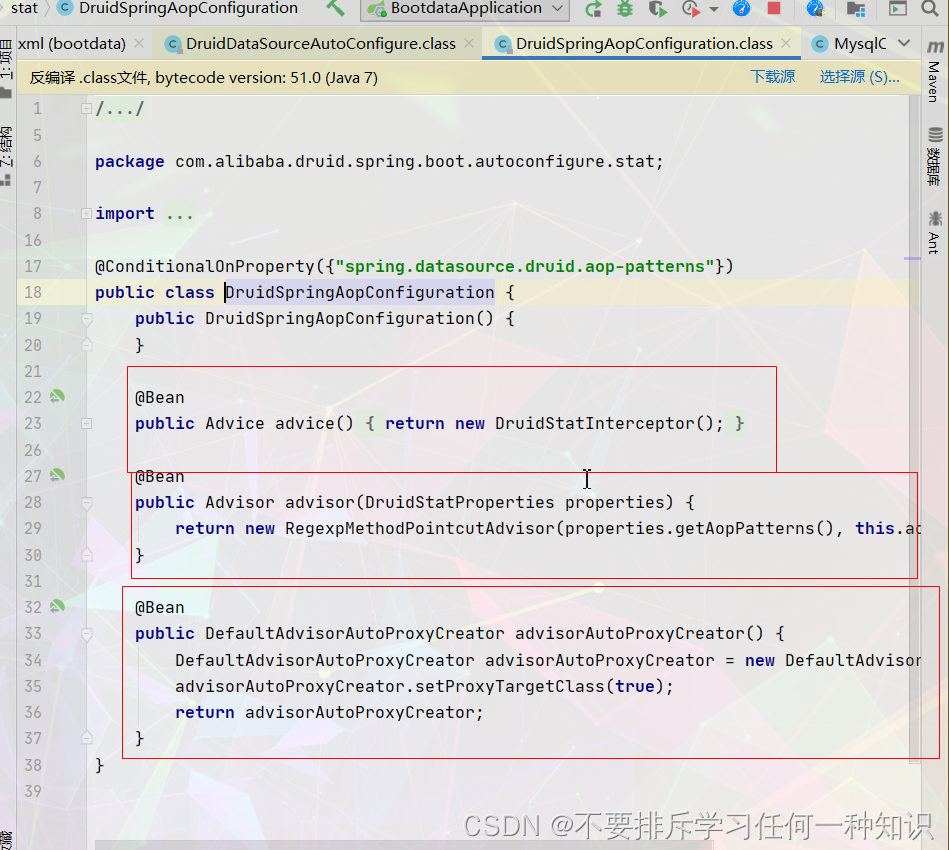
监控springbean的配置项:spring.datasource.druid.aop-patterns
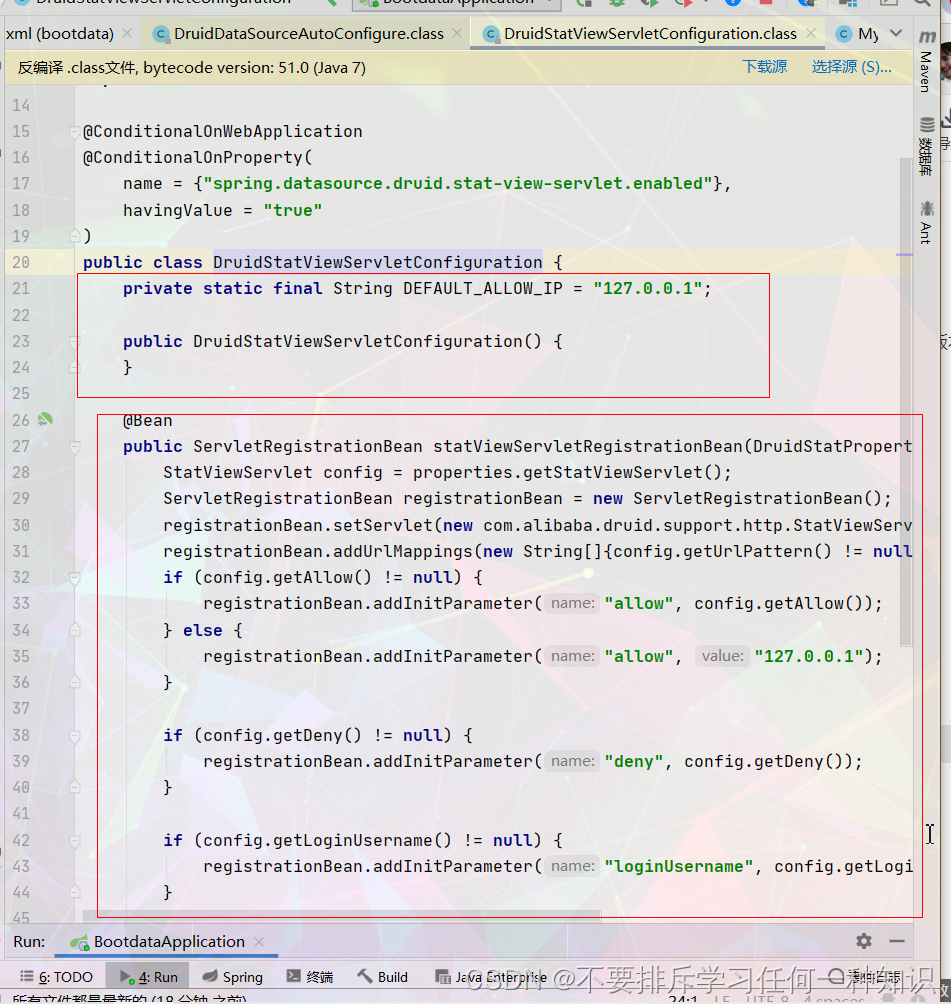
监控页的配置项:spring.datasource.druid.stat-view-servlet.enabled
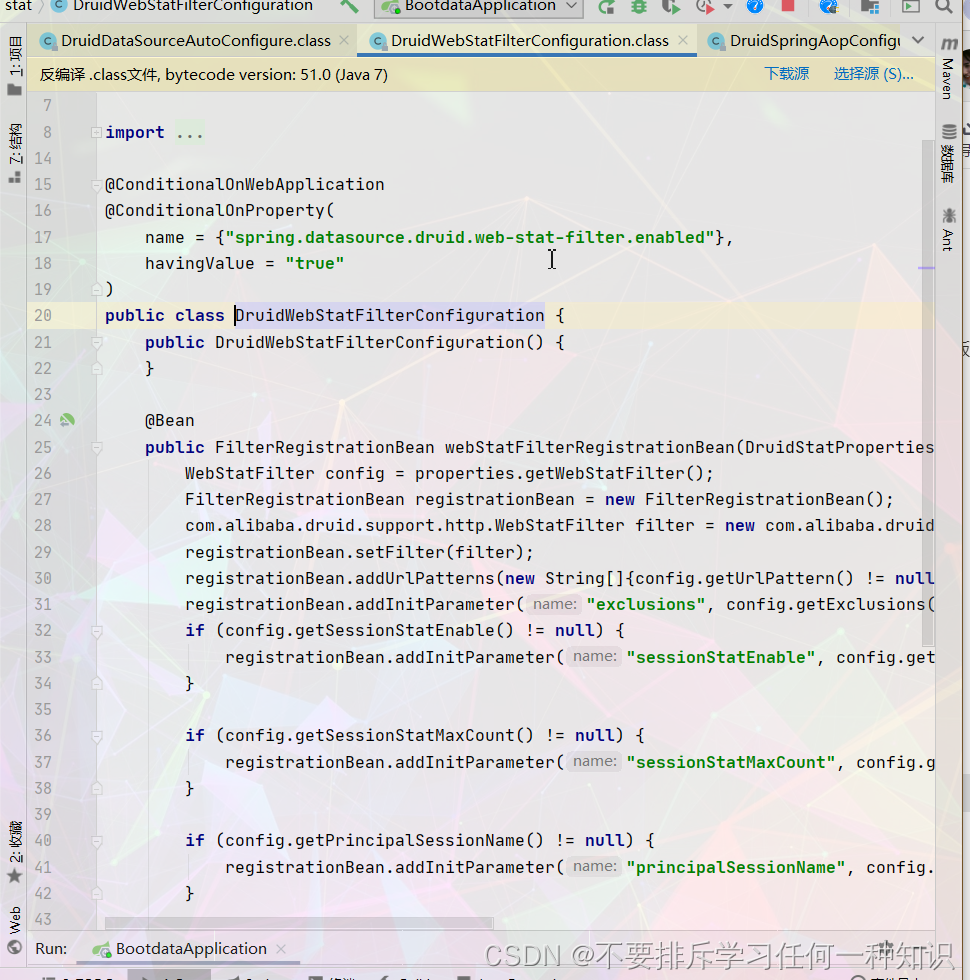
web监控配置:spring.datasource.druid.web-stat-filter.enabled
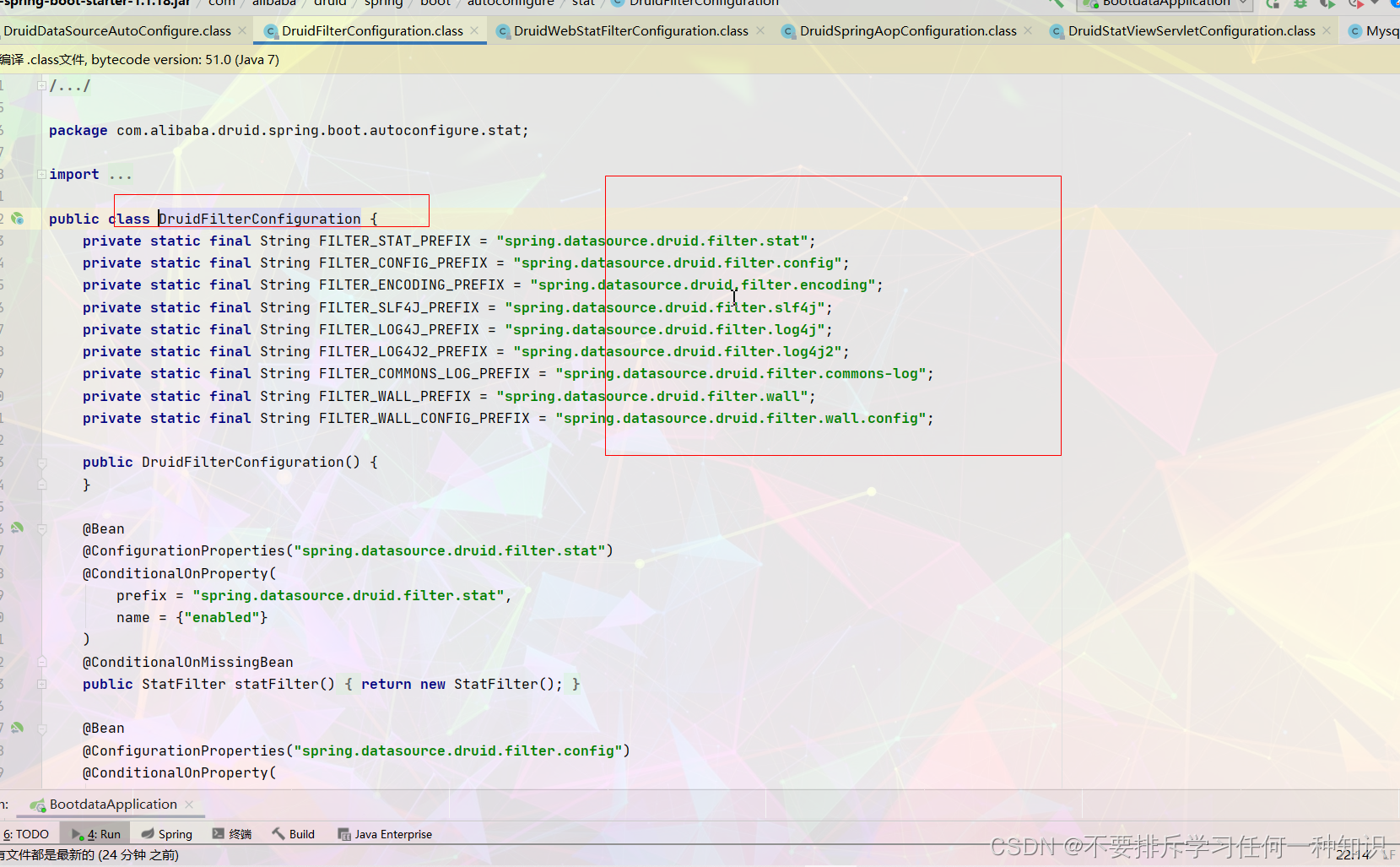
底层又这么一些组件,所有的自己的filter的配置。 -
分析总结:经过上面的分析发现,我们不用再配置什么,然后直接在配置文件写相印的配置,然后在加载的时候就可以了。
(4)进行配置
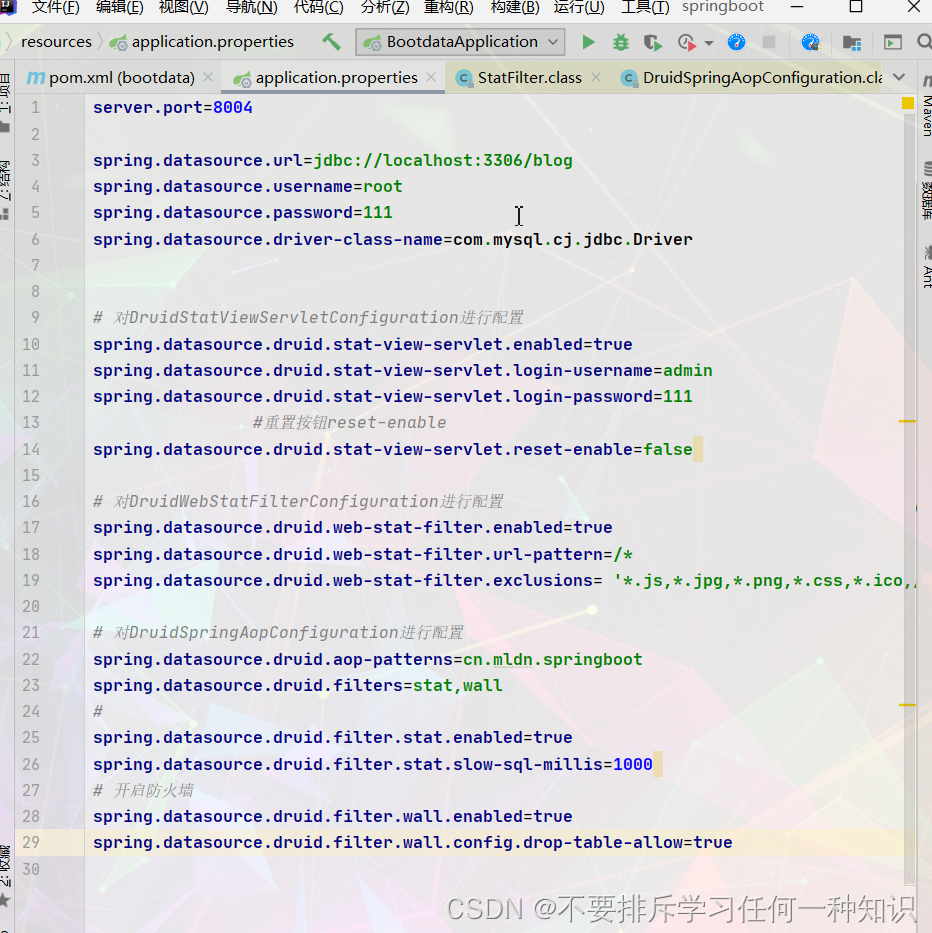
之后如果详细配置就可以参考https://github.com/alibaba/druid/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98与我们的DruidDataSourceAutoConfigure类进行配置即可。
(二)整合Mybatis整理
1、配置方式使用mybatis
(1)导入依赖
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.4</version>
</dependency>
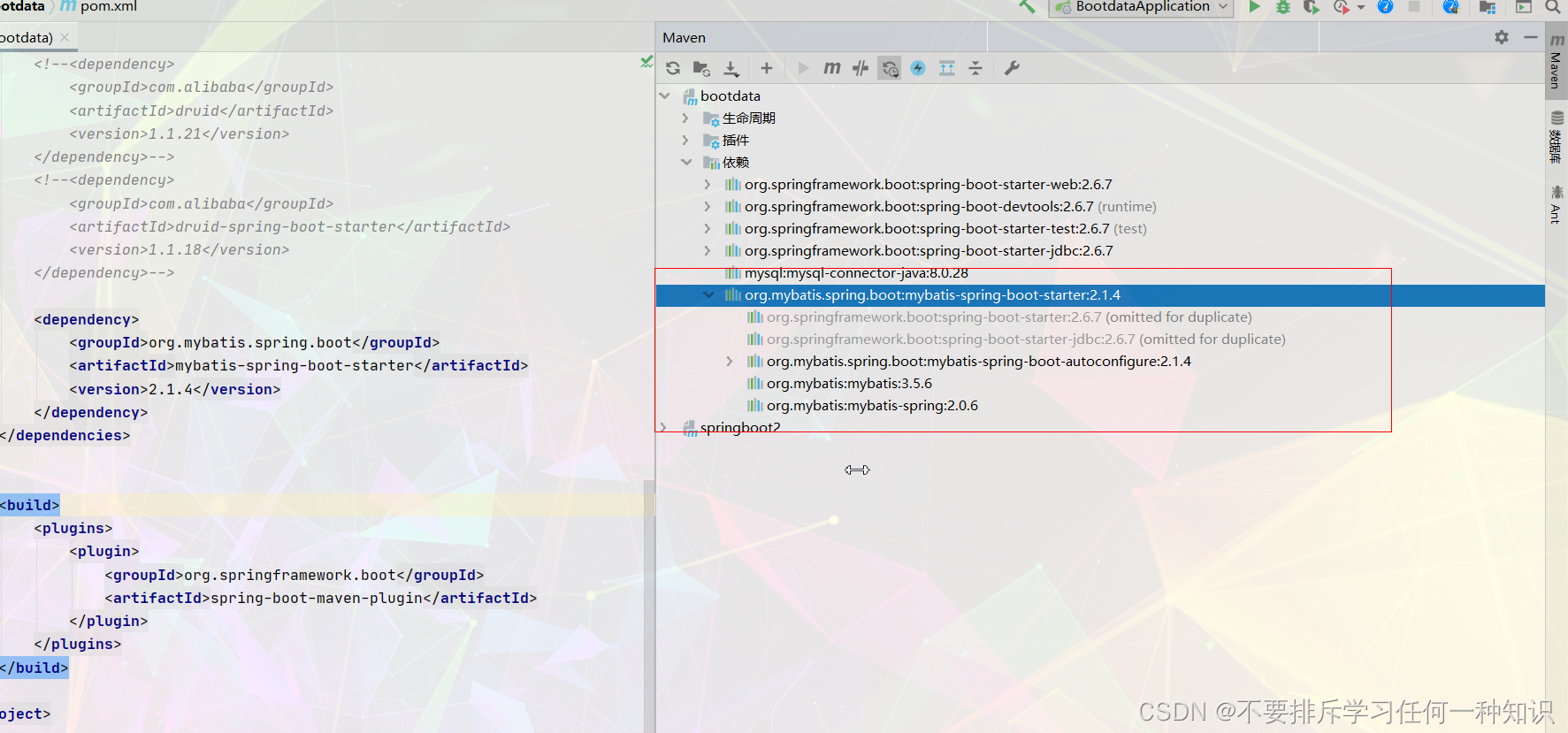
(2)看看原理
老模式配置模式,使用mybatis是全局配置文件
-
sqlSessionFactory
-
sqlSession进行操作
-
Mapper
-
看看原理
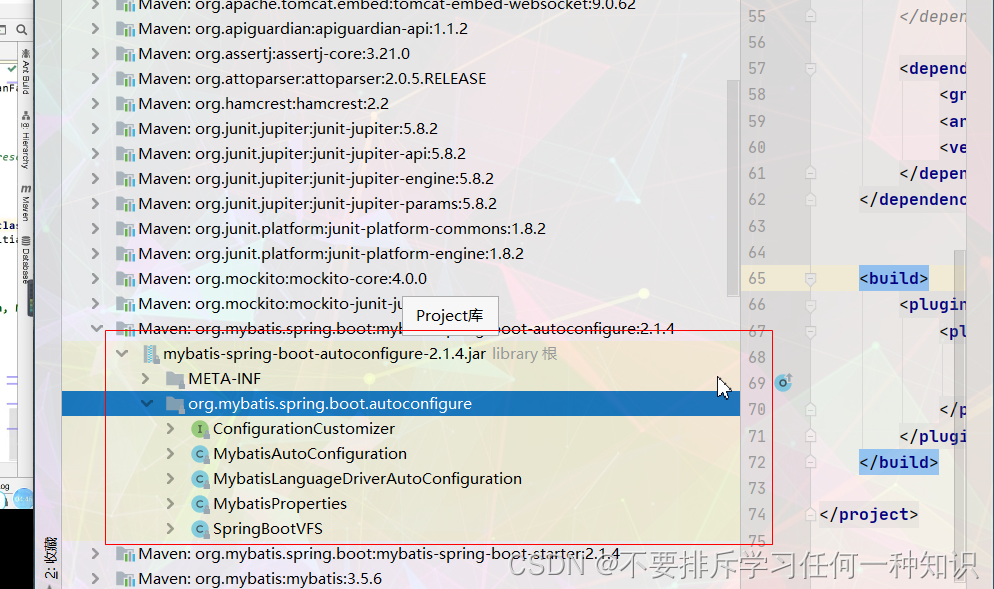
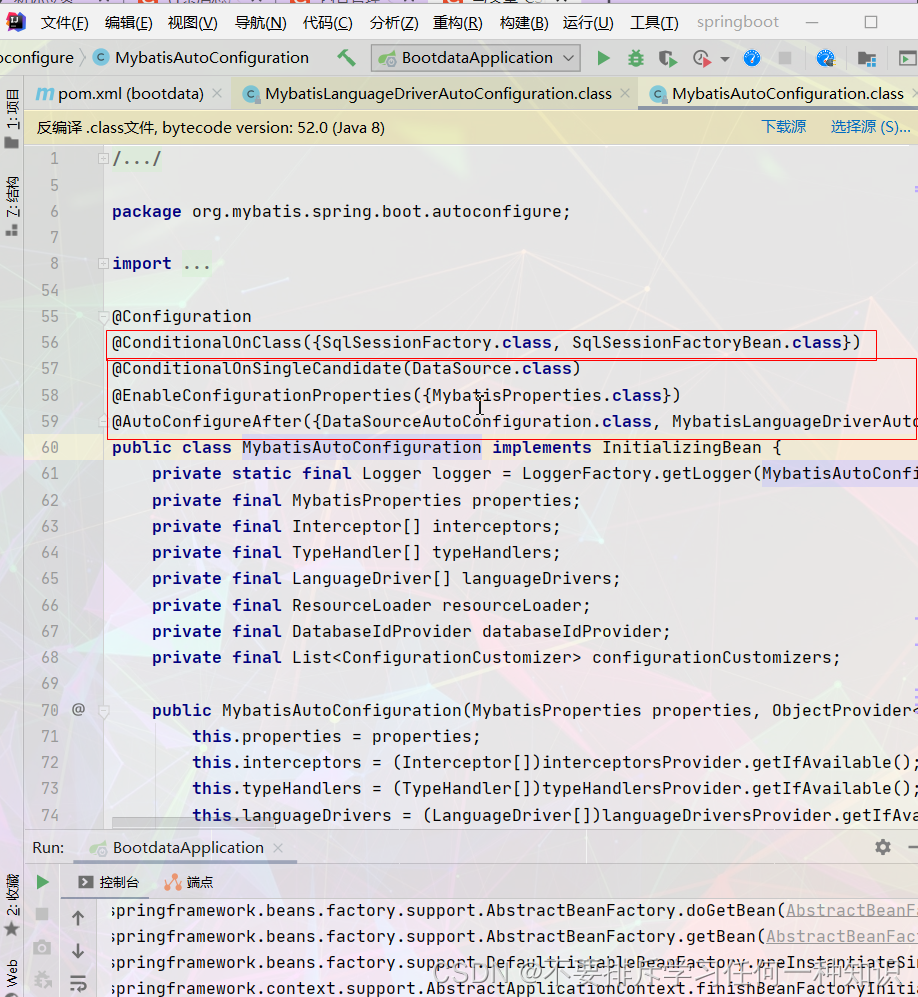
- 所有的配置项都在这里:EnableConfigurationProperties,在这MybatisProperties。
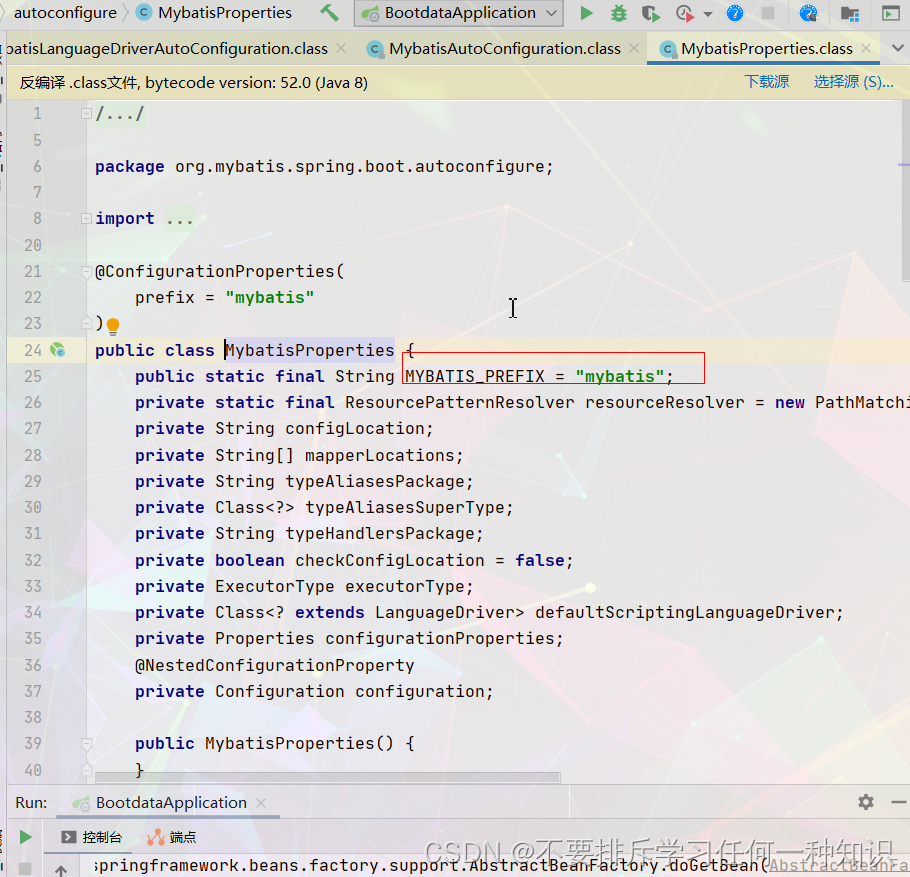
- 配置好了:sqlsessionfactory
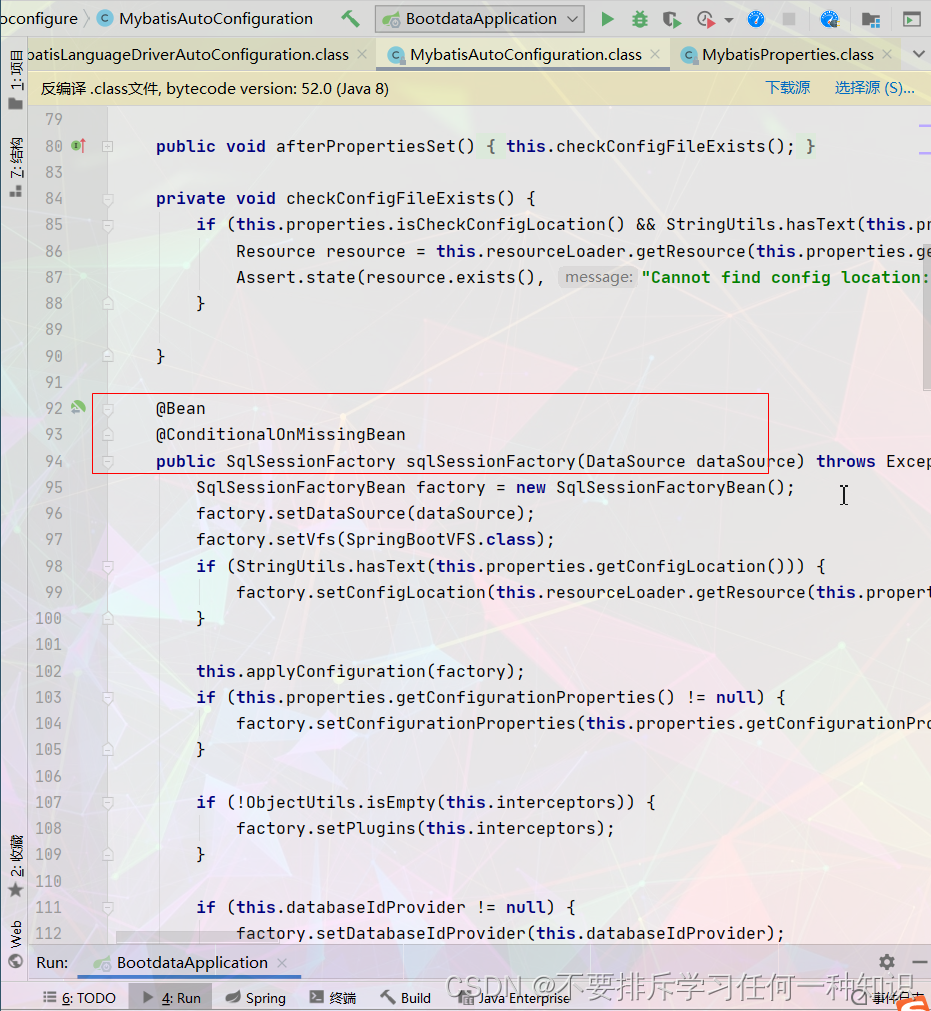
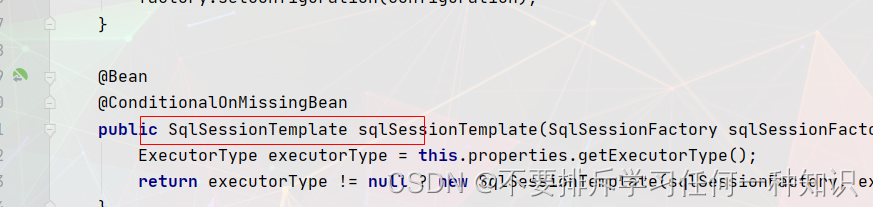
- 配置sqlsessionTemplate(相当于sqlsession)
- 导入了这个(以前有这个,我们会设置包的导入)
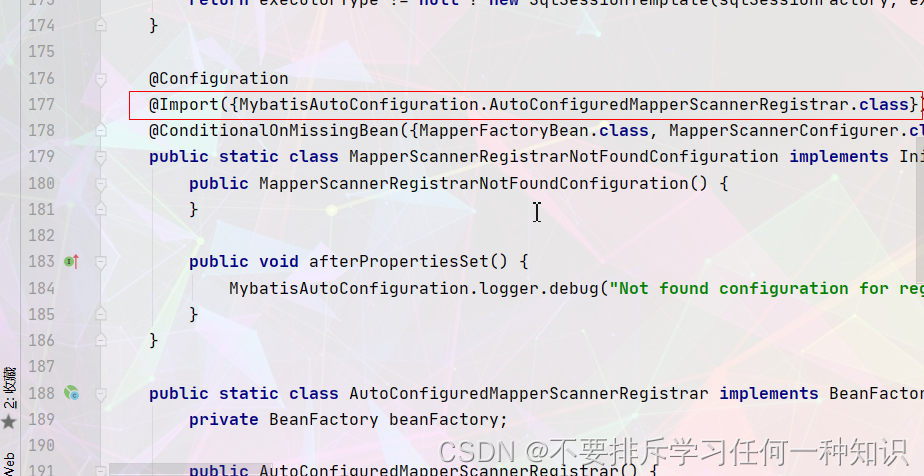
- mapper:只要我们使用了@Mapper注解,就会被自动扫描进来。
- 所有的配置项都在这里:EnableConfigurationProperties,在这MybatisProperties。
(3)进行配置
https://mybatis.net.cn/getting-started.html
-
在导入依赖的前提下配置一个全局文件
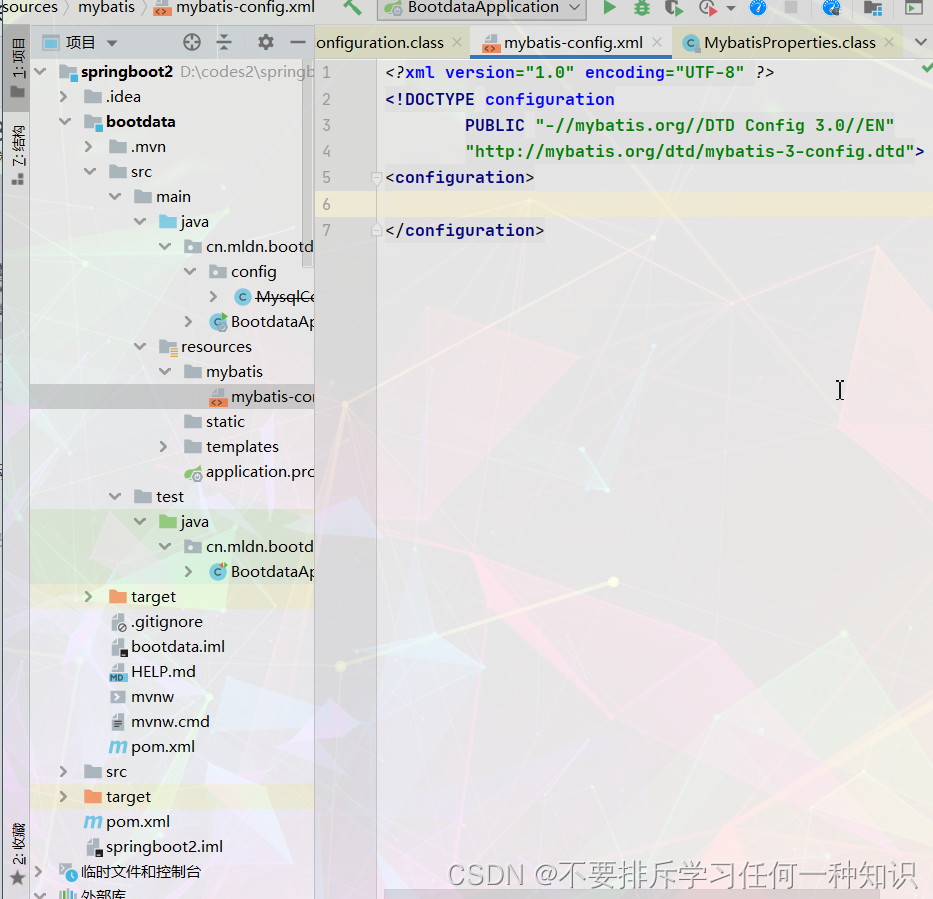
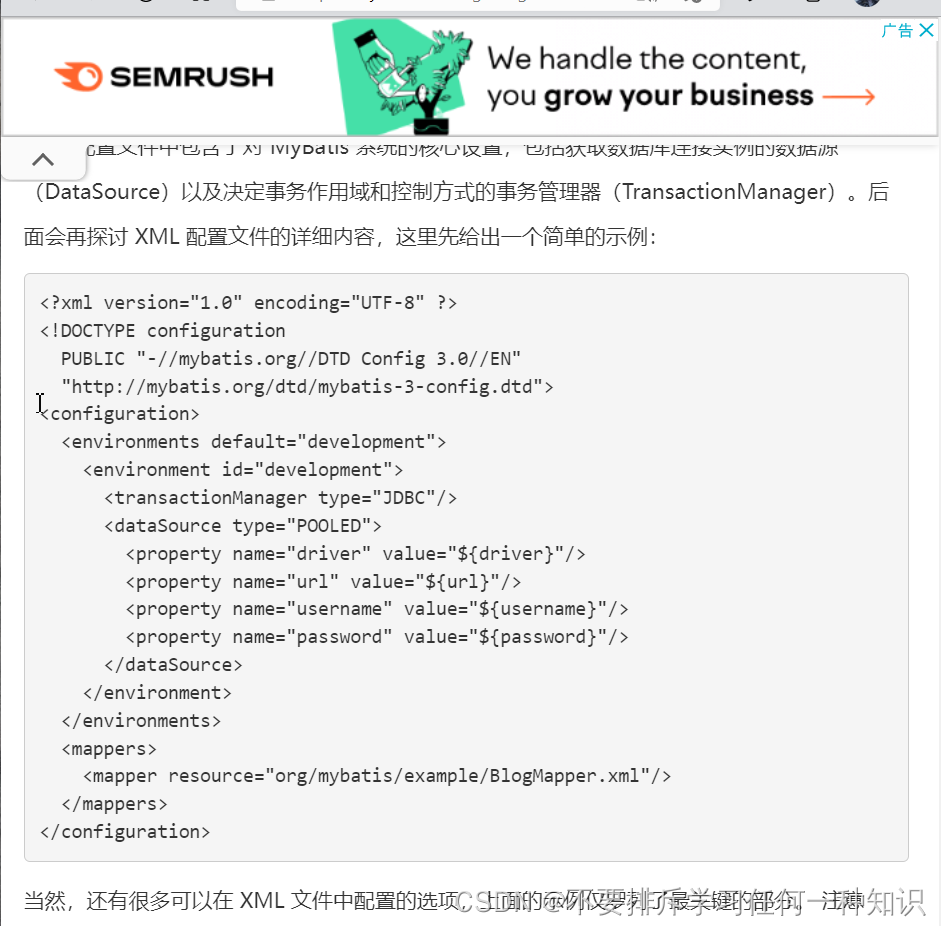
我们不用配置具体内容,因为SpringBoot已经给我们配置了。
-
经过上面的配置后文件映射(具体过程就两个
)- 准备好mapper接口方法
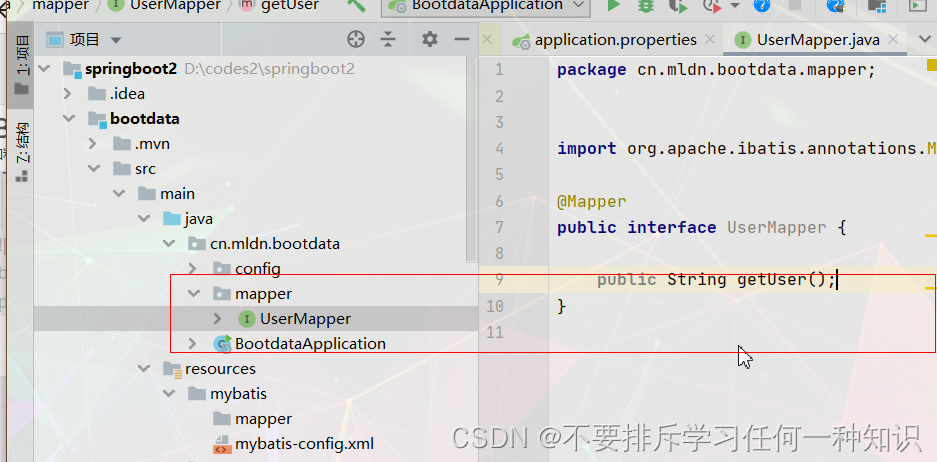
这个接口里面的方法,就会被在service层进行调用。 - 然后准备好SQL语句
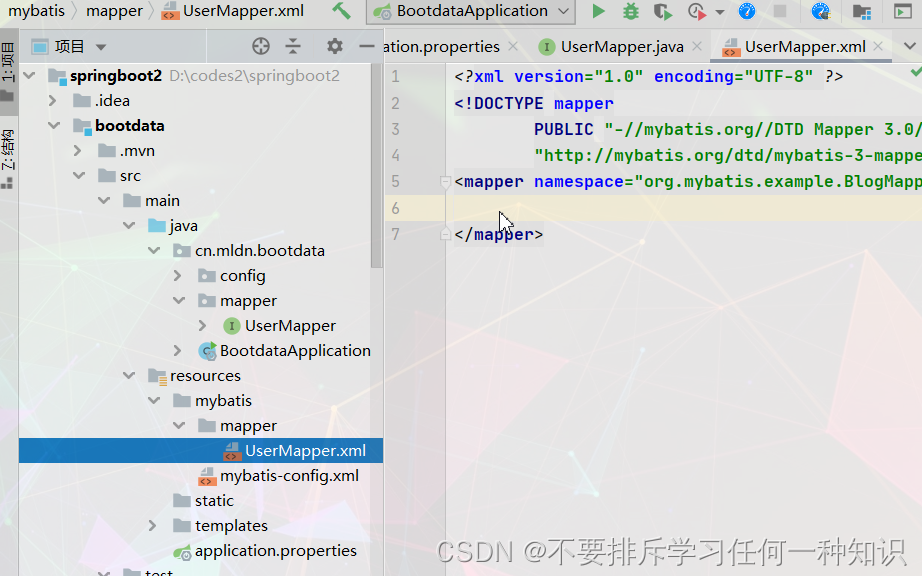
补充映射文件
- 准备好mapper接口方法
-
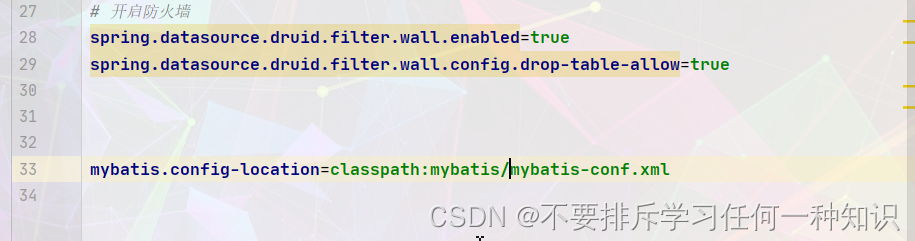
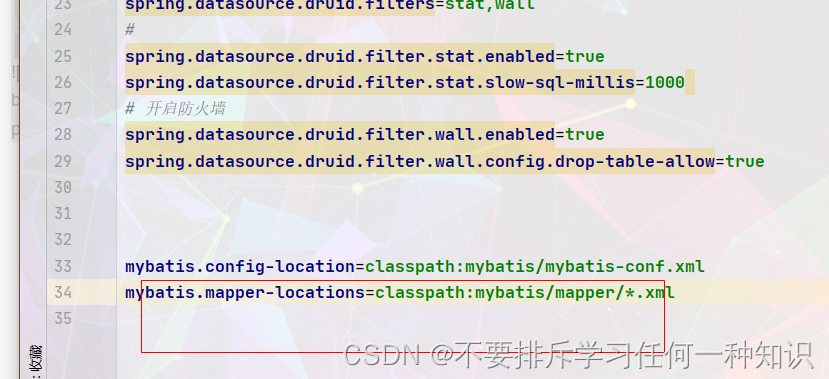
其实就是执行全局配置文件地址和映射文件地址:
mybatis.config-location=classpath:mybatis/mybatis-conf.xml
mybatis.mapper-locations=classpath:mybatis/mapper/*.xml
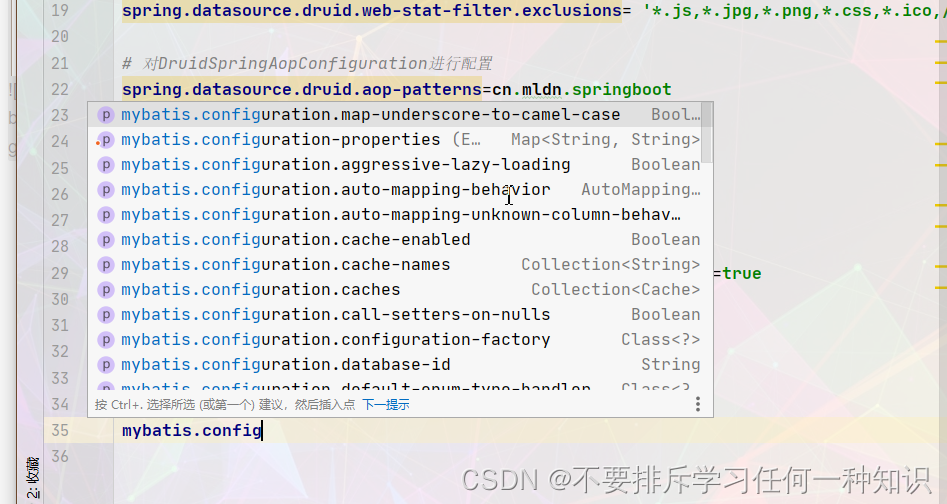
- 可以设置的项
(4)使用总结
- 导入mybatis依赖
- 编写mapper接口
- 编写SQL映射文件
- 在application.yaml执行mapper配置文件地址。
2、注解方式实现mybatis
(1)使用注解
-
首先创建你的表和对应的实体类。
-
然后就是些mapper接口方法。

这里我们就不再使用映射文件了,而是使用纯出街的方式实现的。(同样的也是还是insert啊,update 等字段的) -
然后后续的就是默认的service层调用我们的mapper层。
另外我们也可以两个混着使用,当你某一个方法的SQL语句非常大的时候,那就可以使用混着使用,单独写一个映射文件。
(2)mapper注解的使用
- 我们可以在每一个写的SQL查询接口上上@Mapper注解
- 我们也只用@MapperScan(“指定你mapper文件地址”)在启动类上加
(三)整合Mybatis-plus
https://baomidou.com/pages/24112f/#%E7%89%B9%E6%80%A7
1、使用插件
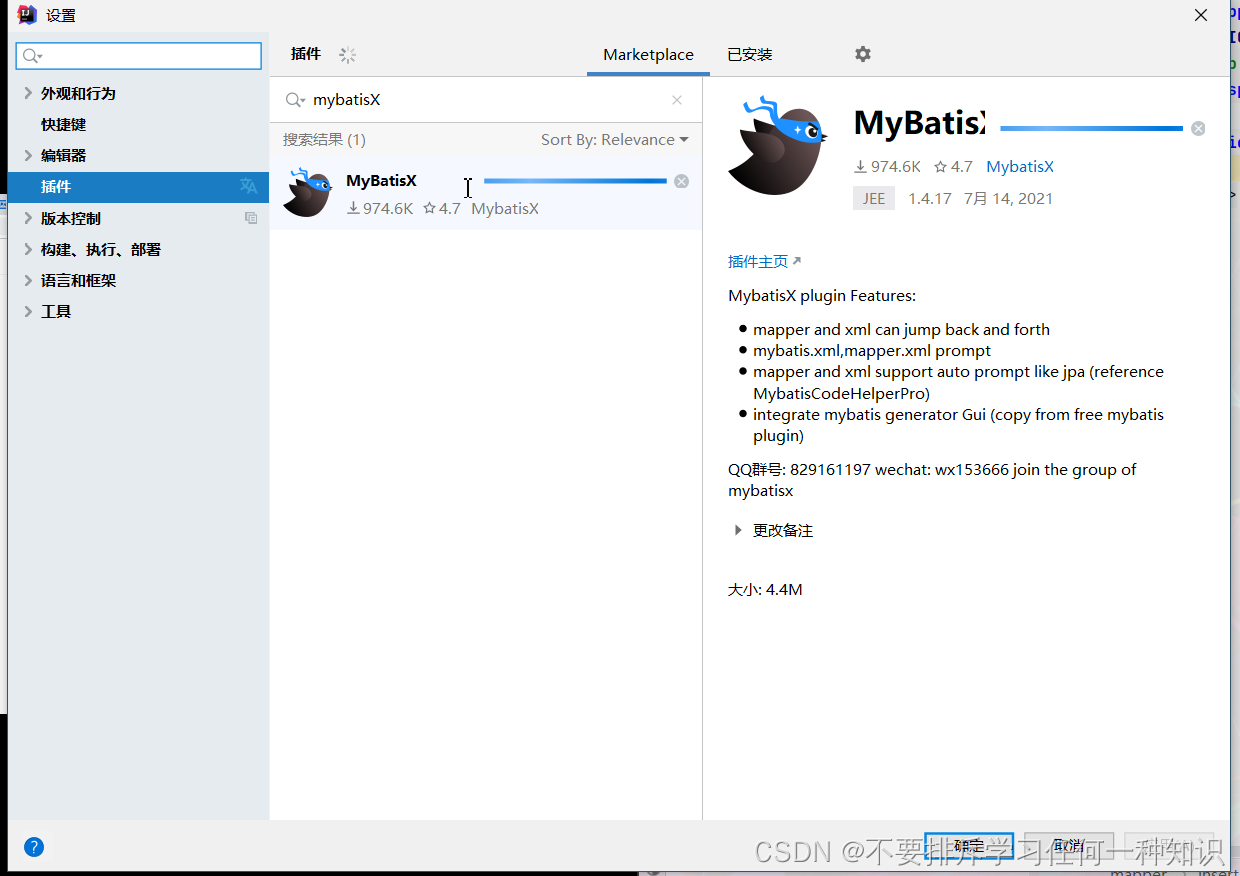
这个可以实现XML的跳转,旁边会给你有小鸟。还有生成代码。语法提示等。
2、例子演示
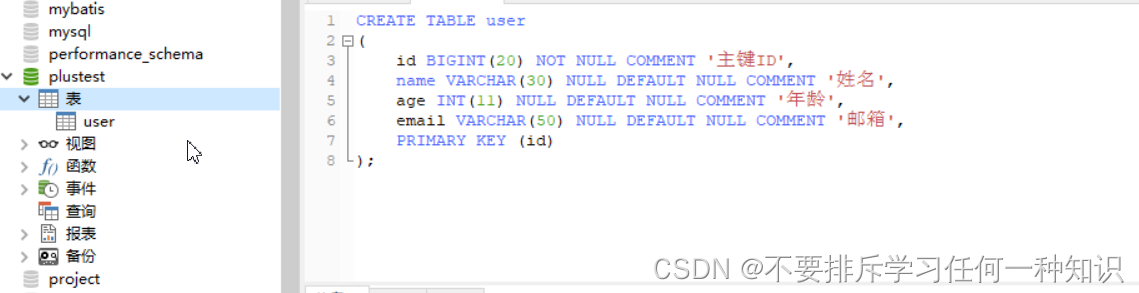
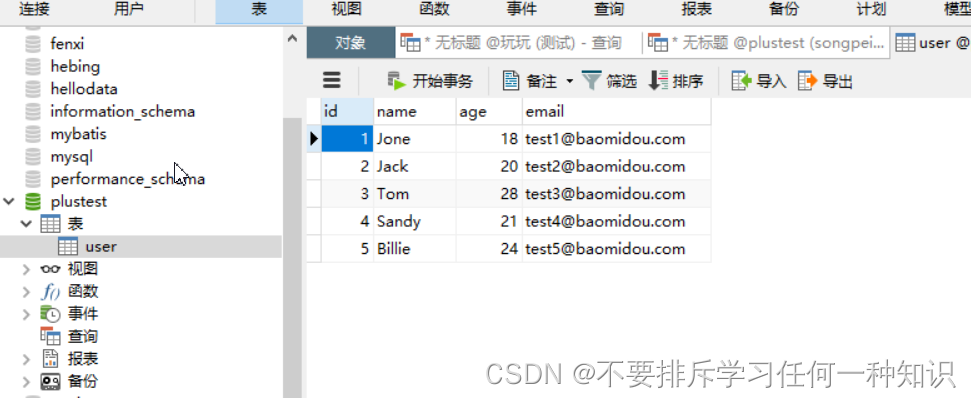
(1)创建表
- 创建表
(2)创建model
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.3</version>
</dependency>
</dependencies>
- 配置yaml
server:
port: 8005
spring:
datasource:
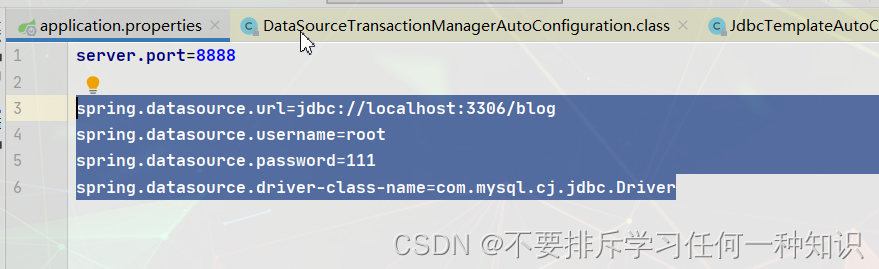
url: jdbc://localhost:3306/blog
username: root
password: 111
driver-class-name: com.mysql.cj.jdbc.Driver
(3)业务逻辑
- 再次配置启动类
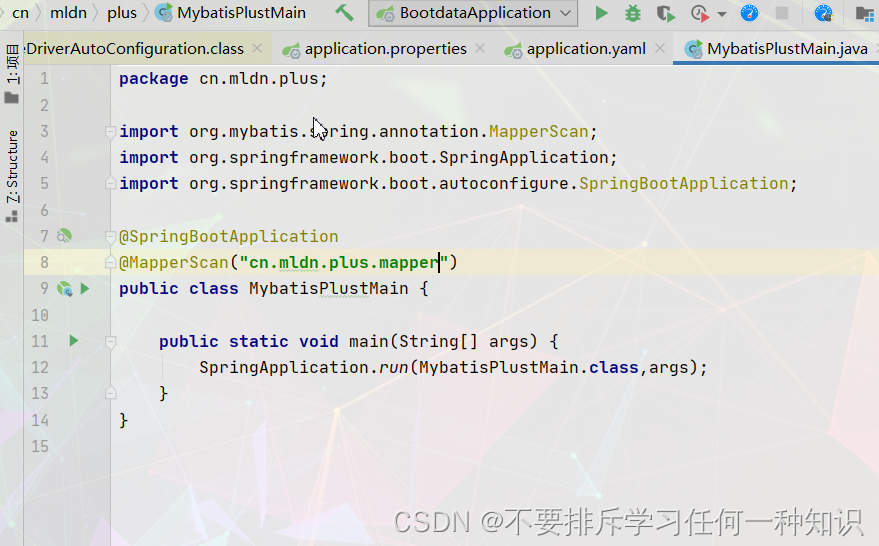
- 编写Mapper接口和实体类
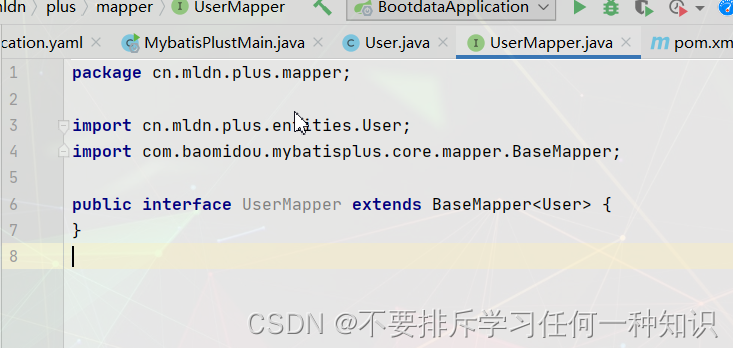
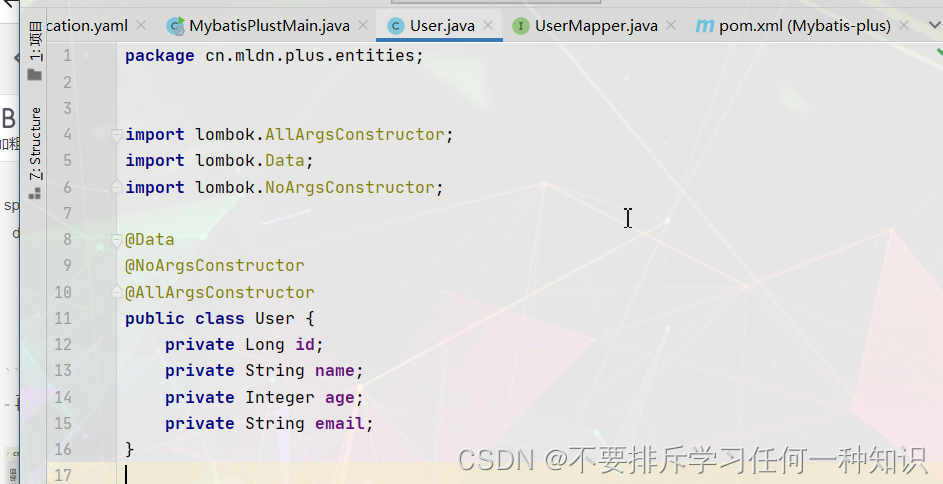
- 编写select方法
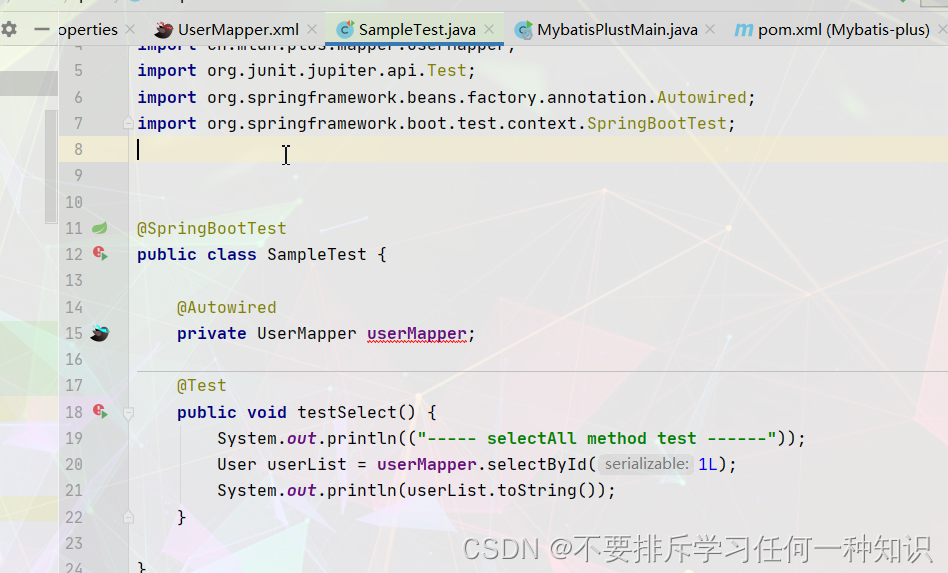
它给配置好了,我的测试报错,但是按着步骤来是没什么问题的,我一会恰饭回来再看看。
3、分析一下自动配置
同样的也是来到这里。
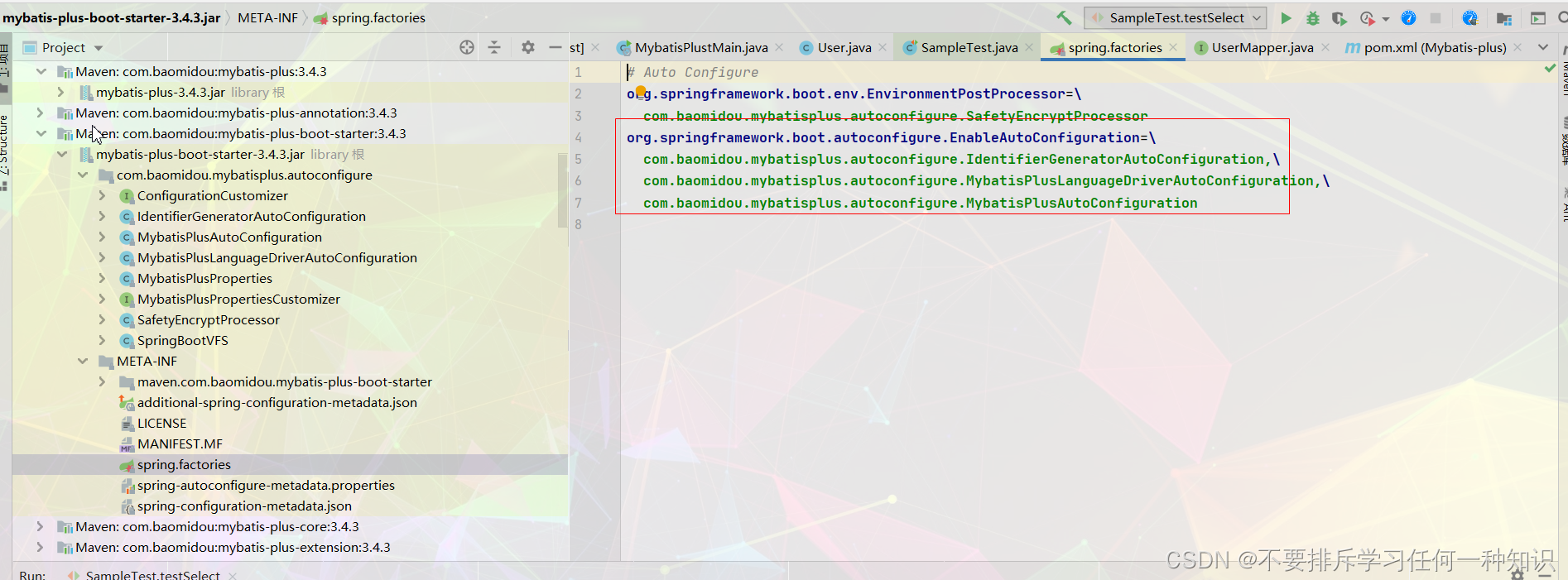
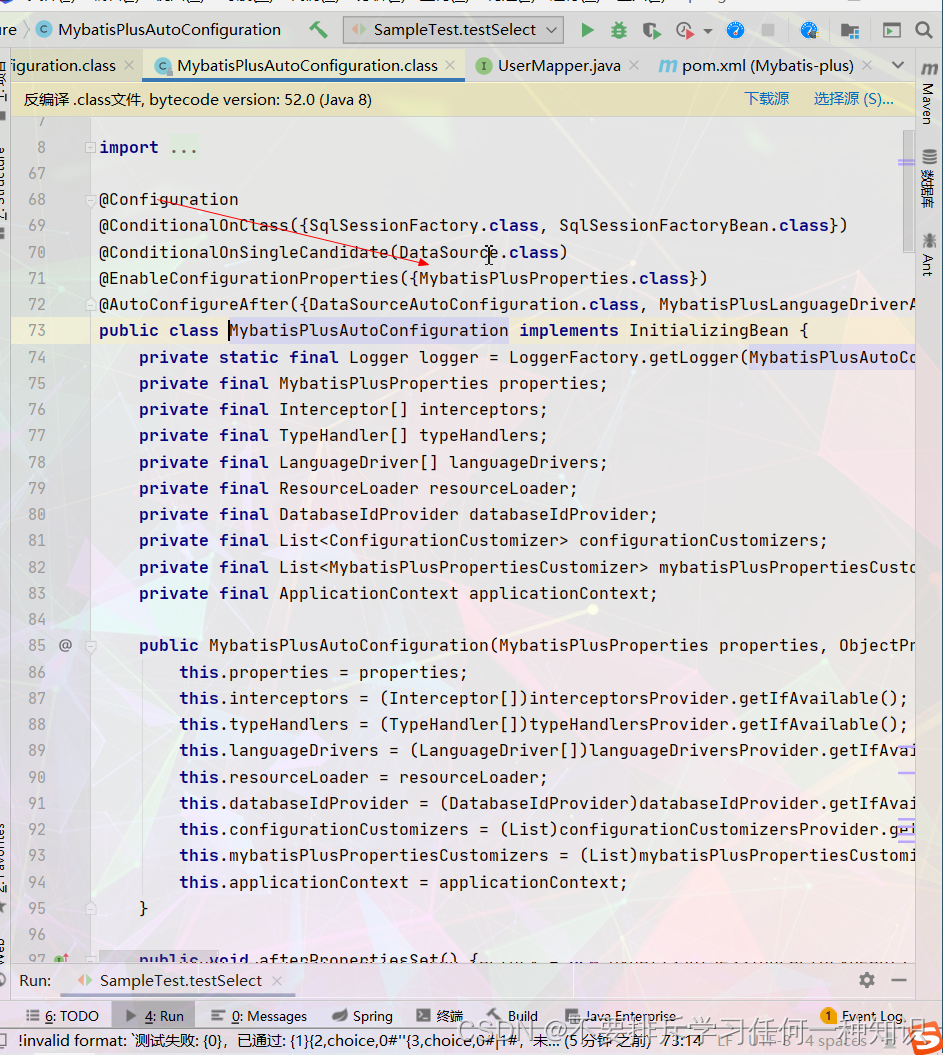
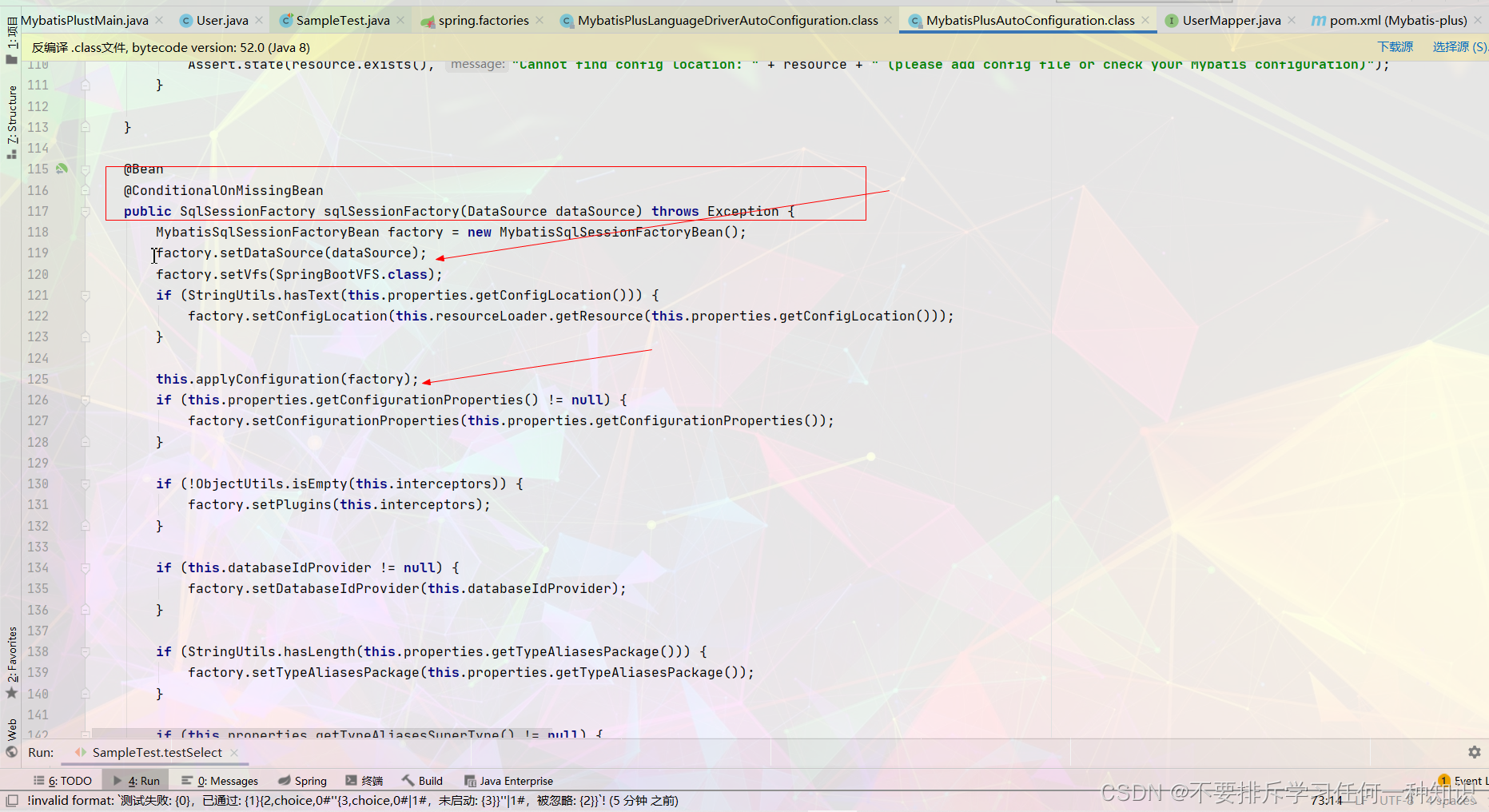
- 而且它直接给你配置好了mapperlocations的路径,默认就是classpath:/mapper/**/*.xml文件,之后就建议放在这个路径。
- 其他都给你配置好了,你顾着写你的业务逻辑即可。
二、非关系型数据库
1、操作非关系型数据库Redis
(1)导依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
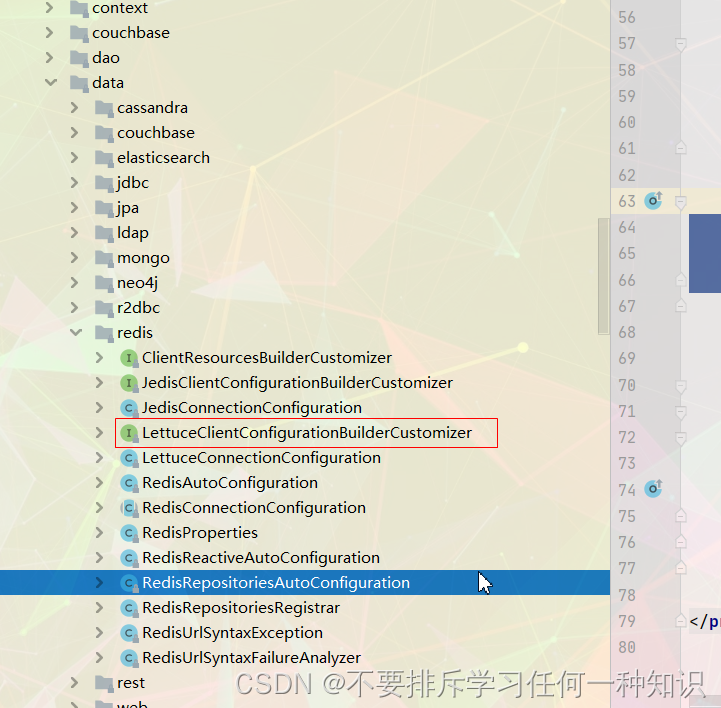
(2)看看自动配置了哪些
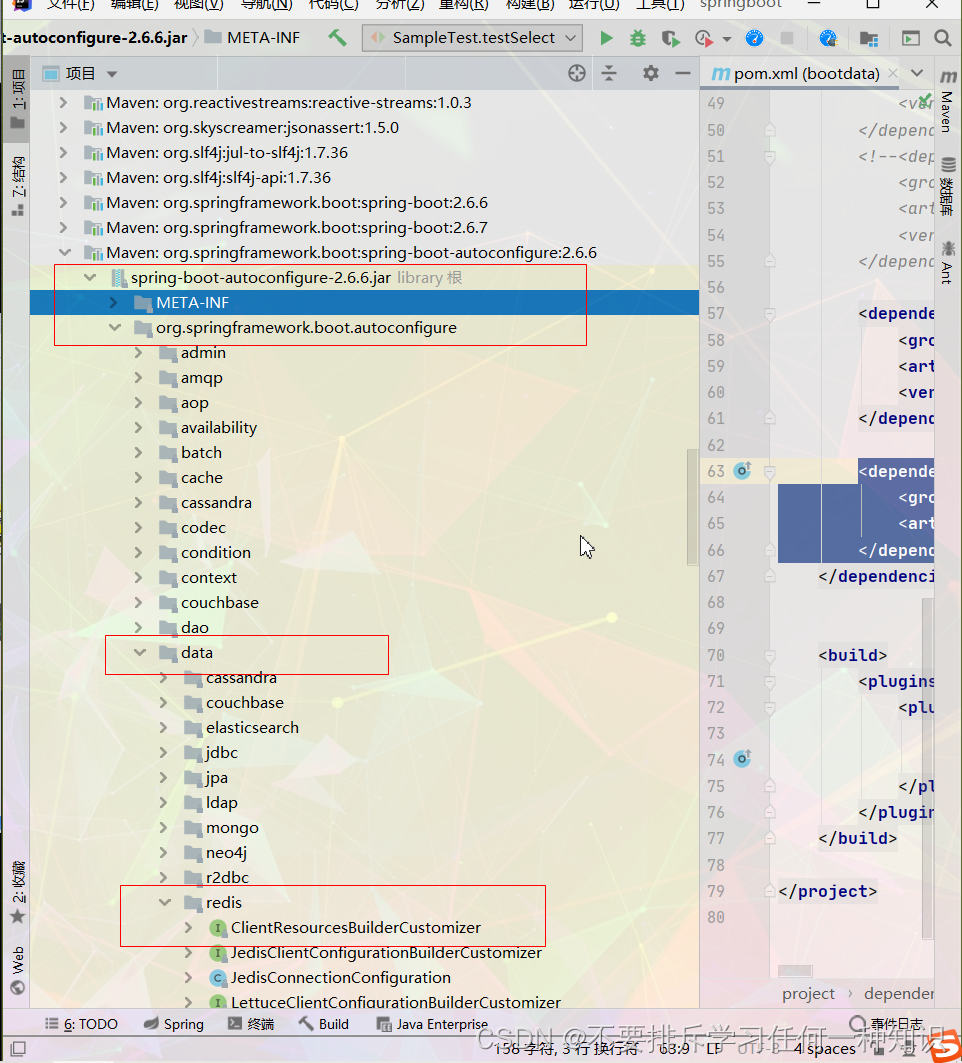
-
这个就是处理客户端的
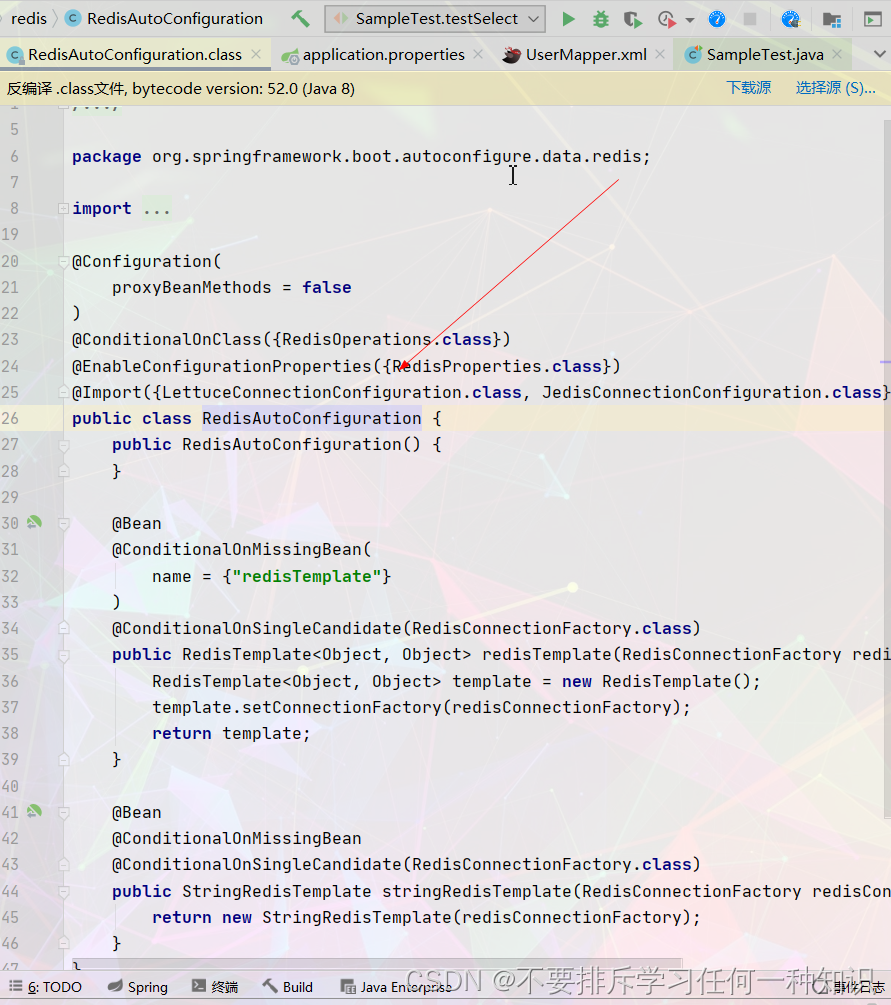
-
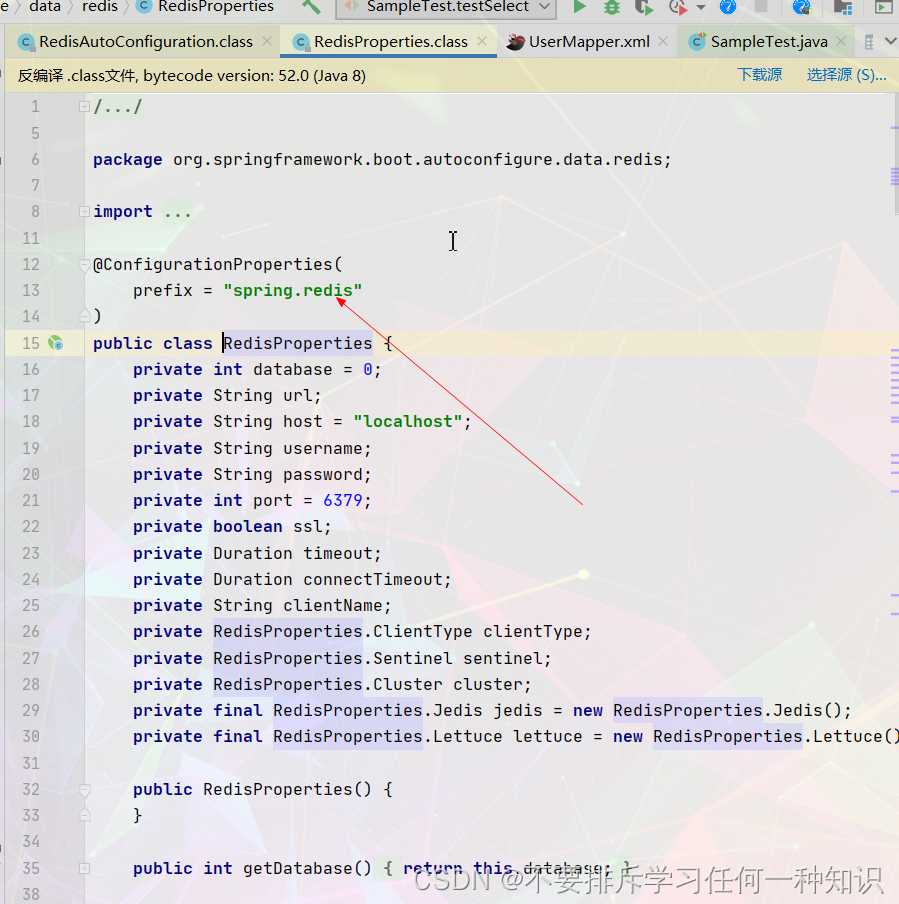
属性配置
-
导入了这么两个
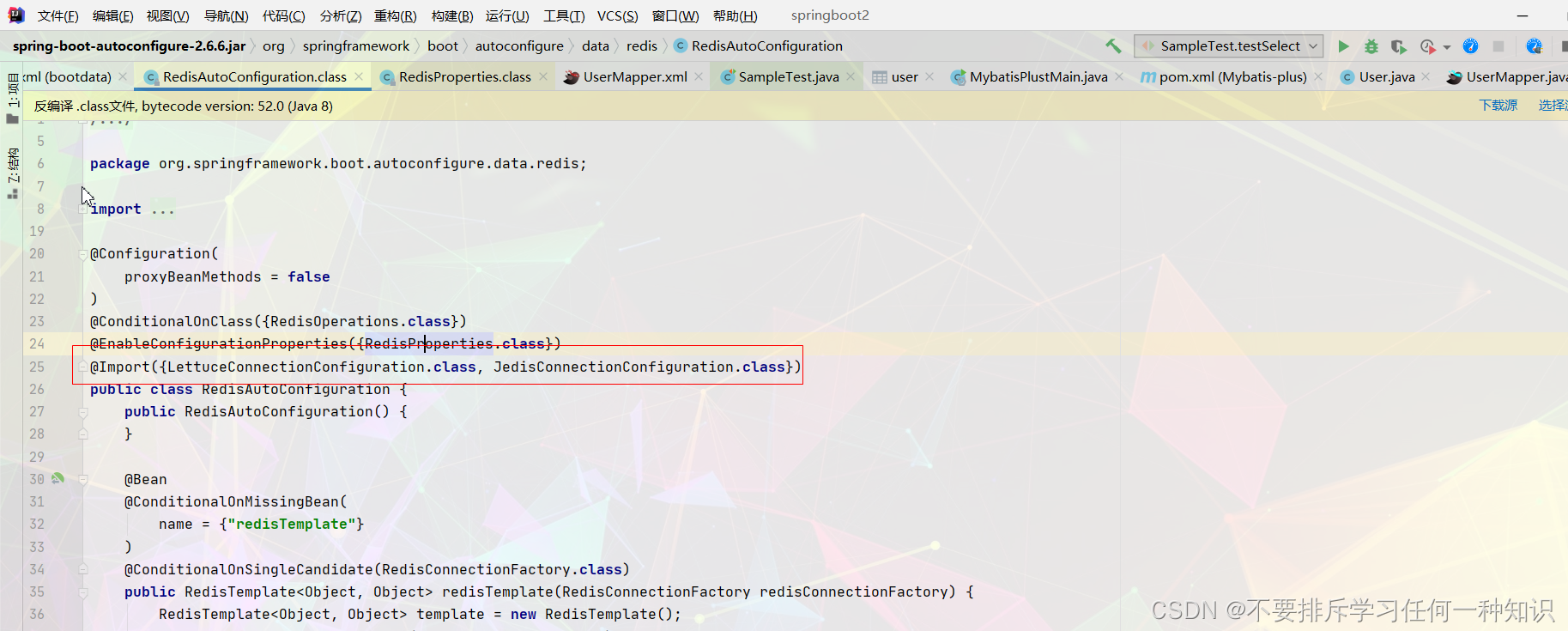
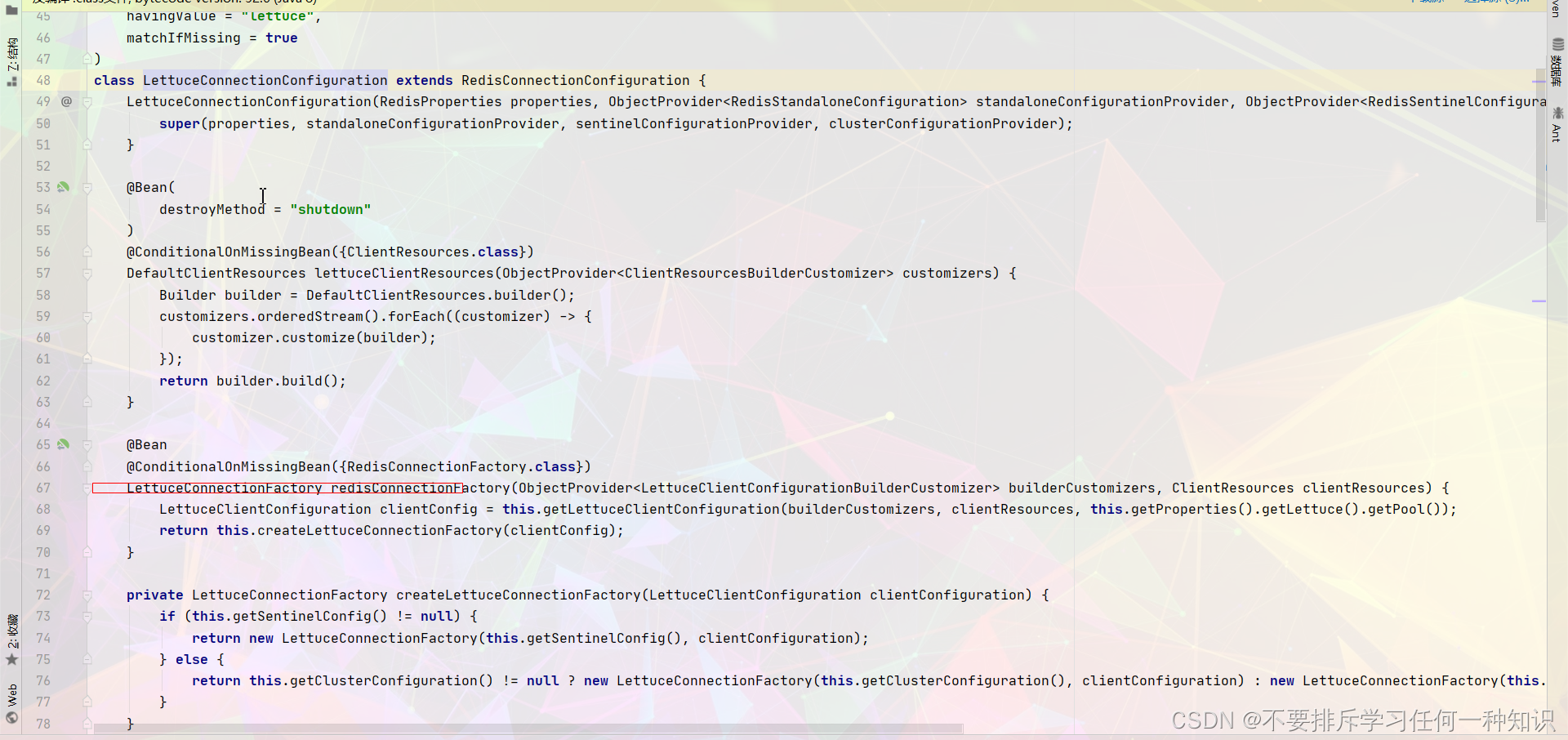
准备好了链接工厂。 -
操作redis的template
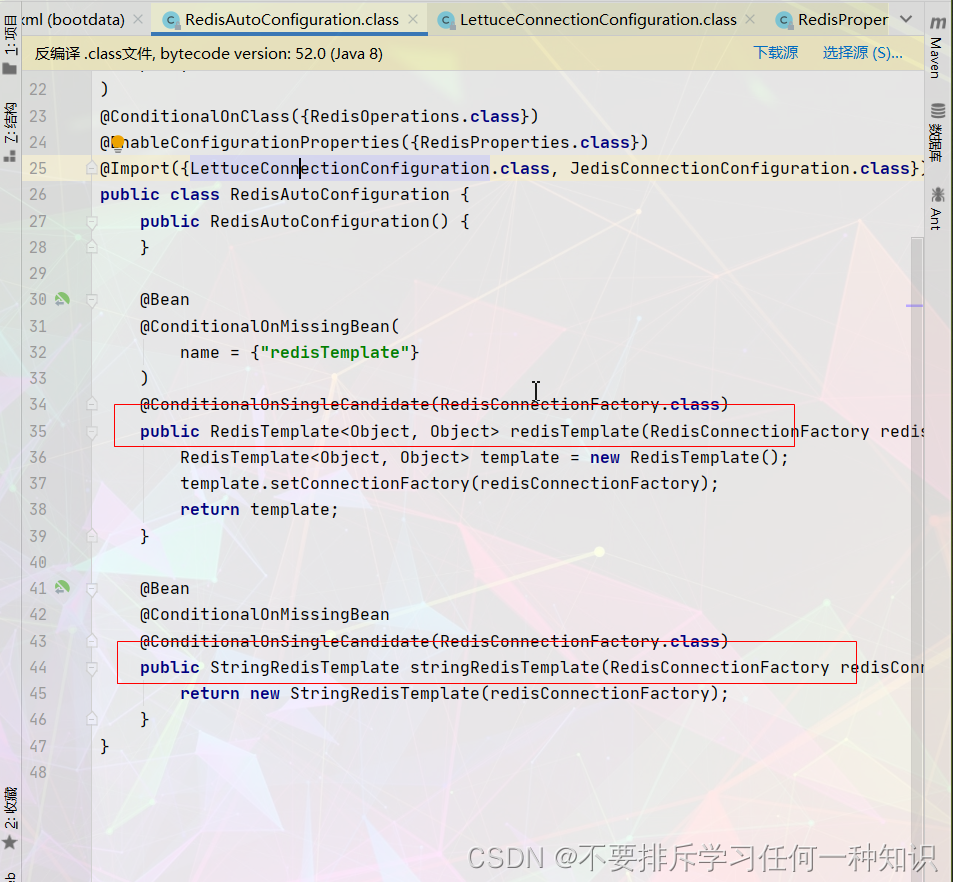
上面个是操作的Object的,下面个操作String的。我们只要操作这个两个即可。
2、整合redis
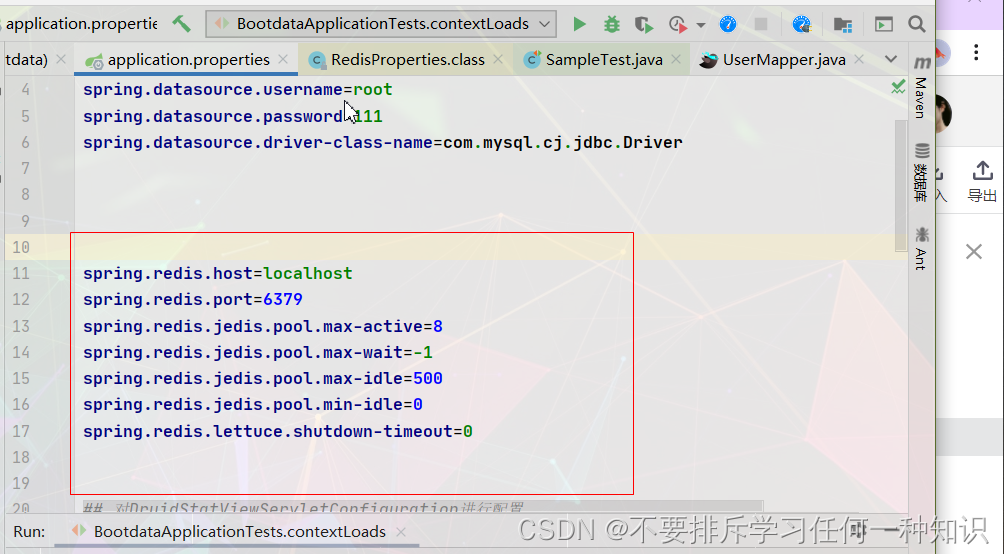
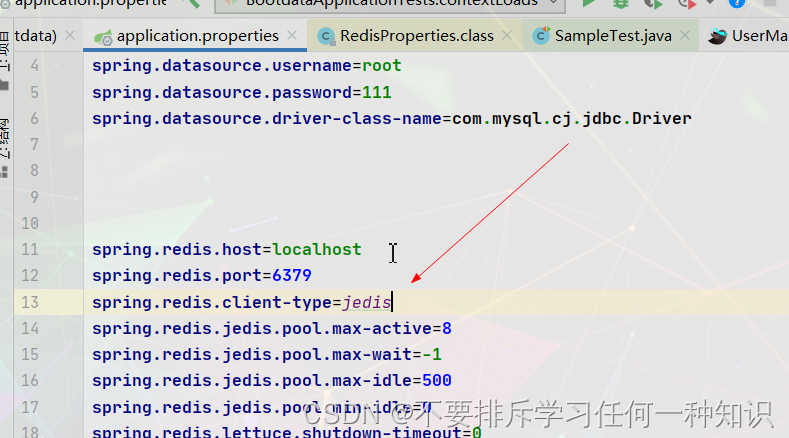
如果没有设置密码就不用设置。localhost可以填你自己的服务器地址。
- 启动测试
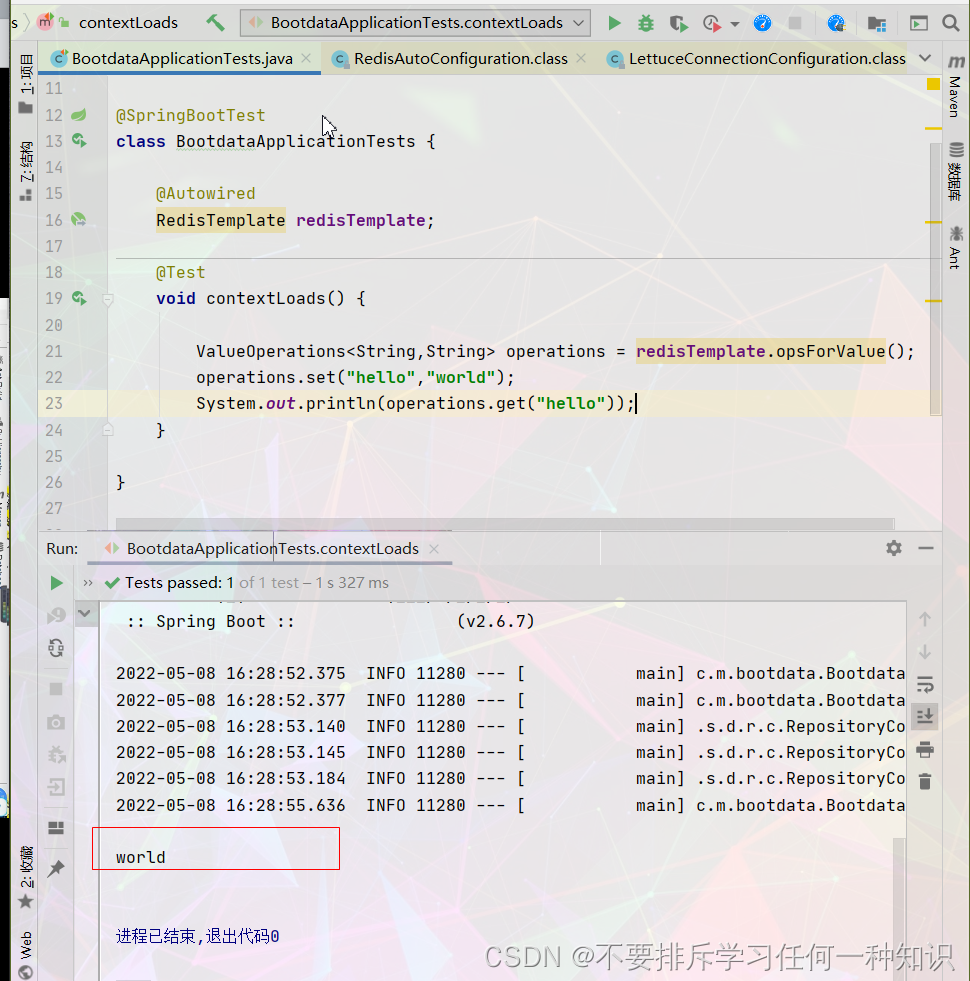
它的底层是采用的Lettuce。当然你也可以切换为Jedis操作Redis。导入Jedis的依赖
- 这里回顾我们的Filter与Interceptor
Filter是Servlet定义的原则组件,好处,脱离了spring应用也可以正常使用。
Interceptor是spring的接口,可以使用spring的自动装配功能。















 3357
3357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









