







本文主要参考 DdddOcr 发布的最新版本启动服务端, 以及JAVA 如何和服务端对接。
DdddOcr,其由作者与kerlomz共同合作完成,通过大批量生成随机数据后进行深度网络训练,本身并非针对任何一家验证码厂商而制作,本库使用效果完全靠玄学,可能可以识别,可能不能识别。
DdddOcr、最简依赖的理念,尽量减少用户的配置和使用成本,希望给每一位测试者带来舒适的体验
项目地址: 点我传送
赞助合作商
| 赞助合作商 | 推荐理由 |
|---|---|
| YesCaptcha | 谷歌reCaptcha验证码 / hCaptcha验证码 / funCaptcha验证码商业级识别接口 点我 直达VIP4 |
| Malenia | Malenia企业级代理IP网关平台/代理IP分销软件 |
上手指南
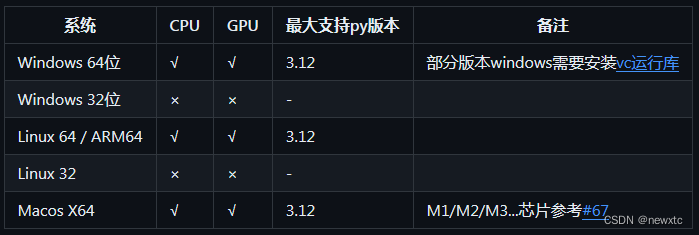
安装步骤
i. 从pypi安装
pip install ddddocr
ii. 从源码安装
git clone https://github.com/sml2h3/ddddocr.git
cd ddddocr
python setup.py
请勿直接在ddddocr项目的根目录内直接import ddddocr,请确保你的开发项目目录名称不为ddddocr,此为基础常识。
文件目录说明
eg:
ddddocr
├── MANIFEST.in
├── LICENSE
├── README.md
├── /ddddocr/
│ │── __init__.py 主代码库文件
│ │── common.onnx 新ocr模型
│ │── common_det.onnx 目标检测模型
│ │── common_old.onnx 老ocr模型
│ │── logo.png
│ │── README.md
│ │── requirements.txt
├── logo.png
└── setup.py
项目底层支持
本项目基于dddd_trainer 训练所得,训练底层框架位pytorch,ddddocr推理底层抵赖于onnxruntime,故本项目的最大兼容性与python版本支持主要取决于onnxruntime。
使用文档
i. 基础ocr识别能力
主要用于识别单行文字,即文字部分占据图片的主体部分,例如常见的英数验证码等,本项目可以对中文、英文(随机大小写or通过设置结果范围圈定大小写)、数字以及部分特殊字符。
# example.py
import ddddocr
ocr = ddddocr.DdddOcr()
image = open("example.jpg", "rb").read()
result = ocr.classification(image)
print(result)
本库内置有两套ocr模型,默认情况下不会自动切换,需要在初始化ddddocr的时候通过参数进行切换
# example.py
import ddddocr
ocr = ddddocr.DdddOcr(beta=True) # 切换为第二套ocr模型
image = open("example.jpg", "rb").read()
result = ocr.classification(image)
print(result)
提示 对于部分透明黑色png格式图片得识别支持: classification 方法 使用 png_fix 参数,默认为False
ocr.classification(image, png_fix=True)
注意
之前发现很多人喜欢在每次ocr识别的时候都重新初始化ddddocr,即每次都执行ocr = ddddocr.DdddOcr(),这是错误的,通常来说只需要初始化一次即可,因为每次初始化和初始化后的第一次识别速度都非常慢
参考例图
包括且不限于以下图片

ii. 目标检测能力
主要用于快速检测出图像中可能的目标主体位置,由于被检测出的目标不一定为文字,所以本功能仅提供目标的bbox位置 (在⽬标检测⾥,我们通常使⽤bbox(bounding box,缩写是 bbox)来描述⽬标位置。bbox是⼀个矩形框,可以由矩形左上⻆的 x 和 y 轴坐标与右下⻆的 x 和 y 轴坐标确定)
如果使用过程中无需调用ocr功能,可以在初始化时通过传参ocr=False关闭ocr功能,开启目标检测需要传入参数
det=True
import ddddocr
import cv2
det = ddddocr.DdddOcr(det=True)
with open("test.jpg", 'rb') as f:
image = f.read()
bboxes = det.detection(image)
print(bboxes)
im = cv2.imread("test.jpg")
for bbox in bboxes:
x1, y1, x2, y2 = bbox
im = cv2.rectangle(im, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=2)
cv2.imwrite("result.jpg", im)
参考例图
包括且不限于以下图片
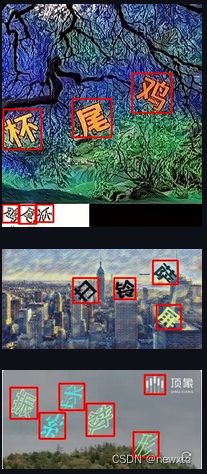
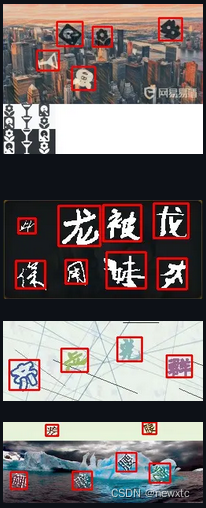
Ⅲ. 滑块检测
本项目的滑块检测功能并非AI识别实现,均为opencv内置算法实现。可能对于截图党用户没那么友好~,如果使用过程中无需调用ocr功能或目标检测功能,可以在初始化时通过传参ocr=False关闭ocr功能或det=False来关闭目标检测功能
本功能内置两套算法实现,适用于两种不同情况,具体请参考以下说明
a.算法1
算法1原理是通过滑块图像的边缘在背景图中计算找到相对应的坑位,可以分别获取到滑块图和背景图,滑块图为透明背景图
滑块图

det = ddddocr.DdddOcr(det=False, ocr=False)
with open('target.png', 'rb') as f:
target_bytes = f.read()
with open('background.png', 'rb') as f:
background_bytes = f.read()
res = det.slide_match(target_bytes, background_bytes)
print(res)
由于滑块图可能存在透明边框的问题,导致计算结果不一定准确,需要自行估算滑块图透明边框的宽度用于修正得出的bbox
提示:如果滑块无过多背景部分,则可以添加simple_target参数, 通常为jpg或者bmp格式的图片
slide = ddddocr.DdddOcr(det=False, ocr=False)
with open('target.jpg', 'rb') as f:
target_bytes = f.read()
with open('background.jpg', 'rb') as f:
background_bytes = f.read()
res = slide.slide_match(target_bytes, background_bytes, simple_target=True)
print(res)
a.算法2
算法2是通过比较两张图的不同之处进行判断滑块目标坑位的位置
参考图a,带有目标坑位阴影的全图


slide = ddddocr.DdddOcr(det=False, ocr=False)
with open('bg.jpg', 'rb') as f:
target_bytes = f.read()
with open('fullpage.jpg', 'rb') as f:
background_bytes = f.read()
img = cv2.imread("bg.jpg")
res = slide.slide_comparison(target_bytes, background_bytes)
print(res)
Ⅳ. OCR概率输出
为了提供更灵活的ocr结果控制与范围限定,项目支持对ocr结果进行范围限定。
可以通过在调用classification方法的时候传参probability=True,此时classification方法将返回全字符表的概率 当然也可以通过set_ranges方法设置输出字符范围来限定返回的结果。
Ⅰ. set_ranges 方法限定返回字符返回
本方法接受1个参数,如果输入为int类型为内置的字符集限制,string类型则为自定义的字符集
如果为int类型,请参考下表
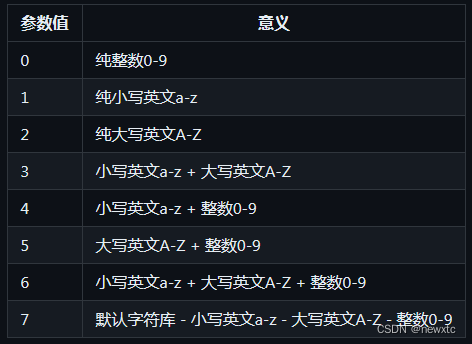
如果为string类型请传入一段不包含空格的文本,其中的每个字符均为一个待选词 如:“0123456789±x/=”"
import ddddocr
ocr = ddddocr.DdddOcr()
image = open("test.jpg", "rb").read()
ocr.set_ranges("0123456789+-x/=")
result = ocr.classification(image, probability=True)
s = ""
for i in result['probability']:
s += result['charsets'][i.index(max(i))]
print(s)
本项目支持导入来自于 dddd_trainer 进行自定义训练后的模型,参考导入代码为
import ddddocr
ocr = ddddocr.DdddOcr(det=False, ocr=False, import_onnx_path="myproject_0.984375_139_13000_2022-02-26-15-34-13.onnx", charsets_path="charsets.json")
with open('test.jpg', 'rb') as f:
image_bytes = f.read()
res = ocr.classification(image_bytes)
print(res)
服务端启动
安装上述文档安装后, 需要启动作为后台服务,这样可以更好的和JAVA 等异种语言的程序对接
start python /app.python/ocr_server.py --ocr --old
# encoding=utf-8
import argparse
import base64
import json
import ddddocr
from flask import Flask, request
parser = argparse.ArgumentParser(description="使用ddddocr搭建的最简api服务")
parser.add_argument("-p", "--port", type=int, default=9898)
parser.add_argument("--ocr", action="store_true", help="开启ocr识别")
parser.add_argument("--old", action="store_true", help="OCR是否启动旧模型")
parser.add_argument("--det", action="store_true", help="开启目标检测")
args = parser.parse_args()
app = Flask(__name__)
class Server(object):
def __init__(self, ocr=True, det=False, old=False):
self.ocr_option = ocr
self.det_option = det
self.old_option = old
self.ocr = None
self.det = None
if self.ocr_option:
print("ocr模块开启")
if self.old_option:
print("使用OCR旧模型启动")
self.ocr = ddddocr.DdddOcr(old=True)
else:
print("使用OCR新模型启动,如需要使用旧模型,请额外添加参数 --old开启")
self.ocr = ddddocr.DdddOcr()
elif self.det_option:
print("det模块开启")
self.det = ddddocr.DdddOcr(det=True)
else:
print("ocr or det 模块未开启!")
def classification(self, img: bytes):
if self.ocr_option:
return self.ocr.classification(img)
else:
raise Exception("ocr模块未开启")
def detection(self, img: bytes):
if self.det_option:
return self.det.detection(img)
else:
raise Exception("目标检测模块模块未开启")
def slide(self, target_img: bytes, bg_img: bytes, algo_type: str):
dddd = self.ocr or self.det or ddddocr.DdddOcr(ocr=False)
if algo_type == 'match':
return dddd.slide_match(target_img, bg_img)
elif algo_type == 'compare':
return dddd.slide_comparison(target_img, bg_img)
else:
raise Exception(f"不支持的滑块算法类型: {algo_type}")
server = Server(ocr=args.ocr, det=args.det, old=args.old)
def get_img(request, img_type='file', img_name='image'):
if img_type == 'b64':
img = base64.b64decode(request.get_data()) #
try: # json str of multiple images
dic = json.loads(img)
img = base64.b64decode(dic.get(img_name).encode())
except Exception as e: # just base64 of single image
pass
else:
img = request.files.get(img_name).read()
return img
def set_ret(result, ret_type='text'):
if ret_type == 'json':
if isinstance(result, Exception):
return json.dumps({"status": 200, "result": "", "msg": str(result)})
else:
return json.dumps({"status": 200, "result": result, "msg": ""})
# return json.dumps({"succ": isinstance(result, str), "result": str(result)})
else:
if isinstance(result, Exception):
return ''
else:
return str(result).strip()
@app.route('/<opt>/<img_type>', methods=['POST'])
@app.route('/<opt>/<img_type>/<ret_type>', methods=['POST'])
def ocr(opt, img_type='file', ret_type='text'):
try:
print('opt='+opt+',img_type='+img_type)
img = get_img(request, img_type)
if opt == 'ocr':
result = server.classification(img)
print('ocr result='+result)
elif opt == 'det':
result = server.detection(img)
print('det result='+result)
else:
raise f"<opt={opt}> is invalid"
return set_ret(result, ret_type)
except Exception as e:
return set_ret(e, ret_type)
@app.route('/slide/<algo_type>/<img_type>', methods=['POST'])
@app.route('/slide/<algo_type>/<img_type>/<ret_type>', methods=['POST'])
def slide(algo_type='compare', img_type='file', ret_type='text'):
try:
target_img = get_img(request, img_type, 'target_img')
bg_img = get_img(request, img_type, 'bg_img')
result = server.slide(target_img, bg_img, algo_type)
return set_ret(result, ret_type)
except Exception as e:
return set_ret(e, ret_type)
@app.route('/ping', methods=['GET'])
def ping():
return "pong"
if __name__ == '__main__':
app.run(host="0.0.0.0", port=args.port)
JAVA 客户端
public String getImgCode(byte[] bigImage) {
try {
if (ddddUrl == null) {
System.out.println("ddddUrl=" + ddddUrl);
return null;
}
long time = (new Date()).getTime();
HttpURLConnection con = null;
String boundary = "----------" + String.valueOf(time);
String boundarybytesString = "\r\n--" + boundary + "\r\n";
OutputStream out = null;
URL u = new URL(ddddUrl);
con = (HttpURLConnection) u.openConnection();
con.setRequestMethod("POST");
con.setConnectTimeout(10000);
con.setReadTimeout(10000);
con.setDoOutput(true);
con.setDoInput(true);
con.setUseCaches(true);
con.setRequestProperty("Content-Type", "multipart/form-data; boundary=" + boundary);
out = con.getOutputStream();
if (bigImage != null && bigImage.length > 0) {
out.write(boundarybytesString.getBytes("UTF-8"));
String paramString = "Content-Disposition: form-data; name=\"image\"; filename=\"" + "bigNxt.gif" + "\"\r\n";
paramString += "Content-Type: application/octet-stream\r\n\r\n";
out.write(paramString.getBytes("UTF-8"));
out.write(bigImage);
}
String tailer = "\r\n--" + boundary + "--\r\n";
out.write(tailer.getBytes("UTF-8"));
out.flush();
out.close();
StringBuffer buffer = new StringBuffer();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(), "UTF-8"));
String temp;
while ((temp = br.readLine()) != null) {
buffer.append(temp);
}
String ret = buffer.toString();
if (ret.length() < 1) {
System.out.println("ddddUrl=" + ddddUrl + " ret=" + buffer.toString());
}
return buffer.toString();
} catch (Throwable e) {
logger.error("ddddUrl=" + ddddUrl + ",e=" + e.toString());
return null;
}
}

















 272
272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









