






Neural Network 神经网络
MLP多层感知机和它的基础
MLP(Multi-Layer Perceptron),即多层感知器,是一种前向结构的人工神经网络,映射一组输入向量到一组输出向量。MLP可以被看做是一个有向图,由多个节点层组成,每一层全连接到下一层。除了输入节点,每个节点都是一个带有非线性激活函数的神经元(或称处理单元)。一种被称为反向传播算法的监督学习方法常被用来训练MLP。MLP是感知器的推广,克服了感知器无法实现对线性不可分数据识别的缺点。
MLP可以被看做是广义的线性模式,只是执行了多层后才得到结论。
线性模型的回归公式:
y = w[0] * x[0] + w[1] * x[1] + …+…+b
上面的公式可以看出,y是输入特征x[0]到x[p]的加权求和,权重为模型学习到的系数w。
我们可以对比下简单的线性模型和多层的神经网络:
display(mglearn.plots.plot_logistic_regression_graph())
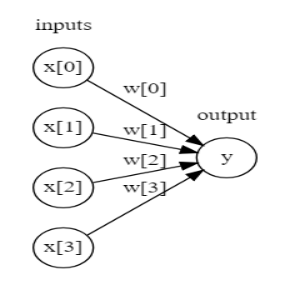
左边的节点代表输入的特征,中间的连线代表学习到的系数,右边的y代表输出的结果,即加权求和的结果。
我们再看看单隐层的多层感知机:

每个输入的特征与隐单元之间有一个系数,每一个隐单元与输出的结果之间也有一个系数,这些系数可以称之为权重,这些隐单元也组成了一个隐层,上图是一个单隐层的神经网络模型。
这里会有一个问题,因为计算一系列多层的加权求和和只计算一次加权求和是完全一样的。那么这个神经网络模型和普通的线性模型到底有什么不同呢?
对每个隐单元的结果再套上一个非线性函数:这个非线性函数通常是校正非线性 relu和正切双曲线 tanh。然后再对经过非线性函数计算过的隐单元结果进行加权求和,就得到了最终的结果y。
所以以一个小型神经网络为例子:计算回归问题的y的实际公式其实是
h[0] = w0x[0] + w1x[1] +…+ wpx[p] + b[0]
h[1] = w0x[0] + w1x[1] +…+ wpx[p] + b[1]
h[2] = w0x[0] + w1x[1] +…+ wpx[p] + b[2]
y = v0h[0] + v1h[1] + v2h[2] + b
对于神经网络而言,有一个重要的参数是隐层中隐单元的个数。对于非常简单的数据集而言,隐单元的个数可以是10个,对于非常复杂的数据集,隐单元的个数可以大到10000。并且还可以添加多个隐层。所以这样多个计算层构成的大型神经网络,可以说是和深度学习这个词非常的搭配了。
由前面介绍看到,单个感知器能够完成线性可分数据的分类问题,是一种最简单的可以“学习”的机器。但他无法解决非线性问题。比如下图中的XOR问题:即(1,1)(-1,-1)属于同一类,而(1,-1)(-1,1)属于第二类的问题,不能由单个感知器正确分类。
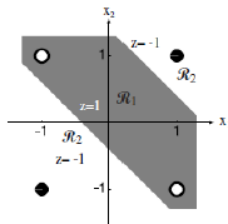
即在Minsky和Papert的专著《感知器》所分析的:感知器只能解决所谓一阶谓词逻辑问题:与(AND),或(OR)等,而不能解决异或(XOR)等高阶谓词罗辑问题。
用多个感知器实现非线性
单个感知器虽然无法解决异或问题,但却可以通过将多个感知器组合,实现复杂空间的分割。如下图:

将两层感知器按照一定的结构和系数进行组合,第一层感知器实现两个线性分类器,把特征空间分割,而在这两个感知器的输出之上再加一层感知器,就可以实现异或运算。
也就是,由多个感知器组合:
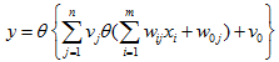
来实现非线性分类面,其中θ(·)表示阶跃函数或符号函数。














 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









