







这个csv文件的数据(AIS数据,类似于GPS定位数据,字节较多)大概1200多万行,在用jupyter notebook pd.read_csv读取时,总是出现问题提示:ParserError: Error tokenizing data. C error: EOF inside string starting at row 11020412
加了
encoding='utf-8'、 header=None、 delimiter="\t"、error_bad_lines=False、 sep='\t'等等等,可是都没用,读出来的都是乱码,直接变成NaN了
改成
df=pd.read_csv(r'F:\AIS数据\oData201803\a20180402.csv',
names['MessageID','MMSI','NaviStatus','ROT_SENSOR','SOG','PosAcc','Lon','Lat','COG',
'TrueHeading','UTCSec','IMO','CallSign','ShipName','ShipCargoType','A','B','C','D',
'FixingDevice','ETA','dm','Destination','AidsToNavType','Off_Position','SarAltitude',
'm_bIsOwnShip','MessageBlendID','LTM','Z1','Z2','Z3'],
header=None , skiprows=1 , error_bad_lines=False , engine='python')
注释:
1:names[表头内容]
2:数据读取出来第一行时表头skiprows=1 是为了跳过第一行的表头
关键在engine='python’
这下可以了,但是会显示如下情况
Skipping line 586281: field larger than field limit (131072)
Skipping line 612412: ',' expected after '"'
Skipping line 639534: field larger than field limit (131072)
Skipping line 693336: field larger than field limit (131072)
Skipping line 774302: ',' expected after '"'
Skipping line 801625: field larger than field limit (131072)
Skipping line 855010: field larger than field limit (131072)
Skipping line 991076: ',' expected after '"'
Skipping line 1018778: field larger than field limit (131072)
.....
针对这个问题又搜了解决办法,在代码前面添加下面的代码
import sys
import csv
maxInt = sys.maxsize
decrement = True
while decrement:
decrement = False
try:
csv.field_size_limit(maxInt)
except OverflowError:
maxInt = int(maxInt/10)
decrement = True
又出现了下面的提示
Skipping line 256361: ',' expected after '"'
Skipping line 508779: ',' expected after '"'
Skipping line 523070: ',' expected after '"'
Skipping line 550192: ',' expected after '"'
Skipping line 563598: ',' expected after '"'
Skipping line 625841: ',' expected after '"'
Skipping line 653164: ',' expected after '"'
Skipping line 687986: ',' expected after '"'
....
跳过了很多
不知道有没有更好的读取这种大数据的方法,还请大神们告知
2021.3.25更新
加上import csv,读写文件时添加一个quoting=csv.QUOTE_NONE,即
df=pd.read_csv(r'F:\AIS数据\oData201803\a20180402.csv',
names['MessageID','MMSI','NaviStatus',...],
low_memory=False, header=None,skiprows=1,quoting=csv.QUOTE_NONE)
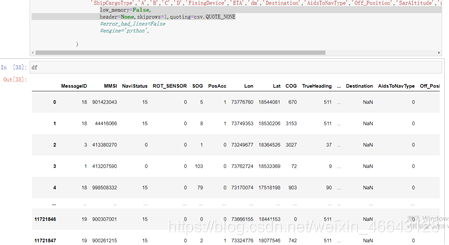
问题解决!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









