









Mysql索引底层数据结构
问题:
1.数据到底放在哪?
2.有哪些数据结构
3.每个数据结构的优缺点
4.索引和数据结构怎么联系起来
5.索引的最左原则
说透数据
- 数据在哪?
- 说到底数据都是存放再磁盘里的,所以我们的数据并在磁盘中的位置并不一定是连续的,因为在硬件的角度磁道每次的位置是不一样的。
- 为什么说sql要优化,在写代码的时候,要减少库的查询
- 每次从磁盘将数据读到内存中,其实都是进行一次磁盘IO,开销是十分大的。如果我读到内存里处理就避免了IO的开销。
数据结构对比
| 二叉树 | 红黑树 | B树 | B+树 | hash | |
|---|---|---|---|---|---|
| 优点 | 树结构查询快 | 平衡树,在二叉树的基础上进行优化 | 每个节点会划分一块磁盘空间进行分配,所以每个节点会存放多个数据节点,树的高度可以降低 | 1.优化了B树的缺点,除去每个叶子节点的数据数据节点存放着数据,其他所有的节点都只存放一个索引值,2.在叶子节点上增加了双向指针,便于范围查询(同时因为树的每一个节点都是排好序的) | 理想状态下其实查询最快,一次哈希直接命中的情况 |
| 缺点 | 但是当顺序插入递增,树成链表的情况 | 在数据量大的时,树的高度会非常的高 | 每个数据节点的结构(key-索引值,value-一行数据),导致每个节点的所占的空间会比较大,那么树的高度又上来了 | 优秀 | 哈希碰撞;不支持范围查询还是要全表扫描 |
| 在mysql选用与否 | 否 | 否 | 否 | 是 | 是(但是基本不用) |
| 能存放多少的数据 | 否 | 否 | 否 | 非叶子节点子节点每一页16kb的数据,正常能存放1170条索引,最后的叶子节点是16条,正常计算3层高的B+树就是1170117016 = 2000多万的索引 | / |
| mysql中使用的特点 | 否 | 否 | 否 | 1.优化叶子节点的双指针,便于范围查询,2.每一页数据都是按照索引排好序的,3.根据B+树的特点建议我们需要使用整形自增主键(原因见备注1) | / |
备注
- 整型自增原因
- 整型原因
- 使占用的一页数据中的空间尽量小
- 整型类型在数据比较的时候快
- 需要自增原因
- 首先你不建自增的情况下,mysql会自己选一列不重复的进行索引创建,或者创建一个隐藏列来创建索引
- 避免节点进行分裂平衡,如果是自增的B+树会向后开篇空间,放新的索引数据节点
- 整型原因
- B树和B+树的数据结构
-
B树
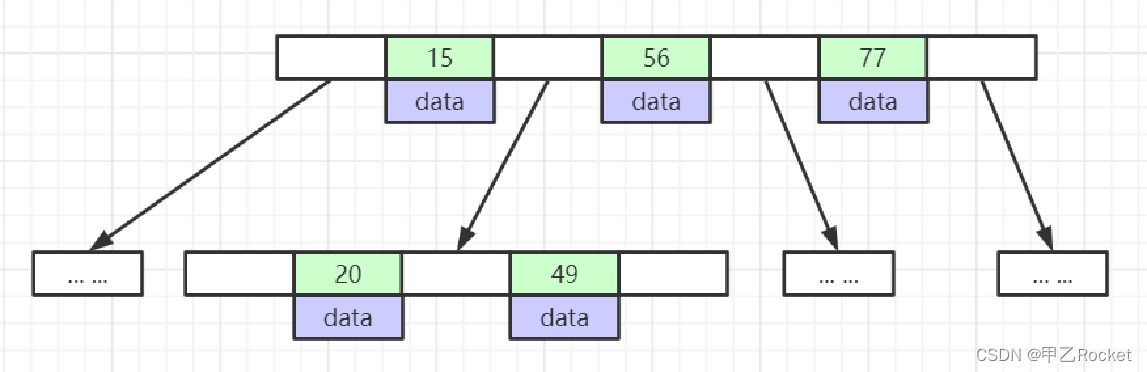
-
B+树

-
二级索引
也就是我们平时自己建的索引
主键索引和二级索引结构
| 二级索引 | 主键索引 | |
|---|---|---|
| 数据结构 | B+树 | B+树 |
| 区别 | 子节点放的value位置放的是主键索引值 | 子节点放的value位置放的是磁盘地址 |
| 使用 | 1.拿到对应索引的的主键索引值2.通过主键索引值去主键索引B+树再查到磁盘地址(或者整行数据) | 直接磁盘地址定位整行数据(innodb) |
存储引擎
| myisam | innodb | |
|---|---|---|
| 数据结构 | B+树 | B+树 |
| 存放 | 每个叶子节点的,value位置放的是磁盘地址 | 每个叶子节点的,value位置放的是整行数据(其实这种也叫聚簇索引) |
| 主要区别 | 拿到磁盘地址然后回表查询出数据 | 不用回查了,拿出来就是数据 |
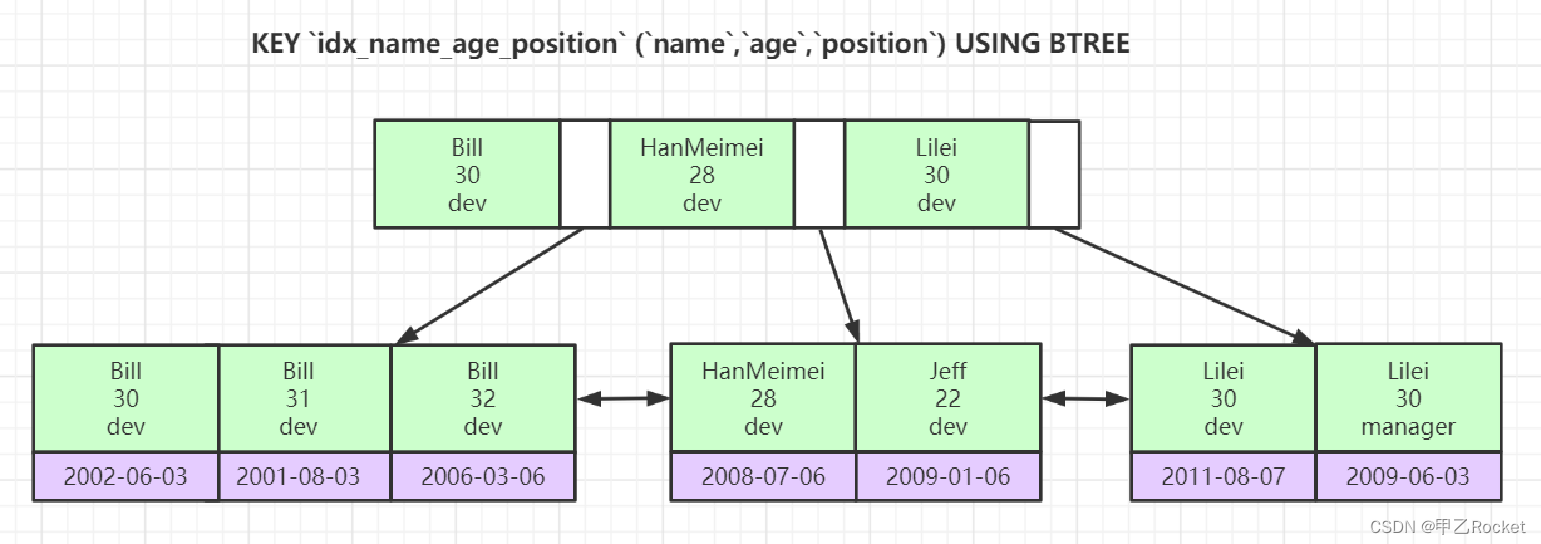
联合索引
最左原则
就是按照创建索引的顺序构建B+树,如下先排name,再排age。。。
按照构建B+树的特点解释最左原则
如果不是从name开始,没法在树中查询,因为每一个节点都是先从name开始排好序的,如果name都进行搜索的话,一定索引失效。


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









