







开源大语言模型完整列表
Large Language Model (LLM) 即大规模语言模型,是一种基于深度学习的自然语言处理模型,它能够学习到自然语言的语法和语义,从而可以生成人类可读的文本。
所谓"语言模型",就是只用来处理语言文字(或者符号体系)的 AI 模型,发现其中的规律,可以根据提示 (prompt),自动生成符合这些规律的内容。
LLM 通常基于神经网络模型,使用大规模的语料库进行训练,比如使用互联网上的海量文本数据。这些模型通常拥有数十亿到数万亿个参数,能够处理各种自然语言处理任务,如自然语言生成、文本分类、文本摘要、机器翻译、语音识别等。
本文对国内外公司、科研机构等组织开源的 LLM 进行了全面的整理。

开源中文 LLM
ChatGLM-6B —— 双语对话语言模型
ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,并针对中文进行了优化。该模型基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。
ChatGLM-6B 使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 虽然规模不及千亿模型,但大大降低了推理成本,提升了效率,并且已经能生成相当符合人类偏好的回答。
ChatGLM2-6B —— 中英双语对话模型 ChatGLM-6B 的第二代版本
基于 ChatGLM 初代模型的开发经验,ChatGLM2-6B 全面升级了基座模型,更长的上下文,更高效的推理、更开放的协议。
VisualGLM-6B —— 多模态对话语言模型
VisualGLM-6B 是一个开源的,支持图像、中文和英文的多模态对话语言模型,语言模型基于 ChatGLM-6B,具有 62 亿参数;图像部分通过训练 BLIP2-Qformer 构建起视觉模型与语言模型的桥梁,整体模型共78亿参数。
MOSS —— 支持中英双语的对话大语言模型
MOSS 是一个支持中英双语和多种插件的开源对话语言模型, moss-moon 系列模型具有 160 亿参数,在 FP16 精度下可在单张 A100/A800 或两张 3090 显卡运行,在 INT4/8 精度下可在单张 3090 显卡运行。
MOSS 基座语言模型在约七千亿中英文以及代码单词上预训练得到,后续经过对话指令微调、插件增强学习和人类偏好训练具备多轮对话能力及使用多种插件的能力。
DB-GPT —— 数据库大语言模型
DB-GPT 是一个开源的以数据库为基础的 GPT 实验项目,使用本地化的 GPT 大模型与数据和环境进行交互,无数据泄露风险,100% 私密,100% 安全。
DB-GPT 为所有以数据库为基础的场景,构建了一套完整的私有大模型解决方案。 此方案因为支持本地部署,所以不仅仅可以应用于独立私有环境,而且还可以根据业务模块独立部署隔离,让大模型的能力绝对私有、安全、可控。
CPM-Bee —— 中英文双语大语言模型
CPM-Bee 是一个 完全开源、允许商用的百亿参数中英文基座模型。它采用 Transformer 自回归架构(auto-regressive),使用万亿级高质量语料进行预训练,拥有强大的基础能力。
CPM-Bee 的特点可以总结如下:
-
开源可商用:OpenBMB 始终秉承 “让大模型飞入千家万户” 的开源精神,CPM-Bee 基座模型将完全开源并且可商用,以推动大模型领域的发展。如需将模型用于商业用途,只需企业实名邮件申请并获得官方授权证书,即可商用使用。
-
中英双语性能优异:CPM-Bee 基座模型在预训练语料上进行了严格的筛选和配比,同时在中英双语上具有亮眼表现,具体可参见评测任务和结果。
-
超大规模高质量语料:CPM-Bee 基座模型在万亿级语料上进行训练,是开源社区内经过语料最多的模型之一。同时,我们对预训练语料进行了严格的筛选、清洗和后处理以确保质量。
-
OpenBMB 大模型系统生态支持:OpenBMB 大模型系统在高性能预训练、适配、压缩、部署、工具开发了一系列工具,CPM-Bee 基座模型将配套所有的工具脚本,高效支持开发者进行进阶使用。
-
强大的对话和工具使用能力:结合 OpenBMB 在指令微调和工具学习的探索,我们在 CPM-Bee 基座模型的基础上进行微调,训练出了具有强大对话和工具使用能力的实例模型,现已开放定向邀请内测,未来会逐步向公众开放。
CPM-Bee 的基座模型可以准确地进行语义理解,高效完成各类基础任务,包括:文字填空、文本生成、翻译、问答、评分预测、文本选择题等等。
LaWGPT —— 基于中文法律知识的大语言模型
LaWGPT 是一系列基于中文法律知识的开源大语言模型。
该系列模型在通用中文基座模型(如 Chinese-LLaMA、ChatGLM 等)的基础上扩充法律领域专有词表、大规模中文法律语料预训练,增强了大模型在法律领域的基础语义理解能力。在此基础上,构造法律领域对话问答数据集、中国司法考试数据集进行指令精调,提升了模型对法律内容的理解和执行能力。
伶荔 (Linly) —— 大规模中文语言模型
相比已有的中文开源模型,伶荔模型具有以下优势:
-
在 32*A100 GPU 上训练了不同量级和功能的中文模型,对模型充分训练并提供强大的 baseline。据知,33B 的 Linly-Chinese-LLAMA 是目前最大的中文 LLaMA 模型。
-
公开所有训练数据、代码、参数细节以及实验结果,确保项目的可复现性,用户可以选择合适的资源直接用于自己的流程中。
-
项目具有高兼容性和易用性,提供可用于 CUDA 和 CPU 的量化推理框架,并支持 Huggingface 格式。
目前公开可用的模型有:
-
Linly-Chinese-LLaMA:中文基础模型,基于 LLaMA 在高质量中文语料上增量训练强化中文语言能力,现已开放 7B、13B 和 33B 量级,65B 正在训练中。
-
Linly-ChatFlow:中文对话模型,在 400 万指令数据集合上对中文基础模型指令精调,现已开放 7B、13B 对话模型。
-
Linly-ChatFlow-int4 :ChatFlow 4-bit 量化版本,用于在 CPU 上部署模型推理。
进行中的项目:
- Linly-Chinese-BLOOM:基于 BLOOM 中文增量训练的中文基础模型,包含 7B 和 175B 模型量级,可用于商业场景。
Chinese-Vicuna —— 基于 LLaMA 的中文大语言模型
Chinese-Vicuna 是一个中文低资源的 LLaMA+Lora 方案。
项目包括
- finetune 模型的代码
- 推理的代码
- 仅使用 CPU 推理的代码 (使用 C++)
- 下载 / 转换 / 量化 Facebook llama.ckpt 的工具
- 其他应用
Chinese-LLaMA-Alpaca —— 中文 LLaMA & Alpaca 大模型
Chinese-LLaMA-Alpaca 包含中文 LLaMA 模型和经过指令微调的 Alpaca 大型模型。
这些模型在原始 LLaMA 的基础上,扩展了中文词汇表并使用中文数据进行二次预训练,从而进一步提高了对中文基本语义理解的能力。同时,中文 Alpaca 模型还进一步利用中文指令数据进行微调,明显提高了模型对指令理解和执行的能力。
ChatYuan —— 对话语言大模型
ChatYuan 是一个支持中英双语的功能型对话语言大模型。ChatYuan-large-v2 使用了和 v1 版本相同的技术方案,在微调数据、人类反馈强化学习、思维链等方面进行了优化。
ChatYuan-large-v2 是 ChatYuan 系列中以轻量化实现高质量效果的模型之一,用户可以在消费级显卡、 PC 甚至手机上进行推理(INT4 最低只需 400M )。
华佗 GPT —— 开源中文医疗大模型
HuatuoGPT(华佗 GPT)是开源中文医疗大模型,基于医生回复和 ChatGPT 回复,让语言模型成为医生,提供丰富且准确的问诊。

HuatuoGPT 致力于通过融合 ChatGPT 生成的 “蒸馏数据” 和真实世界医生回复的数据,以使语言模型具备像医生一样的诊断能力和提供有用信息的能力,同时保持对用户流畅的交互和内容的丰富性,对话更加丝滑。
本草 —— 基于中文医学知识的 LLaMA 微调模型
本草(BenTsao)【原名:华驼 (HuaTuo)】是基于中文医学知识的 LLaMA 微调模型。
此项目开源了经过中文医学指令精调 / 指令微调 (Instruct-tuning) 的 LLaMA-7B 模型。通过医学知识图谱和 GPT3.5 API 构建了中文医学指令数据集,并在此基础上对 LLaMA 进行了指令微调,提高了 LLaMA 在医疗领域的问答效果。
鹏程·盘古α —— 中文预训练语言模型
「鹏程·盘古α」是业界首个 2000 亿参数以中文为核心的预训练生成语言模型,目前开源了两个版本:鹏程·盘古α和鹏程·盘古α增强版,并支持NPU和GPU两个版本,支持丰富的场景应用,在知识问答、知识检索、知识推理、阅读理解等文本生成领域表现突出,具备较强的少样本学习的能力。
基于盘古系列大模型提供大模型应用落地技术帮助用户高效的落地超大预训练模型到实际场景。整个框架特点如下:
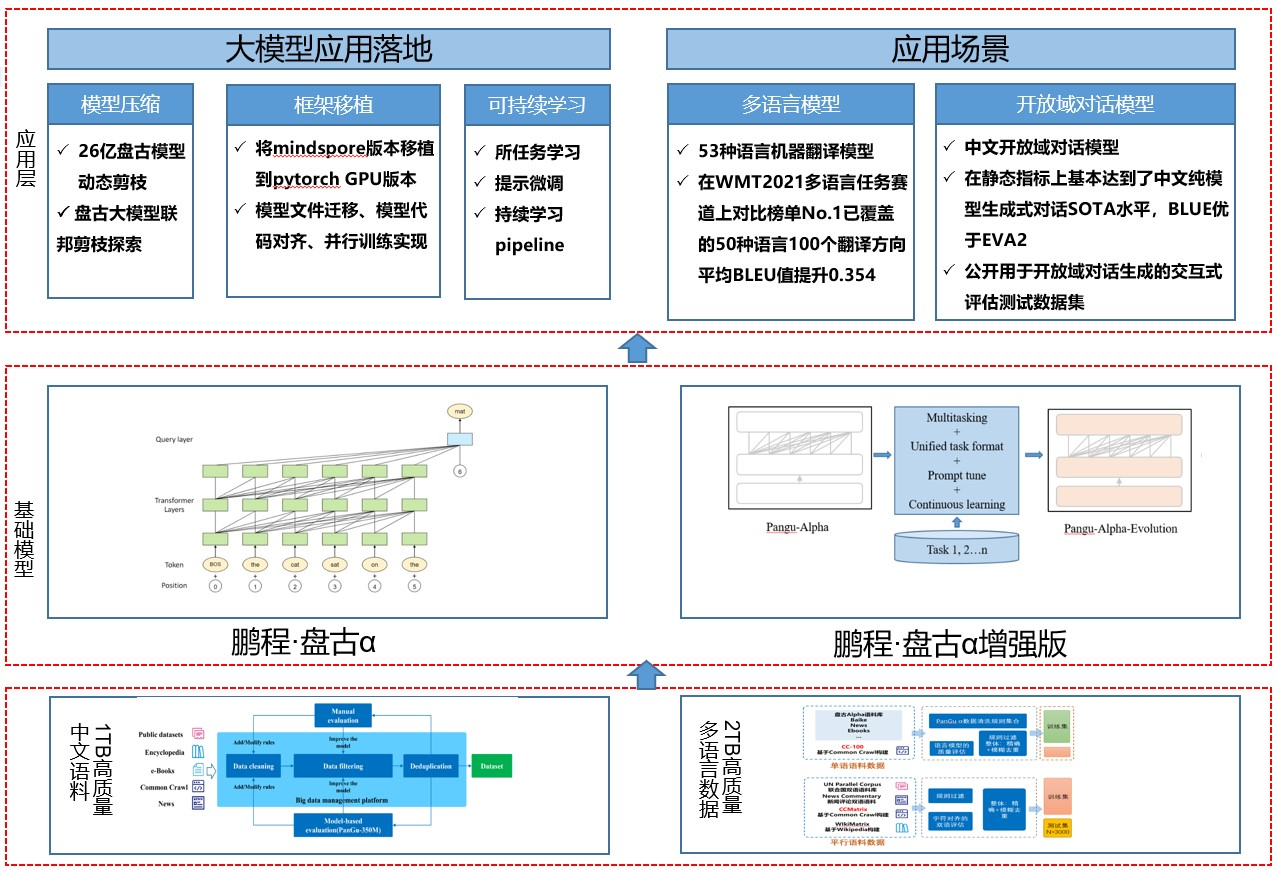
主要有如下几个核心模块:
-
数据集:从开源开放数据集、common crawl 数据集、电子书等收集近 80TB 原始语料,构建了约 1.1TB 的高质量中文语料数据集、53 种语种高质量单、双语数据集 2TB。
-
基础模块:提供预训练模型库,支持常用的中文预训练模型,包括鹏程・盘古 α、鹏程・盘古 α 增强版等。
-
应用层:支持常见的 NLP 应用比如多语言翻译、开放域对话等,支持预训练模型落地工具,包括模型压缩、框架移植、可持续学习,助力大模型快速落地。
鹏程·盘古对话生成大模型
鹏程・盘古对话生成大模型 (PanGu-Dialog)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











