






ElasticSearch:
-
简介:简称es,是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene™ 基础上的搜索引擎,默认端口9200,具有一下概念:
- **shard分片:**一台服务器,无法存储大量的数据,ES把一个index里面的数据,分为多个shard,分布式的存储在各个服务器上面。
- **replica副本:**一个分布式的集群,难免会有一台或者多台服务器宕机,在ES集群中,我们一模一样的数据有多份能正常提供查询和插入的分片我们叫做 primary shard,其余的我们就管他们叫做 replica shard(备份的分片)。
- 可扩展到上百台服务器,处理PB级别的结构化或非结构化数据
-
ELK的下载地址
https://www.elastic.co/cn/downloads/ -
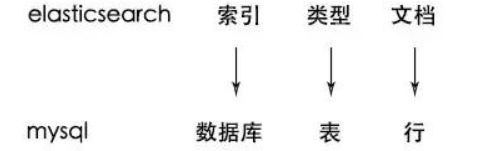
Elasticsearch与关系型数据术语对照:
-
是ELK的一个组成,是一个产品,而且是非常完善的产品,ELK代表的是:E就是ElasticSearch,L就是Logstach,K就是kibana
**E:**EalsticSearch 搜索和分析的功能
**L:**Logstach 搜集数据的功能,类似于flume(使用方法几乎跟flume一模一样),是日志收集系统
**K:**Kibana 数据可视化(分析),可以用图表的方式来去展示,文不如表,表不如图,是数据可视化平台
-
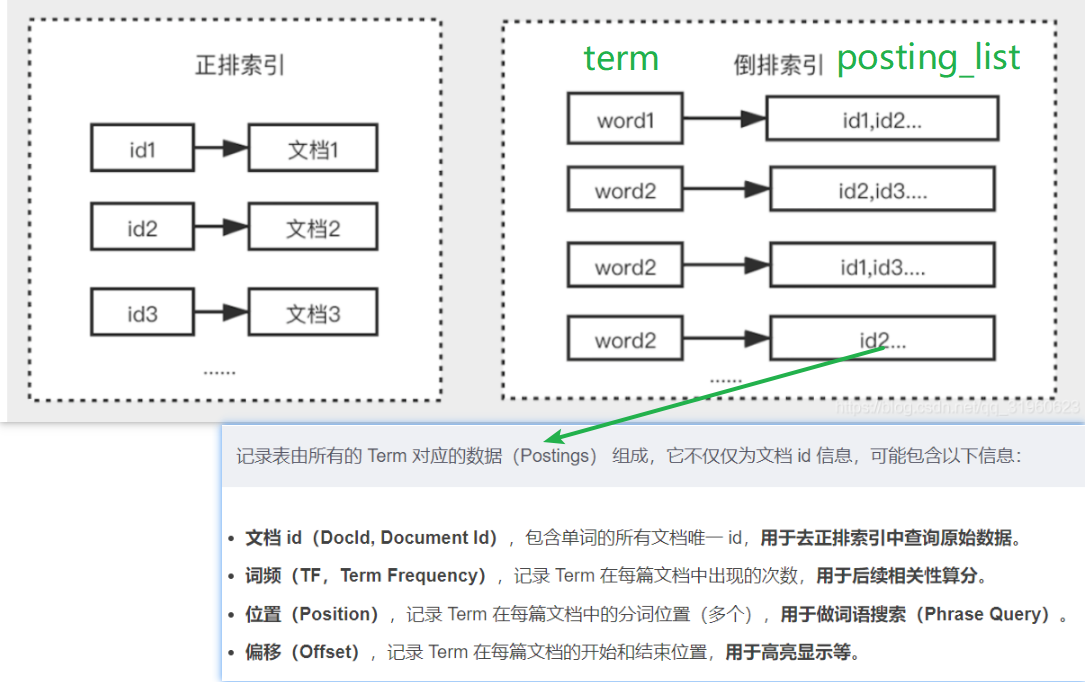
Lucene 作为 Apache 开源的一款搜索工具,一直以来是实现搜索功能的神兵利器,现今火热的 Solr 和 Elasticsearch 均基于该工具包进行开发,而 Lucene 之所以能在搜索中发挥至关重要的作用正是因为倒排索引。
-
常用的脚本:
-
operate_es.sh:
#!/bin/bash while [ "1" == "1" ] do echo "=================== 请输入相应命令进行操作 ===================" echo "------------------- 1 查看ES运行状态 -------------------" echo "------------------- 2 启动 ES -------------------" echo "------------------- 3 关闭 ES -------------------" echo "------------------- 4 退出 -------------------" read -p "请输入序号:" read_num echo ${read_num} case ${read_num} in "1") echo -e "\033[34m ---------- 选择序号:1 ---------- \033[0m" #sh start_es.sh ;; "2") echo -e "\033[34m ---------- 选择序号:2 ---------- \033[0m" #sh see_es.sh ;; "3") echo -e "\033[34m ---------- 选择序号 3 ---------- \033[0m" #sh stop_es.sh ;; *) echo -e "\033[34m ---------- 选择序号:4 ---------- \033[0m" break; ;; esac done -
see_es.sh:
#!/bin/bash es_ps=`jps|grep Elasticsearch` OLD_IFS="$IFS" IFS=" " arr=($es_ps) IFS="$OLD_IFS" if [ -z "${arr[0]}" ] then echo -e "\033[31m Elasticsearch 未启动............. \033[0m" else echo -e "\033[31m --------------Elasticsearch已经在运行,进程id:${arr[0]} -------------- \033[0m" fi -
start_es.sh:
#!/bin/sh es=/home/elasticsearch/elasticsearch-6.7.1/bin cd ${es} #cd /home/elasticsearch/elasticsearch-6.7.1/bin #sh elasticsearch sh elasticsearch -d echo -e "\033[5;31m elasticsearch 后台正在启动............ \033[0m" -
stop_es.sh:
#!/bin/bash es_ps=`jps|grep Elasticsearch` OLD_IFS="$IFS" IFS=" " arr=($es_ps) IFS="$OLD_IFS" if [ -z "${arr[0]}" ] then echo -e "\033[31m Elasticsearch 未启动............. \033[0m" else echo -e "\033[31m 正在停止Elasticsearch,进程id: ${arr[0]} \033[0m" kill -9 ${arr[0]} echo -e "\033[31m 进程已停止................. \033[0m" fi
-
-
分词器:全文搜索引擎会用某种算法对要建索引的文档进行分析, 从文档中提取出若干Token(词元), 这些算法称为Tokenizer(分词器), 这些Token会被进一步处理, 比如转成小写等, 这些处理算法被称为Token Filter(词元处理器), 被处理后的结果被称为Term(词), 文档中包含了几个这样的Term被称为Frequency(词频)。 引擎会建立Term和原文档的Inverted Index(倒排索引), 这样就能根据Term很快到找到源文档了。 文本被Tokenizer处理前可能要做一些预处理, 比如去掉里面的HTML标记, 这些处理的算法被称为Character Filter(字符过滤器), 这整个的分析算法被称为Analyzer(分析器)。
-
分词器的类型有standard analyzer,每个字都会分词,推荐使用安装ik分词器
-
Text:会分词,然后进行索引,keyword:不进行分词,直接索引
-
查看分词效果:
GET /_analyze { "text":"我们的家乡", "analyzer":"standard" }
-
-
json格式的索引:指定多个分词器需要子属性
{ "properties":{ "id":{ "type":"keyword" }, "mascLibId":{ "type":"keyword" }, "mascText":{ "type":"text", "ananlyzer":"hanlp_nlp", "fields":{ "standard":{ "type":"text", "ananlyzer":"hanlp_nlp", } } }, "paperdate":{ "type":"date", "formate":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis" } } } -
es的Restful的操作方式操作资源:↓↓↓
Restful就是一个资源定位、资源操作的风格。不是标准也不是协议,只是一种风格。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。REST是REpresentational State Transfer的缩写(表述性状态转移)
资源:互联网所有的事物都可以被抽象为资源 REST是面向资源的,而资源是通过URI进行暴露的,操作资源通过HTTP动词来实现,URI暴露资源时,URI强调不要使用动词
规则:
CRUD 动作 HTTP 方法 Create POST Read GET Update PUT Delete DELETE **无状态:**REST是无状态的,对每个资源的请求,都不依赖与其他资源或其他请求,每个资源,都是可寻址的,都至少有一个url能对其定位。
-
#查看所有信息 GET indexname/_search { "from":0, "size":30, "query":{ "match_all":{} } } -
#按条件查询 GET indexname/_search { "query":{ "match":{ "title":"哈哈" } } } -
#根据id更新稿件信息 POST indexname/_update/55681224665412 { "doc":{ "title":"更改之后的标题", "text":"更改之后的文本" } } -
#插入数据 POST indexname/_doc/9865522255555 { "id":"9865522255555", "title":"插入的标题", "text":"插入的文本", "date":null } -
#根据条件删除数据 POST indexname/_delete_by_query?refresh { "query":{ "bool":{ "must_not":{ "match":{ "authorId":"000000" } } } } } -
#查询排序 GET indexname/_search { "size":100, "query":{ "match":{ "chanel":"04" } }, "sort":[ { "date":{ "order":"desc" } }, { "_score":{ "order":"desc" } } ] } -
#查询去重 { "collapse": { "field": "过滤的字段" }, "query": { "bool": { } } } -
#查询某种数据量的大小 POST ccbnpmasc/_count { "query":{ "match":{ "chanel":"01" } } }
-
-
es集群加密码:
一: 生成证书
在elasticsearch目录下执行,会在目录elasticsearch的文件目录生成elastic-stack-ca.p12文件,比如我这里是/home/elasticsearch
./elasticsearch-certutil ca
Please enter the desired output file [elastic-stack-ca.p12]: elastic-stack-ca.p12
Enter password for elastic-stack-ca.p12 :
生成 elastic-stack-ca.p12后,执行命令elasticsearch-certutil,需要注意的是elastic-stack-ca.p12文件必须是完整路径
./elasticsearch-certutil cert --ca /home/elasticsearch/elastic-stack-ca.p12
Enter password for CA (/home/elasticsearch/elastic-stack-ca.p12) :
Please enter the desired output file [elastic-certificates.p12]: elastic-certificates.p12
Enter password for elastic-certificates.p12 : #这里可以不用输入密码,直接按回车键
Certificates written to /home/elasticsearch/elastic-certificates.p12
生成的elastic-certificates.p12文件拷贝到每个节点的config目录下
二 :修改配置elasticsearch.yml
elasticsearch.yml配置文件中增加下列配置
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
三 :配置密码
在bin目录下输入下列命令
./elasticsearch-setup-passwords interactive
Enter password for [elastic]: Reenter password for [elastic]: Enter password for [apm_system]: Reenter password for [apm_system]: Enter password for [kibana]: Reenter password for [kibana]: Enter password for [logstash_system]: Reenter password for [logstash_system]: Enter password for [beats_system]: Reenter password for [beats_system]: Enter password for [remote_monitoring_user]: Reenter password for [remote_monitoring_user]: Changed password for user [apm_system] Changed password for user [kibana] Changed password for user [logstash_system] Changed password for user [beats_system] Changed password for user [remote_monitoring_user] Changed password for user [elastic]
-
kinaba 的后台启动
nohup ./kibana & -
kibana 强制关闭
netstat -anp |grep 5601 kill -9 pid -
es的安装
es kibana logstash 下载地址 https://www.oracle.com/java/technologies/javase/jdk12-archive-downloads.html tar -zxvf elasticsearch-7.10.1-linux-x86_64.tar.gz cd elasticsearch-7.10.1 mkdir data (mkdir logs) vim /config/elasticsearch.yml 修改配置文件 -
安装jdk
下载地址: https://www.oracle.com/java/technologies/javase/jdk12-archive-downloads.html tar -zxvf jdk-12.0.2_linux-x64_bin.tar.gz 修改环境变量 vim /etc/profile export JAVA_HOME=/home/ap/ccbnp/jdk_12/jdk-12.0.2 export CLASSPATH=$JAVA_HOME/lib export PATH=$JAVA_HOME/bin:$PATH 使其生效 source /etc/profile 别的用户无法使用 vim ~/.bash_profile 需要修改这个文件















 543
543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









