







章台柳,章台柳,昔日青青今在否?
本文基于《Redis设计与实现》一书
三种特殊数据结构
GEO
GEO即地址信息定位,可以用来存储经纬度,计算两地距离,范围计算等。
GEO类型的基本操作
# 添加坐标点
geoadd key longitude latitude member [longitude latitude member ...]
georadius key longitude latitude radius m|km|ft|mi [withcoord] [withdist] [withhash] [count count]
# 获取坐标点
geopos key member [member ...]
georadiusbymember key member radius m|km|ft|mi [withcoord] [withdist] [withhash] [count count]
# 计算坐标点距离
geodist key member1 member2 [unit]
# 计算经纬度
geohash key member [member ...]
# 举例
GEOADD locations 116.419217 39.921133 beijing
GEOPOS locations beijing
GEODIST locations beijing tianjin km //算计举例
GEORADIUSBYMEMBER locations beijing 150km //通过举例计算城市
注意:没有删除命令,他的本质是zset(type locations)所以可以使用zrem key member
- georedius key 经度 纬度 半径(单位)
- georadiusbymember key member 半径(单位)
获取指定位置范围内的地理位置信息集合
127.0.0.1:6379> georadiusbymember cities:locations beijing 150 km # 获取距离北京150km范围内的城市
1) "beijing"
2) "tianjin"
3) "tangshan"
4) "baoding"
HyperLogLog
基数统计算法,用于统计独立UV(一个人访问一个网站多次,但是还算做一个人)
基数:集合中不重复的元素
API:
//添加数据
PFadd key element [element ...]
//统计数据
PFCOUNT key [key ...]
//合并数据
PFMERGE destkey sourcekey [sourcekey...]
特点:
- 用于进行基数统计,不是集合,不保存数据,只记录数量而不是具体数据
- pfadd命令不是一次性分配12K内存使用,会随着基数的增加内存逐渐增大
- Pfmerge命令合并后占用的存储空间为12K,无论合并之前数据量多少
优缺点:
- 占用内存是固定的,2^64不同元素的基数,只需要废12kb的内存,从内存角度来选择的话HyperLogLog为首选!
- 误差范围:基数估计的结果是一个带有 0.81% 标准错误的近似值,可忽略不计
- 核心是基数估算算法,最终数值存在一定误差
如果允许容错,可以选择HyperLogLog;如果不允许容错,可以继续选择Set等。
Bitmaps
位存储
位图数据结构,操控二进制来记录,只有0和1两种状态。
API:
| 命令 | 作用 |
|---|---|
| GETBIT key offset | 获取指定key对应偏移量上的bit值 |
| SETBIT key offset value | 对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit)。位的设置或清除取决于 value 参数,可以是 0 也可以是 1 |
| BITCOUNT | 计算给定字符串中,被设置为 1 的比特位的数量。 |
| BITOP operation destkey key [key …] | 对一个或多个保存二进制位的字符串 key 进行位元操作,并将结果保存到 destkey 上 |
| BITPOS key bit [start] [end] | 返回位图中第一个值为 bit 的二进制位的位置。在默认情况下, 命令将检测整个位图, 但用户也可以通过可选的 start 参数和 end 参数指定要检测的范围。 |
注意:
- bitmap是string类型,单个值最大可以使用的内存容量为512MB
- setbit时是设置每个value的偏移量,可以有较大耗时(偏移量不要太大)
- bitmap不是绝对好,用在合适的场景最好
redis五大底层数据结构
SDS(简单动态字符串)
SDS可以用来保存数据库中的字符串值,无论是key还是value都是以对象形式存储,还可以被用作缓冲区(在AOF中应用)

- 其中键值对的键为一个字符串对象,对象是由一个保存了字符串“cities”的SDS实现的
- 键值对的值是一个列表对象,列表对象包含了三个由SDS实现的字符串对象
?为什么redis要采用SDS而不是原有的C字符串呢
先来看一下SDS的C源代码:
struct sdshdr {
// 记录buf数组中已使用字节的数量等于SDS所保存字符串的长度
int len;
// 记录buf数组中未使用字节的数量
int free;
// 字节数组,用于保存字符串
char buf[];
};
如图:

- free为0,表示SDS没有未使用的空间
- len为5,表示SDS保存了一个五字节长的字符串
- 从源码中可以看到,buf属性是一个char类型的数组,最后一个字节保存了空字符’\0’,这个空字符不计算在SDS的len属性之中
值得一提的是,SDS函数会自动为空字符分配这额外的1个字节的空间并把他添加到字符串末尾,这样的好处便是SDS可以直接使用一部分C字符串函数库中的函数,比如printf函数
C字符串:
C语言使用长度为N+1的字符数组来表示长度为N的字符串,并且字符数组的最后一个元素总是空字符’\0’
 C字符串与SDS对比
C字符串与SDS对比
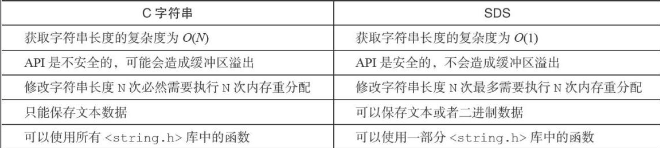
- SDS可以以常数复杂度获取字符串长度
- C字符串并不记录自身的长度信息,因此只能通过遍历字符串来计算长度,复杂度O(N)
- SDS在len属性中记录有sds本身的长度,复杂度O(1)
- 杜绝缓冲区溢出
- 当C字符串进行字符串拼接的时候 ,会默认已经分配了足够多的内存,而一旦这个假定不成立,就会产生缓冲区溢出,那么紧挨着的下一个字符串就会被意外地修改,进行修改的过程中还需要内存重分配,影响性能
- 当SDS的API要对SDS进行修改的时候,API会自动将SDS的空间扩展至执行修改所需的大小,然后才执行实际的修改操作,所以使用SDS既不需要手动修改SDS的空间大小,也不会出现前面所说的缓冲区溢出问题。
- 空间预分配:对SDS进行修改之后,SDS的长度若小于1MB,那么会让free与修改后的len相等;若SDS长度大于等于1MB,那么程序会分配1MB的free空间
- 惰性空间释放:SDS的API要进行SDS的缩短时,并没有真正的释放那部分空间而是将其放在free中,当然,在真正需要释放的时候SDS也有相应的API。
- 二进制安全性
- C字符串中不能包含空字符,否则将会被认为是字符串的结尾,而这个限制使得C字符串只能保存文本数据,而不能保存图片、音频、视频、压缩文件这样的二进制数据
- SDS的API会以处理二进制的方式来处理SDS存放在buf数组里的数据,程序不会对其中的数据做任何限制,也就是说buf中保存的是一系列二进制数据而不是字符,因此我们称buf为字节数组
- 兼容部分C字符串函数
- 前文我们提过SDS的API会总会将SDS保存的数据的末尾设置为空字符,并且会在buf数组中多分配一个字节存储空字符,这就是为了SDS可以重用一部分<string.h>库定义的函数
链表
Redis使用的C语言并没有内置这种数据结构,所以Redis构建了自己的链表实现。
链表节点源码:
typedef struct listNode {
// 前置节点
struct listNode * prev;
// 后置节点
struct listNode * next;
// 节点的值
void * value;
}listNode;
这不就是我们熟悉的双端链表嘛!
Redis还提供了list来持有链表:
typedef struct list {
// 表头节点
listNode * head;
// 表尾节点
listNode * tail;
// 链表所包含的节点数量
unsigned long len;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void (*free)(void *ptr);
// 节点值对比函数
int (*match)(void *ptr,void *key);
} list;
- dup函数用于复制链表节点所保存的值
- free函数用于释放链表节点所保存的值
- match函数用于对比链表节点所保存的值喝另一个输入值是否相等
eg:一个list和三个listNode结构组成的链表
 总结:
总结:
- 链表表头节点的前置节点和表尾节点的后置节点都指向NULL,所以Redis的链表实现的是无环链表
- 链表节点使用void*指针来保存节点值,并且可以通过list结构的dup、free、match三个属性为节点值设置类型特定函数,所以链表可以用于保存各种不同类型的值
字典
一种用于保存键值对的抽象数据结构,Redis构建了自己的字典实现,Redis数据库的底层实现就是通过使用字典,crud操作也是构建在对字典的操作之上
字典使用哈希表作为底层实现
一个哈希表里面可以有多个哈希表节点,而每个哈希表节点就保存了字典中的一个键值对
哈希表源码:
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值
//总是等于size-1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;

- table属性是一个数组,数组中的每个元素都是一个指向dictEntry的指针,每个dictEntry结构保存着一个键值对。
- size属性记录了哈希表的大小
- used属性记录哈希表目前已有节点数量
- sizemask属性的值总是等于size-1,他和哈希值一起决定一个键应该放在table数组的哪个索引上
哈希表节点源码:
typedef struct dictEntry {
// 键
void *key;
// 值
union{
void *val;
uint64_tu64;
int64_ts64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
- next属性是指向另一个哈希表节点的指针,这个指针可以将多个哈希值相同的键值对连接在一起,故可以解决键冲突问题(我们熟悉的链地址法)
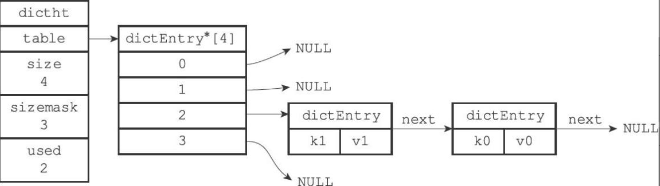 字典
字典
字典源码:
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash索引
//当rehash不在进行时,值为-1
in trehashidx; /* rehashing not in progress if rehashidx == -1 */
} dict;
- type是指向dictType结构的指针,每个dictType结构保存了一簇用于操作特定类型键值对的函数,Redis会为用途不同的字典设置不同的类型特性函数
- privdata属性保存需要传给那些类型特定函数的可选参数。
- ht是一个包含两个项的数组,数组中的每个项都是一个dictht哈希表,字典只是用ht[0],ht[1]只会在对ht[0]进行rehash时使用
typedef struct dictType {
// 计算哈希值的函数
unsigned int (*hashFunction)(const void *key);
// 复制键的函数
void *(*keyDup)(void *privdata, const void *key);
// 复制值的函数
void *(*valDup)(void *privdata, const void *obj);
// 对比键的函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// 销毁键的函数
void (*keyDestructor)(void *privdata, void *key);
// 销毁值的函数
void (*valDestructor)(void *privdata, void *obj);
} dictType;
普通状态下的字典
 哈希算法
哈希算法
Redis计算哈希值和索引值的方法(MurmurHash2):
//使用字典设置的哈希函数,计算键key的哈希值
hash = dict->type->hashFunction(key);
//使用哈希表的sizemask属性和哈希值,计算出索引值
//根据情况不同,ht[x]可以是ht[0]或者ht[1]
index = hash & dict->ht[x].sizemask;
rehash
rehash的目的是为了让load factor(负载因子)维持在一个正常的范围之内,因为当键值对过多时,造成hash冲突的可能性就越大,因此就需要进行扩展;而当键值对太少时,为了防止冗余,就需要进行哈希表的收缩
负载因子计算方法:
#负载因子= 哈希表已保存节点数量/ 哈希表大小
load_factor = ht[0].used / ht[0].size
rehash步骤
- 为ht[1]哈希表分配空间,ht[1]大小取决于要执行的操作,以及ht[0]当前包含的键值对数量(ht[0].used)
- 若扩展,ht[1]的大小为第一个大于等于ht[0].used*2的2 n (2的n次方幂);
- 若收缩,ht[1]的大小为第一个大于等于ht[0].used的2 n 。
- 将保存在ht[0]中的所有键值对rehash到ht[1]上面:rehash指的是重新计算键的哈希值和索引值,然后将键值对放置到ht[1]哈希表的指定位置上。
- ht[0]包含的所有键值对都迁移到了ht[1]之后(ht[0]变为空表),释放ht[0],将ht[1]设置为ht[0],并在ht[1]新创建一个空白哈希表,为下一次rehash做准备。
渐进式rehash
我们知道了rehash就是将ht[0]中的键值对rehash到ht[1]之中,若ht[0]中键值对很多很多,一次性全部rehash就会产生庞大的计算量,从而导致服务器在一段时间内停止服务
步骤:
- 为ht[1]分配空间,让字典同时持有ht[0]和ht[1]两个哈希表
- 在字典中维持一个索引计数器变量rehashidx,并将它的值设置为0,表示rehash工作正式开始。
- 在rehash进行期间,每次对字典执行添加、删除、查找或者更新操作时,程序除了执行指定的操作以外,还会顺带将ht[0]哈希表在rehashidx索引上的所有键值对rehash到ht[1],当rehash工作完成之后,程序将rehashidx属性的值增一。
- 随着字典操作的不断执行,最终在某个时间点上,ht[0]的所有键值对都会被rehash至ht[1],这时程序将rehashidx属性的值设为-1,表示rehash操作已完成。
另外需要注意的是在渐进式rehash进行期间,字典的删除、查找、更新等操作会在两个哈希表上进行。且新添加到字典的键值对一律会被保存到ht[1]里面。
跳跃表
一种有序数据结构,通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的

zskiplistNode结构(右边):
typedef struct zskiplistNode {
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
// 后退指针
struct zskiplistNode *backward;
// 分值
double score;
// 成员对象
robj *obj;
} zskiplistNode;
- level:节点中用L1、L2、L3等标记节点的各个层,每个层带有两个属性:前进指针和跨度,每创建一个新的跳跃表节点时,程序都根据幂次定律(power law,越大的数出现的概率越小)随机生成一个介于1和32之间的值作为level数组的大小,这个大小就是层的“高度”
- 前进指针:用于访问位于表尾方向的其他节点
- 跨度:记录前进指针所指向的节点和当前节点的距离,与遍历无关,用来计算排位(rank)
- 后退指针:指向位于当前节点的前一个节点。在程序从表尾向表头遍历时使用
- 分值:节点按各自保存的分值从小到大排列,当分值相同时节点按照成员对象的大小进行排序,多个节点可以包含同样的分值
- 成员遍历:obj属性是一个指针,指向一个字符串对象,而字符串对象则保存着一个SDS值。,各个节点保存的obj必须是唯一的
zskiplist结构(左边):
typedef struct zskiplist {
//表头节点和表尾节点
structz skiplistNode *header, *tail;
//表中节点的数量
unsigned long length;
//表中层数最大的节点的层数
int level;
} zskiplist;
- header:指向跳跃表的表头节点
- tail:指向跳跃表的表尾节点
- level:记录目前跳跃表中,层数最大的那个节点的层数(表头节点的层数不计算在内)
- length:跳跃表的长度,也是跳跃表目前包含节点的数量(表头节点不计算在内)

整数集合
集合键的底层实现之一,当一个集合只包含整数值元素,并且不多的时候,Redis就会使用整数集合作为集合键的底层实现

typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
eg:

- contents:整数集合的每个元素都是contents数组的一个数组项(item),按从小到大有序排列,不包含重复项
- length:contents数组的长度
- encoding:编码方式,contents数组的真正类型取决于encoding属性的值
整数集合的升级操作:
- 根据新元素的类型,扩展整数集合底层数组的空间大小,并为新元素分配空间。
- 将底层数组现有的所有元素都转换成与新元素相同的类型,并将类型转换后的元素放置到正确的位上,而且在放置元素的过程中,需要继续维持底层数组的有序性质不变。
- 将新元素添加到底层数组里面。
整数集合的降级操作:
- 整数集合不支持降级操作,一旦对数组进行了升级,编码就会一直保持升级后的状态。
压缩列表
是列表键和哈希键的底层实现之一,当一个列表键只包含少量列表项,并且每个列表项不是小整数值就是长度较短的字符串时,redis就会使用压缩列表

 eg:
eg:
 压缩列表节点:
压缩列表节点:

- previous_entry_length:记录压缩列表前一个节点的长度
- 如果我们有一个指向当前节点起始地址的指针c,那么我们只要用指针c减去当前节点previous_entry_length属性的值,就可以得出一个指向前一个节点起始地址的指针p
- encoding:记录节点的content属性所保存数据的类型以及长度
- content:保存节点的值,值得类型和长度由encoding属性决定
连锁更新
添加新节点到压缩列表,或者从压缩列表中删除节点,可能会引发连锁更新操作
 值得注意的是,连锁更新对性能的影响是不大的:
值得注意的是,连锁更新对性能的影响是不大的:
- 首先,压缩列表里要恰好有多个连续的、长度介于250字节至253字节之间的节点,连锁更新才有可能被引发,在实际中,这种情况并不多见;
- 其次,即使出现连锁更新,但只要被更新的节点数量不多,就不会对性能造成任何影响。
Redis对象与底层数据结构的关系
Redis中一切的结构都是对象,之前提到的string、list、hash、set、zset都是对象
对象
Redis使用对象来表示数据库中的键和值,每次当我们在Redis的数据库中新建一个键值对的时候,至少会创建两个对象,一个键对象,一个值对象
typedef struct redisObject {
// 类型
unsigned type:4;
// 编码
unsigned encoding:4;
// 指向底层实现数据结构的指针
void *ptr;
// ...
} robj;
对象的ptr指针指向对象的底层实现数据结构,而这些数据结构由对象的encoding属性决定

















 1115
1115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









