







1.事务的ACID特性
1.隔离性(Isolation)
隔离性是指,事务内部的操作与其他事务是隔离的,并发执行的各个事务之间不能互相干扰。隔离性是通过锁+MVCC来控制的。
2.原子性(Atomicity)
事务是一个不可分割的工作单位,要么全部提交,要么全部失败回滚。原子性是通过undo log实现的。
3.一致性(consistency)
事务前后的数据必须保持一致性。一致性是通过redo log+undo log实现的。
4.持久性(Durability)
持久性是指事务一旦提交,它对数据库的改变就应该是永久性的,不会因为宕机等原因而丢失数据,持久性是通过redo log实现的。
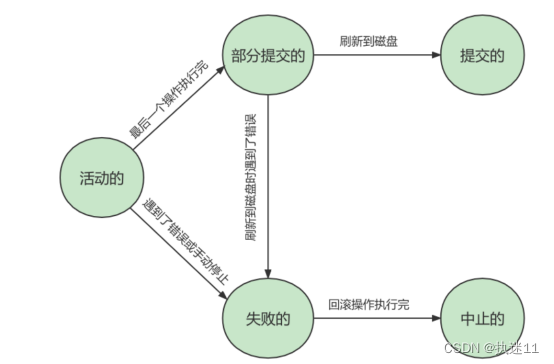
2.事务的状态:
1.活跃的
2.部分提交的
提交但是没有刷新到磁盘
3.失败的
活跃或者部分提交然后遇到错误无法继续执行
4.终止的
回滚
5.提交的
正常提交,正常存到了磁盘
一个事务的最终状态:要么提交,要么终止
3.使用事务
1.显式
步骤1:
显式:BEGI;或者START TRANSACTION;
START TRANSACTION可以跟几个修饰符:READ ONLY(只读) ,READ WRITE(读写),WITH CONSISTENT SNAPSHOT(启动一致性读)
步骤2:
一系列事务中的操作(主要是DML,不含DDL)
步骤3:
提交事务 或 中止事务(即回滚事务)
2.隐式
如果不使用BEGIN 默认会提交事务,也就是隐式事务。
隐式事务默认是开启的
使用BEGIN或者关掉这个系统变量 事务就不会自动提交了。
隐式提交数据的情况
1.数据定义语言(Data definition language,缩写为:DDL)。
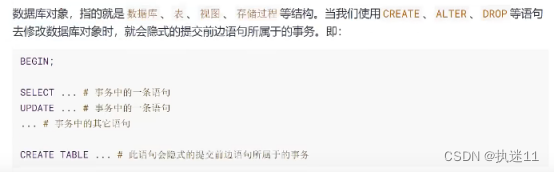
2.隐式使用或修改mysql数据库中的表。

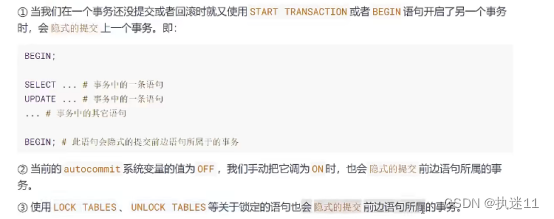
3.使用BEGIN等语句
当我们在一个事务还没提交或者回滚时就又使用 START TRANSACTION 或者 BEGIN 语句开启了另一个事务时,会隐式的提交上一个事务。
4.加载数据的语句。

5.关于MySQL复制的一些语句。
举例1:
TRUNCATE TABLE user3; #清空user3表的内容
SELECT * FROM user3;
SELECT @completion_type; #默认是0
SET @@completion_type = 1;
commit之后表示马上自动开启一个相同隔离级别的事务
BEGIN;
INSERT INTO user3 VALUES(‘张三’); #存入一条数据
COMMIT;
SELECT * FROM user3;#
INSERT INTO user3 VALUES(‘李四’);#存入一条数据可以成功
INSERT INTO user3 VALUES(‘李四’); #存入失败
ROLLBACK;#回滚
SELECT * FROM user3; #只能查询到张三这条数据
#举例2:体会savepoint
CREATE TABLE user3(NAME VARCHAR(15),balance DECIMAL(10,2));
BEGIN
INSERT INTO user3(NAME,balance) VALUES(‘张三’,1000);
COMMIT;
SELECT * FROM user3;

BEGIN;
UPDATE user3 SET balance = balance - 100 WHERE NAME = ‘张三’;
UPDATE user3 SET balance = balance - 100 WHERE NAME = ‘张三’;
SAVEPOINT s1;#设置保存点
UPDATE user3 SET balance = balance + 1 WHERE NAME = ‘张三’;
ROLLBACK TO s1; #回滚到保存点 不是最终状态 还需要提交或回滚
SELECT * FROM user3; #800
ROLLBACK; #回滚操作
SELECT * FROM user3;#1000
4.数据并发引发的问题
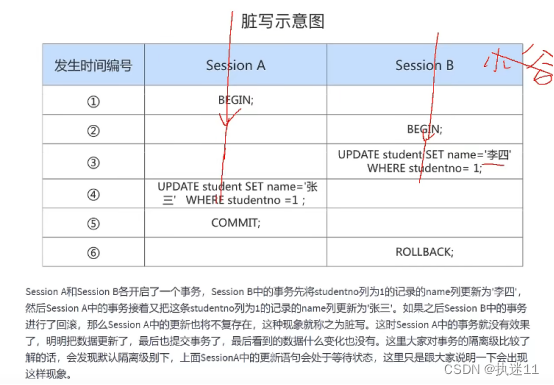
1.脏写
对于两个事务 Session A、Session B,如果事务Session A 修改了另一个未提交 事务Session B 修改过的数据,那就意味着发生了脏写。
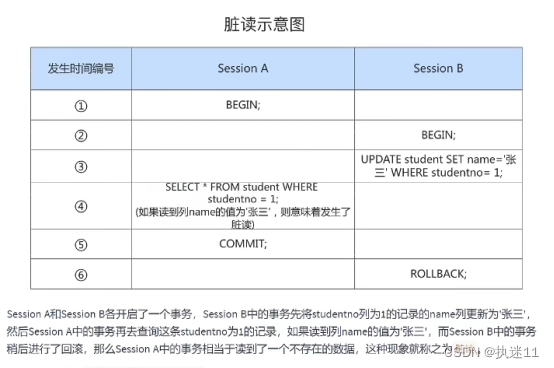
2.脏读
对于两个事务 Session A、Session B,Session A读取了已经被 Session B更新但还没有被提交的字段。之后若Session B回滚 ,Session A读取的内容就是临时且无效的。
3.不可重复读
对于两个事务SessionA、SessionB,SessionA读取了一个字段,然后SessionB更新了该字段。之后Session A再次读取同一个字段,值就不同了。那就意味着发生了不可重复读。(两次读取的值不一样)

我们在Session B中提交了几个隐式事务(注意是隐式事务,意味着语句结束事务就提交了),这些事务都修改了studentno列为1的记录的列name的值,每次事务提交之后,如果Session A中的事务都可以查看到最新的值,这种现象也被称之为不可重复读。
4.幻读
对于两个事务Session A、Session B, Session A 从一个表中读取了一个字段, 然后 Session B在该表中插入了一些新的行。之后, 如果Session A再次读取同一个表, 就会多出几行。那就意味着发生了幻读。(多了数据)


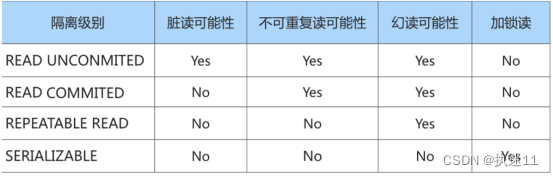
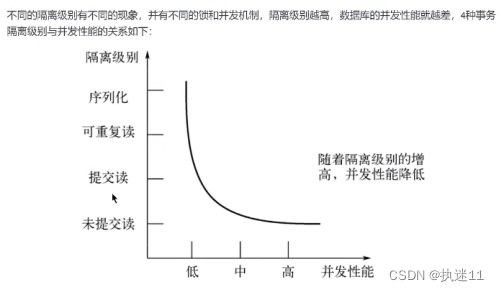
5.MySQL四种隔离级别
1.READ UNCOMMITTED 读未提交
在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。不能避免脏读、不可重复读、幻读。
2.READ COMMITTED 读已提交
它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。可以避免脏读,但不可重复读、幻读问题仍然存在。
3.REPEATABLE READ 可重复读
事务A在读到一条数据之后,此时事务B对该数据进行了修改并提交,那么事务A再读该数据,读到的还是原来的内容。可以避免脏读、不可重复读,但幻读问题仍然存在。这是MySQL的默认隔离级别
4.SERIALIZABLE 可串行化
确保事务可以从一个表中读取相同的行。在这个事务持续期间,禁止其他事务对该表执行插入、更新和删除操作。所有的并发问题都可以避免,但性能十分低下。能避免脏读、不可重复读和幻读。
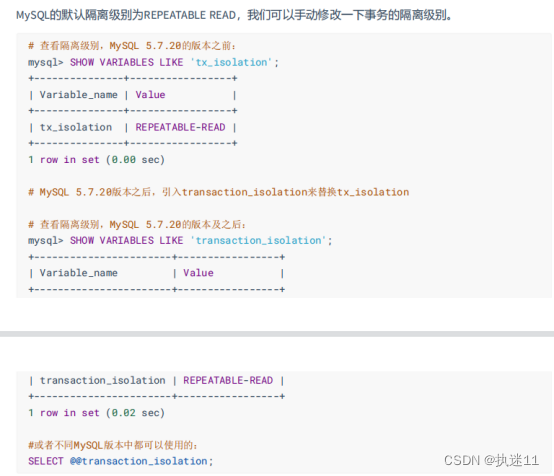
设置隔离级别:
SET [GLOBAL|SESSION] TRANSACTION ISOLATION LEVEL 隔离级别;
#其中,隔离级别格式:
READ UNCOMMITTED
READ COMMITTED
REPEATABLE READ
SERIALIZABLE
或者:
SET [GLOBAL|SESSION] TRANSACTION_ISOLATION = ‘隔离级别’(推荐)
#其中,隔离级别格式:
READ-UNCOMMITTED
READ-COMMITTED
REPEATABLE-READ
SERIALIZABLE
6.redo日志
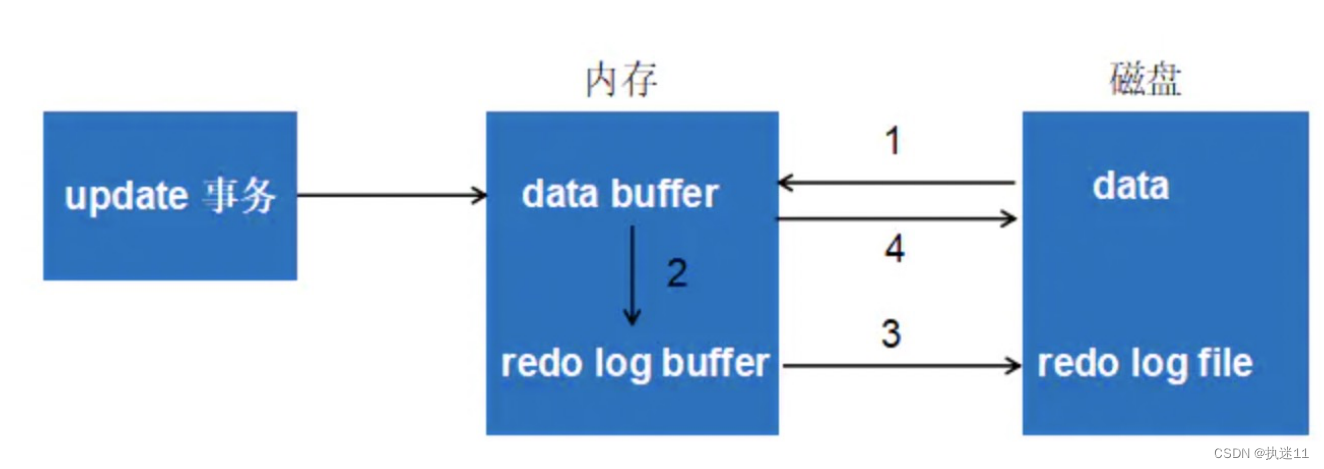
保证事务的持久性
redo log buffer
大小:默认 16M ,最大值是4096M,最小值为1M
查看:show variables like ‘%innodb_log_buffer_size%’;
步骤:
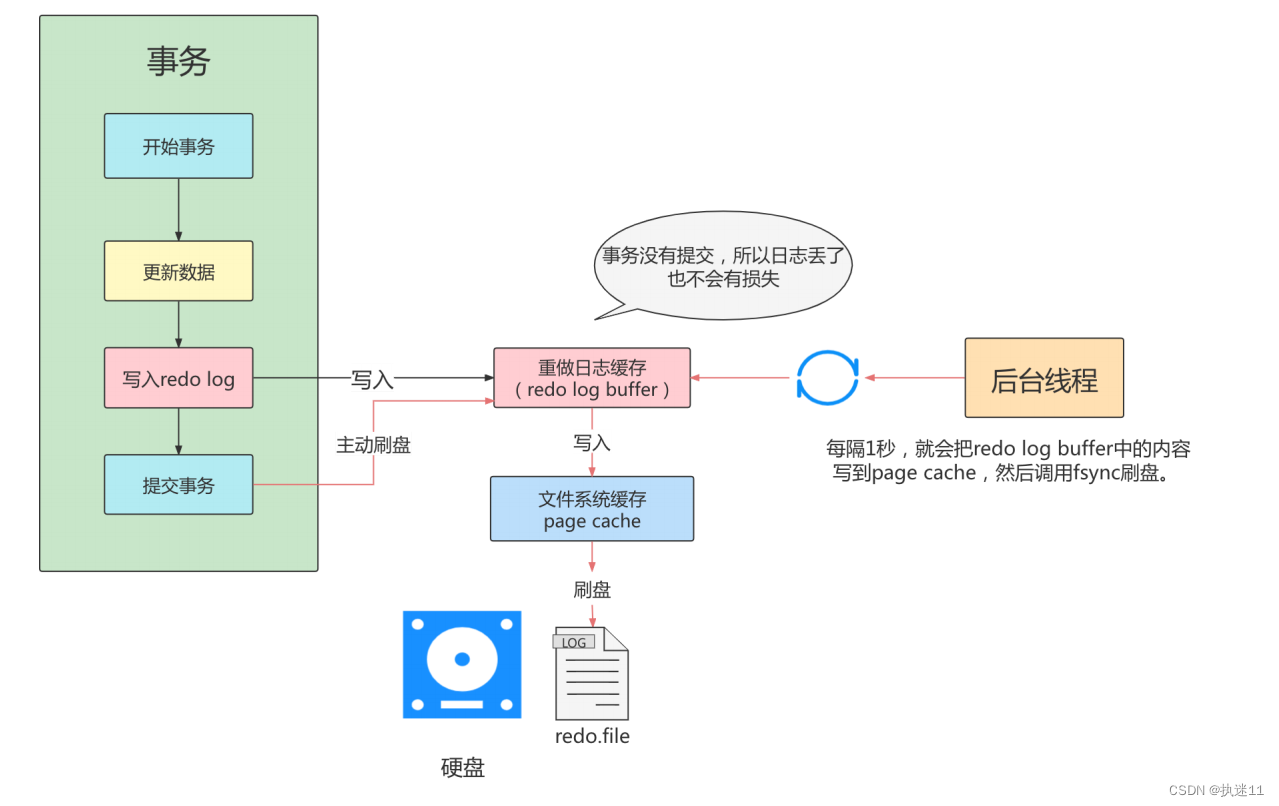
第1步:先将原始数据从磁盘中读入内存中来,修改数据的内存拷贝
第2步:生成一条重做日志并写入redo log buffer,记录的是数据被修改后的值
第3步:当事务commit时,将redo log buffer中的内容刷新到 redo log file,对 redo log file采用追加 写的方式
第4步:定期将内存中修改的数据刷新到磁盘中
innodb_flush_log_at_trx_commit
0:提交事务不进行刷盘,系统默认每1s刷盘一次。
1:表示每次事务提交时都将进行同步,刷盘操作( 默认值 )
2:表示每次事务提交时都只把 redo log buffer 内容写入 page cache,不进行同步。由os自己决定什么时候同步到磁盘文件。
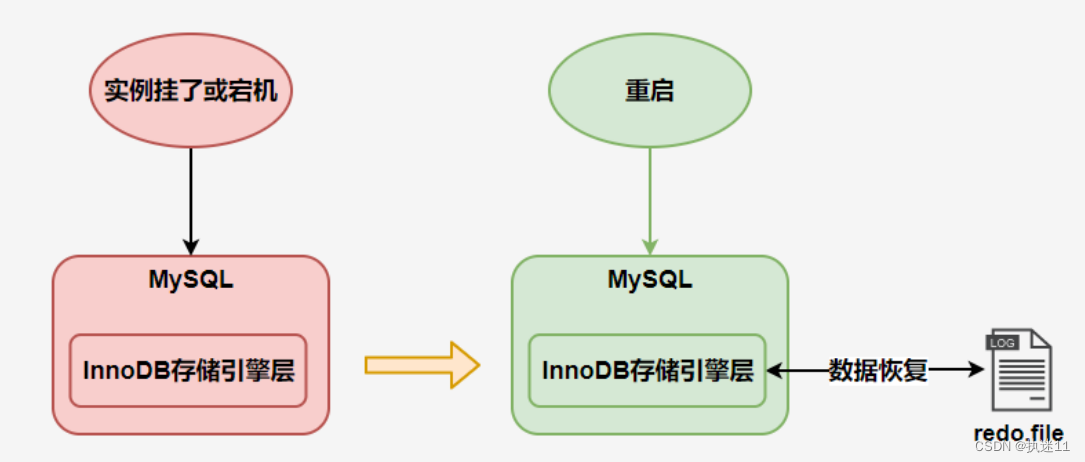
redo log file
innodb_log_files_in_group
指明redo log file的个数,命名方式如:ib_logfile0,iblogfile1… iblogfilen。默认2个,最大100个。
innodb_log_group_home_dir
指定 redo log 文件组所在的路径,默认值为 ./ ( var/lib/mysql )
innodb_log_file_size
单个 redo log 文件设置大小,默认值为 48M 。最大值为512G
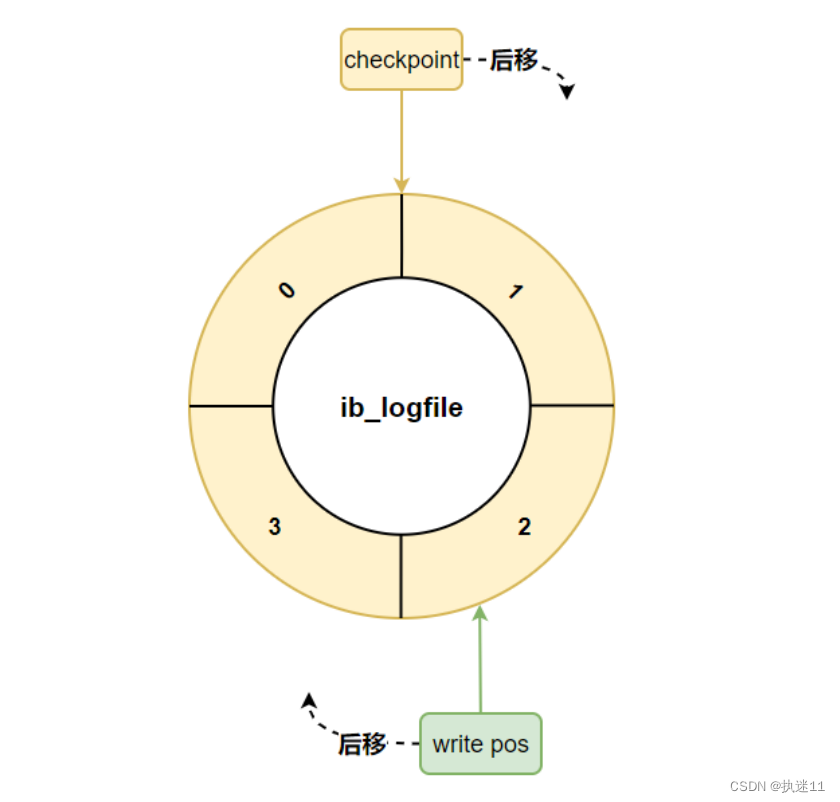
采用循环使用的方式向redo日志文件组里写数据的话,会导致后写入的redo日志覆盖掉前边写的redo日志?当然! 需要确定最一开始的文件一定要刷到磁盘中了
write pos:写文件内容的指针 只要记录redo日志 这个指针就往后移
checkpoint: 记录持久化内容的指针 数据刷新到磁盘了了 这个指针就往后移
当write pos超过了checkpoint一圈 说明文件写满了 需要清理
7.undo日志
回滚行记录到某个特定版本,用来保证事务的原子性、一致性。每次增删改之前,将数据存到undolog
插入一条记录时:至少要把这条记录的主键记录下来,之后回滚的时候只需要把这个主键对应的记录删掉就可以了
删除一条记录时,要把这条记录的内容都记下来,回滚的时候再把这条数据插入到表中
修改一条记录时:要把这条记录的旧值都保存下来,回滚的时候再把这条记录更新为旧值
查询不会记录undo日志
undo log 也会产生redolog undolog也需要持久性的保护
mysql默认一页是16kb, 如果每个事务都分配一页的话,资源比较浪费,所以undo页设为可重用,当事务提交是,并不会立即删除undo页,undolog在commit后,会被放到一个链表中,然后判断undo页的使用空间是否小于3/4,小于的话,表示当前的undo页可以被重用,其他的undo log 可以记录在当前undo页的后面。
InnoDB对undo log的管理采用段的方式,也就是 回滚段(rollback segment) 。每个回滚段记录了1024 个 undo log segment ,而在每个undo log segment段中进行 undo页 的申请。InnoDB支持最大 128个rollback segment ,故其支持同时在线的事务限制提高到了 128*1024 。
回滚段与事务
- 每个事务只会使用一个回滚段,一个回滚段在同一时刻可能会服务于多个事务。
- 当一个事务开始的时候,会指定一个回滚段,在事务进行的过程中,当数据被修改时,原始的数据会被复制到回滚段。
- 在回滚段中,事务会不断填充盘区,直到事务结束或所有的空间被用完。如果当前的盘区不够用,事务会在段中请求扩展下一个盘区,如果所有已分配的盘区都被用完,事务会覆盖最初的盘
区或者在回滚段允许的情况下扩展新的盘区来使用。 - 回滚段存在于undo表空间中,在数据库中可以存在多个undo表空间,但同一时刻只能使用一个undo表空间。
- 当事务提交时,InnoDB存储引擎会做以下两件事情:
将undo log放入列表中,以供之后的purge(清除)操作
判断undo log所在的页是否可以重用,若可以分配给下个事务使用
回滚段中的数据分类
- 未提交的回滚数据(uncommitted undo information)
- 已经提交但未过期的回滚数据(committed undo information)
- 事务已经提交并过期的数据(expired undo information)
事务提交后并不能马上删除undolog及所在的页,因为可能还有其他事物需要通过undolog来得到行记录之前的版本,所以事务提交时将udno log 放到一个立案表中,是否可以最终删除undo log及undo log所在的页由purge线程来判断。
insert undolog 只对当前事务可见,对其他事务不可见,所以undo log 在事务提交后可以直接删除,不需要进行purge操作
**update undo log 记录的是delete 和update操作产生的undolog 该undolog 可能需要提供MVCC机制,因此不能在事务提交时就进行删除,提交时放入undo log链表,等待purge线程进行最后的删除。
**
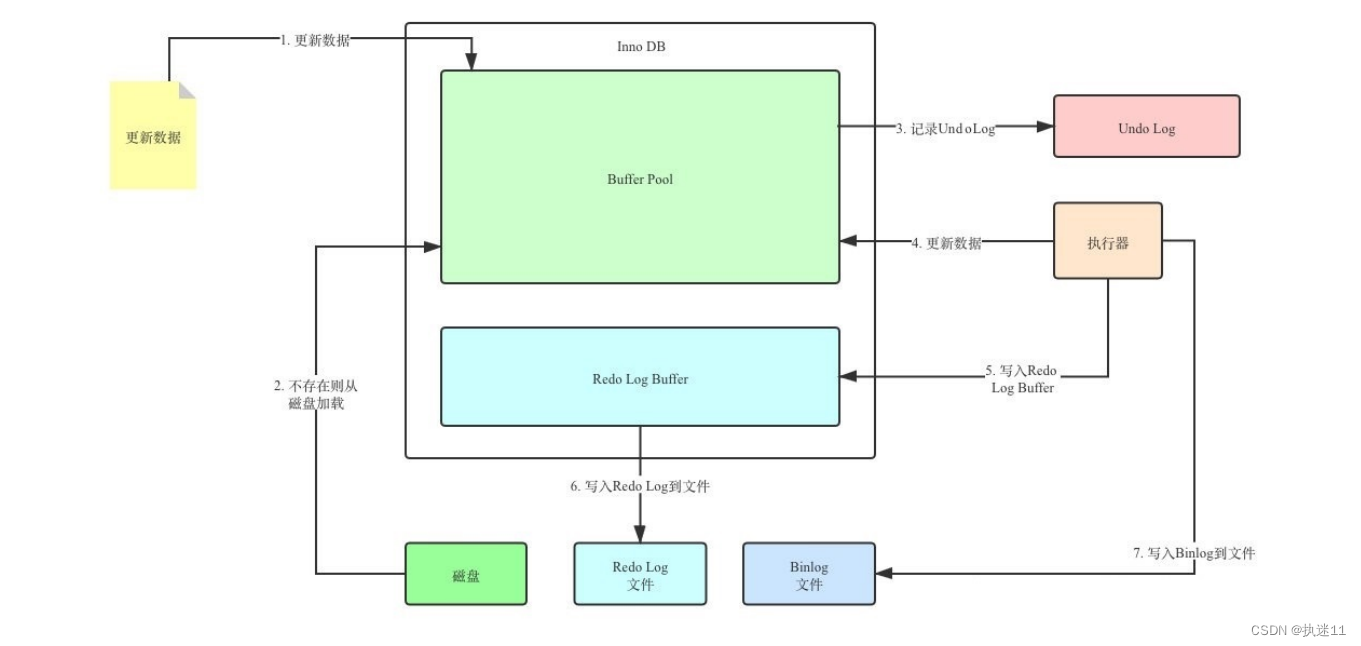
执行更新数据时
1.先查询数据库缓冲池是否有数据,没有的话从磁盘加载到内存
2.记录Undo Log
3.执行器更新数据
4.写入Redo Log Buffer
5.写入Redo Log File
undo log是逻辑日志,对事务回滚时,只是将数据库逻辑地恢复到原来的样子。
redo log是物理日志,记录的是数据页的物理变化,undo log不是redo log的逆过程。
purge线程两个作用:清理undo页和清除page里面带有delete_Bit表示的数据行。
在innodb中,事务中的delete操作实际上并不是真正的删除掉数据行,而是一种delete mark操作,在记录上标识delete_Bit,而不删除记录。是一种假删除,至是做了标记,真正的删除工作需要后台purge线程去完成。















 4547
4547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









