







vcore
NM 主要使用两个参数来限制 containers CPU 资源使用。
首先,使用 yarn.nodemanager.resource.percentage-physical-cpu-limit 来设置所有 containers 的总的 CPU 使用率占用总的 CPU 资源的百分比。比如设置为 60,则所有的 containers 的 CPU 使用总和在任何情况下都不会超过机器总体 CPU 资源的 60 %。
然后,使用 yarn.nodemanager.linux-container-executor.cgroups.strict-resource-usage 设置是否对 container 的 CPU 使用进行严格限制。如果设置为 true ,即便 NM 的 CPU 资源比较空闲, containers CPU 使用率也不能超过限制,这种配置下,可以严格限制 CPU 使用,保证每个 container 只能使用自己分配到的 CPU 资源。但是如果设置为 false ,container 可以在 NM 有空闲 CPU 资源时,超额使用 CPU,这种模式下,可以保证 NM 总体 CPU 使用率比较高,提升集群的计算性能和吞吐量,所以建议使用非严格的限制方式(实际通过 CGroup 的 cpu share 功能实现)。不论这个值怎么设置,所有 containers 总的 CPU 使用率都不会超过 cpu-limit 设置的值。
NM 会按照机器总的 CPU num* limit-percent 来计算 NM 总体可用的实际 CPU 资源,然后根据 NM 配置的 Vcore 数量来计算每个 Vcore 对应的实际 CPU 资源,再乘以 container 申请的 Vcore 数量计算 container 的实际可用的 CPU 资源。这里需要注意的是,在计算总体可用的 CPU 核数时,NM 默认使用的实际的物理核数,而一个物理核通常会对应多个逻辑核(单核多线程),而且我们默认的 CPU 核数通常都是逻辑核,所以我们需要设置 yarn.nodemanager.resource.count-logical-processors-as-cores 为 true 来指定使用逻辑核来计算 CPU 资源。
Hadoop YARN同时支持内存和CPU两种资源的调度,默认只支持内存,如果想进一步调度CPU,需要自己进行一些配置。
目前的CPU被划分成虚拟CPU(CPU virtual Core),这里的虚拟CPU是YARN自己引入的概念,初衷是,考虑到不同节点的CPU性能可能不同,每个CPU具有的计算能力也是不一样的,比如某个物理CPU的计算能力可能是另外一个物理CPU的2倍,这时候,你可以通过为第一个物理CPU多配置几个虚拟CPU弥补这种差异。用户提交作业时,可以指定每个任务需要的虚拟CPU个数。
内存资源的多少会会决定任务的生死,如果内存不够,任务可能会运行失败;相比之下,CPU资源则不同,它只会决定任务运行的快慢,不会对生死产生影响。
由于CPU资源的独特性,目前这种CPU分配方式仍然是粗粒度的。很多任务可能是IO密集型的,消耗的CPU资源非常少,如果此时为它分配一个CPU,则是一种严重浪费,完全可以和其他几个任务共用这个CPU.也就是说,我们需要支持更细粒度的CPU表达方式。借鉴亚马逊EC2中CPU资源的划分方式,即提出了CPU最小单位为EC2 Compute Unit(ECU),一个ECU代表相当于1.0-1.2 GHz 2007 Opteron or 2007 Xeon处理器的处理能力。YARN提出了CPU最小单位YARN Compute Unit(YCU),目前这个数是一个整数,默认是720,由参数yarn.nodemanager.resource.cpu-ycus-per-core设置,表示一个CPU core具备的计算能力(该feature在目前已知版本中不存在,https://issues.apache.org/jira/browse/YARN-1089 & https://issues.apache.org/jira/browse/YARN-1024),这样,用户提交作业时,直接指定需要的YCU即可,比如指定值为360,表示用1/2个CPU core,实际表现为,只使用一个CPU core的1/2计算时间。注意,在操作系统层,CPU资源是按照时
参数设置
————————————————————————————————
1、ApplicationMaster 内存
提交任务到yarn上时,为ApplicationMaster分配的内存量,一般不需要太大,1G-4G即可
在yarn-site.xml中配置
参数名 : yarn.app.mapreduce.am.resource.mb
值:1024mb

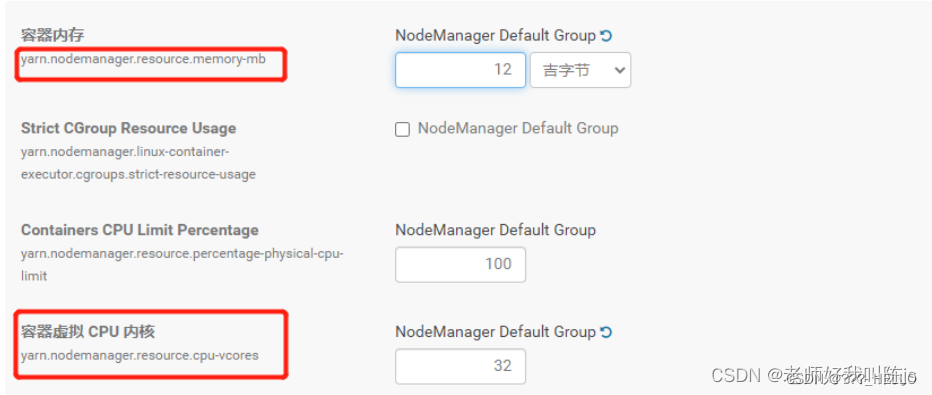
2、容器内存
每台nodemanager节点提供给yarn进行调度管理的内存大小,就是分配多少资源去让yarn进行管理
这个需要根据每台服务器的内存来确定,拿 三台服务器每台8核16G内存举例,每台机器可以给yarn分配16G内存,但不建议全给,一般配置10G-14G即可
参数名:yarn.nodemanager.resource.memory-mb
值: 12G
3、容器虚拟 CPU 内核
每台nodemanager节点提供给yarn进行调度管理的CPU核数大小,就是分配多少CPU去让yarn进行管理
这个需要根据每台服务器的内存来确定,拿 三台服务器每台8核16G内存举例,每台机器可以给yarn分配8核,但不建议全给,一般配置4-6核即可(前面已经讲到 参数可以控制整体cpu的使用 yarn.nodemanager.resource.percentage-physical-cpu-limit)。但有时候在运行yarn任务时会出现计算很慢问题。注意这里是虚拟内核,因为yarn不会去检测服务器的内核数量,所以针对这种情况,就可以将数量增加1到2倍来提高运算效率。比如配置为32
(还有一说法:目前推荐将该值设值为与物理CPU核数数目相同。如果你的节点CPU核数不够8个,则需要调减小这个值,而YARN不会智能的探测节点的物理CPU总数。)
参数名:yarn.nodemanager.resource.cpu-vcores
值: 32
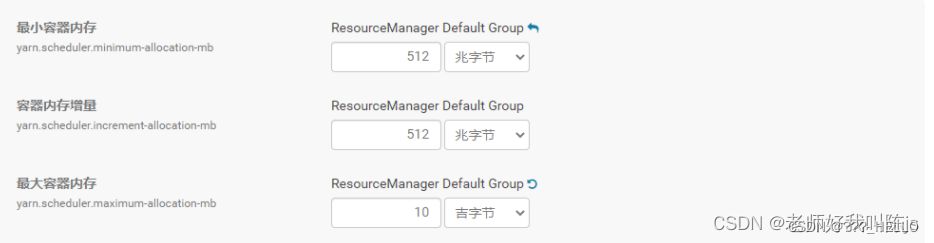
4、最小容器内存
就是分配给每个Container(容器)的最小执行内存。每创建一个容器就默认占用这么多内存资源,默认512MB即可
参数名:yarn.scheduler.minimum-allocation-mb
值: 512mb
5、容器内存增量
当创建一个容器后,默认创建的容器资源无法支持任务去运行,就需要增加内存资源,就需要配置每次增加内存资源的大小。配置512MB即可,但如果在yarn上提交的每个任务所涉及的数据或计算都很多,则可以相应调整为1G,2G等
参数名:yarn.scheduler.increment-allocation-mb
值:512mb
6、最大容器内存
就是一个容器所最大支持的内存容量,如果某个任务涉及的数据非常的大,若配置的最大容器内存过小,则会导致任务失败。
一般配置为 <=容器虚拟 CPU 内核,但不能超过容器内存yarn.nodemanager.resource.memory-mb
参数名:yarn.scheduler.maximum-allocation-mb
值:10G
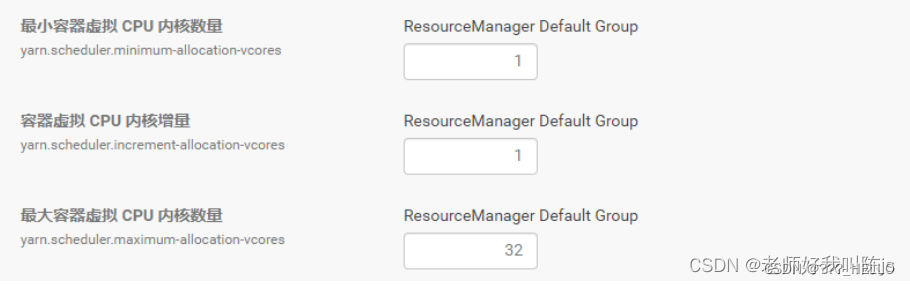
7、最小容器虚拟 CPU 内核数量
与最小内存同理,一个容器涉及的最小计算量的cpu数
参数名:yarn.scheduler.minimum-allocation-vcores
值: 1
8、容器虚拟 CPU 内核增量
与容器内存增量同理,一个容器每次增加的cpu数
参数名:yarn.scheduler.increment-allocation-vcores
值 :1
9、最大容器虚拟 CPU 内核数量
与容器最大内存同理,一个容器容纳的最大CPU数,代表它最大的计算能力,同样不能超过之前配置的容器虚拟 CPU 内核, yarn.nodemanager.resource.cpu-vcores
参数名:yarn.scheduler.maximum-allocation-vcores
值:32
部分内容转载于
原文链接:
————————————————
版权声明:本文为CSDN博主「老师好我叫陈js」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/chenjunshi123/article/details/122456706















 1125
1125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









