







pandas 简介
numpy 能够帮我们处理的是 数值型数据,但是这还不够,很多时候,我们的数据除了数值之外,还有字符串,还有时间序列等,
这是就需要 pandas 帮我们处理它们了。
什么是Pandas?
Pandas的名称来自于面板数据(panel data)
Pandas是一个强大的分析结构化数据的工具集,基于NumPy构建,提供了高级数据结构和数据操作工具,它是使Python成为强大而高效的数据分析环境的重要因素之一。
。一个强大的分析和操作大型结构化数据集所需的工具集
。基础是NumPy,提供了高性能矩阵的运算
。提供了大量能够快速便捷地处理数据的函数和方法
。应用于数据挖掘,数据分析
。提供数据清洗功能
pandas 的数据结构
pandas 库有两个重要的数据结构:
- Series 系列 [ˈsɪəriːz]
- DataFrame Frame [freɪm] 框架
我们可以将 Series 看作显示了索引的一维数组,将 DataFrame 看作显示了纵横轴索引的二维数组,因此 numpy 的许多方法与函数可以用在 Series 与 DataFrame 上。
Series对象
我们首先来了解 Series ,因为 Pandas 是基于NumPy构建的,所以我们可以参考 一维数组 对象来理解 Series对象。
import numpy as np
import pandas as pd
list_1=list(range(1,6))
arr=np.array(list_1)
ser=pd.Series(list_1)
print(f'这是由 1 到 5 构成的一维数组,只有数据元素:\n{
arr}')
print(f'这是由 1 到 5 构成的Series对象,由数据元素及其索引:\n{
ser}')

由此我们可以更好的理解 Ndarray 对象和 Series 对象,
- 数据类型不同:两者都是一系列同类型数据的集合,不同之处在于 Ndarray 对象只能存储数值型数据,而一个Series 对象中可以同时包含数值型数据;字符串和python 对象等等;
- 两者的索引都是由 0 开始的,不同之处在于 Series 对象的索引可以重新指定,而 Ndarray 对象的索引不能变更;且 Series 对象的索引会在内容中显示出来,而Ndarray 对象的索引不会在内容中显示出来。
Series 对象的创建:
pandas. Series ( data , index , dtype , name , copy )
- data:只要是数据都可以,当data的类型为字典时,键为索引,值作内容。
- index:默认从零开始,当指定索引时,索引的个数要等于数据元素的个数。
- dtype:元素的数据类型,默认会自己判断
- name:设置索引和元素值的名称
Series . name=str 设置元素值的名称
Series . index.name=str 设置索引的名称 - copy:拷贝数据,默认为 False
import numpy as np
import pandas as pd
data={
'name':'张三','age':20,'class':'三班'}
ser=pd.Series(data)
print(ser)
print('利用 Series 对象的属性,index和values访问其索引值与元素值:')
print(ser.index)
print(ser.values)

DataFrame 对象
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。可以参考 excel 表格

DataFrame 构造方法如下:
pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
- data:一组数据(ndarray、series, map, lists, dict 等类型)。
- index:索引值,或者可以称为行标签,默认为 RangeIndex (0, 1, 2, …, n) 。
- columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
- dtype:数据类型。
- copy:拷贝数据,默认为 False。
Pandas DataFrame 是一个二维的数组结构,类似二维数组。
DataFrame 的构建
data 为字典类型:
键作索引,值作内容。
- 由数组,列表或元组构成的字典;
import numpy as np
import pandas as pd
data={
'a':[1,2,3,4],
'b':(4,5,6,7),
'c':np.arange(9,13)}
frame=pd.DataFrame(data)
print(f'DataFrame对象:\n{
frame}')
string='''通过属性 index 查看对象的行索引;
columns查看对象列索引;
values查看对象的值。'''
print(string)
print(f'行索引:{
frame.index}')
print(f'列索引:{
frame.columns}')
print(f'元素值:\n{
frame.values}')
print('指定索引:')
frame=pd.DataFrame(data,index=['A','B','C','D'],columns=['a','b','c','d'])
print(frame)

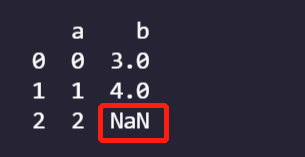
2. 由 Series对象构成的字典;
import numpy as np
import pandas as pd
data={
'a':pd.Series(np.arange(3)),
'b':pd.Series(np.arange(3,5))
}
frame=pd.DataFrame(data)
print(frame)
- 由字典构成的字典;
import numpy as np
import pandas as pd
data={
'a':{
'apple':3.6,'banana':5.6},
'b':{
'apple':3,'banana':5},
'c':{
'apple':3.6}
}
frame=pd.DataFrame(data)
print(frame)

data 为列表类型:
- data为二维数组时;
- 由 Series对象构成的列表;
- 由字典构成的列表;
import numpy as np
import pandas as pd
arr=np.arange(12).reshape(4,3)
frame_arr=pd.DataFrame(arr)
print('data为二维数组时;')
print(frame_arr)
list_dic=[{
'apple':3.6,'banana':5.6},{
'apple':3,'banana':5 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 255
255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











