







前言,最后一个样例也就是实验指导书的样例,的截图显示最佳适应算法存在bug,相邻分区没有进行合并,这个bug已经修复。
实验七 动态分区分配方式的模拟
一、实验目的
- 了解动态分区分配方式中使用的数据结构和分配算法,并进一步加深对动态分区存储管理方式及其实现过程的理解。
二、实验环境
-
硬件环境:计算机一台,局域网环境;
-
软件环境: Windows或Linux操作系统, C语言编程环境。
三、实验内容
-
用C语言分别实现采用首次适应算法和最佳适应算法的动态分区分配过程alloc( )和回收过程free( )。其中,空闲分区通过空闲分区链来管理:在进行内存分配时,系统优先使用空闲区低端的空间。
-
假设初始状态下,可用的内存空间为640KB,并有下列的请求序列:
- 作业1申请130KB。
- 作业2申请60KB。
- 作业3申请100KB。
- 作业2释放60KB。
- 作业4申请200KB。
- 作业3释放100KB。
- 作业1释放130KB。
- 作业5申请140KB。
- 作业6申请60KB。
- 作业7申请50KB。
- 作业6释放60KB。
请分别采用首次适应算法和最佳适应算法,对内存块进行分配和回收,要求每次分配和回收后显示出空闲分区链的情况。
/*
* @Description:
* @version:
* @Author:
* @Date: 2021-05-27 09:11:39
* @LastEditors: Please set LastEditors
* @LastEditTime: 2021-05-28 15:13:05
*/
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdbool.h>
#include <stdlib.h>
struct Jobs
{
int jobID;
int addr_start;
int addr_end;
struct Jobs *next;
};
struct Unoccupied_block
{
struct Unoccupied_block *previous;
int addr_start;
int addr_end;
struct Unoccupied_block *next;
};
struct Blocking_queue
{
int jobID;
int space;
struct Blocking_queue *next;
};
struct Jobs *jobhead;
struct Blocking_queue *bqhead;
struct Unoccupied_block *ubhead;
bool empty()
{
// 判断阻塞队列是否为空
if (bqhead->next == NULL)
return true;
return false;
}
// 按照空闲分区的大小从小到大排序
void sort()
{
// 冒泡排序
struct Unoccupied_block *t = ubhead->next;
int length = 0;
// 获得长度
while (t)
{
length++;
t = t->next;
}
t = ubhead->next;
// 冒泡排序的变形算法
for (int i = 0; i < length - 1; i++)
{
for (int j = 0; j < length - i - 1; j++)
{
struct Unoccupied_block *a, *b, *temp;
temp = (struct Unoccupied_block *)malloc(sizeof(struct Unoccupied_block));
int count = j;
while (count--)
{
t = t->next;
}
a = t;
b = t->next;
if (a->addr_end - a->addr_start > b->addr_end - b->addr_start)
{
temp->addr_start = a->addr_start;
temp->addr_end = a->addr_end;
a->addr_start = b->addr_start;
a->addr_end = b->addr_end;
b->addr_start = temp->addr_start;
b->addr_end = temp->addr_end;
}
t = ubhead->next;
}
}
}
// 按照开始位置排序
void sort2()
{
// 冒泡排序
struct Unoccupied_block *t = ubhead->next;
int length = 0;
// 获得长度
while (t)
{
length++;
t = t->next;
}
t = ubhead->next;
// 冒泡排序的变形算法
for (int i = 0; i < length - 1; i++)
{
for (int j = 0; j < length - i - 1; j++)
{
struct Unoccupied_block *a, *b, *temp;
temp = (struct Unoccupied_block *)malloc(sizeof(struct Unoccupied_block));
int count = j;
while (count--)
{
t = t->next;
}
a = t;
b = t->next;
if (a->addr_start > b->addr_start)
{
temp->addr_start = a->addr_start;
temp->addr_end = a->addr_end;
a->addr_start = b->addr_start;
a->addr_end = b->addr_end;
b->addr_start = temp->addr_start;
b->addr_end = temp->addr_end;
}
t = ubhead->next;
}
}
}
void Output()
{
struct Unoccupied_block *t = ubhead->next;
int count = 0;
printf("------------------------------------\n");
printf("当前的空闲分区链为:\n");
while (t)
{
count++;
printf("%d %d %d\n", count, t->addr_start, t->addr_end);
t = t->next;
}
printf("------------------------------------\n\n");
}
void InsertJob(struct Jobs newJob)
{
// 找到作业队列队尾,插入信息
// !注意需要分配空间,不能直接使用&newJob,因为它是局部变量,跳出该作用域后自动销毁,直接使用导致不可预料的结果
struct Jobs *t1 = jobhead;
while (t1->next)
t1 = t1->next;
struct Jobs *t = (struct Jobs *)malloc(sizeof(struct Jobs));
t->jobID = newJob.jobID;
t->addr_start = newJob.addr_start;
t->addr_end = newJob.addr_end;
t->next = NULL;
t1->next = t;
}
void InsertBQ(struct Blocking_queue newJob)
{
// 找到阻塞队列队尾,插入作业信息
struct Blocking_queue *t = bqhead;
while (t->next)
t = t->next;
struct Blocking_queue *t2 = (struct Blocking_queue *)malloc(sizeof(struct Blocking_queue));
t2->jobID = newJob.jobID;
t2->space = newJob.space;
t2->next = NULL;
t->next = t2;
}
void DeleteJob(int id, int *start, int *end)
{
// 删除作业链表中的项
struct Jobs *t = jobhead;
while (t->next)
{
if (t->next->jobID == id)
break;
t = t->next;
}
// 保存删除作业的信息
*start = t->next->addr_start;
*end = t->next->addr_end;
t->next = t->next->next;
printf("回收成功\n");
printf("作业信息为:ID: %d Space: %d\n", id, *end - *start);
}
struct Blocking_queue *DeleteBQ(int id)
{
// 删除阻塞队列中指定作业号的项,并且返回删除那一项后面的结点
struct Blocking_queue *t = bqhead;
while (t->next)
{
if (t->next->jobID == id)
break;
t = t->next;
}
t->next = t->next->next;
return t->next;
}
bool Arrange(int newJobID, int newJobSpace, bool blockFlag)
{
// 得到三个队列的第一个有效结点
struct Unoccupied_block *head1 = ubhead->next;
struct Jobs *head2 = jobhead->next;
struct Blocking_queue *head3 = bqhead->next;
// 标记是否分配到空间
bool flag = false;
while (head1)
{
// 这个分区大于要求的大小,则取下一部分分配,此时只需修改链表即可
if (head1->addr_end - head1->addr_start > newJobSpace)
{
printf("分配成功\n");
printf("作业信息为:ID: %d Space: %d\n", newJobID, newJobSpace);
struct Jobs newjob;
newjob.addr_start = head1->addr_start;
newjob.addr_end = newjob.addr_start + newJobSpace;
newjob.jobID = newJobID;
newjob.next = NULL;
InsertJob(newjob);
head1->addr_start += newJobSpace;
flag = true;
break;
}
// 若等于,就需要删除这个空闲分区表项
else if (head1->addr_end - head1->addr_start == newJobSpace)
{
printf("分配成功\n");
printf("作业信息为:ID: %d Space: %d\n", newJobID, newJobSpace);
struct Jobs newjob;
newjob.addr_start = head1->addr_start;
newjob.addr_end = head1->addr_end;
newjob.jobID = newJobID;
newjob.next = NULL;
InsertJob(newjob);
head1->previous->next = head1->next;
flag = true;
break;
}
// 否则,寻找下一项
else
head1 = head1->next;
}
if (!flag)
{
printf("分配失败\n");
printf("作业信息为:ID: %d Space: %d\n", newJobID, newJobSpace);
struct Blocking_queue newJob;
newJob.jobID = newJobID;
newJob.space = newJobSpace;
newJob.next = NULL;
// 若处理的本来就是阻塞队列中的作业,且还没有分配成功,就不需要再次进入阻塞队列
if (!blockFlag)
InsertBQ(newJob);
return false;
}
return true;
}
void Free(int newJobID)
{
// 找到三个链表的有效结点
struct Unoccupied_block *head1 = ubhead->next;
struct Jobs *head2 = jobhead->next;
struct Blocking_queue *head3 = bqhead->next;
// 删除指定作业,并从作业链表中得到作业的信息
int jobAddrStart, jobAddrEnd;
DeleteJob(newJobID, &jobAddrStart, &jobAddrEnd);
// 先按照开始位置排序一遍,这样就允许两个算法共用一个回收函数了
sort2();
struct Unoccupied_block *indexInsert = ubhead;
// 寻找插入位置
while (indexInsert)
{
if (head1 == NULL || head1->addr_start >= jobAddrEnd)
{
// 如果删除的作业的结束位置在第一个表项之前,或无表项,那么就要在头结点后插入,直接赋值结束查找
indexInsert = ubhead;
break;
}
else if (indexInsert->addr_end <= jobAddrStart && (indexInsert->next == NULL || indexInsert->next->addr_start >= jobAddrEnd))
break;
else
indexInsert = indexInsert->next;
}
// 前后无邻接,且是个空表
if (indexInsert->next == NULL)
{
struct Unoccupied_block *newItem = (struct Unoccupied_block *)malloc(sizeof(struct Unoccupied_block));
newItem->addr_start = jobAddrStart;
newItem->addr_end = jobAddrEnd;
indexInsert->next = newItem;
newItem->previous = indexInsert;
newItem->next = NULL;
return;
}
// 前后无邻接的情况,直接插入表项
if (indexInsert->addr_end < jobAddrStart && indexInsert->next->addr_start > jobAddrEnd)
{
struct Unoccupied_block *newItem = (struct Unoccupied_block *)malloc(sizeof(struct Unoccupied_block));
newItem->addr_start = jobAddrStart;
newItem->addr_end = jobAddrEnd;
indexInsert->next->previous = newItem;
newItem->next = indexInsert->next;
newItem->previous = indexInsert;
indexInsert->next = newItem;
return;
}
// 前后都邻接
else if (indexInsert->addr_end == jobAddrStart && indexInsert->next->addr_start == jobAddrEnd)
{
indexInsert->addr_end = indexInsert->next->addr_end;
struct Unoccupied_block *t = indexInsert->next;
if (t->next == NULL)
{
indexInsert->next = NULL;
return;
}
t->next->previous = indexInsert;
indexInsert->next = t->next;
return;
}
// 前邻接,修改前面的一项,把它的结束位置修改为释放作业的结束位置
else if (indexInsert->addr_end == jobAddrStart)
{
indexInsert->addr_end = jobAddrEnd;
return;
}
// 后邻接,修改后面的一项,把它的开始位置修改为释放作业的开始位置
else if (indexInsert->next->addr_start == jobAddrEnd)
{
indexInsert->next->addr_start = jobAddrStart;
return;
}
}
void first_fit(bool altype)
{
// 读入文件中的数据,这里假设文件中的数据复合逻辑,比如说,不存在释放还在阻塞队列中作业等非法情况
FILE *fp;
printf("请输入文件名:\n");
char filename[20];
scanf("%s", filename);
if ((fp = fopen(filename, "r")) == NULL)
{
printf("打开文件错误\n");
return;
}
// 初始化三个链表,空闲分区,阻塞队列与已分配空间的作业
jobhead = (struct Jobs *)malloc(sizeof(struct Jobs));
jobhead->next = NULL;
bqhead = (struct Blocking_queue *)malloc(sizeof(struct Blocking_queue));
bqhead->next = NULL;
ubhead = (struct Unoccupied_block *)malloc(sizeof(struct Unoccupied_block));
struct Unoccupied_block *first = (struct Unoccupied_block *)malloc(sizeof(struct Unoccupied_block));
// 这里设置空闲分区表为双向链表
first->addr_start = 0;
first->addr_end = 640;
first->next = NULL;
first->previous = ubhead;
ubhead->next = first;
ubhead->previous = NULL;
ubhead->addr_start = -1;
ubhead->addr_end = -1;
while (!feof(fp))
{
struct Jobs newJob;
int id, type, space;
fscanf(fp, "%d %d %d", &id, &type, &space);
if (type == 1)
{
Arrange(id, space, false);
if (altype)
sort();
Output();
}
else if (type == 0)
{
Free(id);
if (altype)
sort();
// 如果阻塞队列中有未完成分配的作业,取出一项进行分配,直到处理完所有阻塞作业
if (!empty())
{
struct Blocking_queue *t = bqhead->next;
while (t)
{
printf("处理阻塞队列中的作业%d\n", t->jobID);
// 若阻塞队列中的一个作业分配成功,则从阻塞队列中取下这个作业
if (Arrange(t->jobID, t->space, true))
{
if (altype)
sort();
t = DeleteBQ(t->jobID);
continue;
}
t = t->next;
}
}
Output();
}
}
}
int main(void)
{
// 减少代码冗余,因为两个算法只是对内存进行分配回收后是否排序的问题,所以仅用一个函数,用一个标志位区分是否排序
printf("*******************************************************\n\n");
printf("首次适应算法:\n\n");
first_fit(false);
printf("*******************************************************\n\n");
printf("最佳适应算法:\n\n");
first_fit(true);
return 0;
}
/*
代码调试过程中用到的测试数据
验证前邻接:
1 1 130
2 1 60
3 1 20
1 0 130
2 0 60
验证后邻接:
1 1 130
2 1 60
3 1 20
2 0 60
1 0 130
验证前后都邻接:
1 1 130
2 1 60
3 1 20
1 0 130
3 0 20
2 0 60
验证存在阻塞作业的情况
1 1 130
2 1 640
3 1 40
4 1 10
1 0 130
4 0 10
3 0 40
2 0 640
验证多个阻塞作业的情况:
1 1 130
2 1 640
3 1 640
4 1 10
1 0 130
4 0 10
2 0 640
3 0 640
验证最佳适应:
1 1 50
2 1 40
3 1 30
4 1 20
5 1 10
1 0 50
3 0 30
5 0 10
6 1 5
7 1 35
验证两个算法共用一个回收函数可能导致的问题:
1 1 130
2 1 60
3 1 100
4 1 10
5 1 10
1 0 130
3 0 100
5 0 10
2 0 60
4 0 10
验证实验指导书的例子:
1 1 130
2 1 60
3 1 100
2 0 60
4 1 200
3 0 100
1 0 130
5 1 140
6 1 60
7 1 50
6 0 60
*/
- 验证回收内存时内存块前邻接:

该测试数据的两算法结果相同
- 验证后邻接:

该测试数据的两算法结果相同
-
验证前后都邻接:

该测试数据的两算法结果相同
-
验证存在阻塞作业的情况:
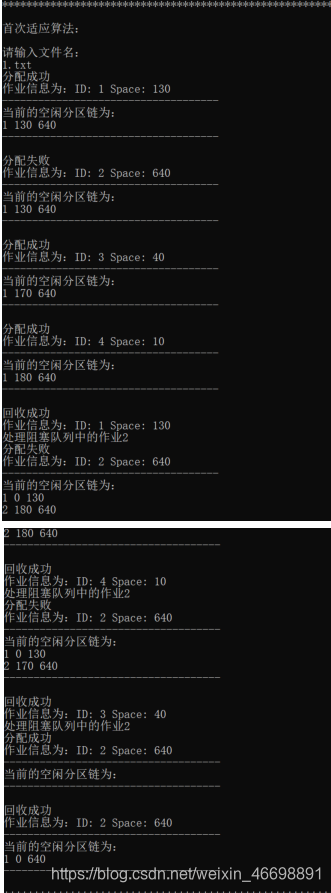
该测试数据的两算法结果相同
-
验证多个阻塞作业的情况:
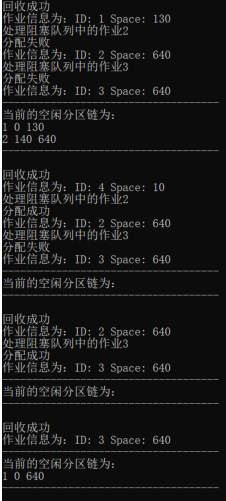
-
验证最佳适应:


-
验证实验指导书的例子:


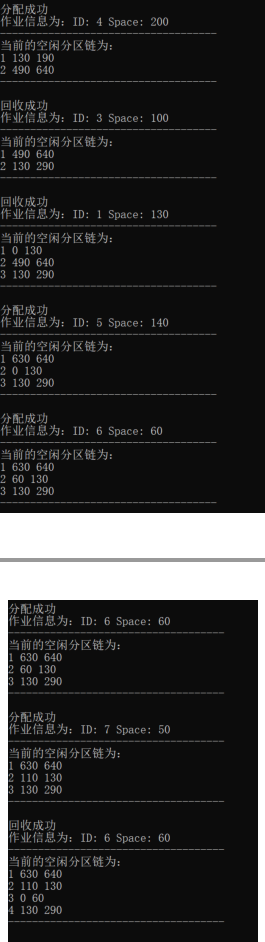
四、实验总结
- 结合实验情况,谈谈你对存储管理的理解和体会。
- 存储管理可以有效地对外部存储资源和内存进行管理,可以完成存储分配,存储共享,存储保护,存储扩充,地址映射等重要功能,对操作系统的性能有很重要的影响。首次适应算法和最佳适应算法是存储管理中两个十分重要的页面置换算法。
- 首次适应算法从空闲分区链首开始查找,直至找到一个能满足其大小要求的空闲分区为止。然后再按照作业的大小,从该分区中划出一块内存分配给请求者,余下的空闲分区仍留在空闲分区链中。该算法倾向于使用内存中低地址部分的空闲区,在高地址部分的空闲区很少被利用,从而保留了高地址部分的大空闲区,为以后到达的大作业分配大的内存空间创造了条件。但是低地址部分不断被划分,留下许多难以利用、很小的空闲区,而每次查找又都从低地址部分开始,会增加查找的开销。
- 最佳适应算法总是把既能满足要求,又是最小的空闲分区分配给作业。为了加速查找,该算法将所有的空闲区按大小排序后,以递增顺序形成一个空白链。这样每次找到的第一个满足要求的空闲区,必然是最优的。这样,每次分配给文件的都是最合适该文件大小的分区,但是内存中留下许多难以利用的小的空闲区。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











