







课程链接:
尚硅谷大数据Hadoop 3.x(入门搭建+安装调优)_哔哩哔哩_bilibili
(Hadoop到底是干什么用的? - 知乎 (zhihu.com)
资料
Hadoop就是存储海量数据和分析海量数据的工具。
第1章 Hadoop概述


1.1 Hadoop 是什么
(1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
(2)主要解决,海量数据的存储和海量数据的分析计算问题。
(3)广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
1.2 Hadoop 发展历史(了解)
1)Hadoop创始人Doug Cutting,为了实现与Google类似的全文搜索功能,他在Lucene框架基础上进行优 化升级,查询引擎和索引引擎。
2)2001年年底Lucene成为Apache基金会的一个子项目。
3)对于海量数据的场景,Lucene框架面对与Google同样的困难,存储海量数据困难,检索海量速度慢。
4)学习和模仿Google解决这些问题的办法 :微型版Nutch。
5)可以说Google是Hadoop的思想之源(Google在大数据方面的三篇论文)
GFS —>HDFS、Map-Reduce —>MR 、BigTable —>HBas
6)2003-2004年,Google公开了部分GFS和MapReduce思想的细节,以此为基础Doug Cutting等人用了2年业余时间实现了 DFS和MapReduce机制,使Nutch性能飙升。
7)2005 年Hadoop 作为 Lucene的子项目 Nutch的一部分正式引入Apache基金会。
8)2006 年 3 月份,Map-Reduce和Nutch Distributed File System (NDFS)分别被纳入到 Hadoop 项目 中,Hadoop就此正式诞生,标志着大数据时代来临。
9)名字来源于Doug Cutting儿子的玩具大

1.3 Hadoop 三大发行版本(了解)
Hadoop 三大发行版本:Apache、Cloudera、Hortonworks。
Apache 版本最原始(最基础)的版本,对于入门学习最好。
2006 Cloudera 内部集成了很多大数据框架,对应产品 CDH。2008 Hortonworks 文档较好,对应产品 HDP。
2011 Hortonworks 现在已经被 Cloudera 公司收购,推出新的品牌 CDP。
1.4 Hadoop 优势(4 高)
1)高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元 素或存储出现故障,也不会导致数据的丢失。

2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。

3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处 理速度。

4)高容错性:能够自动将失败的任务重新分配。

1.5 Hadoop 组成(面试重点)
Hadoop1.x、2.x、3.x区别
在 Hadoop1.x 时 代 , Hadoop中的MapReduce同时处理业务逻辑运算和资源的调度,耦合性较大。
在Hadoop2.x时代,增加了Yarn。Yarn只负责资源的调度 , MapReduce 只负责运算。
Hadoop3.x在组成上没有变化。

1.5.1 HDFS 架构概述
HDFS(Hadoop Distributed File System) ,是一个分布式文件系统。作用:数据存储。
(1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、 文件权限),以及每个文件的块列表和块所在的DataNode等。(数据目录)
(2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。(存储具体数据)
(3)Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。

1.5.2 YARN 架构概述
YARN(Yet Another Resource Negotiator) 简称 ,另一种资源协调者,是 Hadoop 的资源管理器。
作用:资源管理(主要管理CPU和内存)、资源调度。
(1)ResourceManager(RM):整个集群资源(内存、CPU等)的老大
(3)ApplicationMaster(AM):单个任务运行的老大
(2)NodeManager(N M):单个节点服务器资源老大
(4)Container:容器,相当一台独立的服务器,里面封装了 任务运行所需要的资源,如内存、CPU、磁盘、网络等。

说明1:客户端可以有多个
说明2:集群上可以运行多个ApplicationMaster
说明3:每个NodeManager上可以有多个Containe
1.5.3 MapReduce 架构概述
负责计算
MapReduce 将计算过程分为两个阶段:Map 和 Reduce
(1)Map 阶段并行处理输入数据 (分发)
(2)Reduce 阶段对 Map 结果进行汇总 (聚集)

1.5.4 HDFS、YARN、MapReduce三者关系
HDFS负责数据存储、YARN负责资源调度、MapReduce负责计算

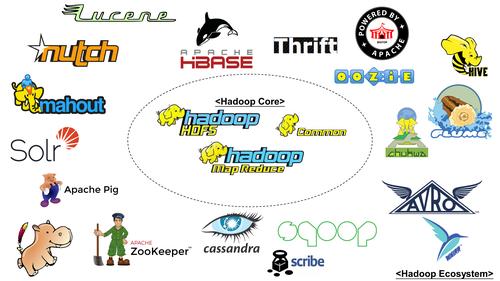
1.6 大数据技术生态体系

图中涉及的技术名词解释如下:
(1)Sqoop:Sqoop 是一款开源的工具,主要用于在 Hadoop、Hive 与传统的数据库(MySQL) 间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到关系型数据库中。
(2)Flume:Flume 是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统, Flume 支持在日志系统中定制各类数据发送方,用于收集数据;
(3)Kafka:Kafka 是一种高吞吐量的分布式发布订阅消息系统;
(4)Spark:Spark 是当前最流行的开源大数据内存计算框架。可以基于 Hadoop 上存储的大数 据进行计算。
(5)Flink:Flink 是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
(6)Oozie:Oozie 是一个管理 Hadoop 作业(job)的工作流程调度管理系统。
(7)Hbase:HBase 是一个分布式的、面向列的开源数据库。HBase 不同于一般的关系数据库, 它是一个适合于非结构化数据存储的数据库。
( 8)Hive:Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张 数据库表,并提供简单的 SQL 查询功能,可以将 SQL 语句转换为 MapReduce 任务进行运 行。其优点是学习成本低,可以通过类 SQL 语句快速实现简单的 MapReduce 统计,不必开 发专门的 MapReduce 应用,十分适合数据仓库的统计分析。
(9)ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、 名字服务、分布式同步、组服务等。
1.7 推荐系统框架图

第 2 章 Hadoop 运行环境搭建(开发重点)
2.1 模板虚拟机环境准备
1、安装模板虚拟机,IP 地址 192.168.10.100、主机名称 hadoop100、内存 2G、硬盘 50G
(建议jdk和hadoop都装好,克隆完就少改很多东西)
2、关闭防火墙,关闭防火墙开机自启
注意:在企业开发时,通常单个服务器的防火墙时关闭的。公司整体对外会设置非常安 全的防火墙
systemctl stop firewalld
systemctl disable firewalld.service
3、配置windows网络




4、修改克隆虚拟机的静态 IP
vim /etc/sysconfig/network-scripts/ifcfg-ens33
# 要修改或增加的内容
ONBOOT=yes
BOOTPROTO=static
IPADDR=192.168.10.102
PREFIX=24
GATEWAY=192.168.10.2
DNS1=192.168.10.2
5、设置主机名(相当定义了一个全局变量,不用一个一个的改ip)
vim /etc/hostname
# 或
sudo hostnamectl hadoop100
6、配置 Linux 克隆机主机和 windows 名称映射 hosts 文件,打开/etc/hosts
vim /etc/hosts
192.168.10.100 hadoop100
192.168.10.101 hadoop101
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
192.168.10.105 hadoop105
192.168.10.106 hadoop106
192.168.10.107 hadoop107
192.168.10.108 hadoop108
7、重启虚拟机,测试网络
- 虚拟机外网
ping www.baidu.com
8、配置普通用户具有root权限
vim /etc/sudoers
修改/etc/sudoers 文件,在%wheel 这行下面添加一行,如下所示:
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
## Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL
【普通用名称】 ALL=(ALL) NOPASSWD:AL
注意:atguigu 这一行不要直接放到 root 行下面,因为所有用户都属于 wheel 组,你先 配置了 atguigu 具有免密功能,但是程序执行到%wheel 行时,该功能又被覆盖回需要 密码。所以 atguigu 要放到%wheel 这行下面。
创建工作目录
[root@hadoop100 ~]$ mkdir /opt/module
[root@hadoop100 ~]$ mkdir /opt/software
2.2 安装工具
1、安装 epel-release(额外的软件包)
# 注:Extra Packages for Enterprise Linux 是为“红帽系”的操作系统提供额外的软件包,
# 适用于 RHEL、CentOS 和 Scientific Linux。相当于是一个软件仓库,大多数 rpm 包在官方repository 中是找不到的)
$ yum install -y epel-release
- 若yum出错
kill -9 【yum进程号】
2、卸载虚拟机自带的 JDK
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
# 检查是否卸载成功,无返回则成功
rpm -qa | grep -i java
➢ rpm -qa:查询所安装的所有 rpm 软件包
➢ grep -i:忽略大小写
➢ xargs -n1:表示每次只传递一个参数
➢ rpm -e –nodeps:强制卸载软件
# 重启虚拟机
reboot
3、安装 JDK
用 xftp传输工具将 JDK 导入到 opt 目录下面的 software 文件夹下面
2.3 克隆虚拟机并配置环境
2.3.1 克隆虚拟机
将虚拟机hadoop100 克隆出虚拟机hadoop102、hadoop103,并修改ip/etc/sysconfig/network-scripts/ifcfg-ens33 和 /etc/hostname 中的ip地址和主机名
2.3.2 虚拟机hadoop102 安装 JDK
1、用 Xftp 传输工具将 JDK 导入到 /opt/software 文件夹下,解压 JDK 到/opt/module 目录下
(直接拉入虚拟机的大文件不完整)
$ cd /opt/software
$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C
2、配置 JDK 环境变量
- 新建
/etc/profile.d/my_env.sh文件,添加如下内容
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
- source 一下/etc/profile 文件,让新的环境变量 PATH 生效
$ source /etc/profile
- 测试 JDK 是否安装成功
$ java -version
2.3.3 虚拟机hadoop102 安装 Hadoop
1、将 hadoop-3.1.3.tar.gz 导入到 /opt/software下
2、解压安装文件到/opt/module 下面
$ cd /opt/software
$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
3、将 Hadoop 添加到环境变量
- 修改
/etc/profile.d/my_env.sh文件 ,在 my_env.sh 文件末尾添加如下内容
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbi
- source 一下/etc/profile 文件,让新的环境变量 PATH 生效
$ source 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2918
2918











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









