






 本文详细介绍了Linux中常见的命令,包括文件管理(如ls、cd、mkdir、rm、cp、mv)、文本处理(如grep、find)、查看文件内容(如cat、more、less)、压缩解压(如tar)、进程管理(如ps、kill)以及系统性能监控(如topas)等,提供了丰富的实例和使用技巧。
本文详细介绍了Linux中常见的命令,包括文件管理(如ls、cd、mkdir、rm、cp、mv)、文本处理(如grep、find)、查看文件内容(如cat、more、less)、压缩解压(如tar)、进程管理(如ps、kill)以及系统性能监控(如topas)等,提供了丰富的实例和使用技巧。
Linux命令格式
command [-options] [parameter]
说明:
command :命令名,相应功能的英文单词或单词的缩写
-options :选项,可用来对命令进行控制,也可以省略
parameter:传给命令的参数,可以是 零个、一个或者多个
使用技巧
小技巧:
ctrl + shift + =放大终端窗口的字体显示ctrl + -缩小终端窗口的字体显示
自动补全
在敲出 文件 / 目录 / 命令 的前几个字母之后,按下 tab 键
- 如果输入的没有歧义,系统会自动补全
- 如果还存在其他 文件 / 目录 / 命令 ,再按一下 tab 键,系统会提示可能存在的命令
- 按
上 / 下光标键可以在曾经使用过的命令之间来回切换 - 如果想要退出选择,并且不想执行当前选中的命令,可以按
ctrl + c
常用的Linux命令
| 命令 | 作用 | 对应英文 |
|---|---|---|
| ls | 查看当前文件夹下的内容 | list |
| pwd | 查看当前所在目录 | print work directory |
| cd [目录名] | 切换文件夹 | change directory |
| mkdir [目录名(文件夹)] | 创建目录(文件夹) | make directory |
| rm [文件名] | 删除指定文件 | remove |
| cp [复制的文件名] [复制到的地址] | 复制文件或目录 | copy |
| touch [文件名] | 如果文件不存在,新建文件 | touch |
| mv 旧文件名 新文件名 | 文件重命名 | |
| clear | 清屏 | clear |
| date | 查看系统时间 | |
| topas | 查看系统性能 | |
cp 复制
示例
#把文件不改名复制到另一个目录
cp 文件 复制到的目录
#把文件复制到另一个目录,并且改名
cp 文件 复制到的目录/改之后的文件名
#把文件夹及其子文件不改名复制到另一个目录下
cp -r /要复制的文件夹/ /要复制到的目录下/
rm 删除
示例
#不带选项删除文件会提示确认
rm 文件名
#选项-i为默认选项,效果与无选项相同
rm -i 文件名
#强行删除普通文件
#选项-f删除普通文件时,不会提示确认
rm -f 文件名
#删除目录
#注意目录与普通文件的区别,删除目录必须带-r,否则会报错
#-r:递归删除,主要用于删除目录,可以删除指定目录及包含的所有内容,包含所有的子目录和文件
#删除文件夹
rm -rf 路径/目录名
tail
tail命令用于查看纯文本文档的后 N行或持续刷新内容,用于查看实时日志。
命令参数
命令格式
tail [参数] [文件]
参数
-f 循环读取
-q 不显示处理信息
-v 显示详细的处理信息
-c<数目> 显示的字节数
-n<行数> 显示文件的尾部 n 行内容
--pid=PID 与-f合用,表示在进程ID,PID死掉之后结束
-q, --quiet, --silent 从不输出给出文件名的首部
-s, --sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒
举例
#实时查看文件最新信息
tail -f 文件名
#查看文本内容的最后20行
tail -n 20 文件名
#显示文件信息从第20行到文件末尾
tail -n +20 文件名
#动态查看实时输出info.log日志
tail -f info.log
#查看info.log日志后200行
tail -n 200 info.log
#动态查看含有关键字orderId的日志
tail -f info.log | grep "orderId"
tar 压缩解压
-c: 建立压缩档案
-x:解压
-t:查看内容
-r:向压缩归档文件末尾追加文件
-u:更新原压缩包中的文件
这五个是独立的命令,压缩解压都要用到其中一个,可以和别的命令连用但只能用其中一个。下面的参数是根据需要在压缩或解压档案时可选的。
-z:有gzip属性的
-j:有bz2属性的
-Z:有compress属性的
-v:显示所有过程
-O:将文件解开到标准输出
举例
#这条命令是将所有.jpg的文件打成一个名为all.tar的包。-c是表示产生新的包,-f指定包的文件名。
tar -cf all.tar *.jpg
#这条命令是将所有.gif的文件增加到all.tar的包里面去。-r是表示增加文件的意思。
tar -rf all.tar *.gif
#这条命令是更新原来tar包all.tar中logo.gif文件,-u是表示更新文件的意思。
tar -uf all.tar logo.gif
#这条命令是列出all.tar包中所有文件,-t是列出文件的意思
tar -tf all.tar
#这条命令是解出all.tar包中所有文件,-x是解开的意思
tar -xf all.tar
压缩
#将目录里所有jpg文件打包成tar.jpg
tar –cvf jpg.tar *.jpg
#将目录里所有jpg文件打包成jpg.tar后,并且将其用gzip压缩,生成一个gzip压缩过的包,命名为jpg.tar.gz
tar –czf jpg.tar.gz *.jpg
#将目录里所有jpg文件打包成jpg.tar后,并且将其用bzip2压缩,生成一个bzip2压缩过的包,命名为jpg.tar.bz2
tar –cjf jpg.tar.bz2 *.jpg
#将目录里所有jpg文件打包成jpg.tar后,并且将其用compress压缩,生成一个umcompress压缩过的包,命名为jpg.tar.Z
tar –cZf jpg.tar.Z *.jpg
#rar格式的压缩,需要先下载rar for linux
rar a jpg.rar *.jpg
#zip格式的压缩,需要先下载zip for linux
zip jpg.zip *.jpg
解压
# 解压 tar包
tar –xvf file.tar
#解压tar.gz
tar -xzvf file.tar.gz
#解压 tar.bz2
tar -xjvf file.tar.bz2
#解压tar.Z
tar –xZvf file.tar.Z
#解压rar
unrar e file.rar
#解压zip
unzip file.zip 解压zip
chmod 改变权限
# 语法
chmod [选项] <权限模式> <文件或目录>
权限类型:
r(读4):查看文件内容 / 列出目录内容。
w(写2):修改文件 / 在目录中创建/删除文件。
x(执行1):运行文件(如脚本)/ 进入目录。
用户类型:
u:所有者(user)
g:所属组(group)
o:其他用户(others)
a:所有用户(all,即 u+g+o)
权限表示方式:
符号模式:如 rwxr-xr–
数字模式:如 755(每位数字是 r=4 + w=2 + x=1 的和)
示例
#数字模式
#所有者-所属组-其他用户
# 示例1:设置为 rwxr-xr-x(751)
chmod 755 file.sh
# 示例2:设置为 rw-r-----(640)
chmod 640 config.txt
#符号模式
# 示例1:给所有者添加执行权限
chmod u+x file.sh
# 示例2:移除组和其他用户的写权限
chmod g-w,o-w file.txt
# 示例3:设置所有者可读写执行,组和其他人只读
chmod u=rwx,go=r file.txt
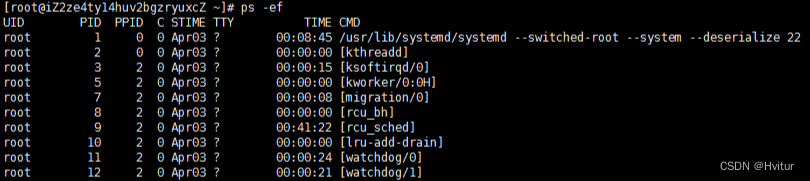
ps -ef 查看进程
命令:ps -ef | grep XX
查看包含“XX”的所有进程
命令详解:
ps命令将某个进程显示出来(是LINUX下最常用的也是非常强大的进程查看命令)
grep命令是查找(是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来,grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户)
中间的 | 是管道命令 是指ps命令与grep同时执行
ps -ef |grep 命令查询的各个数据代表的含义:
| UID | PID | PPID | C | STIME | TTY | TIME | CMD |
|---|---|---|---|---|---|---|---|
| 程序被该 UID 所拥有 | 就是这个程序的 ID | 则是其上级父程序的ID | CPU使用的资源百分比 | 系统启动时间 | 登入者的终端机位置 | 使用掉的CPU时间 | 所下达的是什么指令 |
kill 杀死进程
kill 命令会向操作系统内核发送一个信号(多是终止信号)和目标进程的 PID,然后系统内核根据收到的信号类型,对指定进程进行处理。
kill(选项)(参数)
-a:当处理当前进程时,不限制命令名和进程号的对应关系;
-l <信息编号>:若不加<信息编号>选项,则-l参数会列出全部的信息名称;
-p:指定kill 命令只打印相关进程的进程号,而不发送任何信号;
-s <信息名称或编号>:指定要送出的信息;
-u:指定用户。
只有第9种信号(SIGKILL)才可以无条件终止进程,其他信号进程都有权利忽略,下面是常用的信号
HUP 1 终端断线(平滑重启进程)
INT 2 中断(同 Ctrl + C)
QUIT 3 退出(同 Ctrl + \)
TERM 15 终止
KILL 9 强制终止
CONT 18 继续(与STOP相反, fg/bg命令)
STOP 19 暂停(同 Ctrl + Z)
示例:
##杀死进程
kill -9 <PID>
[root@itbkz.com ~]#ps -ef |grep chronyd
chrony 30365 1 0 19:58 ? 00:00:00 /usr/sbin/chronyd
root 30385 29218 0 19:58 pts/1 00:00:00 grep --color=auto chronyd
[root@itbkz.com ~]#kill -9 30483
[root@itbkz.com ~]#ps -ef |grep chronyd
root 30508 29218 0 20:00 pts/1 00:00:00 grep --color=auto chronyd
topas 查看系统性能
操作系统的最全面动态,而又查看方便的性能视图就是topas命令了,下面以topas输出为例,对AIX系统的性能监控做简要描述
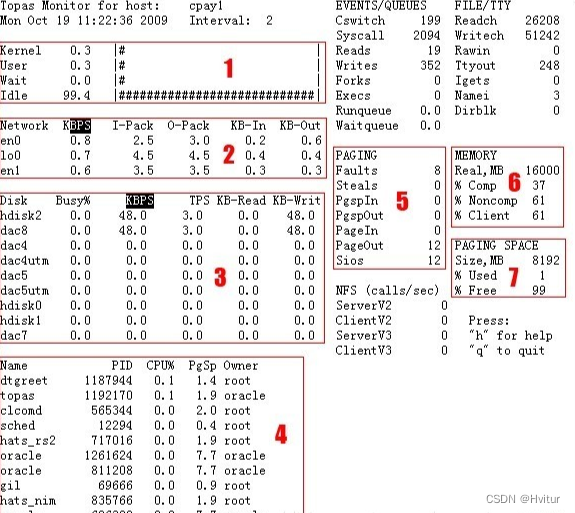
区域1:反映CPU使用率和工作状况

Kernel:
说明:操作系统的内核占用的CPU时间比率。
操作系统作为基础软件,为应用程序支持和服务的同时,本身的运行也需要一定的CPU和内存资源(顺便提到内存资源,后面不再阐述这个内容了),特别是内存资源,系统负载越重,相应的内核占用的CPU和内存资源也会越多。一般来说,内核占用的CPU时间不会太多的。一般小于应用的CPU使用率。
User:
说明:用户进程占用的CPU时间比率。
这个为CPU使用率的关键数值。该使用率反映了用户在操作系统基础上运行的各种软件占用的CPU时间比率的总和。一般来说,如果User+Kernel连续大于70%,即可以认为系统可能存在CPU上的严重性能问题。
Wait
说明:CPU处于等待状态占CPU时间的比率。
CPU的等待一般都为等待IO的响应,众所周知,目前计算机的主要瓶颈都在IO。应用程序执行的时候,需要读写磁盘等外部存储的数据,进程就会发起IO请求后等待IO完成。这个等待的过程占用CPU时间就是wait。当这个值很高的时候,就说明IO来不及响应很多的IO请求,这个时候,就只能从IO层面想办法优化了。
Idle:
说明:CPU空闲时间比率,这个就不用说了吧。就是CPU多少时间比率在闲着。
CPU占用率出问题的主要可能原因:数据库服务器执行某一个SQL或者存储过程(存储过程就是封装起来的sql程序包而已)需要大量的运算(一般为软件设计不合理)。或者应用程序中存在异常的地方,比如死循环,或者其他写程序时的逻辑错误导致。一般程序出错会导致一个CPU被全部占用,比如上述的20%占用的原因就是一个交易程序长期占用一个CPU全部时间片(系统共计5个CPU)。
区域2:反映网络使用率的状况。
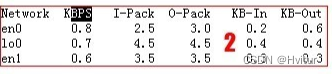
Netwok:
列出了网卡接口,KBPS即每秒钟多少KB(千字节) I-Pack每秒钟输入的数据包个数, O-Pack 每秒钟输出的数据包个数 KB-In每秒钟输入的字节数KB-Out每秒钟输出的字节数。
当我们发现网络拥堵时(出现网卡传输失效的报错,即网卡发送数据包失败。或者网络响应明显变慢的时候,如果CPU没有问题,那么请检查网络流量)发现某一个网卡的KBPS持续大于四位数,甚至五位数时(这个值要是网卡千兆还是百兆而定)。就要看看这个网卡是什么网卡,在处理什么业务了。在命令行执行netstat–in 查看对应en接口的ip地址,通过ip地址看看是带官网卡还是生产服务网卡流量高。然后通过netstat–v en 看看网卡的详细工作状态,出现了多少错包,冲突包,crc校验错或者网络重置过等信息。上述信息请详细看netstat–v en*的输出.如果出现大量crc,错包的话,可能网线有问题或者接触不良。
如果上述均正常,而网络反应慢,则有可能是交换机拥堵。
网络出现问题的可能原因:通过百兆的带管网加载大量数据,大量队列的长时间的ftp传输,或者网线,交换机问题等。
区域3:反映磁盘使用率的状况。
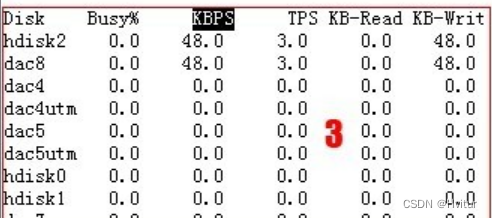
Disk Busy%磁盘繁忙的百分比,即磁盘能满足的最大IOPS(每秒IO操作数)和当前IO数量的比率。其他的参数不再解释。望文生义即可。
一般主要看磁盘的Busy%,当磁盘的Busy%持续大于85%时,即认为磁盘相当繁忙,已经可能要出问题了。当然,自己知道已经确定要产生大量IO操作的内容则不必在意,等其完成即可。
出现问题的原因:应用服务器上面写日志进程或者查询日志的进程大量读写日志,导致磁盘繁忙率高,或者其他程序频繁读写磁盘导致。系统中hdisk0,hdisk1一般为系统盘,内置SCSI磁盘的相对IOPS是较低的。很容易满负荷运行。
区域4:反映进程信息的状况。
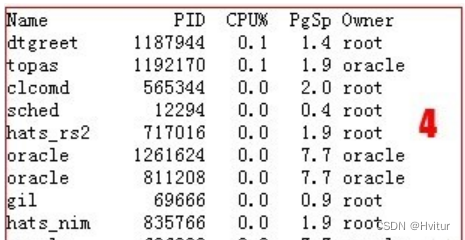
Name:进程的名称,即进程被执行时启动的二进制文件的名称。
PID:进程的ID,进程的ID在系统中唯一,是我们了解跟踪进程信息重要数值。
跟踪进程的CPU使用,磁盘IO读写,进程的内存和pagingspace占用等等均需要使用。
CPU%:进程占用CPU时间的比率。
PgSp:进程占用的pagingspace的空间大小。
Owner:进程的属主,即由哪个操作用户用户启动了这个进程。
在topas中,默认是列出占用cpu最高的前几个的进程信息供参考,如果前面第一区域的的CPU使用率持续高,就要看看这里是那个进程占用了大量的CPU资源,看看是哪个用户的进程,如果自己执行的,则杀掉或者找项目组解决即可。
区域5:反映内存页面和换页空间信息的状况。

换页空间即磁盘上的空间,在AIX操作系统中用来做内存空间使用。具体的理论就不再阐述了,详细信息请参阅操作系统内容。磁盘空间的速度当然相比内存,慢了不止10倍。所以,只是内存页面的一个暂时存放地,存放的还是那些长期不怎么用到的内存页面而已。如果paging大量出现,这时候就有麻烦了,说明:内存不够用了!
该区域主要关注PageIn,PageOut如果这两个数值均大于三位数,并且长期大于这个数值,在技术上叫做内存颠簸,即不停的把内存页面换到磁盘空间上,又从磁盘空间把内存页面读进来,系统的内存使用效率变的极差,系统响应性能也变慢了。
这个信息也可以用vmstat来看,pi和po列即与这里相对应。当然,如果只是有页面出,或者只有页面入,或者短时间的一些页面换入换出,则没有什么问题,关注一下即可。
区域6:反映内存使用的信息。

Real,MB:操作系统实际拥有的内存的总量,单位是MB。换算成G需要÷1024
%Comp,计算型内存占用比率,
%Noncomp非计算型内存占用的比率。
%Client也为非计算型内存,Noncomp包涵Client型内存,jfs文件系统使用的内存为noncomp,为了区分,jfs2和nfs使用的内存为Client。
Comp:计算型内存就是进程实际使用的内存,例如我们写程序的时候malloc内存,或者在排序中使用了堆栈,进程中变量数值都需要在内存中保存,这部分内存为计算型内存(阐述不全面,仅供参考)。而操作系统在进行文件读写,需要的io缓冲区,或者我们在写程序的时候,打开文件,读写文件,均在文件缓冲区进行。(裸设备例外,CCCC的数据库采用RAC,数据的存储全部使用裸设备,在数据库服务器上,数据文件的缓冲在oracle的sga区的databuffer中(这个区域系统认为是计算型内存),是不会占用非计算内存的。)
导致内存出问题的可能原因很多。主要有:进程使用了更多的内存,例如,CCCC数据库服务器大量的oracle连接使用了很多内存,或者数据库中执行的某一个sql脚本或者存储过程的执行需要大量的内存来完成其操作(特例库中出现过这个情形,一个存储过程的执行导致操作系统内存被耗尽,pg也随之耗尽,操作系统自动执行PGSP_KILL,把该进程给干掉了,我也是第一次知道aix系统还有这个功能,呵呵)。第二个主要的问题就是内存泄漏,内存泄漏最简单的来说,就是申请了内存空间,使用后不再使用了,但是也没有释放。我们写程序的时候malloc,却没有free。这就导致了严重的问题,随着程序的执行,可用物理内存越来越少,最后就挂了,只好定期重启应用来解决。
操作系统的内存换页机制导致了程序中不用的内存页面最后都跑到pg上面去了,换页空间会持续增长的。因应用导致系统问题就是这么产生的。
区域7反映的是换页空间的使用率。
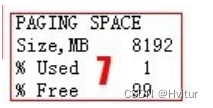
如果换页空间的使用率长期增长,就说明系统内存不足,已经开始使用磁盘空间来缓冲内存了,如果PG使用率持续增长,或者大于50%,需要警惕(到50%在监控平台已经是主要告警啦!),并马上提交系统管理员分析内存增长原因。如果该数值持续增长,系统一定会挂掉的!
搜索命令
搜索常用命令
| 命令 | 作用 |
|---|---|
| find [查找路径] -寻找条件 匹配方式 | 查找指定路径下匹配方式相同的文件,包括子目录 |
| grep 搜索文本 文件名 | 搜索文本文件内容 |
find 搜索文件
find 命令:通常用来在特定的目录下搜索符合条件的文件
| 命令 | 作用 |
|---|---|
| find [查找路径] -寻找条件 匹配方式 | 查找指定路径下匹配方式相同的文件,包括子目录 |
命令参数
寻找条件
-name:按照文件名查找文件
-a:and 必须满足两个条件才显示
-o:or 只要满足一个条件就显示
-iname:按照文件名查找文件(忽略大小写)
-type:根据文件类型进行搜索
-perm:按照文件权限来查找文件
-user 按照文件属主来查找文件。
-group 按照文件所属的组来查找文件。
-fprint 文件名:将匹配的文件输出到文件。
-newer file1 ! newer file2 查找更改时间比文件file1新但比文件file2旧的文件
匹配方式
-print 默认动作,将匹配的文件输出到标准输出
-exec 对匹配的文件执行该参数所给出的命令。相应命令的形式为 'command' { } \;,注意{ }和\;之间的空格。
-ok 和-exec的作用相同,只不过以一种更为安全的模式来执行该参数所给出的命令,在执行每一个命令之前,都会给出提示,让用户来确定是否执行。
-delete 将匹配到的文件删除
举例
#搜索当前目录下,文件名为.log,且内容中含有“变量”的文件
find . -name "*.log" | xargs grep -r "变量"
#搜索桌面目录下,文件名包含 1 的文件
find -name "*1*"
#搜索桌面目录下,所有以 .txt 为扩展名的文件
find -name "*.txt"
#搜索桌面目录下,以数字 1 开头的文件
find -name "1*"
#搜索路径下名字结尾为svr.out的文件
find /路径 "*svr.out"
#在当前路径的.tbl文件中,搜索内容含有“表名”的
find .-name ".tbl" |xargs grep -n 表名
grep 文本搜索
Linux 系统中 grep 命令是一种强大的文本搜索工具
grep 允许对文本文件进行 模式查找,所谓模式查找,又被称为正则表达式。可以把grep理解成字符查找工具。
grep是筛选的命令,在查看日志的时候,也可以对日志的内容进行筛选
它可以把我们需要筛选的关键词那一部分的行数显示出来。
命令参数
| 选项 | 含义 |
|---|---|
| -n | 显示匹配行及行号 |
| -v | 显示不包含匹配文本的所有行(相当于求反) |
| -i | 忽略大小写 |
| - -color | 高亮显示关键字 |
| -c | 只统计符合条件的总行数,而不会打印出行 |
| -B数字 | 显示符合条件的行之前对应数字的行,”B”有before之意 |
| -C | 在显示符合条件的行的同时,也会显示其前后的行,”-C”有Context之意(上下文之意) |
常用的两种模式查找
| 参数 | 含义 |
|---|---|
| ^a | 行首,搜寻以 a 开头的行 |
| ke$ | 行尾,搜寻以 ke 结束的行 |
-A 10 匹配行的前10行内容
-B 10 匹配行的后10行内容
-C 10 匹配行的环绕10行内容
'error' 关键词需要引号包裹
举例
#在.log类型的文件中搜索张三
grep 张三 *.log
#在.log类型的文件中搜索张三,忽略大小写
grep -i 张三 *.log
#在.log类型的文件中搜索张三,忽略大小写显示行号
grep -in 张三 *.log
#查询catalina.out中,包含error关键字前后10行的日志以less的方式显示出来
grep -Cn 10 'error' catalina.out | less
#查询关键字,高亮显示
#-C5表示显示该关键词所在的上下5列
grep 'request' -C5 app.log --color
#grep过滤屏蔽关键字
#比如我们日志类型是DEBUG级别,想要屏蔽DEBUG级别的日志,就可以使用下面的命令
tail -f app.log | grep -v 'DEBUG'
#查询多个条件,与条件
tail grep 'A' -f app.log | grep 'B'
#查询多个条件,或条件
tail -f grep -E 'A|B' app.log
目录命令
目录常用命令
| 命令 | 作用 |
|---|---|
| ls | 为列出目录的内容 |
| cd [目录名] | 用于切换工作路径 |
ls 查看目录
| 命令 | 作用 |
|---|---|
| ls | 为列出目录的内容 |
Linux 下文件和目录的特点
- 以 . 开头的文件为隐藏文件,需要用 -a 参数才能显示
- . 代表当前目录
- 双点. 代表上一级目录
命令参数
ls选项
|参数| 含义|
|–|:–|
| -a | 显示指定目录下所有子目录与文件,包括隐藏文件 |
|-l | 以列表方式显示文件的详细信息 |
| -h | 配合 -l 以人性化的方式显示文件大小 |
| -trl | 按照时间从远到近排序显示 |
ls通配符
| 通配符 | 含义 |
|---|---|
| * | 代表任意个数个字符 |
| ? | 代表任意一个字符,至少 1 个 |
| [] | 表示可以匹配字符组中的任一一个 |
| [abc] | 匹配 a、b、c 中的任意一个 |
| [a-f] | 匹配从 a 到 f 范围内的的任意一个字符 |
注意:以 . 开头的文件为隐藏文件,需要用 -a 参数才能显示
cd 切换目录
cd命令用于切换工作路径
命令参数
命令格式
cd [目录名]
参数
. 代表当前目录
.. 代表上一级目录
cd 切换目录
cd ~ 切换到当前用户的主目录(家目录~)
cd . 保持在当前目录不变
cd .. 切换到上级目录
cd - 可以在最近两次工作目录之间来回切换
查看文件内容
查看文件常用命令
| 命令 | 作用 |
|---|---|
| cat 文件名 | 查看文件内容、创建文件、文件合并、追加文件内容等功能 |
| more 文件名 | 分屏显示文件内容 |
| less [参数] 文件 | 分屏显示文件内容 |
cat
cat 命令可以用来 查看文件内容、创建文件、文件合并、追加文件内容等功能
cat 会一次显示所有的内容,适合查看内容较少的文本文件
命令参数
| 选项 | 含义 |
|---|---|
| -n | 显示文件行号 |
| -b | 显示行号,但是不把空白行计入行 |
| -s | 多行空白行只显示一行空白行 |
举例
查看info.log的全部日志内容
cat info.log
查看info.log的java关键字关联的全部内容
cat info.log | grep "java"
查看info.log的java关键字后5行关联的全部内容
cat info.log | grep -A 5 "java"
查看info.log的java关键字前10行关联的全部内容
cat info.log | grep -B 10 "java"
查看info.log的java关键字前后20行关联的全部内容
cat info.log | grep -C 20 "java"
more
more 命令可以用于分屏显示文件内容,每次只显示一页内容
适合于 查看内容较多的文本文件
命令参数
命令格式
more [选项] 文件
more 的操作键
| 操作键 | 功能 |
|---|---|
| 空格键 | 显示手册页的下一页 |
| b | 回滚一页 |
| Enter键 | 向下n行,需要定义。默认为1行 |
| Ctrl+F | 向下滚动一屏 |
| Ctrl+B | 返回上一屏 |
| f | 前滚一屏 |
| = | 输出当前行的行号(只输出当前一行的行号) |
| v | 调用vi编辑器 |
| q | 退出more |
| /word | 搜索 word 字符串 |
选项
| 选项 | 作用 |
|---|---|
| +n | 从文件的第n行开始查看 |
| -n | 每次翻页n行 |
| -v | 抑制非打印字符的图形翻译,more打开文件时出现^M乱码时使用 |
举例
#从text.log文件的2000行开始查看
more +2000 text.log
#每次翻页20行
more -20 text.log
#从text.log文件的里面的“变量”的前两行开始显示
more +/变量 text.log
#打开文件,抑制非打印字符的图形翻译,more打开文件时出现^M乱码时使用
more -v text.log
less
less命令是查看文档,跟more一样可以进行翻页,但是可以往前翻页。
应该说是linux正统查看文件内容的工具,功能极其强大。less 的用法比起 more 更加的有弹性。在 more 的时候,我们并没有办法向前面翻,在 less 里头可以拥有更多的搜索功能,不止可以向下搜,也可以向上搜
命令参数
命令格式
less [参数] 文件
参数:
-b <缓冲区大小> 设置缓冲区的大小
-e 当文件显示结束后,自动离开
-f 强迫打开特殊文件,例如外围设备代号、目录和二进制文件
-g 只标志最后搜索的关键词
-i 忽略搜索时的大小写
-m 显示类似more命令的百分比
-N 显示每行的行号
-o <文件名> 将less 输出的内容在指定文件中保存起来
-Q 不使用警告音
-s 显示连续空行为一行
-S 行过长时间将超出部分舍弃
-x <数字> 将“tab”键显示为规定的数字空格
/字符串:向下搜索“字符串”的功能
?字符串:向上搜索“字符串”的功能
n:重复前一个搜索(与 / 或 ? 有关)
N:反向重复前一个搜索(与 / 或 ? 有关)
z 向后翻一页
d 向后翻半页
b 向上翻一页
h 显示帮助界面
Q 退出less 命令
u 向前滚动半页
y 向前滚动一行
空格键 滚动一页
回车键 滚动一行
[pagedown]: 向下翻动一页
[pageup]: 向上翻动一页
标记导航
当使用 less 查看大文件时,可以在任何一个位置作标记,可以通过命令导航到标有特定标记的文本位置:
m - 标记一个锚点当前位置
' - 跳转到某个锚点.
比如:
ma - 标记当前位置为a
'a - 导航到标记 a 处
其他技巧
- 使用less的时候我们看的是固定的文档,如果我们希望像tail一样查看滚动的当前最新文档,我们可以在less命令的时候,使用大写的F,来查看滚动日志,
ctrl+c停止回到less - 可以按 v 进入编辑模型, shift+ZZ 保存退出到 less 查看模式
- 可以按 :e 查看下一个文件, 用 :n 和 :p 来回切换
- G - 移动到最后一行
- g - 移动到第一行
- q / ZZ - 退出 less 命令
举例
比如下面这个,就是忽略搜索时的大小写,显示百分比,显示行号,连续空行为一行的来显示log日志
less -imNs /opt/appl/spring-cloud/log/service.log
vi
如果文件已存在,会直接打开该文件;
如果文件不存在,会新建一个文件
备注说明:一般VIM是用来编辑文件的,所以不是查看日志的常用命令。但是VIM也是可以实现日志文件内容查看的。
命令参数
命令格式
vi 文件名
操作按键
| 按键 | 作用 |
|---|---|
| n | 下一个搜索出来的word字符串 |
| shift+n | 前一个搜索出来的word字符串 |
| i | 进入编辑模式,左下角显示INSERT |
| ESC | 退出编辑模式,之后使用退出命令退出vi编辑器 |
| gg | 移动到文件顶部第一行 |
| G | 移动到文件底部最后一行 |
| dd | 删除整行 |
| D | 从当前光标删除至行尾 |
| d^ | 从当前光标删除至行首 |
| dG | 从当前光标删除至文件末尾 |
| dIG | 从当前光标删除至文件顶部 |
| ndd | 删除n行,比如删除10行就是10dd |
| yy | 复制行 |
底线命令模式
| 命令 | 作用 |
|---|---|
| /word | 搜索word字符串 |
| ?word | 向前搜索word字符串 |
| :$ | 跳转到最后一行 |
| :w | 保存 |
| :w 文件名 | 另存为 |
| :q | 退出。如未保存,会提示未保存。 |
| :q! | 强行退出,不保存退出(常用) |
| :wq | 保存并退出 |
| :x | 保存并退出 |
| :wq! | 强制保存修改的内容然后退出(修改了只读文件会用到) |
| :set nu | 显示行号 |
| :n | 重复上一次查询 |




















 3731
3731

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











