







1.政采上没有我这个品牌怎么上传啊?
提供 京东/苏宁/其他政府采购网链接,加入品牌库。厂商提供商标注册证、品目名称、公司名称发给王清华老师 然后@群里的王清华老师,让王老师给加上
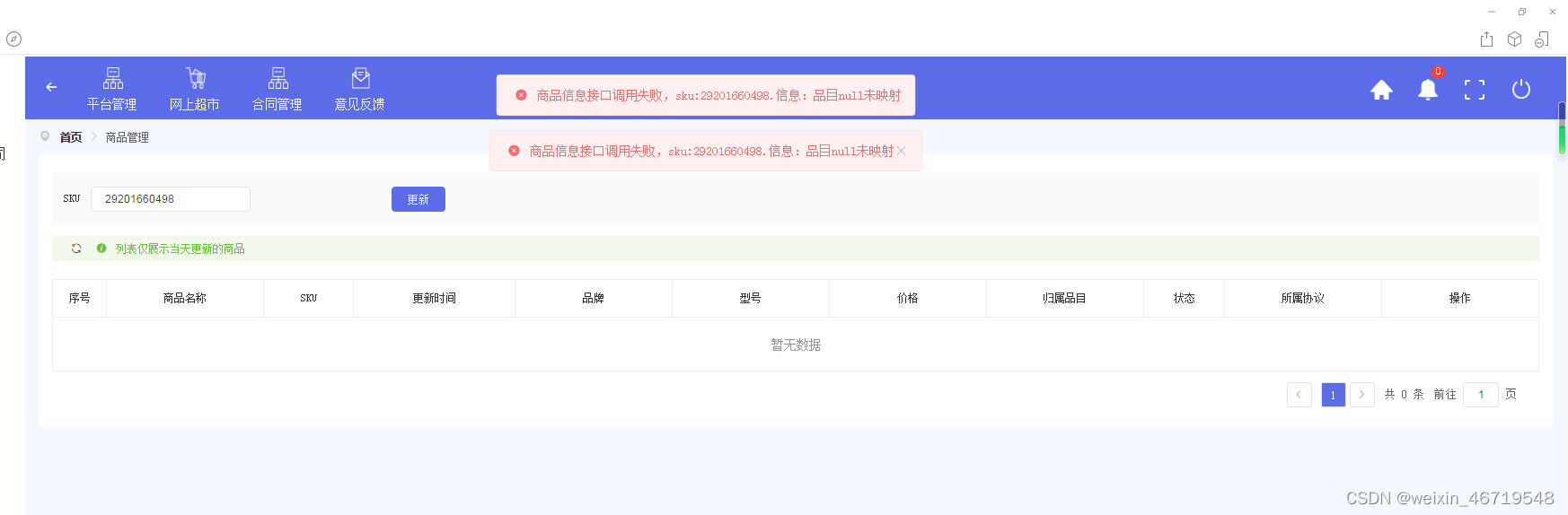
2.品目未映射
上传商品的品目没写对,未和政采对应上
3.上下架记录:电商自动下架
未维护参数.检查品牌型号
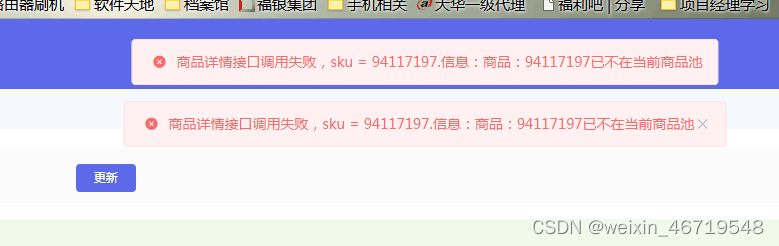
商品还没有同步到供应商网络那边,更没有到商城,等等
查接口,看日志
5.商品名称必须包含品牌及型号信息
6.定点家具只能产商申请
7.添加型号需要将商品来源发给王老师
8.品牌没传过去,需要重新在我们商城添加一遍商品
9.节能证书查询https://www.cqc.com.cn/www/chinese/zscx/
http://www.ccgp.gov.cn/search/jnqdchaxun.htm
10.集采类目需要维护参数
11.未检测到合理价 1 产品型号填写的不对 2这个商品云采确实没有收录
12.超市电商后台看到都上架了,店铺里是看不到商品的,有个品牌筛选,选择品牌就看到了大概2-3小时缓存
13.下架原因:优惠价大于通用资源配置,自动下架。
可以再该品目里的商品详情页查看限额
采集问题:
1.正常采
2.部分公务卡商品,商品分类不同(为省里的分类)。没法用采集

3.部分分类没有分类id.没法用采集
本文来源:http://awupp.top/qiluyuncai/113.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









