









创建数据库
在存储数据之前,我们需要先创建数据库,创建数据库使用
create database 数据库名称;

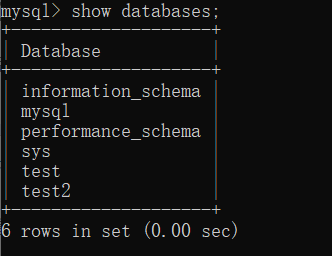
查看数据库
创建完数据库,我们可以使用
show databases;
来查看所有数据库。
使用数据库
要创建表前,我们需要先使用数据库,使用数据库使用
use 数据库名称;

删除数据库
在发现数据库没有价值的时候,我们可以使用
drop database 数据库名称;
删除数据库。(慎用)

创建数据表
创建数据表使用
create table 表名(
字段名1 数据类型 [约束条件:主键/自增/非空/唯一/默认值],
字段名1 数据类型 [约束条件:主键/自增/非空/唯一/默认值],
[约束条件:主键/外键]
);
约束条件
SQL中有6种约束条件,分别为主键,外键,自增,非空,唯一,默认值
主键 PRIMARY KEY
PRIMARY KEY 约束唯一标识数据库表中的每条记录,主键中必须包含唯一的值,而且包含 NULL 值,每个表都应该有一个主键,且每个表只能有一个主键。主键可以在创建字段时候直接在字段后直接定义,也可以在所有字段的最后定义.例如我们要创建班级表,其中id为主键:
creat table classes(
cid int primary key,
cname varchar(10),
);
creat table classes(
cid int,
cname varchar(10),
primary key(id)
);
外键 FOREIGN KEY
FORREIGN KEY用于将多个表关联在一起,一个表中的 FOREIGN KEY 指向另一个表中的 PRIMARY KEY。例如我们创建学生表,其中的班级id之间与班级表中的班级关联.
create table students(
sid int primary key,
sname varchar(10),
cid int,
foreign key(cid) references classes(cid)
);
自增AUTO_INCREMENT
AUTO_INCREMENT会在新记录插入表中时自动生成一个在上条记录的基础上增加1的记录。
creat table classes(
cid int auto_increment,
cname varchar(10),
primary key(id)
);
非空 NOT NULL
NOT NULL 限制该字段不能为null ,否则就会报错.
creat table classes(
cid int not null,
cname varchar(10),
primary key(id)
);
唯一 UNIQUE
UNIQUE限制该字段不能出现重复值,包括null,否则就会报错.
creat table classes(
cid int,
cname varchar(10) unique,
primary key(id)
);
默认值 DEFAULT
DEFAULT在插入记录,该字段为null时,自动添加一个默认值.
creat table classes(
cid int,
cname varchar(10) default '无名氏',
primary key(id)
);
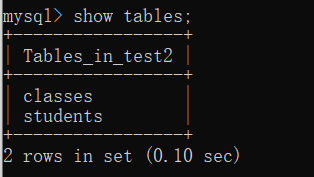
展示表格
想要查看所有表格,可以使用
show tables;
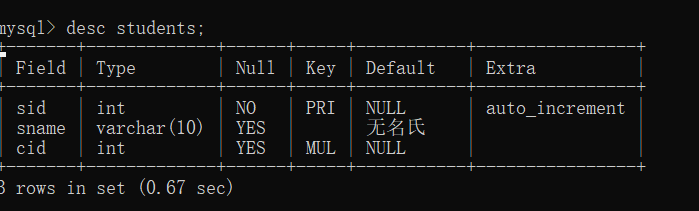
查看表格字段数据类型
查看表格字段数据类型可以使用
desc 表名;
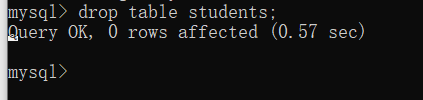
删除表格
删除表格可以使用
drop table 表名;
修改表格名称
修改表格名称可以使用
alter table 表名 rename 新表名;

修改字段名
修改字段名称使用
alter table 表名 change 字段名 新字段名 数据类型 [约束条件:自增/非空/默认值][位置first/after]

修改字段类型
修改字段类型使用
alter table 表名 modify 字段名 数据类型 [约束条件:自增/非空/默认值][位置first/after]

增加字段
alter table 表名 add 字段名 数据类型 [约束条件:自增/非空/默认值][位置first/after]

删除字段
alter table 表名 drop 字段名;

插入数据
insert into 表名([字段名]) values(值1,值2...);

查询数据
select 字段1,字段2...聚合函数/*[as 别名/别名] from 表名;
查询不重复的数据
select distinct 字段1,字段2.../*[as '别名'/'别名'] from 表名;
空值查询
select 字段1,字段2... from 表名 where 字段 is [not] null;
模糊查询
select 字段1,字段2.... from 表名 where 字段 [not] like '...通配符';
排序
select 字段1,字段2... from 表名 order by 字段1 [asc/desc],字段2[asc/desc]...;
限制数量
select 字段1,字段2... from 表名 limit [偏移量],行数;
分组
select 聚合函数1 as 别名1, 合函数2 as 别名2,... from 表名 group by 字段1,字段2...;
合并查询
SQL的连接方式有外连接和内连接,其中左表为主表,如果值为空,则显示为null,内连接时无主副表之分,只显示两表联结字段相等的行.
左连接(外连接)
select 字段1,字段2,... from 表名1 left join 表名2 on 表1.key=biao2.key;
右连接(外连接)
select 字段1,字段2.... from 表名1 right join 表名2 on 表1.key=表2.key;
内连接
select 字段1,字段2... from 表名1 inner join 表名2 on 表1.key=表2.key;
笛卡尔积连接
select * from 表1,表2 where 表1.key=表2.key
自连接
slect 字段 from 表1 as t1 left join 表1 as t2 on t1.key=t2.key;
联合查询
去重联合查询
select 字段 from 表1 union select 字段 from 表2;
不去重联合查询
select 字段 from 表1 union all select 字段 from 表2;
子查询
子查询是说一个select 中有多个select
子查询有[not] in, any和all操作符
| 操作符 | 说明 |
|---|---|
| [not] in | 在\不在其中 |
| any | 任何一个 |
| all | 所有 |
更新数据
update 表名 set 字段1=值1,字段2=值2,... where 条件;
# %表示多个字符,_表示1个字符

还可以更新字段下的所有记录,例如公司对全体员工进行加薪200,那可以使用
update employee set salary=salary+200;
删除数据
delete from 表名 where 条件;

truncate classes;
truncate是执行删除一张表,再重新创建一张一样的表,执行速度比delete快.
进行全部删除或更新数据时,需要取得数据库更新权限
set sql_safe_updates=0;
聚合函数
| 函数 | 说明 |
|---|---|
| avg() | 平均值 |
| count() | 计数 |
| max() | 最大值 |
| min() | 最小值 |
| sum() | 求和 |
*所有聚合函数都会忽略null
常用函数
| 函数 | 说明 |
|---|---|
| abs(数值) | 返回绝对值 |
| bin() | 返回数值的二进制 oct()返回8进制,hex()返回16进制 |
| cancat(字符串1,字符串2,…) | 将字段拼接为一个字符串,如果有一个值为null那么返回空字符串 |
| instr(str,substr) | 返回substr再str中第一次出现的位置 |
| left(str,len) | 从左开始截取长度为len的字符串 |
| right(str,len) | 从右开始截取长度为len的字符串 |
| mid(str,pos,len) | 从左第pos位开始截取长度为len的字符串 |
| substring(str,start,len) | 从左第start位开始截取长度为len的字符串 |
| replace(str,from_str,to_str) | 从左第start位开始截取长度为len的字符串 |
| ltrim(str,from_str,to_str) | 返回删除左空格的字符串 |
| rtrim(str,from_str,to_str) | 返回删除右空格的字符串 |
| trim(str,from_str,to_str) | 返回删除左右空格的字符串 |
| repeat(str,count) | 返回由count字符组成的字符串 |
| reverse(str) | 颠倒字符串str的顺序并返回 |
| upper(str) | 返回str所有大写 |
| lower(str) | 返回str所有小写 |
| round(n,num) | 四舍五入小数点,小数点后保留num位小数,没有指定第二个参数保留0为小数 |
| floor(n) | 返回地板数 |
| rand() | 返回随机数 |
| date(date) | 返回指定日期或将文本转换为日期 |
| week(date,num) | 返回是一年中的第几周,num指定从第几开始计算 |
| month(date) | 返回月份 |
| year(date) | 返回年份 |
| day(date) | 返回日 |
| quarter(date) | 放回季度 |
| date_add(date,interval expr type) | 加日期 |
| adddate(date,interval expr type) | 加日期 |
| date_sub(date,interval expr type) | 减日期 |
| subdate(date,interval expr type) | 减日期 |
| date_format(date,格式化) | 格式化日期 |
| datediff(date,date) | 返回2个日期相差的天数 |
| curdate() | 当前日期 |
| curtime() | 当前时间 |
| now() | 当前日期时间 |
| unix_timestamp(date) | 返回一个unix时间戳,从“1970-01-01 00:00:00”开始的秒数 |
| from_unixtime(unix_timestamp) | 以“yyyy-mm-dd hh:mm:ss”格式转换时间戳函数 |
| group_cancat([distinct] str [order by str asc/desc] [separator]) | 将group by分组后的值连接起来,返回一个字符串结果 |
| group_count([distinct] str) | 将group by分组后的值统计起来 |
| ifnull(expr,alt value) | 如果expr为null 则返回alt value |
| isnull(expr) | 如果expr为null ,返回true,否则返回false |
| ifnull(expr,alt value) | 如果expr为null 则返回alt value |
| if(expr,ture,false) | 根据判断,返回true 或者false的内容,逻辑表达式case … when … then… else… end |
| 开窗函数名([字段名]) over([partition by 字段名] [order by [字段名] asc/desc][滑动窗口]) | 滑动窗口有几种指定方式,通常使用beteween frame_start and frame_end来表示范围,共有几种关键字 current row 当前行;unbounded preceding 分区中的第一行; unbounded following 分区中的最后一行;expr preceding 分区中的当前行减去expr的值;expr following 分区中的当前行加上expr的值 |
| -rank() | 排名,重复间断的序号 |
| -dense_rank() | 分区排名,重复不间断的序号 |
| -row_number() | 分区中排名,不重复不间断的序号 |
| -percent_rank() | 排名,出现排名相同的下个排名继续排名 |
| -cume_dist() | 排名,出现排名相同的下个排名继续排名 |
| -lag() | 排名,出现排名相同的下个排名继续排名 |
| -lead() | 排名,出现排名相同的下个排名继续排名 |
| -first_value() | 返回分区内第一个值 |
| -last_value() | 返回分区内最后一个值 |
| -nth_value() | 返回分区内最后一个值 |
| -nfile() | 返回分区内最后一个值 |














 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









