






牛客上看到一位同学说自己毕业后入职了腾讯,一开始月薪是 23000,有年终奖、股票和补贴,第一年的总收入是 50 万左右。
tql
第二年涨了 3k base,最后到手是 52 万。
第三年,碰到英伟达招人就跳槽了过去,月薪涨到 32000,年薪能达到 41 万,还有不少股票。
可能有小伙伴会问,好家伙,base 涨了,年薪反而降了?
我只能说英伟达是 13 薪,非自动驾驶部门 wlb,股票还有不少钱。
当然了,腾讯也不愧是国内的第一互联网大厂,整体的薪资水平确实很顶。努努力,腾讯也不是遥不可及,星球里就有一些 25 届的球友拿到了腾讯的 offer。

那接下来,我们就以《Java 面试指南》中收录的腾讯面经同学 29 Java 后端一面为例,来看看腾讯的面试官都喜欢问哪些问题,好摸个底。

背八股就认准三分恶的面渣逆袭
题目非常多,我们一个一个来过。
尤其是考研结束后打算冲春招的同学,可以抓紧时间准备起来了,尤其是 985、211 bg 的同学,春招还是可以好好拼一把的。需要PDF【领取/点击】
腾讯面经同学 29 Java 后端一面
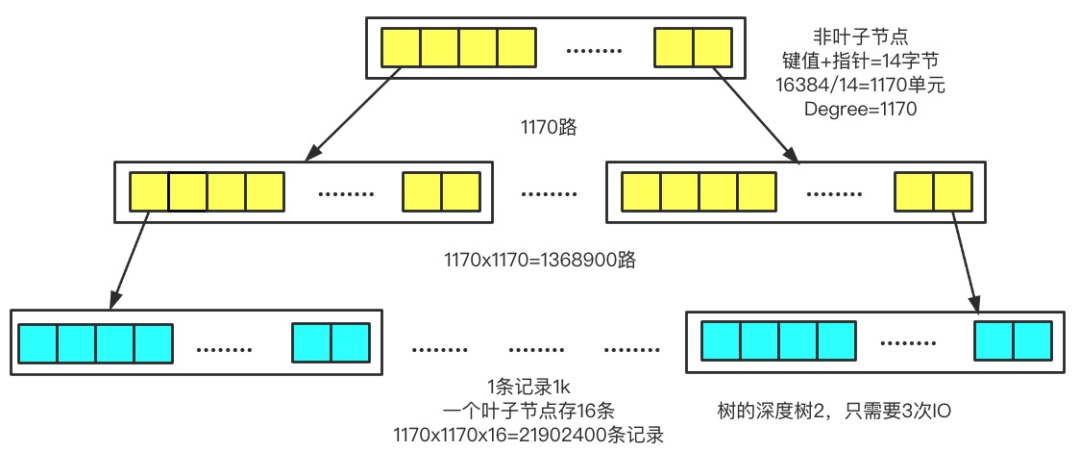
InnoDB中一个三层的B+树能存多少数据?
清幽之地:B+树存储数据条数
假如我们的主键 ID 是 bigint 类型,长度为 8 个字节。指针大小在 InnoDB 源码中设置为 6 字节,这样一共 14 字节。所以非叶子节点(一页16k)可以存储 16384/14=1170 个这样的单元(键值+指针)。
一个指针指向一个存放记录的页,一页可以放 16 条数据,树深度为 2 的时候,可以存放 1170*16=18720 条数据。
同理,树深度为 3 的时候,可以存储的数据为 1170*1170*16=21902400条记录。
MySQL的索引怎么存储的?每个索引一个B+树,还是多个索引放一个B+树?叶子节点中存的是什么数据?
MySQL 默认的存储引擎是 InnoDB,InnoDB 的索引是按照 B+ 树结构存储的,不同类型的索引有不同的存储方式。
主键索引是按照聚簇索引的方式存储的,也就是说,主键索引的叶子节点存储的是整行数据,数据和索引在同一个 B+ 树中。
普通索引、唯一索引是按照非聚簇索引的方式存储的,每个辅助索引都是独立的 B+ 树,叶子节点存储的是主键值,通过主键值回到主键索引中查找完整的数据,俗称回表。
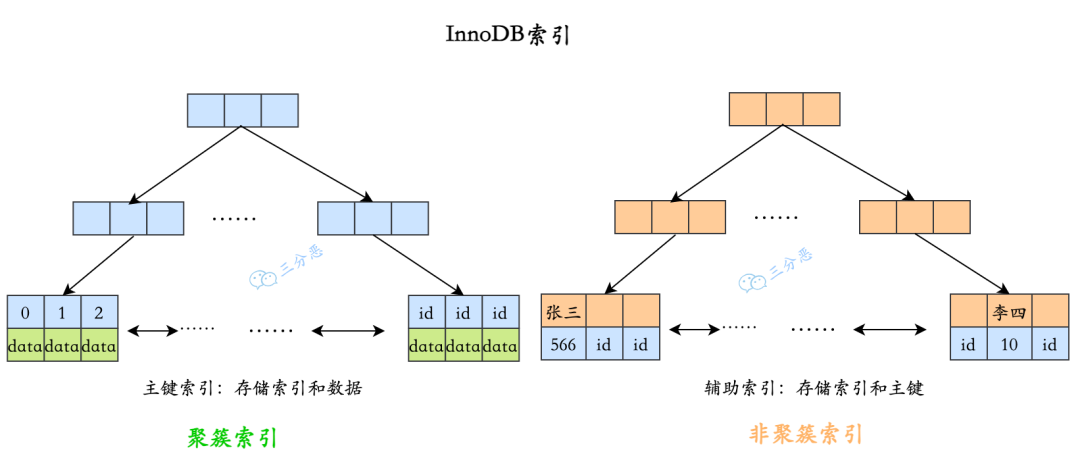
三分恶面渣逆袭:聚簇索引和非聚簇索引
每个表只能有一个聚簇索引;但可以有多个非聚簇索引。
每个叶子节点能存放多少条数据?
B+ 树索引的每个叶子节点对应一个数据页,默认大小为 16KB。假设一条数据的大小为 1k,那么每个叶子节点可以存放 16 条数据。
B+树的范围查找怎么做的?
比如说在下面这棵 B+ 树上查找 45。
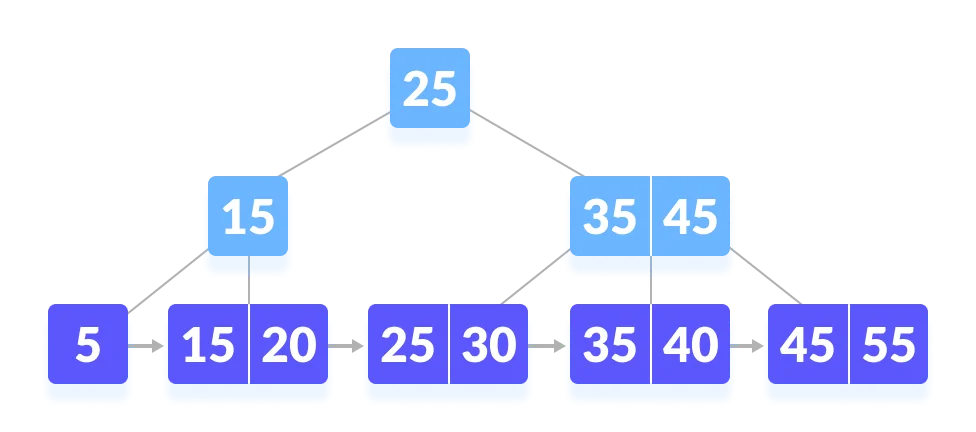
oi-wiki:查找 45
第一步,从根节点开始,因为比 25 大,所以从右子树开始。因为 45 比 35大,所以和右边的索引比较,右侧的索引也是 45,所以继续往右子树查找。
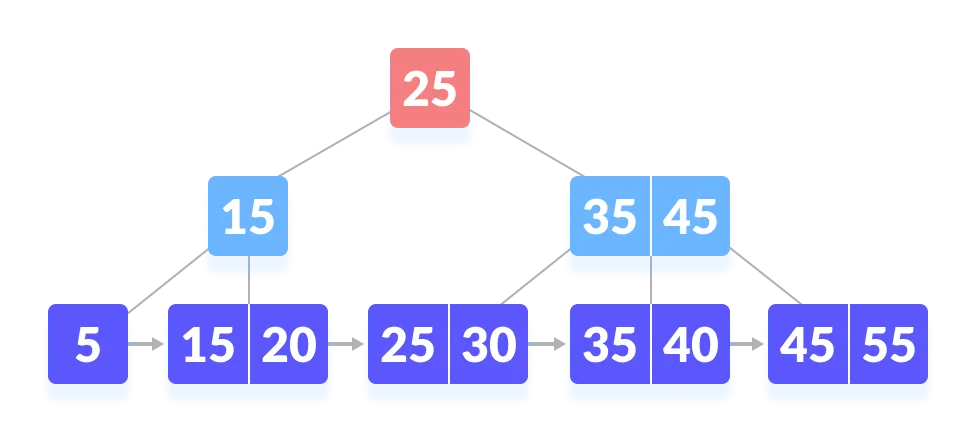
oi-wiki:从根节点开始
第二步,从叶子节点 45 开始,依次遍历,找到 45。
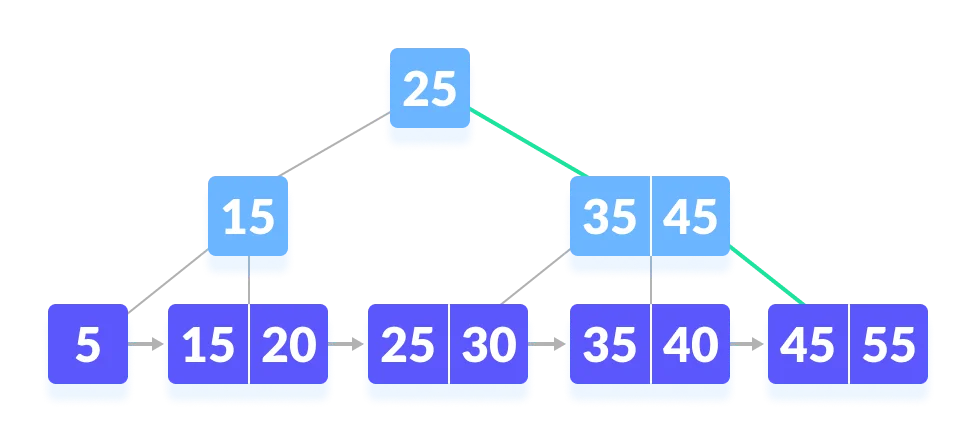
oi-wiki:找到 45
分库分表具体的分片策略是怎么做的?
常见的分片策略有三种,分别是范围分片、Hash 分片和配置路由分片。
范围分片是根据某个字段的值范围进行分库分表。这种方式适用于分片键具有顺序性或连续性的场景。
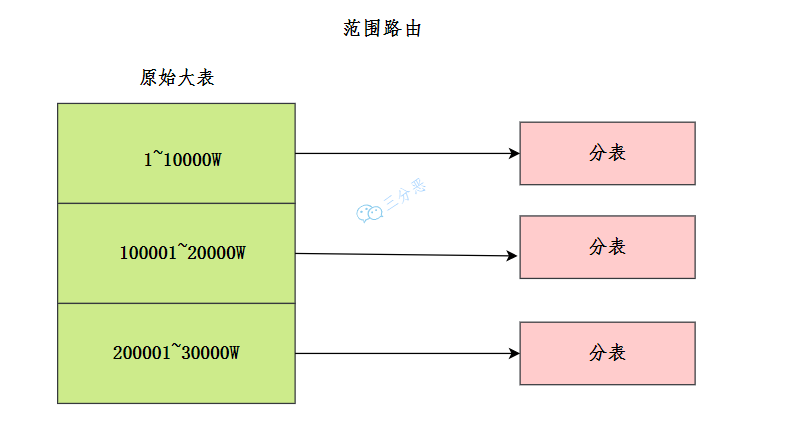
三分恶面渣逆袭:范围分片
比如说将 user_id 作为分片键:
-
1 ~ 10000 → db1.user_1
-
10001 ~ 20000 → db2.user_2
Hash 分片是指通过对分片键的值进行哈希运算,将数据均匀分布到多个分片中。
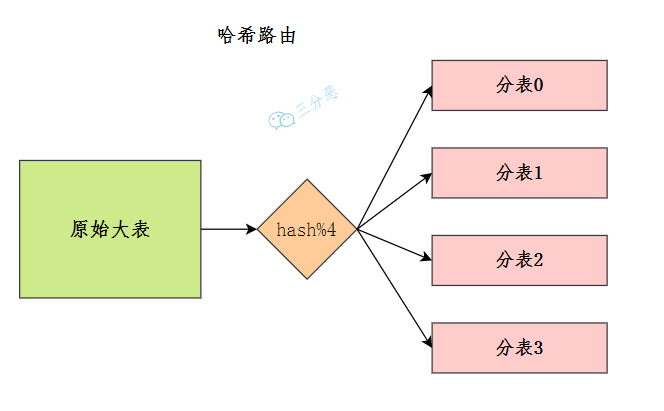
三分恶面渣逆袭:Hash 分片
假如我们一开始规划好了 4 个数据表,那么路由算法可以简单地通过取模来实现:
public String getTableNameByHash(long userId) {
int tableIndex = (int) (userId % 4);
return "user_" + tableIndex;
}
配置路由分片是通过路由配置来确定数据应该存储在哪个表,适用于分片键不规律的场景。
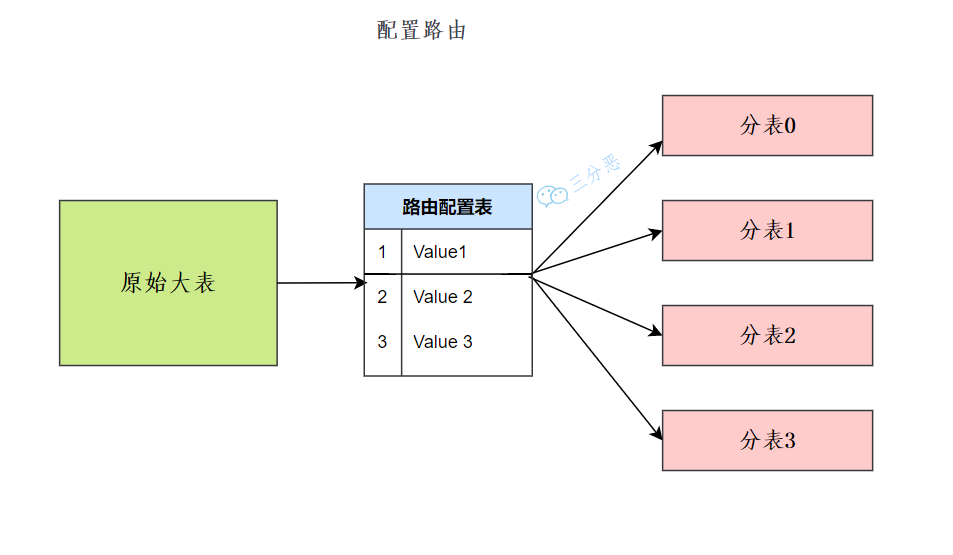
三分恶面渣逆袭:配置路由
比如说我们可以通过 order_router 表来确定订单数据存储在哪个表中:
| order_id | table_id |
|---|---|
| xxxx | table_1 |
| yyyy | table_2 |
| zzzz | table_3 |
表存满了之后怎么扩表?
在技术派实战项目中,我们将文章的基本信息和文章详情做了垂直分表处理,因为文章的详情会占用比较大的空间,并且更新频繁,而文章的基本信息占用的空间比较小,且更新频率较低。
垂直拆分可以减轻单表的查询和更新压力。
当单表数据增量过快,比如说单表超过 500 万条数据,就可以考虑水平分表了。比如说我们可以将文章表拆分成多个表,如 article_0、article_9999、article_19999 等。
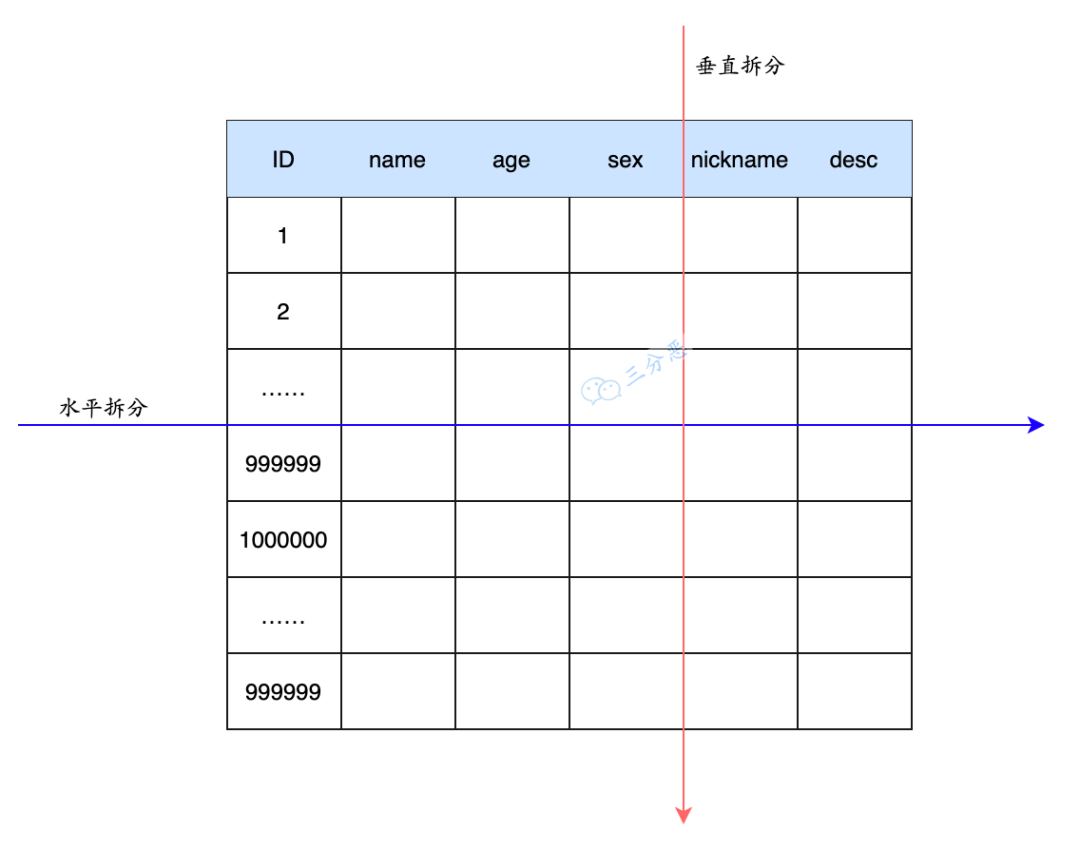
三分恶面渣逆袭:表拆分
id是怎么生成的?(分布式自增主键)
技术派项目中,我们在雪花算法 Snowflake 的基础上实现了一套自定义的 ID 生成方案,通过更改时间戳单位、ID 长度、workId 与 dataCenterId 的分配比例,ID 生成的延迟降低了 20%;同时满足了社区在高并发环境下 ID 的唯一性和可追溯性。
有没有其他的分布式id生成算法?(雪花),具体怎么实现的?
雪花算法是 Twitter 开源的分布式 ID 生成算法,其核心思想是:使用一个 64 位的数字来作为全局唯一 ID。
-
第 1 位是符号位,永远是 0,表示正数。
-
接下来的 41 位是时间戳,记录的是当前时间戳减去一个固定的开始时间戳,可以使用 69 年。
-
然后是 10 位的工作机器 ID。
-
最后是 12 位的序列号,每毫秒最多可生成 4096 个 ID。
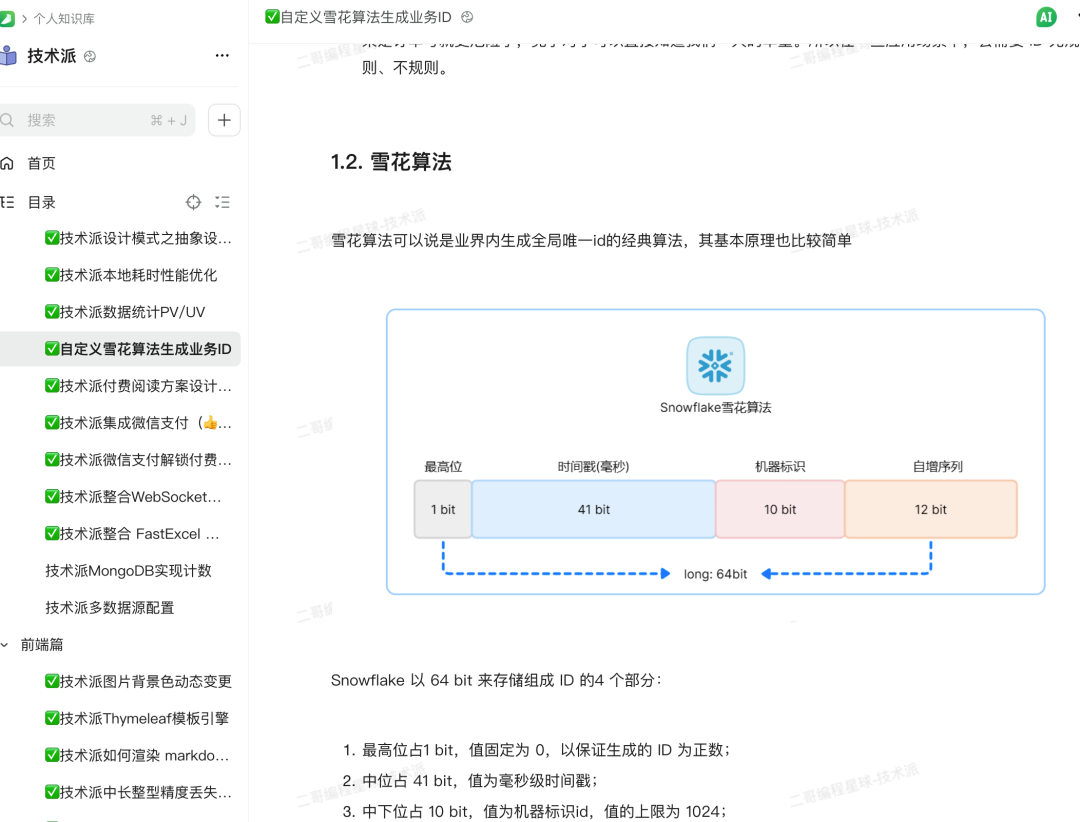
技术派:雪花算法
大致的实现代码如下所示:
public class SnowflakeIdGenerator {
private long datacenterId = 1L; // 数据中心ID
private long machineId = 1L; // 机器ID
private long sequence = 0L; // 序列号
private long lastTimestamp = -1L;
public synchronized long nextId() {
long timestamp = System.currentTimeMillis();
if (timestamp == lastTimestamp) {
sequence = (sequence + 1) & 4095;
if (sequence == 0) {
while (timestamp == lastTimestamp) {
timestamp = System.currentTimeMillis();
}
}
} else {
sequence = 0;
}
lastTimestamp = timestamp;
return ((timestamp - 1609459200000L) << 22) | (datacenterId << 17) | (machineId << 12) | sequence;
}
}
除了雪花算法,还有百度 UidGenerator、美团 Leaf 等开源的分布式 ID 生成方案。
Redis保证incr命令原子性的原理是什么?
INCR 命令是 Redis 中的一个原子操作,用于将存储在 key 中的数值加 1。
Redis 的单线程模型确保了每个命令都是原子执行的,不会被其他命令打断。
Redis数据的可靠性怎么保证?
Redis 的持久化机制保证了 Redis 服务器在重启后数据不丢失,通过 RDB 和 AOF 文件来恢复内存中原有的数据。
这两种持久化方式可以单独使用,也可以同时使用。
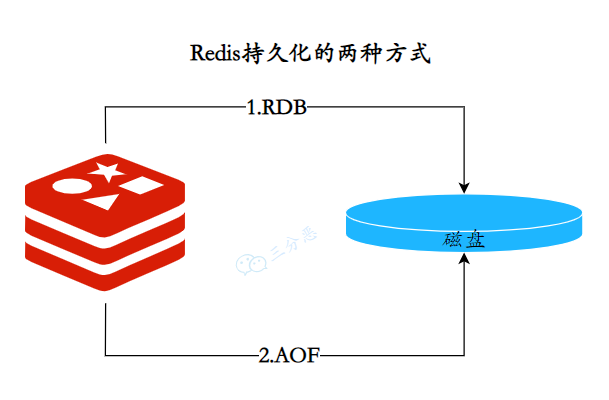
三分恶面渣逆袭:Redis持久化的两种方式
介绍AOF持久化的过程?
AOF 的工作流程分为四个步骤:命令写入、文件同步、文件重写、重启加载。
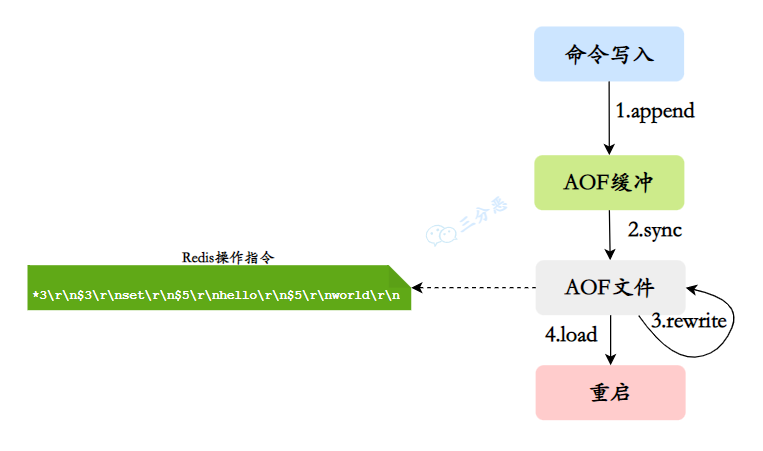
三分恶面渣逆袭:AOF工作流程
1)当 AOF 持久化机制被启用时,Redis 服务器会将接收到的所有写命令追加到 AOF 缓冲区的末尾。
2)接着将缓冲区中的命令刷新到磁盘的 AOF 文件中,刷新策略有三种:
-
always:每次写命令都会同步到 AOF 文件。
-
everysec(默认):每秒同步一次。如果系统崩溃,可能会丢失最后一秒的数据。
-
no:在这种模式下,如果发生宕机,那么丢失的数据量由操作系统内核的缓存冲洗策略决定。
3)随着 AOF 文件的不断增长,Redis 会启用重写机制来生成一个更小的 AOF 文件:
-
将内存中每个键值对的当前状态转换为一条最简单的 Redis 命令,写入到一个新的 AOF 文件中。即使某个键被修改了多次,在新的 AOF 文件中也只会保留最终的状态。
-
Redis 会 fork 一个子进程,子进程负责重写 AOF 文件,主进程不会被阻塞。
主进程(fork)
│
├─→ 子进程(生成新的 AOF 文件)
│ │
│ ├─→ 内存快照
│ ├─→ 写入临时 AOF 文件
│ ├─→ 通知主进程完成
│
├─→ 主进程(追加缓冲区到新 AOF 文件)
├─→ 替换旧 AOF 文件
├─→ 重写完成
4)当 Redis 服务器重启时,会读取 AOF 文件中的所有命令并重新执行它们,以恢复重启前的内存状态。
AOF重写期间命令可能会写入两次,会造成什么影响?
AOF 重写期间,Redis 会将新的写命令同时写入旧的 AOF 文件和重写缓冲区。
这样会带来额外的磁盘开销。
但可以防止在 AOF 重写尚未完成时,Redis 发生崩溃,导致数据丢失。即使重写失败,旧的 AOF 文件仍然是完整的。
当重写完成后,会通过原子操作将新的 AOF 文件替换旧的 AOF 文件。
讲一下JVM的内存模型?
Java 内存模型(JMM)是一个抽象模型,主要用来定义多线程中变量的访问规则,可以解决变量的可见性、有序性和原子性问题,确保在并发环境中安全地访问共享变量。
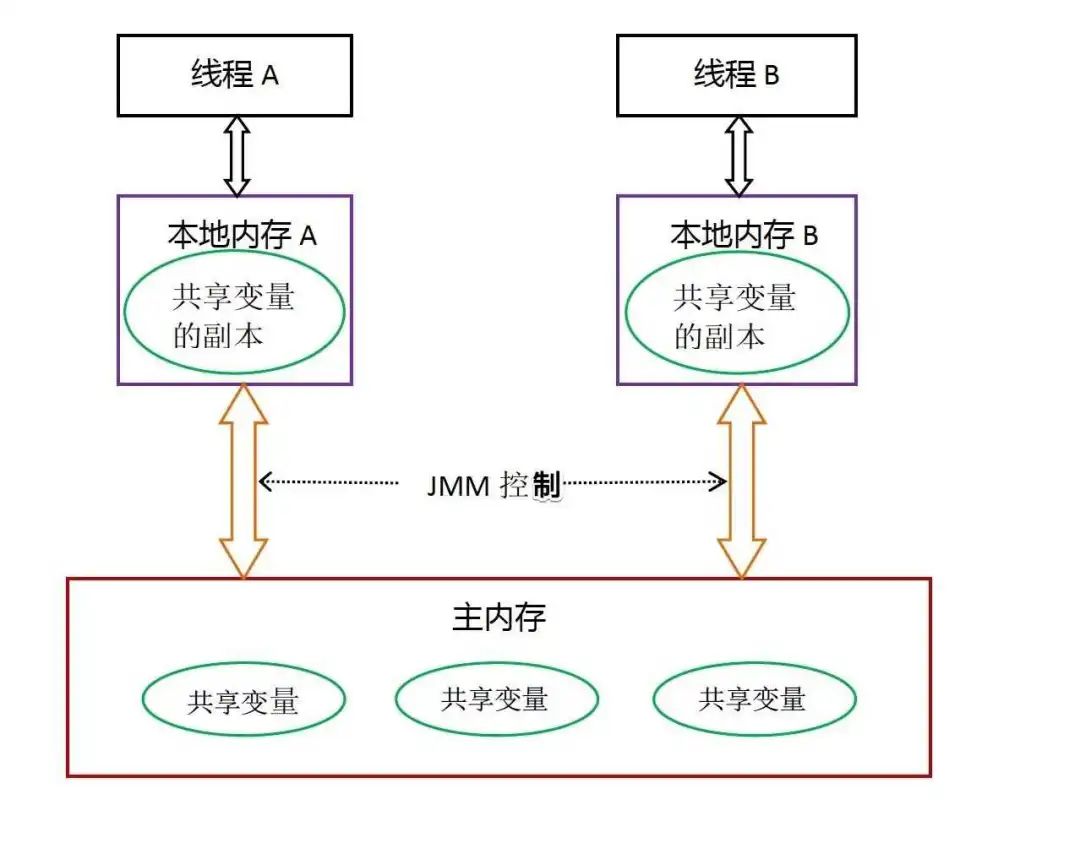
深入浅出 Java 多线程:Java内存模型
线程之间的共享变量存储在主内存中,每个线程都有一个私有的本地内存,本地内存中存储了共享变量的副本,用来进行线程内部的读写操作。
new一个对象存放在哪里?(运行时数据区),局部变量存在JVM哪里
堆属于线程共享的内存区域,几乎所有 new 出来的对象都会堆上分配,生命周期不由单个方法调用所决定,可以在方法调用结束后继续存在,直到不再被任何变量引用,最后被垃圾收集器回收。
栈属于线程私有的内存区域,主要存储局部变量、方法参数、对象引用等,通常随着方法调用的结束而自动释放,不需要垃圾收集器处理。
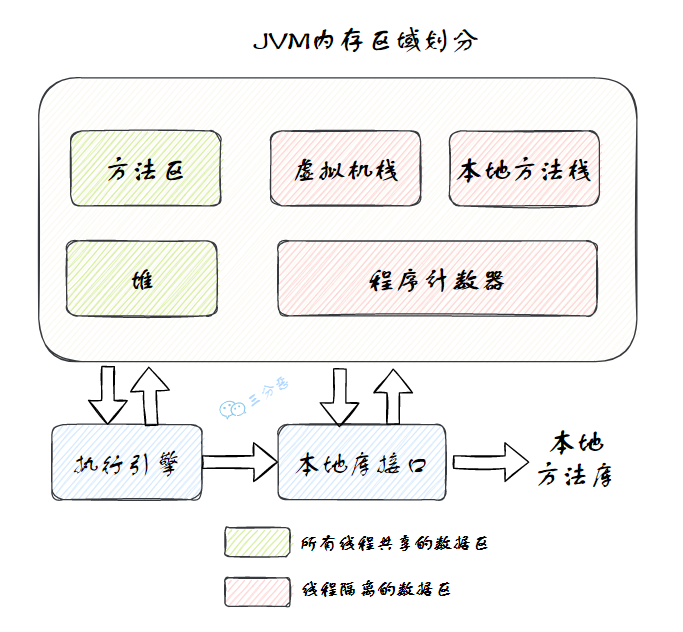
三分恶面渣逆袭:Java虚拟机运行时数据区
JVM垃圾回收机制?
垃圾回收就是对内存堆中已经死亡的或者长时间没有使用的对象进行清除或回收。
JVM 在做 GC 之前,会先搞清楚什么是垃圾,什么不是垃圾,通常会通过可达性分析算法来判断对象是否存活。
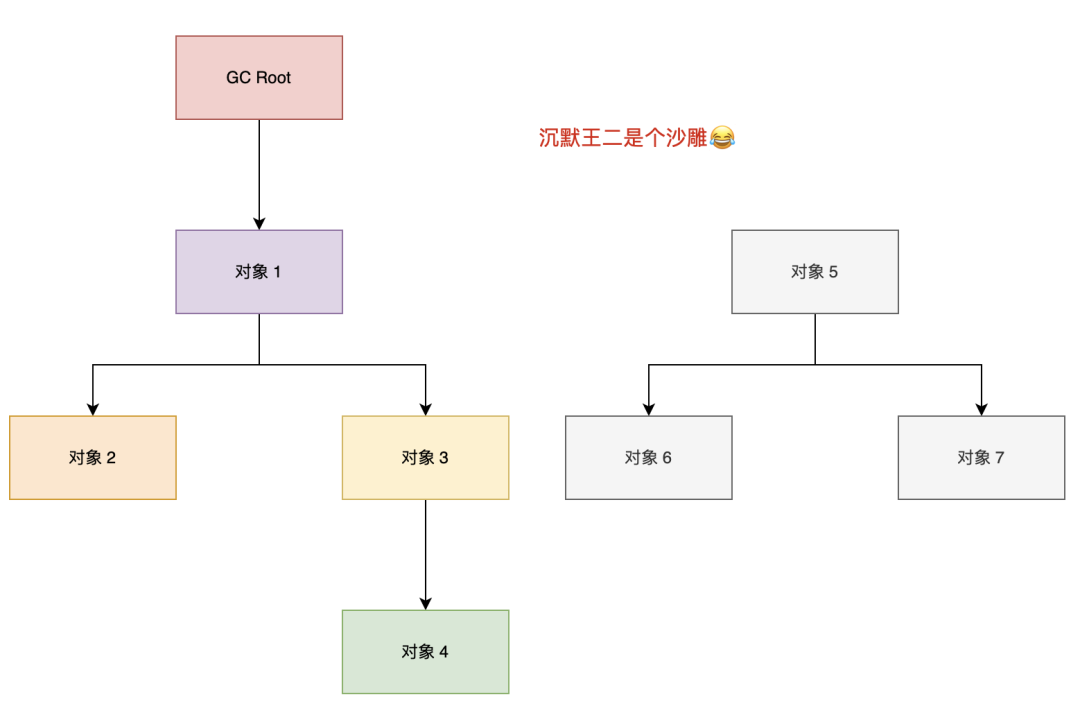
二哥的 Java 进阶之路:可达性分析
在确定了哪些垃圾可以被回收后,垃圾收集器(如 CMS、G1、ZGC)要做的事情就是进行垃圾回收,可以采用标记清除算法、复制算法、标记整理算法、分代收集算法等。
技术派项目使用的 JDK 8,所以默认采用的是 CMS 垃圾收集器。
Linux系统的8080端口有多少个TCP连接,怎么看?
可以通过 netstat 命令查看,如netstat -an | grep ':8080' | grep 'tcp' | wc -l。

二哥的 Java 进阶之路:netstat 命令查看 8080 端口
-
-a:显示所有网络连接和监听端口。 -
-n:以数字形式显示地址和端口。 -
grep ':8080':过滤出 8080 端口的连接。 -
grep 'tcp':仅显示 TCP 连接。 -
wc -l:统计匹配到的行数,即连接数。
也可以使用 ss 命令,它是 netstat 的替代工具;还可以使用 lsof 命令,它可以列出当前系统打开的文件和套接字。
如何看Linux进程或CPU使用情况?
top 命令可以实时查看所有进程的 CPU 和内存使用情况。
ps aux --sort=-%cpu | head -5可以查看 CPU 使用率最高的 5 个进程。

二哥的 Java 进阶之路:ps 命令
Linux查看内存情况?
可以使用 watch 配合 free 命令实时监控内存使用情况。如 watch -n 1 free -m每秒刷新一次内存使用情况。

二哥的 Java 进阶之路:free
讲下TCP的TIME_WAIT
TIME-WAIT 发生在第四次挥手,当客户端在发送 ACK 确认对方的 FIN 报文后,会进入 TIME_WAIT 状态。
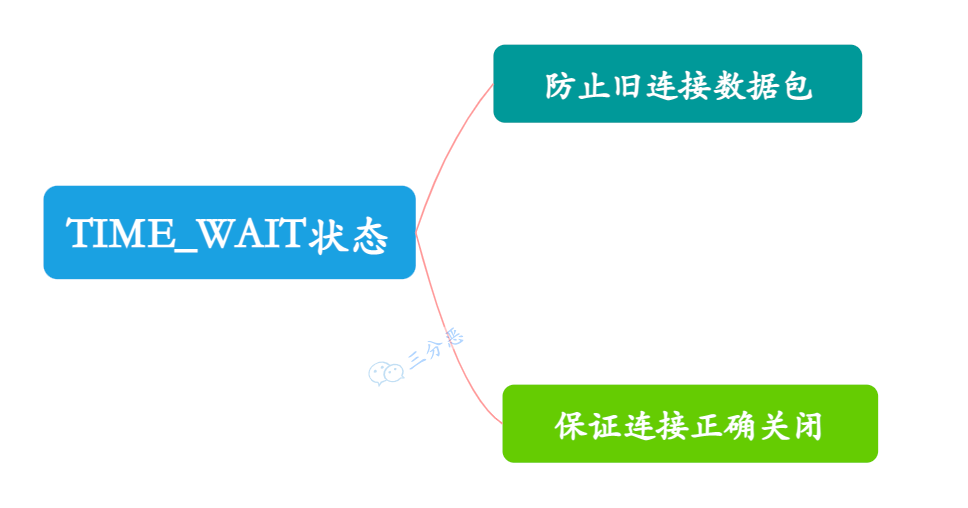
三分恶面渣逆袭:TIME_WAIT 状态的作用
它存在的意义主要有两个:
-
在 TIME_WAIT 状态中,客户端可以重新发送 ACK 确保对方正常关闭连接。
-
在 TIME_WAIT 持续的 2MSL 时间后,确保旧数据包完全消失,避免它们干扰未来建立的新连接。
ConcurrentHashMap底层是怎么实现的?
在 JDK 8 及以上版本中,ConcurrentHashMap 的实现进行了优化,不再使用分段锁,而是使用了一种更加精细化的锁——桶锁,以及 CAS 无锁算法。每个桶(Node 数组的每个元素)都可以独立地加锁,从而实现更高级别的并发访问。
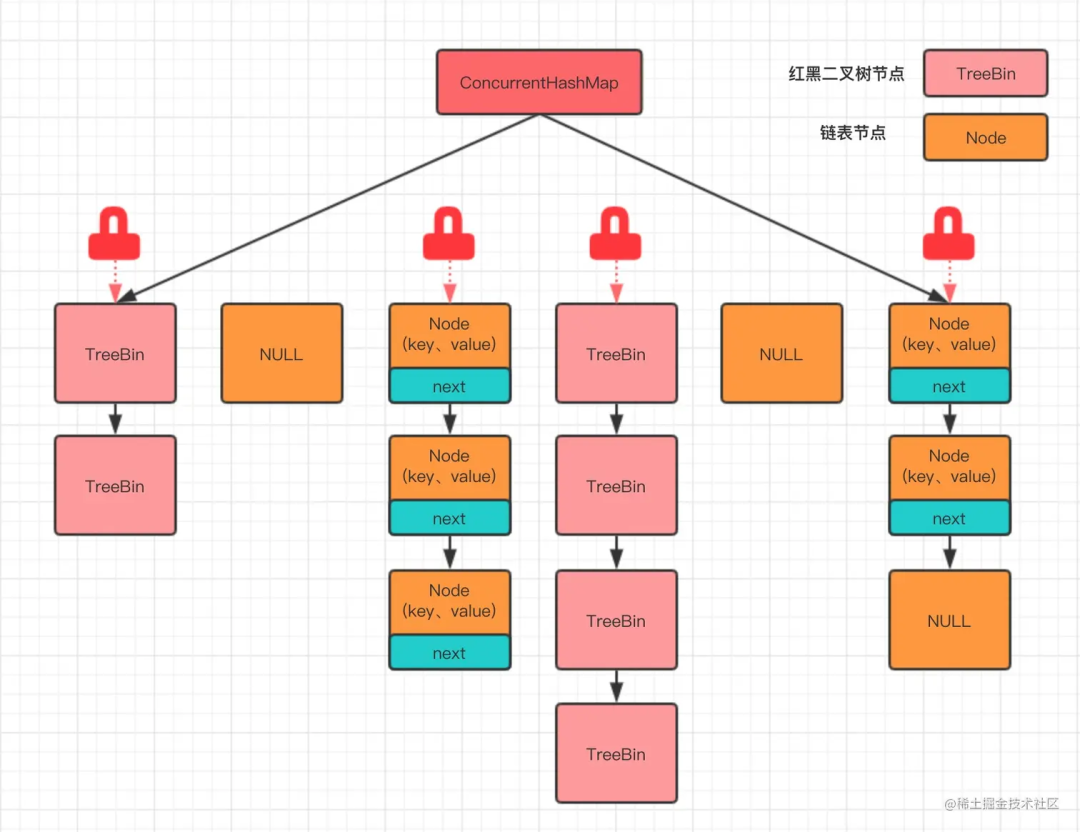
初念初恋:JDK 8 ConcurrentHashMap
对于读操作,通常不需要加锁,可以直接读取,ConcurrentHashMap 内部使用了 volatile 变量来保证内存可见性。
对于写操作,ConcurrentHashMap 使用 CAS 操作来实现无锁的更新,这是一种乐观锁的实现,因为它假设没有冲突发生,在实际更新数据时才检查是否有其他线程在尝试修改数据,如果有,采用悲观的锁策略,如 synchronized 代码块来保证数据的一致性。
ending
一个人可以走得很快,但一群人才能走得更远。二哥的编程星球已经有 6700 多名球友加入了,如果你也需要一个优质的学习环境,戳链接 🔗 加入我们吧。这是一个 编程学习指南 + Java 项目实战 + LeetCode 刷题 + 简历精修 的私密圈子,你可以阅读星球专栏、向二哥提问、帮你制定学习计划、和球友一起打卡成长。
两个置顶帖「球友必看」和「知识图谱」里已经沉淀了非常多优质的学习资源,相信能帮助你走的更快、更稳、更远。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









