







无监督学习的视频图像深度和运动估计
参考文章:https://blog.csdn.net/weixin_42113967/article/details/115732187
摘要:作者提出了一种无监督学习框架,提出了一个单目相机的序列图像进行深度估计与运动估计。使用端到端学习方法,将视图合成作为监督信号。方法使用单视图深度网络和多视图位姿网络,利用计算的深度和位姿,将附近的视图warp到目标,从而产生损失。
方法:depth network和pose network共同训练的架构模式e
核心:
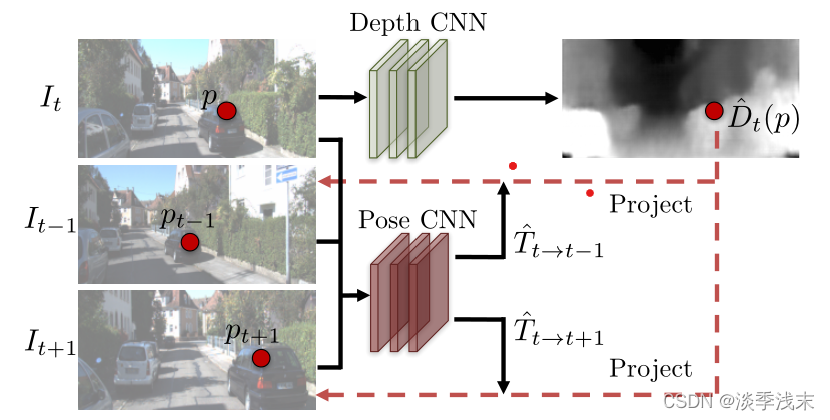
Depth CNN : (target view)作为输入,输出逐像素深度图^
.
Pose CNN: (target view)和
,
(source views)作为输入,输出相对相机位姿(
、
)。
然后,两个网络的输出被用来反向warp source views来重建target view,并使用光度重建损失来训练CNN。
Loss: ![]()
其中,It就是target view,^Is就是Is(source view) 通过深度图warp到target view的结果
Warp:

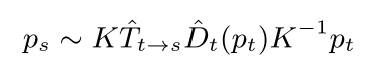
: pixel in source image,
:pixel in target image,K :the camera intrinsics matrix
除此以外,为了让该公式能够被神经网络训练,求出D和T,我们必须让它可求导 (differentiable)。本文的做法是采用Spatial Transformer Networks [2]文章中的双线性插值法 (biliner interpoltion)
限制:1 场景是静态的,没有移动的物体;2 target view和source view之间没有遮挡;3 the surface is Lam-bertian so that the photo-consistency error is meaningful.(Surface不符合Lambertian规律,不是理想散射)。
为了解决这个问题,作者提出了使用explainability prediction network(depth and pose networks连接起来同时训练)。这里没懂,参考论文笔记-深度估计(6)-Unsupervised Learning of Depth and Ego-Motion from Video_一只飞鱼的博客-CSDN博客
CVPR 2017【论文笔记】Unsupervised Learning of Depth and Ego-Motion from Video_Agent 1的博客-CSDN博客
文章额外用了一个“解释性网络”来估计每个target和source图片对的mask,用这个mask(相当于target图像与每一个source图像组成的图像对都有一个mask)来降低弱纹理的图像部分的权重。其网络结构形似pose网络,与pose共享前5层网络,随后分开分别求解释性pose和mask(可认为得到的mask大小为层数2x(N-1),即与其他所有帧,每两帧共享一层,Es就是每层中的数值。)
于是上述的Loss为:
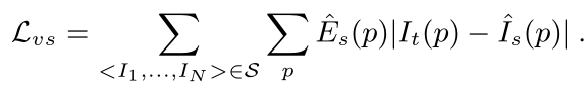
因为对Es是没有直接监督的,会导致实现最小化损失,为了避免Es最终被优化为0,给Es添加了形如softmax的交叉熵的正则项Lreg(Es),从而可以避免移动物体带来的误差???
梯度主要来源于像素的强度差(I()和相邻的I(
)),如果正确的
位于低纹理区域或远离估计区域,就会抑制训练。为了输出(不论是深度还是视差)在图像分布中平滑,特别为了解决低纹理或估计值离真值太远时会造成梯度为0或梯度错误的情况,大家一般会有两种思路:1 在深度网络中使用具有小瓶颈的卷积编码器-解码器架构(convolutional encoder-decoder architec-ture with a small bottleneck),将周围的梯度传递给当前像素;2 明确的多尺度和平滑度损失使梯度可以从更大的空间区域直接获得。本文受SfmNet启发,采用后一种方案。本文采用第二种方法,对平滑项采用L1范式,最终的loss变为:
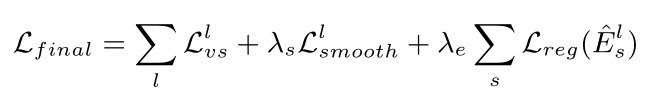
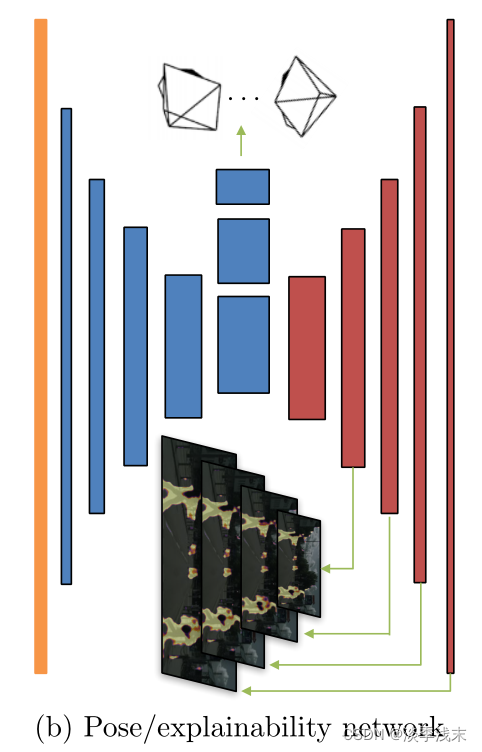
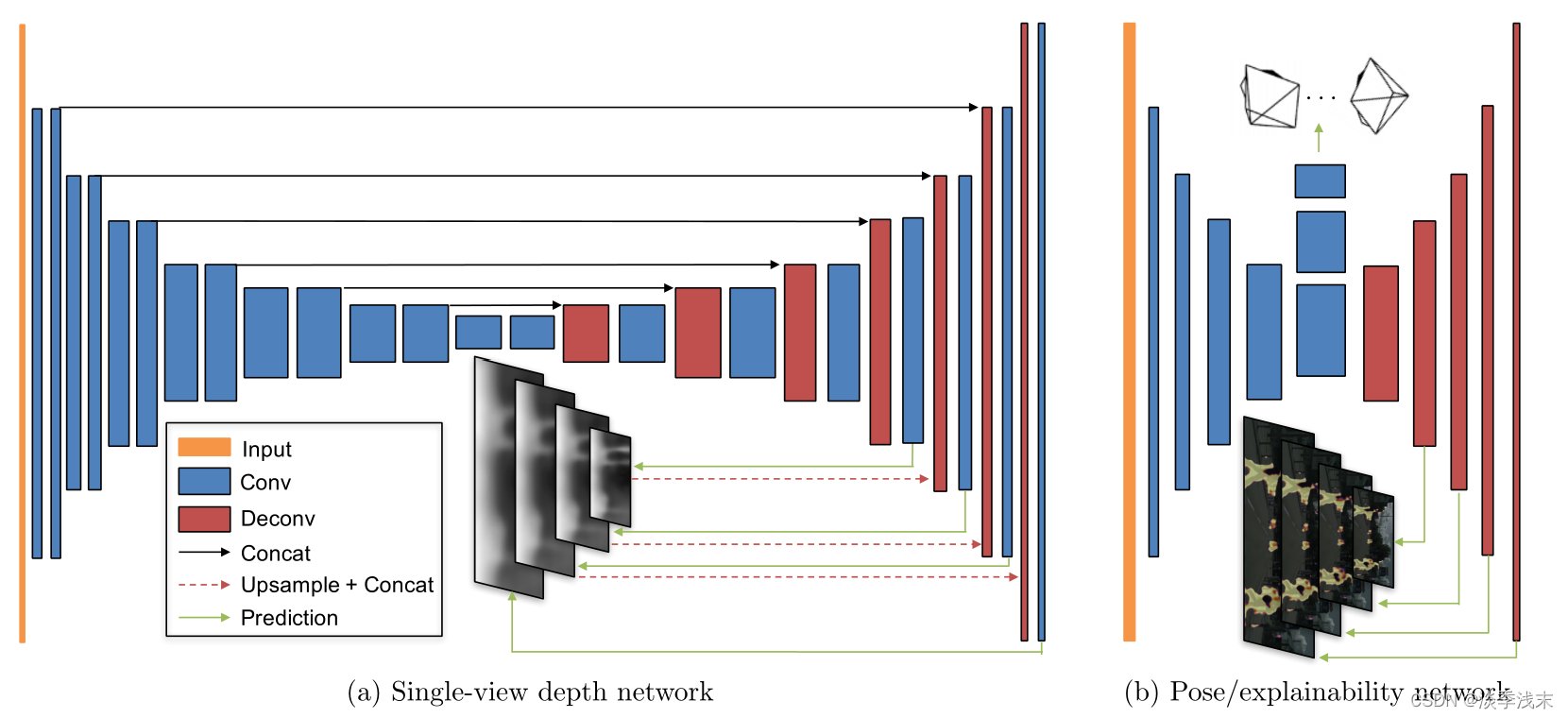
网络结构
参考:CVPR 2017【论文笔记】Unsupervised Learning of Depth and Ego-Motion from Video_Agent 1的博客-CSDN博客
都是encoder-decoder的结构,Single-view depth network采用dispnet的结构;pose network的input是target和source连接在一起的,经过七个卷积层再应用全局平均池化预测空间位置。
对于explainability prediction network,前五层和pose network是共享的,output通过softmax每两个通道归一化,第二个通道经过归一化后就是^Es。除了预测层其他层都使用relu激活,并且使用了激活函数为1/(α∗sigmoid(x)+β) 其中α = 10 and β = 0.1。
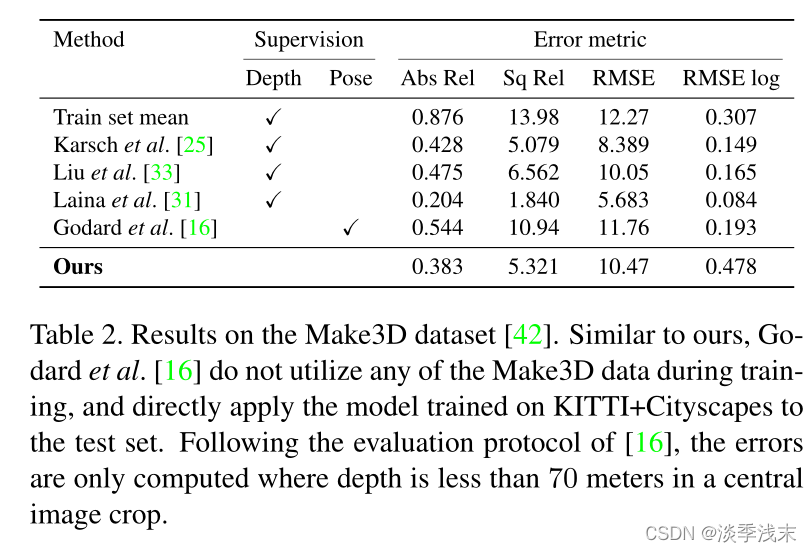
实验:KITTI Cityscapes

Make 3D
Visualizing the explainability prediction

存在的问题:1 目前的框架对运动物体和遮挡的物体估计效果不好,这两者解决3D场景的关键问题。通过运动分割(motion segmentation)可能是一个潜在的解决方案; 2 需要已知的相机内参;3 深度预测还是不够完整。

















 8088
8088

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









