







 本文介绍了如何从前程无忧网上抓取爬虫职位信息,通过Python实现网络请求和数据解析,将数据存储,并进行详细的统计与可视化,包括学历、工作地点、福利、经验要求、公司性质和招聘人数的分析。
本文介绍了如何从前程无忧网上抓取爬虫职位信息,通过Python实现网络请求和数据解析,将数据存储,并进行详细的统计与可视化,包括学历、工作地点、福利、经验要求、公司性质和招聘人数的分析。
前言
本文以前程无忧网的爬虫职位为例,通过
面向对象的形式进行编码,利用requests库发起请求,利用xpath与正则表达式进行数据解析,将最终结果存入Excel中,最后利用pyecharts对数据进行统计并可视化(截图模糊但实际效果清晰)。
一、页面分析
-
首先进入前程无忧网首页:https://www.51job.com/
-
在搜索框中输入”爬虫“,点击搜索。
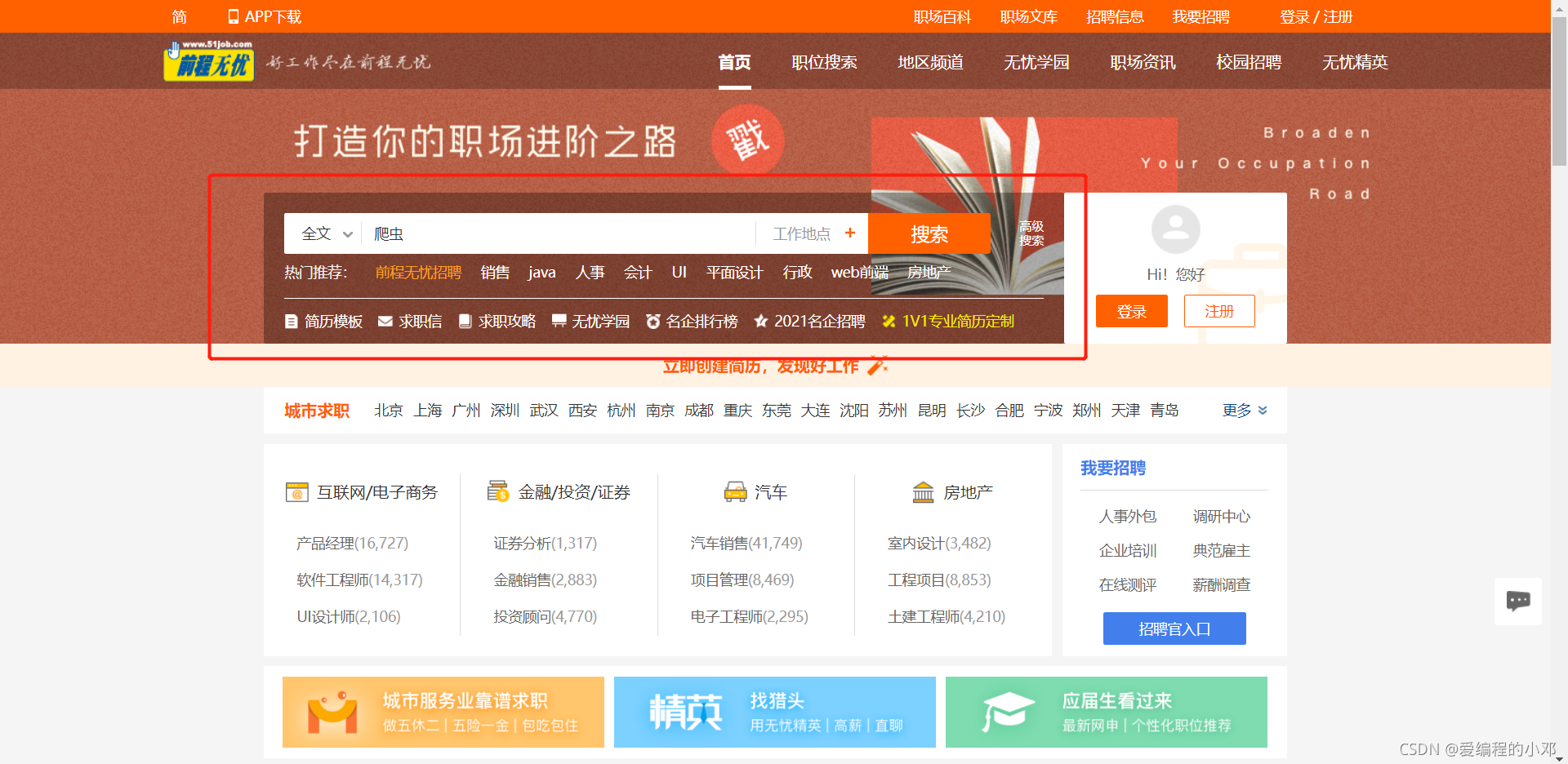
-
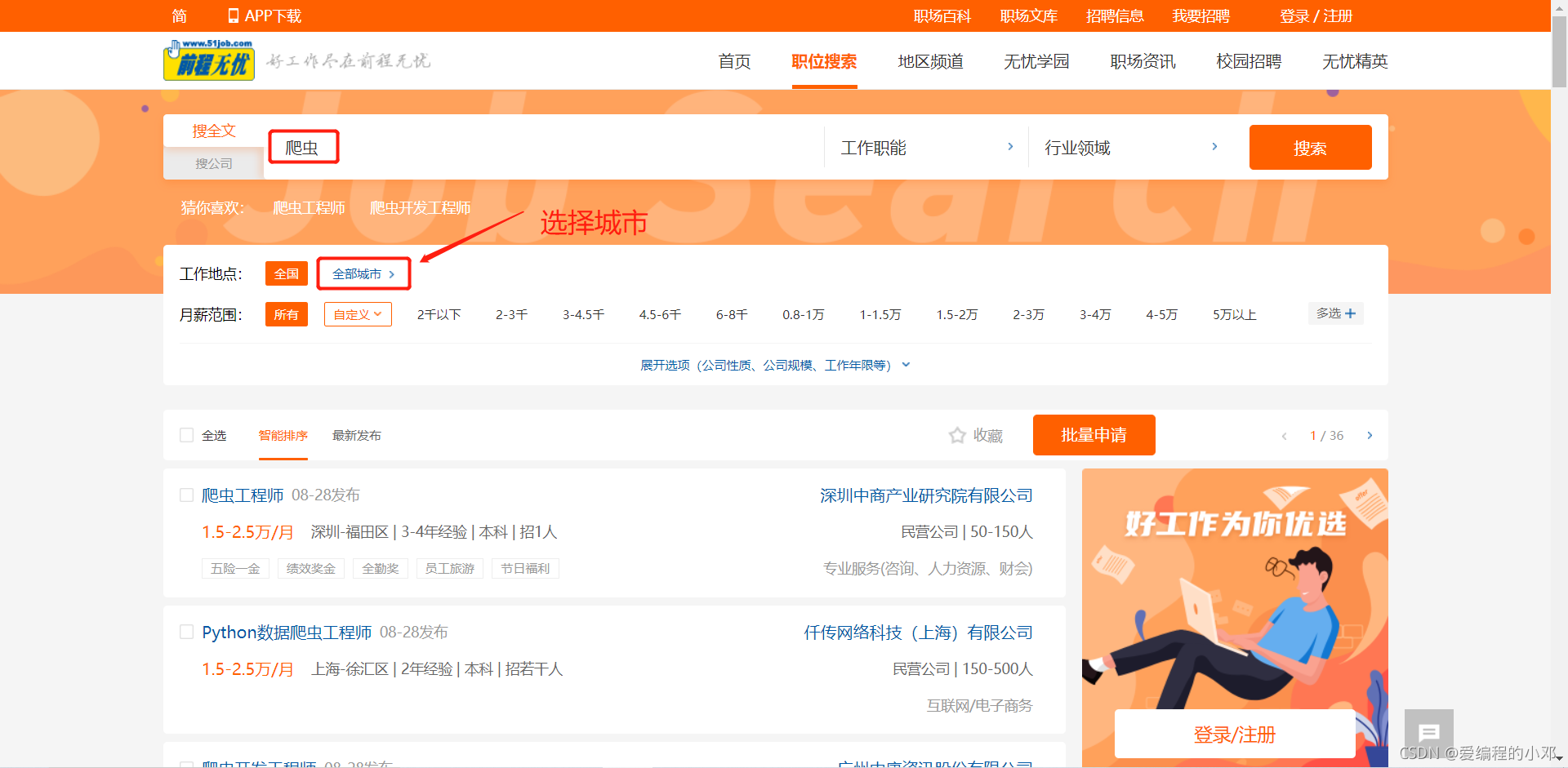
返回的页面如下。
-
通过在搜索框中搜索不同关键词,页面下方导航栏改变页数,以及选择不同城市,通过观察网页URL可以发现如下规律,由于URL的查询字符串部分完全一致,所以下图中未显示。(下图URL为全国爬虫职位第一页的URL)

-
下表为中国主要城市的编号。
| 城市名 | 城市编号 |
|---|---|
| 全国 | 000000 |
| 北京市 | 010000 |
| 上海市 | 020000 |
| 广州市 | 030200 |
| 深圳市 | 040000 |
| 武汉市 | 180200 |
| 西安市 | 200200 |
| 杭州市 | 080200 |
| 南京市 | 070200 |
| 成都市 | 090200 |
| 重庆市 | 060000 |
| 东莞市 | 030800 |
| 大连市 | 230300 |
| 沈阳市 | 230200 |
| 苏州市 | 070300 |
| 昆明市 | 250200 |
| 长沙市 | 190200 |
| 合肥市 | 150200 |
| 宁波市 | 080300 |
| 郑州市 | 170200 |
| 天津市 | 050000 |
| 青岛市 | 120300 |
| 济南市 | 120200 |
| 哈尔滨市 | 220200 |
| 长春市 | 240200 |
| 福州市 | 110200 |
-
由于无法直接获得职位信息的总页数,所以只能通过尝试发现,全国爬虫职位信息共36页。同时职位编码可以利用程序进行转换。
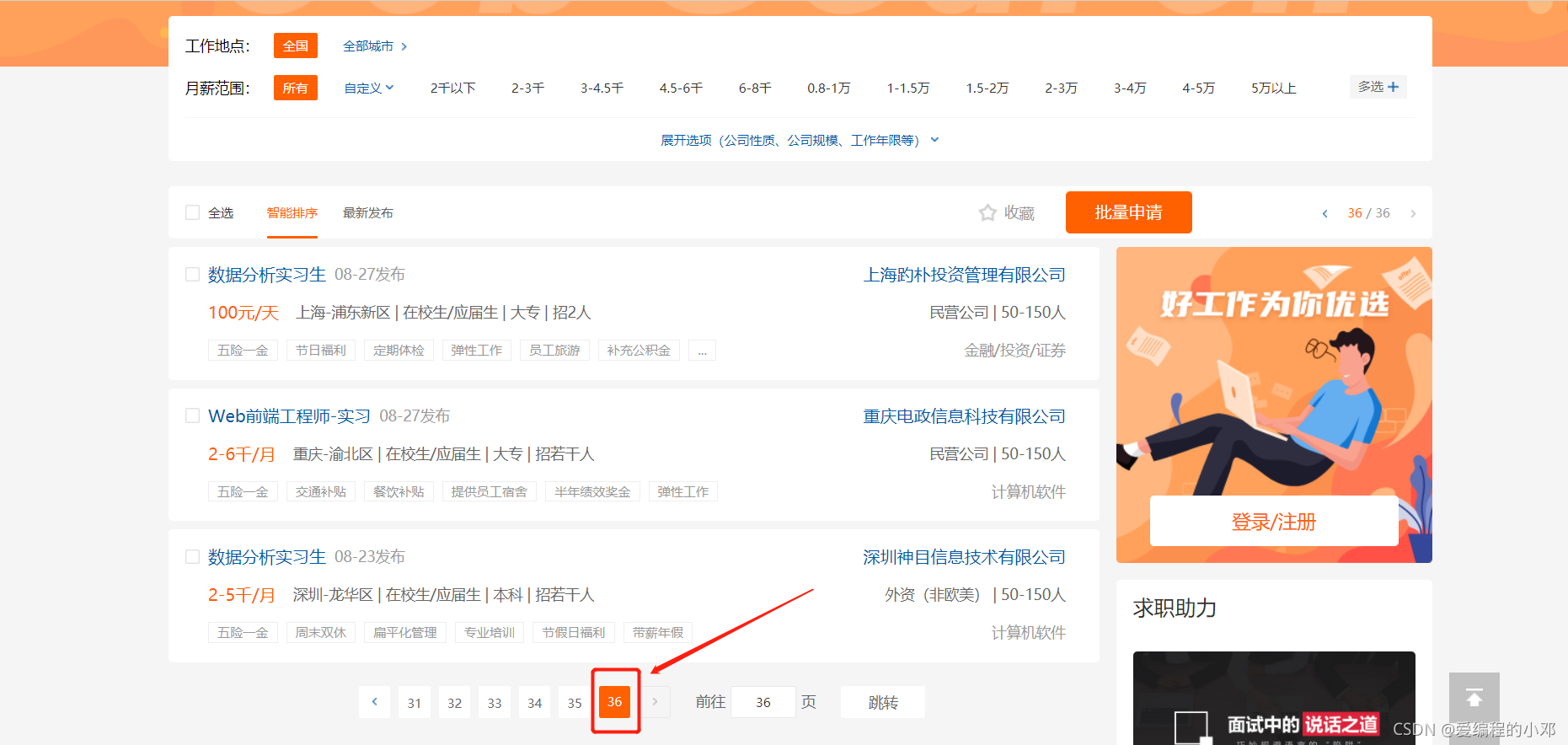
-
通过以上分析可以得到模板URL,通过改变相应位置的参数即可改变搜索条件,其他位置的参数感兴趣的小伙伴可以自行研究。
-
到此网页的URL分析完成,下面解决数据提取问题。通过观察发现,服务器返回的网页源代码,与在开发者工具(F12)中的网页源代码不同,原因是由于浏览器呈现的数据是由JS通过浏览器二次渲染得到的,所以数据要在JS代码中获取。
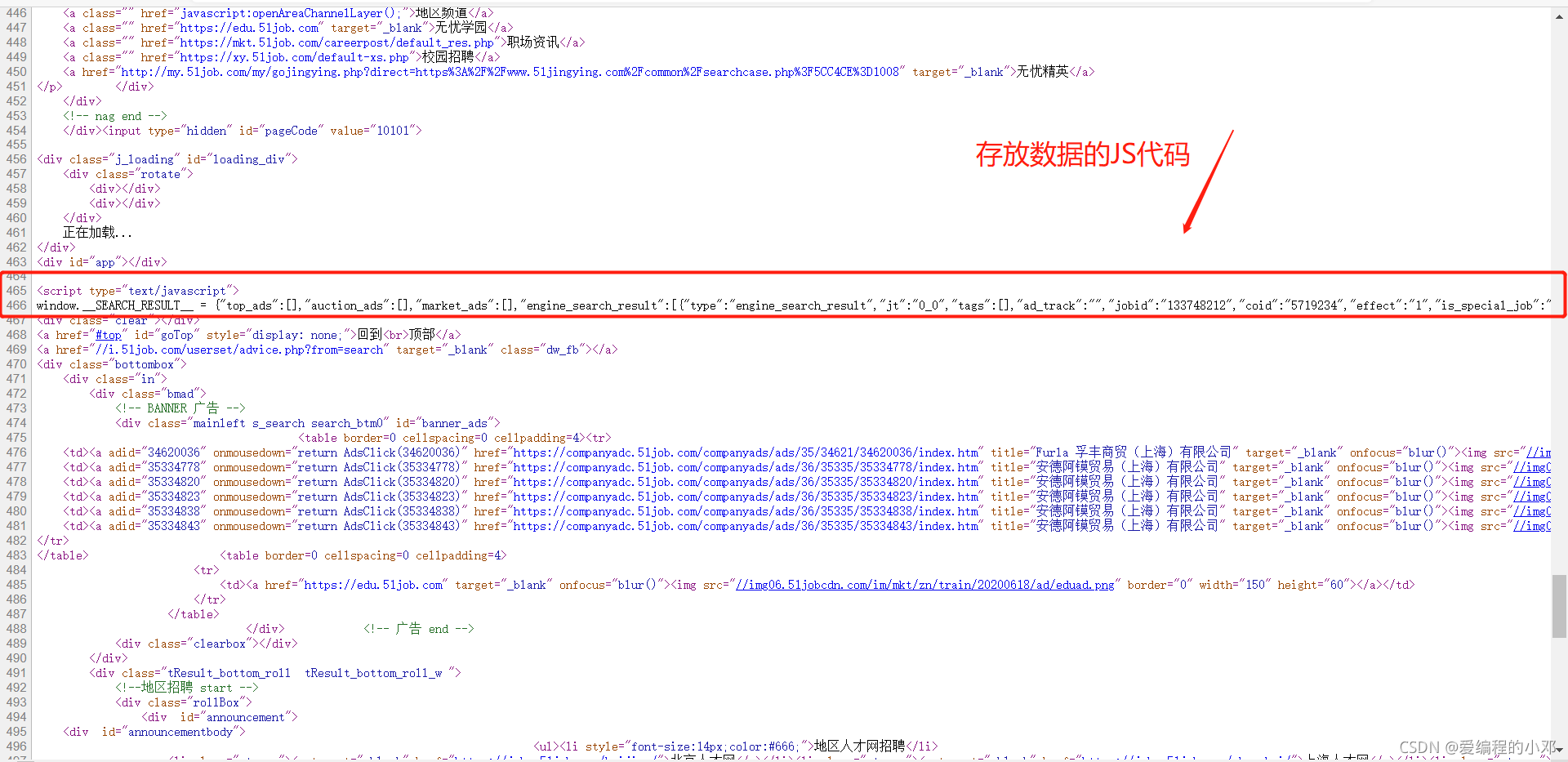
-
经过xpath和正则表达式提取之后,可以看到数据的存储形式。每页返回一个列表,列表含有若干个下图所示的字典。这样就可以提取到想要的数据。
{
"type":"engine_search_result",
"jt":"0_0",
"tags":[
],
"ad_track":"",
"jobid":"133748212",
"coid":"5719234",
"effect":"1",
"is_special_job":"",
"job_href":"https:\/\/jobs.51job.com\/shenzhen-ftq\/133748212.html?s=sou_sou_soulb&t=0_0",
"job_name":"爬虫工程师",
"job_title":"爬虫工程师",
"company_href":"https:\/\/jobs.51job.com\/all\/co5719234.html",
"company_name":"深圳中商产业研究院有限公司",
"providesalary_text":"1.5-2.5万\/月",
"workarea":"040100",
"workarea_text":"深圳-福田区",
"updatedate":"08-28",
"iscommunicate":"",
"companytype_text":"民营公司",
"degreefrom":"6",
"workyear":"5",
"issuedate":"2021-08-28 09:02:13",
"isFromXyz":"",
"isIntern":"",
"jobwelf":"五险一金 绩效奖金 全勤奖 员工旅游 节日福利",
"jobwelf_list":[
"五险一金",
"绩效奖金",
"全勤奖",
"员工旅游",
"节日福利"
],
"isdiffcity":"",
"attribute_text":[
"深圳-福田区",
"3-4年经验",
"本科",
"招1人"
],
"companysize_text":"50-150人",
"companyind_text":"专业服务(咨询、人力资源、财会)",
"adid":""
},
二、代码实现
import urllib.parse
import random
import requests
from lxml import etree
import re
import json
import time
import xlwt
class QianChengWuYouSpider(object):
# 初始化
def __init__(self, city_id, job_type, pages):
# url模板
self.url = 'https://search.51job.com/list/{},000000,0000,00,9,99,{},2,{}.html'
# UA池
self.UApool = [
"Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0) Opera 12.14",
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:68.0) Gecko/20100101 Firefox/68.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:75.0) Gecko/20100101 Firefox/75.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.16; rv:83.0) Gecko/20100101 Firefox/83.0',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0; Touch; MASMJS)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)',
"Opera/12.80 (Windows NT 5.1; U; en) Presto/2.10.289 Version/12.02",
"Opera/9.80 (Windows NT 6.1; U; es-ES) Presto/2.9.181 Version/12.00",
"Opera/9.80 (Windows NT 5.1; U; zh-sg) Presto/2.9.181 Version/12.00",
]
# 请求头
self.headers = {
'User-Agent': random.choice(self.UApool),
# 注意加上自己的Cookie
'Cookie': '',
}
# 请求参数
self.params = {
"lang": "c",
"postchannel": 0000,
"workyear": 99,
"cotype": 99,
"degreefrom": 99,
"jobterm": 99,
"companysize": 99,
"ord_field": 0,
"dibiaoid": 0,
"line": '',
"welfare": ''
}
# 保存的文件名
self.filename = "前程无忧网" + job_type + "职位信息.xls"
# 城市编号
self.city_id = city_id
# 职位名称 【转为urlencode编码】
self.job_type = urllib.parse.quote(job_type)
# 页数
self.pages = pages
# 临时存储容器
self.words = []
# 请求网页
def parse(self, url):
response = requests.get(url=url, headers=self.headers, params=self.params)
# 设置编码格式为gbk
response.encoding = 'gbk'
# 网页源代码
return response.text
# 数据提取
def get_job(self, page_text):
# xpath
tree = etree.HTML(page_text)
job_label = tree.xpath('//script[@type="text/javascript"]')[2].text
# 正则表达式
job_str = re.findall('"engine_jds":(.*"adid":""}]),', job_label)[0]
# 转换为json类型
data = json.loads(job_str)
# 数据提取
for item in data:
# 职位名称
job_name = item['job_name']
# 职位链接
job_href = item 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









