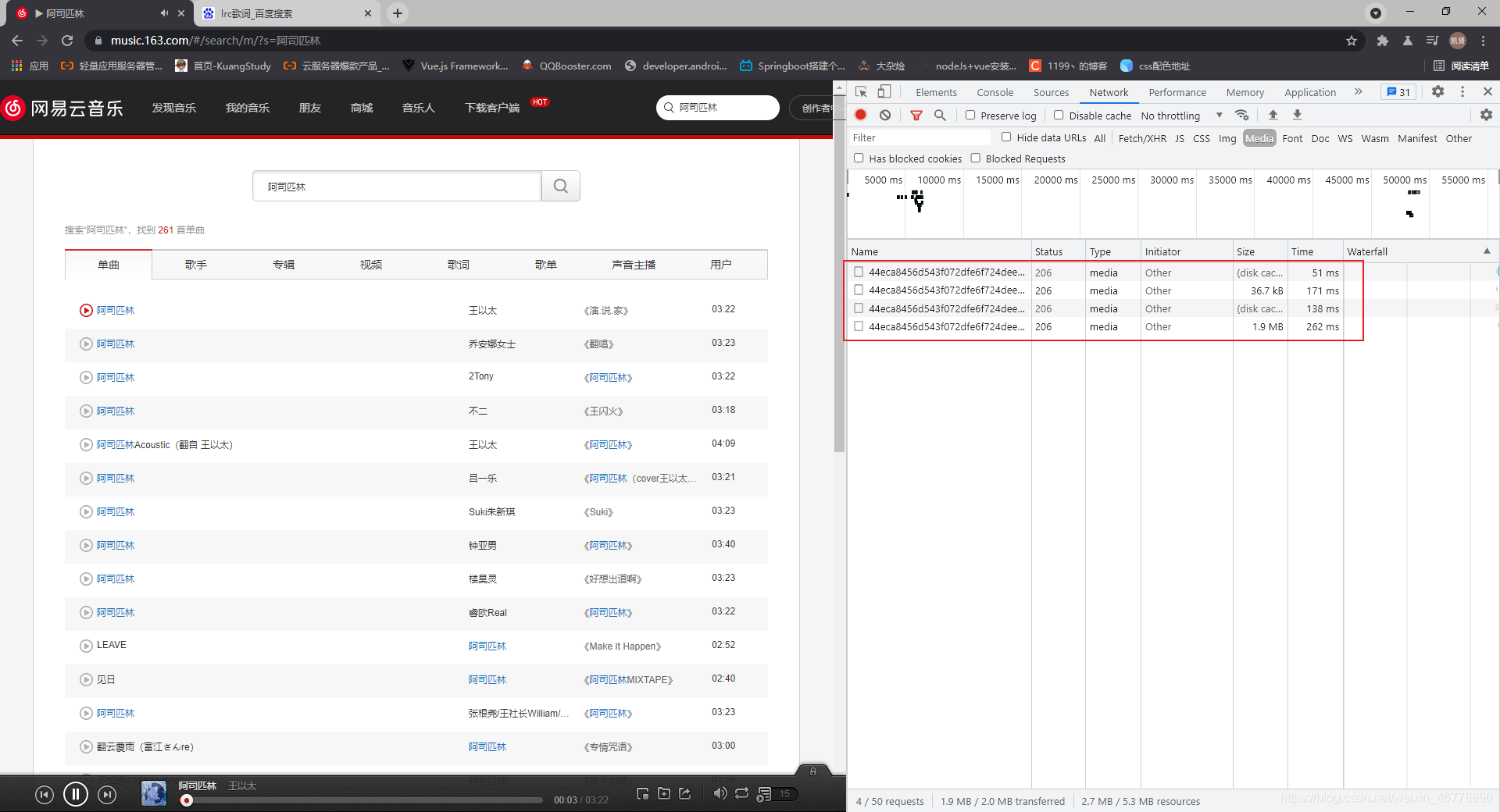
获得网易云音乐歌曲播放的url 首先打开F12开发者工具,点击NetWork,Media过滤一些不必要的请求 搜索你要的歌曲,这里例举阿司匹林 点击播放 这边会显示请求 点击Size最大的请求,复制其url即可 歌词的话可以去百度上搜索XXXLRC歌词,这里例句阿司匹林








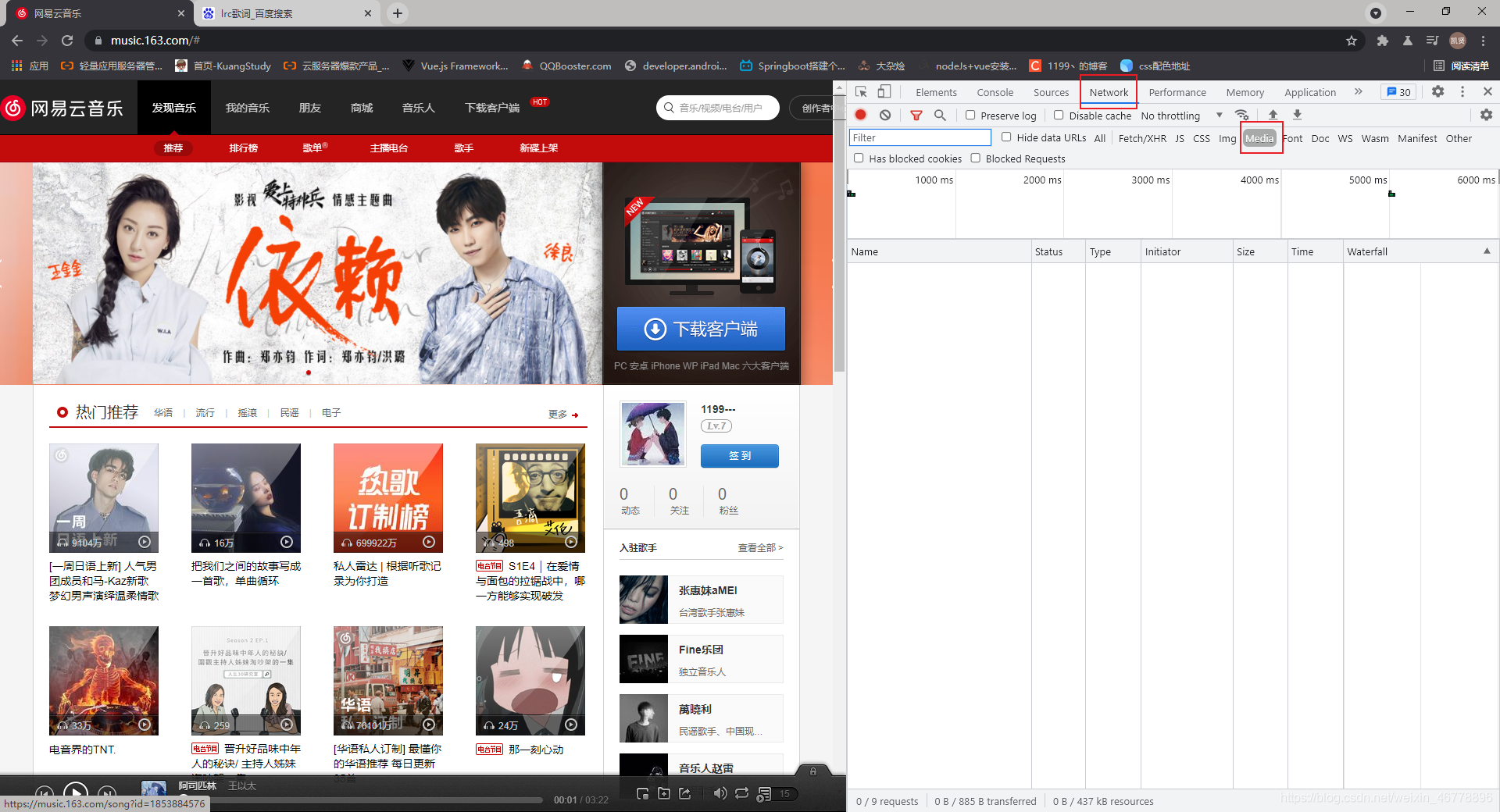
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0GEj9uoD-1624511923511)(C:\Users\L\AppData\Roaming\Typora\typora-user-images\image-20210624130855682.png)]](https://i-blog.csdnimg.cn/blog_migrate/05f5054d5a604383035533efac8fad50.png)
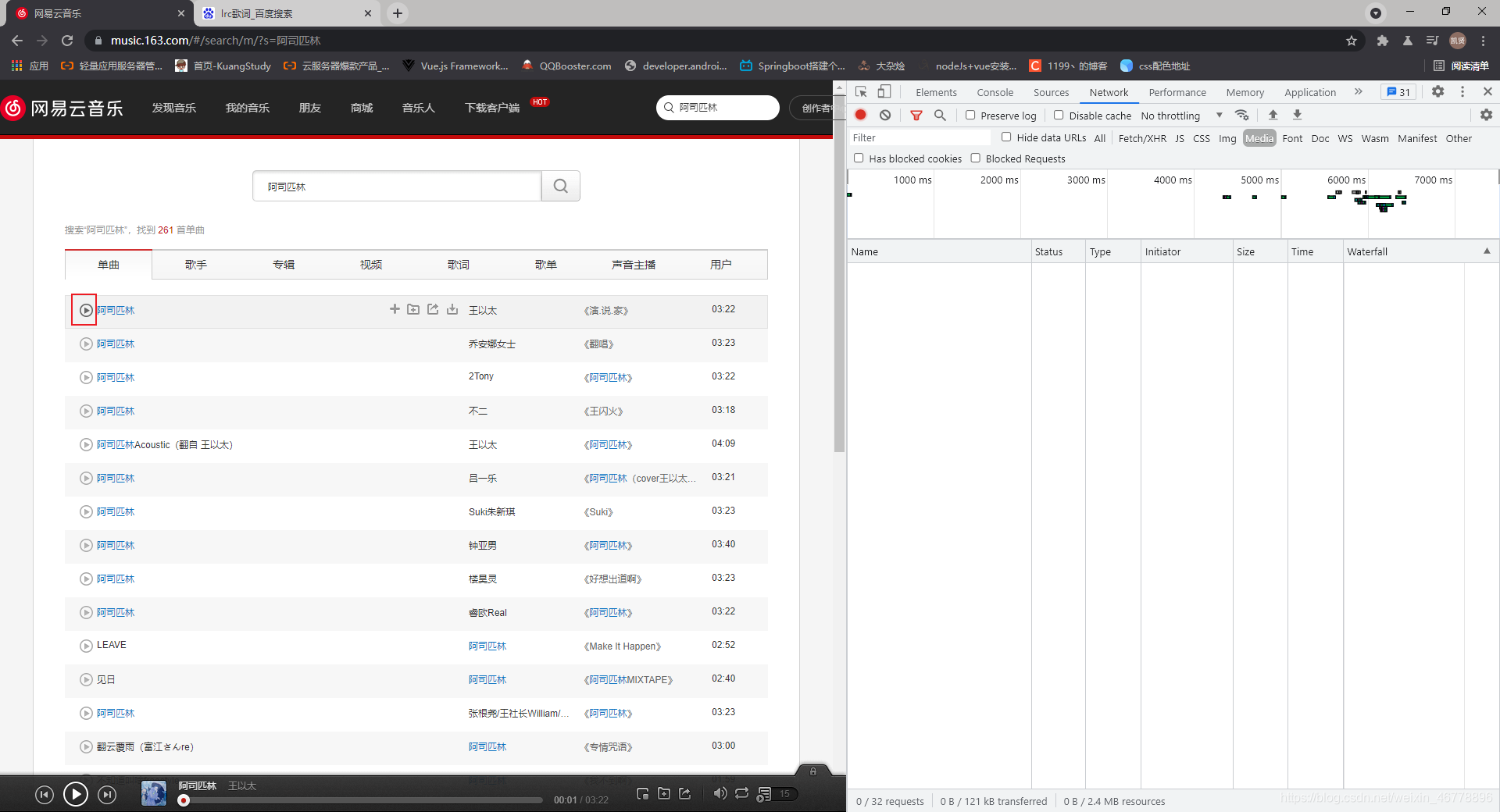
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-X0XDNC76-1624511902652)(C:\Users\L\AppData\Roaming\Typora\typora-user-images\image-20210624131401061.png)]](https://i-blog.csdnimg.cn/blog_migrate/fa17f970c62cb4d617a7ab79ca70f4b9.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MZ2iYgdI-1624511902653)(C:\Users\L\AppData\Roaming\Typora\typora-user-images\image-20210624131424505.png)]](https://i-blog.csdnimg.cn/blog_migrate/9a7282c66fcd9311399309cb6a6ab140.png)


















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






