






 文章介绍了一种名为AdaptiveNet的方法,它允许在部署后针对边缘环境动态调整神经网络架构,以优化准确性和延迟。通过云上预训练模型的弹性化和边缘设备上的架构搜索,AdaptiveNet在各种视觉任务和设备上表现出色,降低了训练开销并提升了模型性能。
文章介绍了一种名为AdaptiveNet的方法,它允许在部署后针对边缘环境动态调整神经网络架构,以优化准确性和延迟。通过云上预训练模型的弹性化和边缘设备上的架构搜索,AdaptiveNet在各种视觉任务和设备上表现出色,降低了训练开销并提升了模型性能。
AdaptiveNet : Post-deployment Neural Architecture Adaptation for Diverse Edge Environment, Mobicom, 23
( AdaptiveNet:面向多元边缘环境的部署后神经网络结构的适应器 )
0. Abstract
研究背景:随着深度学习模型在边缘设备上的推广,为了保证边缘环境中的服务质量,十分需要在边缘环境中生成定制化的模型结构。
研究现状:传统的部署前模型定制方法难以处理边缘环境的多样性。
创新点:作者提出部署到边缘环境后再调整模型框架,可以精确测量模型质量并保留隐私数据。
实现方法:一种预训练辅助的云模型弹性化方法(在人为指定的原模型的指导下生成模型架构的搜索空间),一种边缘友好的设备上架构搜索方法(每个设备基于一系列边缘定制的优化有效地找到并维护最合适的子网)
性能:能够显著实现更好的准确性和延迟权衡,与baseline相比在60%的延迟下。实现比平均精度提高46.74%。同时训练开销小,云端13GPU小时,边缘环境2min。
1. Introduction
研究背景:同一模型的部署环境差异巨大,同一边缘环境也具有动态性。(这里文章有举例)
研究现状:现今研究有许多根据目标环境自动生成定制模型的技术。大部分方法在云端实现,作者称为:Pre-deployment approaches。例如NAS(Nerual Architecture Search),但NAS需要从目标环境中收集信息,同时不适应高动态的边缘环境。
一个更理想的方法是让模型在部署后自动适应目标环境,作者称为:Post-deployment approach,可以精确测量模型质量并保留隐私数据。过往的部署后方法研究更侧重于对模型进行量化和剪枝、边缘环境种数据分布的差异性。
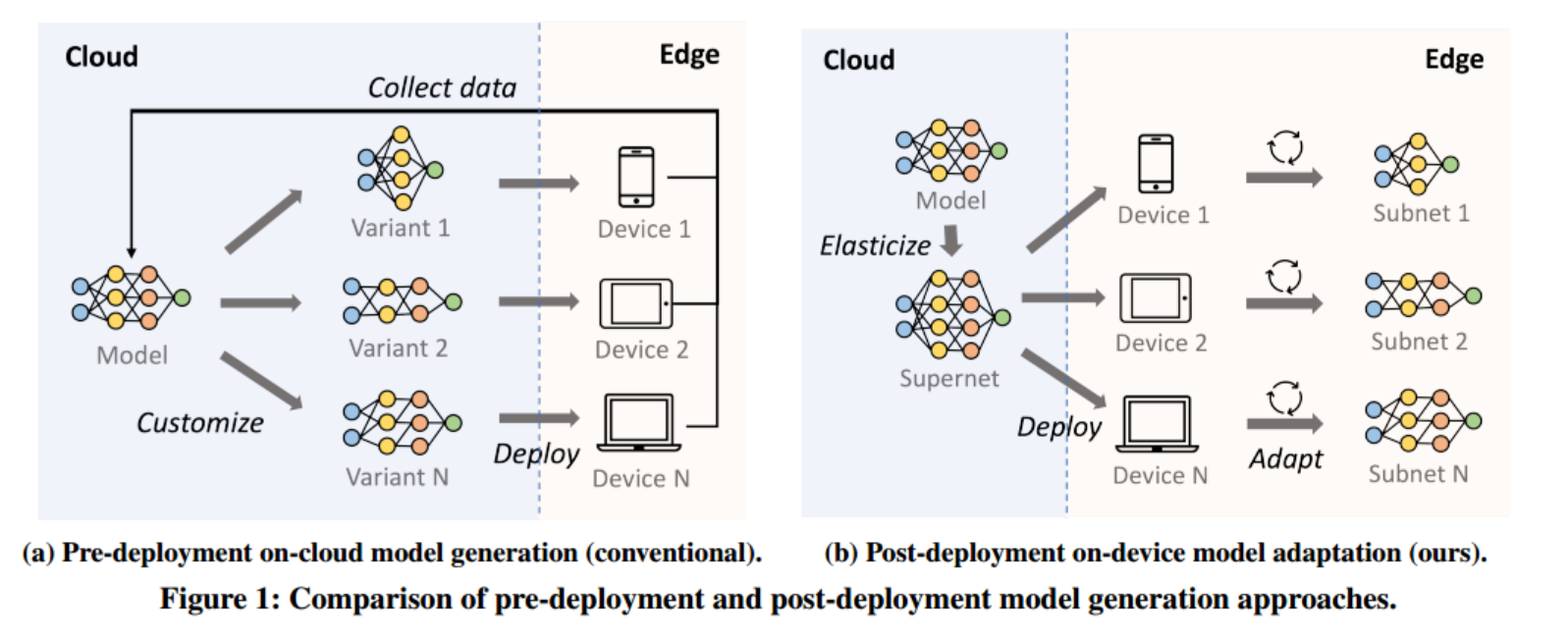
Adaptivenet:作者提出了Adaptivenet,一个端到端系统,通过设备上的后部署神经框架适应器来生成适应不同边缘环境的模型。
首先在利用云上模型弹性化方法,云端生成模型框架的高质量搜索空间,输入预训练模型,在其中添加分支将其转化为多路径超网,确保每条路径都是可用的模型,对并分支进行训练,边缘侧只需要搜索最合适的模型结构,无需训练。
然后,在边缘侧进行模型搜索,在设备上建立性能模型,同时引入一种基于重用的模型评估方法,在候选模型之间缓存中间特征,提高模型搜索和更新的效率。
实验:三种视觉任务:image classification、object detection、semantic segmentation。三种模型:ResNet、MobileNetV2、EfficientNetV2。三种不同计算能力的端设备:Jetson Nano,Xiaomi 12,NVIDIA 2080Ti GPU。Baselins:LegoDNN,FlexDNN,SkipNet,Slimmable Neural Networks。
AdaptiveNet能够显著实现更好的准确性和延迟权衡,与baseline相比在60%的延迟下。实现比平均精度提高46.74%。同时训练开销小,云端13GPU小时,边缘环境2min。
Contribution:1. 提出并发展了部署后神经结构搜索方法、2. 提出了一种预训练辅助的模型弹性化方法。3. 与SOTA baseline相比,实现了更好的准确性-延迟权衡。
2. Backgroud and Motivation
研究现状:有许多方法用于提高端设备上的模型性能:优化边缘设备上的模型推理框架、设计轻量化模型、压缩要部署的模型。
另一个挑战是如何为成千上万个不同计算能力的端设备部署模型,现在常用的方法是在云端自动生成模型并分发到不同端设备,如NAS。
此外,还有一些在边缘环境种缩放模型的方法,如结构化剪枝、动态神经网络(如早期退出技术)。
现今研究的局限性:文章认为基于云端的部署前模型生成方法难以适应环境的多变性,并总结了三种环境多变性:
设备间差异:对生成模型提出挑战

设备动态性差异:对动态维护模型提出挑战
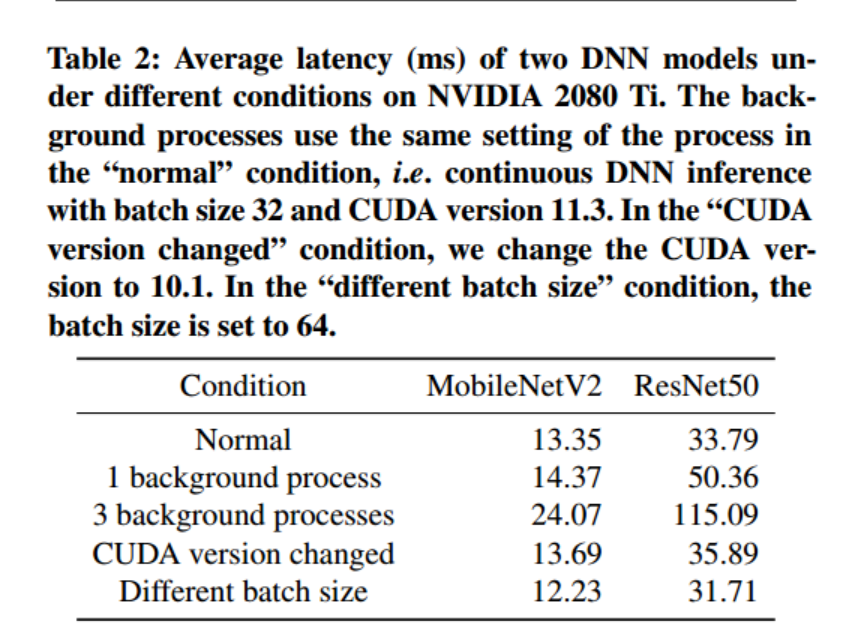
数据分布差异:对于具有数据分布差异的边缘环境,NAS常用的用于评估模型性能的统一精度预测器不能很好的执行。
Goal and Chanllenge:上述局限性也证明了AdaptiveNet的两点优势,一是可以直接在边缘设备上评估模型性能,二是即插即用,不需要从边端向云端收集和传输数据。
同时也带来了两点挑战,一是为边缘环境生成模型搜索空间是困难的,二是在边端上搜索模型结构可能耗费大量时间。
3. AdaptiveNet Overview
超网:包括了模型模块的融合和压缩
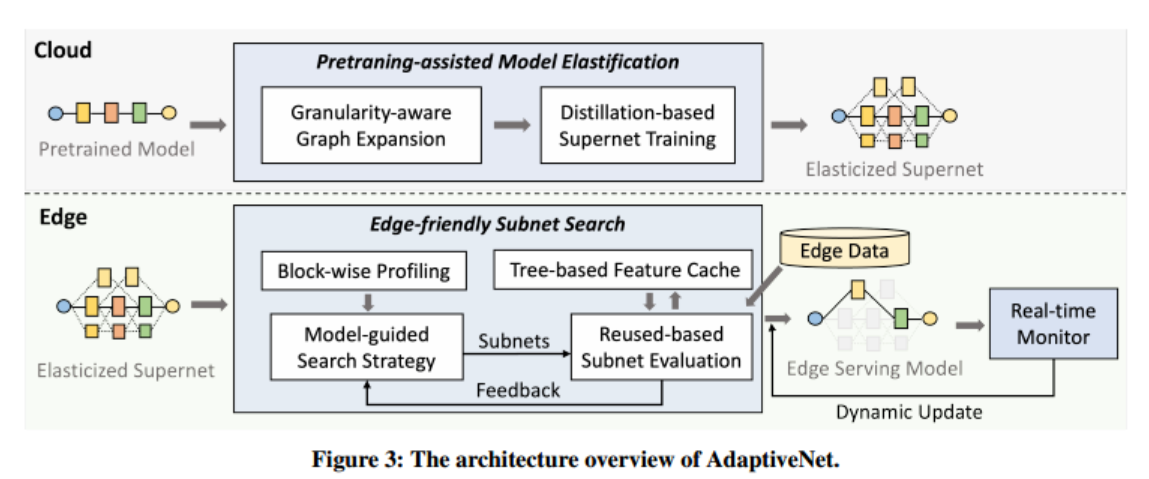
4. Elastification on Cloud
模型弹性化的目标是将输入的预训练模型转化为一个超网(supernet),组成超网的每一个子网都有不通的延迟和准确性性能,以适应不通的端设备。
挑战一:如何生成超网 - Granularity-aware Graph Expansion
将模型切分为基本块Bi(0),对基本快进行一系列的合并(添加合并块替代多个基本块)和收缩(对基本块进行剪枝或量化)。图中灰色为基本快,上半部分超网为合并块,下半部分超网为压缩块。

个人问题:文章这里并没有提怎么对块进行合并,可以用什么方法呢
挑战二:对生成的超网进行训练
需要将超微进行训练,以提高子网的质量,使得子网可以直接在边缘使用,节省设备上重训造成的资源和时间。
整个训练过程包括分支蒸馏阶段和整个模型微调阶段。仅蒸馏将导致次优的最终精度,而世界训练将显著减慢收敛速度。
分支蒸馏阶段:首先冻结基本块Bi(0),从而保留原始预训练模型的准确性。然后,采用基于特征的知识提取,让添加的分支块模仿其相应的原始块。
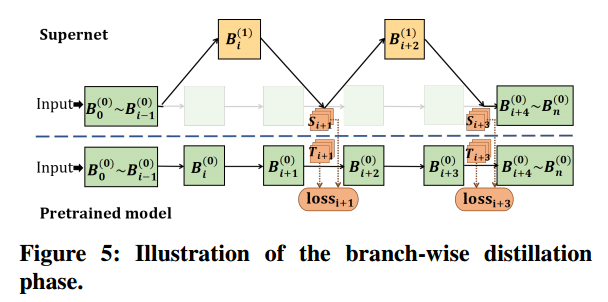
在每次迭代种,从超网随机抽取一个子网,并使用原始模型作为教师模型来训练子网中的新分支,在这个过程中只训练分支块,将基本块作为强监督,因此蒸馏过程是高效且易于收敛的。
全模型微调阶段:使用标记数据进一步微调超网。随机抽取子网Bi(j),计算子网输出和标签之间的交叉熵损失,并更新参数。
5. Adaptation on Edge
端上自适应的目标是通过搜索超网,在边缘环境种自适应地获得最佳架构。主要包括两个步骤,基于延迟模型引导的模型结构搜索和基于重用的模型评估。
基于延迟模型引导的搜索策略:设定延迟预算Tbudget,边缘数据集为Dedge,搜索的目标是找到一个延迟预算内,准确度最高的子网。直接在边缘数据集上测量准确性,并利用延迟模型来计算延迟。
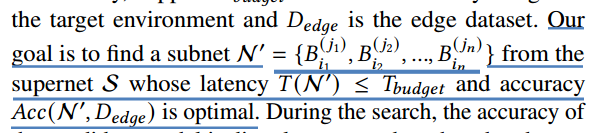
延迟模型:超网组成快Bi(j)在设备上推理延迟的统计表,仅测量单个块的延迟并进行记录,在计算子网总体推理延迟时,对组成子网的组成块的延迟进行加和,可以节省大量测量端设备上推理时延的成本。
子网的搜索过程不是线性遍历的,而是包括了候选初始化和候选突变两个过程。文章设计了两个函数NearbyInit和NearbyMutate,NearInit通过随机采样,找到一组延迟在[Tbudget-▲T,Tbudget+▲T],接下来在每次迭代中,通过替换子网中的分支来随机变异子网,找到减少延迟变化的最佳替代分支。

基于重用的模型评估:共用组成块的子网,可以重用共用部分的中间特征,从而节省计算时间。

但保存大量的中间特征会占用大量内存,因此文章引入了树形结构来保存部分通用特征并最大可能的提高重用率。
叶节点和非叶节点分别表示子网和公共前缀子结构,共享同一父节点的节点,就共用同一个公共前缀结构。在评估过程中,按照深度优先的顺序评估所有子网,可以保证保存的通用特征数量不会超过树的深度。
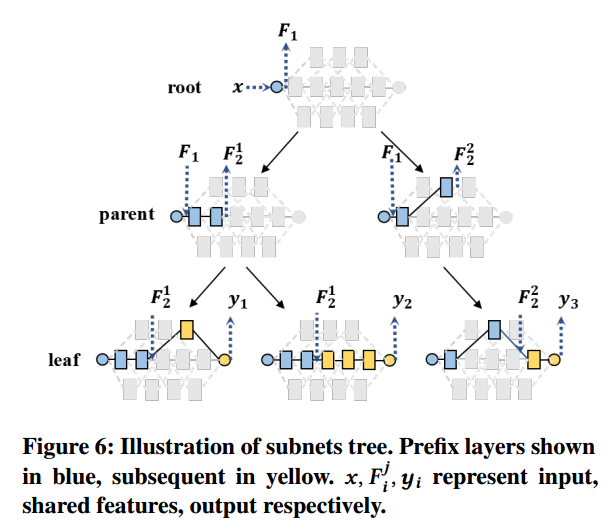
另一个问题是,逐一测试模型,可能会导致数据I/O操作过于频繁,因此,采用批量模型组评估,即加载一批数据并谁用该批评估所有候选子网。
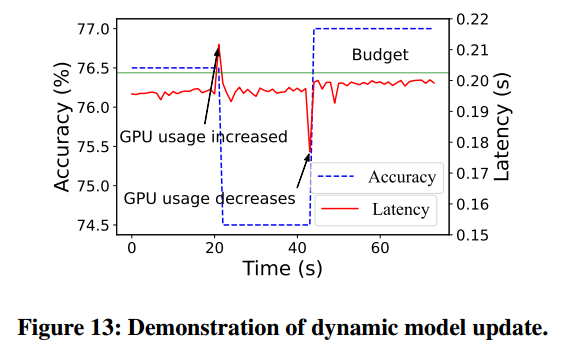
模型的动态更新:搜索到最佳子网后,边缘环境的变化,可能会使子网在运行中变得不再理想。因此AdaptiveNet会在搜索期间组织子网池,保存所有子网的[arch,latency,accuracy],并保存在不同延迟级别下的最佳子网组([Tbudget-▲T,Tbudget+▲T])。
在运行时,运行一个延迟监视器来检测运行模型的延迟变化,当推理延迟超出预算时,延迟监视器会计算延迟缩放比,并在子网池中搜索当前边缘环境中的最佳子网。如果子网池长没有模型符合延迟预算,则重启自适应搜索过程。

6. Implementation
文章中讲解了一些具体的实现细节,这里不做总结,感兴趣的话可以读一读原文。
7. Evaluation
实验配置:
三种视觉任务:image classification( MobileNetV2, ResNet50, ResnNet101 and imageNet2012 Dataset )、object detection( EfficientDet and COCO2017 Dataset )、semantic segmentation( FPN and CamVid Dataset )
三种不同计算能力的端设备:Jetson Nano 4GB memory),Xiaomi 12(Snapdragon 8 Gen 1 CPU and 8GB memory),NVIDIA 3090Ti GPU(24GB GPU memory)
(前面的introduction说的是使用2080Ti的边缘服务器,应该是作者前面写错了。)
Baselins:LegoDNN,FlexDNN,SkipNet,Slimmable Neural Networks
实验结果:
AdaptiveNet在几乎每个延迟预算下都比baseline实现了更高的准确度。
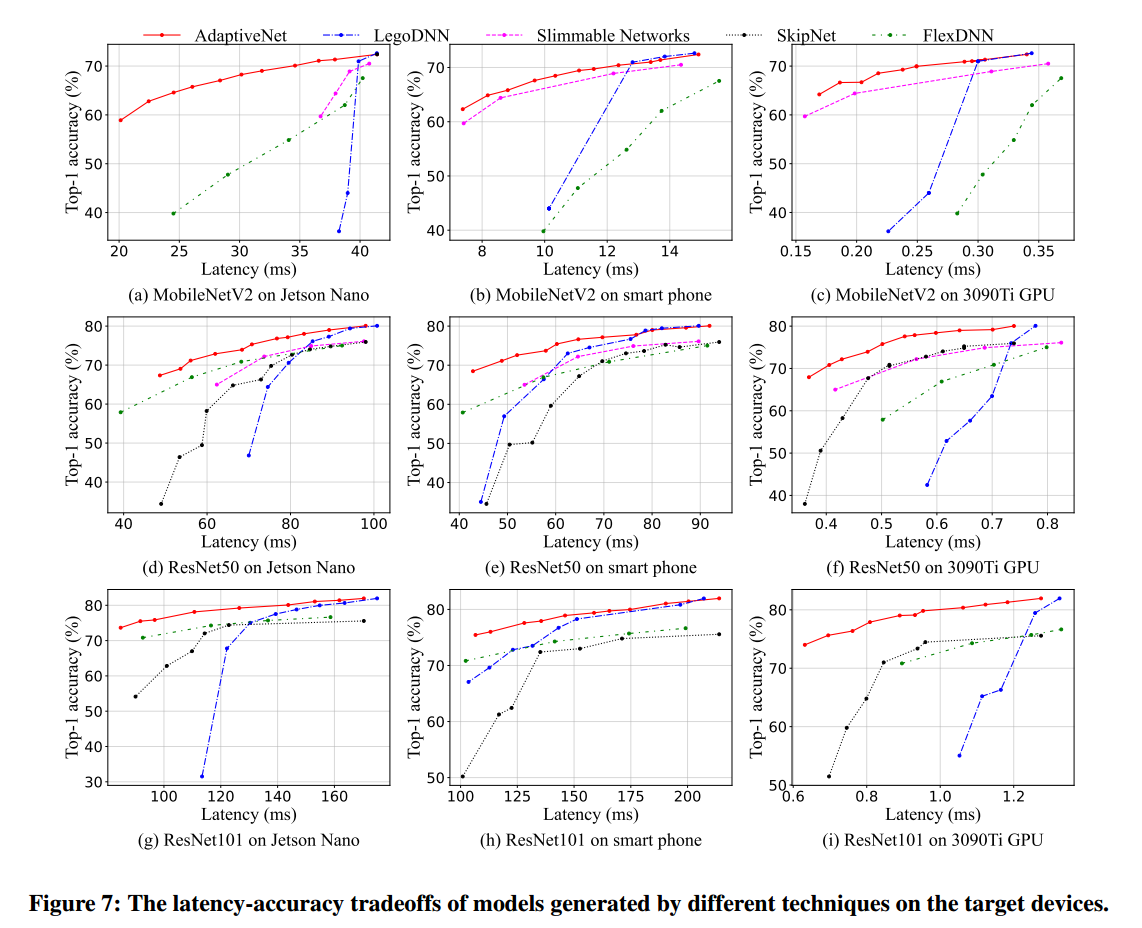
在物体检测和语义分割任务上,AdaptiveNet实现了合理的扩展性能,并优于baseline
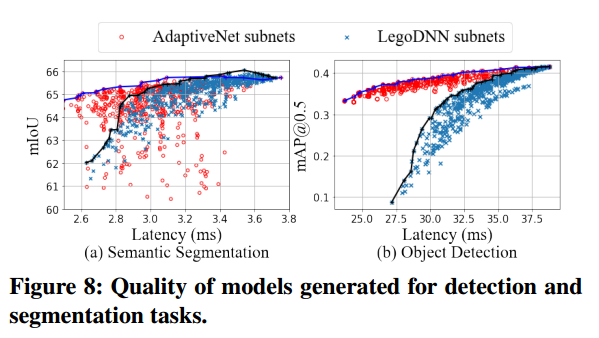
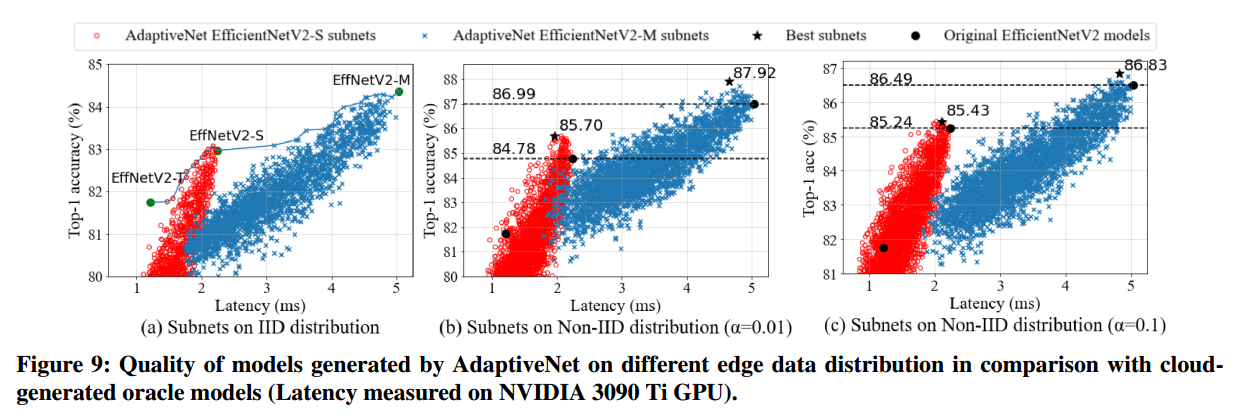
用迪利克雷分布模拟不同边缘数据集上生成模型的质量。
为了证明云上弹性化阶段的效率和有效性,将超网训练方法与直接训练整个超网的方法进行了比较。

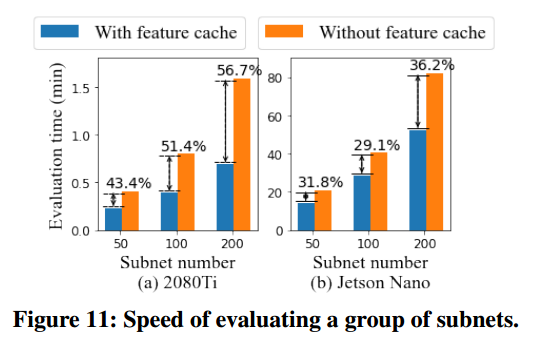
测试了基于重用的模型评估方法的加速百分比
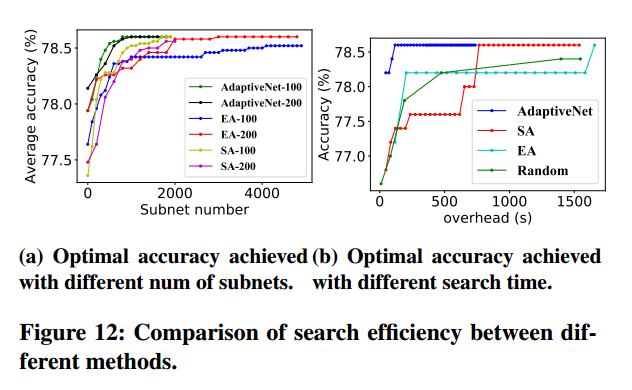
测试了延迟模型引导的模型结构搜索策略的优势
EA:进化算法,SA:退火算法
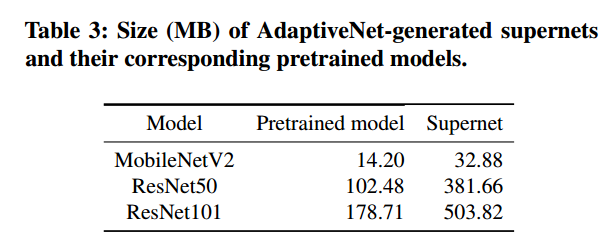
对比AdaptiveNet和预训练模型的大小,超网只比原始预训练模型大1.32-2.72倍
模型动态更新模块的性能
8. Discussion
- 如果边缘环境的数据是无标签的,可以通过查询oracle模型来生成标签。
- AdaptiveNet的想法也可以应用于nlp领域和transformer模型。
- AdpativeNet不需要设备上重训是一大优势,因为重训要求设备部署大量高质量有标签数据。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









