






一、什么是本地缓存,它能解决什么问题
1.概念
缓存涉及的范围很广,如web页面缓存、客户端缓存、数据库缓存、磁盘缓存等。
在后端程序中,缓存主要分为本地缓存和远端缓存,其中:
远端缓存常见的有Redis、MongoDB等,
本地缓存一般区分堆内缓存与堆外缓存
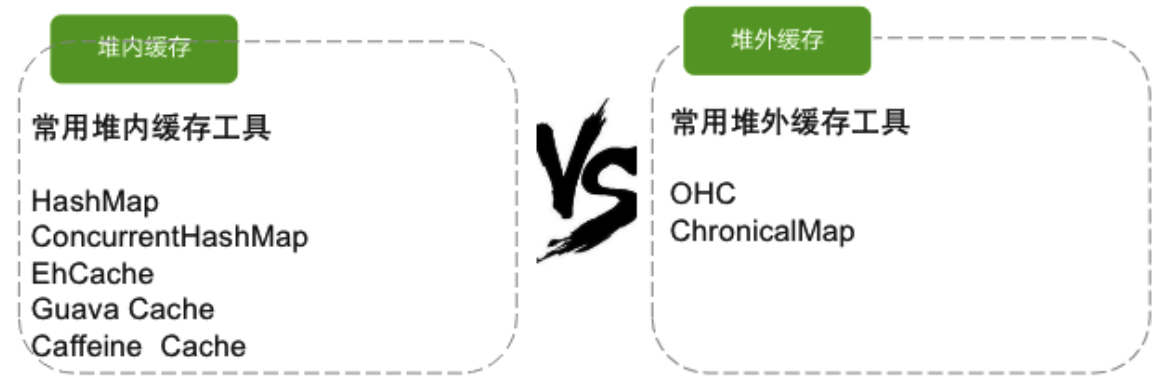
1.1 堆内缓存与堆外缓存
1.1.1 使用场景及特点

1.1.2 常用实现工具
2.本地缓存的优劣
2.1 本地缓存的优势
- 快速读写
- 节省数据库资源
- 减少服务远程网络调用
- 提升服务QPS
2.2 本地缓存的劣势
- 存储容量受JVM内存大小限制
- 影响GC频率
二、设计一款本地缓存
1.本地缓存的特征
1.1 命中率
命中率 = 命中数 / (命中数 + 没有命中数)
命中率越高,缓存的利用率也就越高
1.2 最大空间
1.2.1 定义
缓存中可以容纳最大元素的数量
当缓存存放的数据超过最大空间时,就需要根据淘汰算法来淘汰部分数据,以存放新到达的数据
1.3 淘汰算法
1.3.1 定义
如果缓存满了,而又没有命中缓存,那么就会按照某一种策略,把缓存中的旧对象踢出,而把新的对象加入缓存池。而这些策略统称为替代策略(缓存算法)
1.3.2 分类
一般来说,淘汰算法主要有三种淘汰机制,分别为
- 基于容量淘汰
- 定时淘汰
-
- 按照写入时间,最早写入的最先淘汰
- 按照访问时间,最早访问的最先淘汰
- 基于引用淘汰
1.3.2.1. FIFO (first in first out)
定义:先进先出,按对象进入缓存的顺序来移除它们;常见使用队列Queue来实现
设计思路:
1). 用普通的hashMap保存缓存数据。
2). 需要额外的map用来保存key的过期特性,例子中使用了LinkedHashMap,将“剩余存活时间”作为key,利用LinkedHashMap的排序特性。
代码实现
package com.exam.richard;
import java.util.LinkedHashMap;
import java.util.Map;
/**
* first in first out cache
* @param <K>
* @param <V>
*/
public class FIFOCache<K,V> {
private int size;
private Map<K,V> CACHE = new LinkedHashMap<>();
public FIFOCache(int size){
this.size = size;
}
/**
* 设置缓存
* @param key
* @param value
*/
public void put(K key,V value){
if (CACHE.size() >= size){
// 删除第一个缓存
Map.Entry<K,V> firstCache = CACHE.entrySet().iterator().next();
CACHE.remove(firstCache.getKey());
}
CACHE.put(key,value);
size++;
}
/**
* 查询缓存
* @param key
*/
public V get(K key){
return CACHE.get(key);
}
}
1.3.2.2 LRU (least recently used)
定义:
最近最少使用,移除最长时间不被使用的对象,常见使用LinkedHashMap来实现,多数本地缓存默认策略,每次访问数据都会将其放在我们的队尾,如果需要淘汰数据,就只需要淘汰队首即可
设计思路:
- LRU的基础算法,需要了解;每次put、get时需要更新key对应的访问时间,我们需要一个数据结构能够保存key最近的访问时间且能够排序。
- 既然包含过期时间特性,那么带有过期时间的key需要额外的数据结构保存。
package com.exam.richard;
import java.util.*;
import java.util.concurrent.ConcurrentSkipListMap;
/**
* LRU 算法
* @param <K>
* @param <V>
*/
public class LRUCacheV2 <K,V> {
/**
* 容量
*/
private int size;
/**
* k,v缓存
*/
private Map<K,V> CACHE = new LinkedHashMap<>();
/**
* 过期时间长度
*/
private Map<K,Long> EXPIRED = new HashMap<>();
/**
* k key
* Long put的时候当前时间 + 过期时间
*/
private Map<K,Long> VALID_TIME = new HashMap<>();
/**
* key : put的时候当前时间 + 过期时间
* LinkedHashSet<K> : 过期的这批KEY 的 集合
*/
private Map<Long,LinkedHashSet<K>> EXPIRED_KEYS = new ConcurrentSkipListMap<>();
public LRUCacheV2(int size){
this.size = size;
}
/**
* 带有缓存时间,如果还考虑到并发问题,要加锁
* @param key
* @param value
* @param expired
*/
public void put(K key,V value,Long expired){
if (CACHE.size() > size){
// 超出容量,先删除过期
Long now = System.currentTimeMillis();
for (Long validTime : EXPIRED_KEYS.keySet()) {
if (validTime < now){
// 过期了
LinkedHashSet<K> keys = EXPIRED_KEYS.get(validTime);
for (K validKey : keys){
CACHE.remove(validKey);
EXPIRED.remove(validKey);
VALID_TIME.remove(validKey);
}
}
}
// 再删除最后访问的
if (CACHE.size() > size){
// 还是超了,移除最早访问的
Iterator<Map.Entry<K,V>> iterator = CACHE.entrySet().iterator();
while (iterator.hasNext() && CACHE.size() > size){
Map.Entry<K,V> entry = iterator.next();
K lastKey = entry.getKey();
CACHE.remove(lastKey);
EXPIRED.remove(lastKey);
Long validTime = VALID_TIME.remove(lastKey);
LinkedHashSet<K> lastValidKeys = EXPIRED_KEYS.get(validTime);
if (Objects.nonNull(lastValidKeys)){
lastValidKeys.remove(lastKey);
if (lastValidKeys.size() == 0){
EXPIRED_KEYS.remove(validTime);
}
}
}
}
}
// 假如当前KEY 已存在,先删除EXPIRED_KEYS 里面的值
if (CACHE.containsKey(key)){
// 先移除旧数据,主要是V
Long validTime = VALID_TIME.get(key);
LinkedHashSet<K> keys = EXPIRED_KEYS.get(validTime);
if (Objects.nonNull(keys) && keys.size() > 0){
keys.remove(key);
}
}
// 设置缓存逻辑
CACHE.put(key,value);
EXPIRED.put(key,expired);
Long validTime = System.currentTimeMillis() + expired;
VALID_TIME.put(key,validTime);
LinkedHashSet<K> keys = EXPIRED_KEYS.get(validTime);
if (Objects.isNull(keys)){
keys = new LinkedHashSet<>();
EXPIRED_KEYS.put(validTime,keys);
}
keys.add(key);
size++;
}
/**
* 查询缓存
* @param key
* @return
*/
public V get(K key){
V value = CACHE.get(key);
if (Objects.isNull(value)){
return null;
}
// 判断是否过期
if (System.currentTimeMillis() > VALID_TIME.get(key)){
CACHE.remove(key);
EXPIRED.remove(key);
Long validTIme = VALID_TIME.get(key);
VALID_TIME.remove(key);
LinkedHashSet<K> keys = EXPIRED_KEYS.get(VALID_TIME);
if (keys.size() != 0){
keys.remove(key);
if (keys.isEmpty()){
EXPIRED_KEYS.remove(validTIme);
}
}
return null;
}
/**
* 放到第一位
*/
CACHE.remove(key);
CACHE.put(key,value);
Long expired = EXPIRED.get(key);
Long validTime = VALID_TIME.get(key);
LinkedHashSet<K> keys = EXPIRED_KEYS.get(validTime);
if (Objects.nonNull(keys)){
keys.remove(key);
}
EXPIRED.remove(key);
validTime = System.currentTimeMillis() + expired;
EXPIRED.put(key,validTime);
keys = EXPIRED_KEYS.get(validTime);
if (Objects.isNull(keys)){
keys = new LinkedHashSet<>();
}
keys.add(key);
return value;
}
}
1.3.2.3. LFU (Less frequently used)
定义:最少频率使用,区别于LRU主要在于LRU的淘汰规则是基于访问时间,而LFU是基于访问次数的,利用额外的空间(可通过HashMap)记录每个数据的使用频率,然后选出频率最低进行淘汰。
优点:避免了LRU不能处理时间段的问题
设计思路:
1). 用普通的hashMap保存缓存数据。
2). 需要额外的map用来保存每个key的访问次数。
3). 用TreeMap记录访问相同次数的key列表,以在容量达到阀值时淘汰访问次数最少的key
代码实现
package com.exam.richard;
import java.util.*;
/**
* 最小使用缓存
* @param <K>
* @param <V>
*/
public class LFUCache<K,V> {
/**
* 容量
*/
private int size;
/**
* 存放缓存的ke,value
*/
private Map<K,V> keyToValue = new HashMap<>();
/**
* key使用次数统计
*/
private Map<K,Integer> keyToCount = new HashMap<>();
/**
* 相同使用次数的key统计
*/
private TreeMap<Integer, LinkedHashSet<K>> countToKey = new TreeMap<>();
public LFUCache(int size){
this.size = size;
}
/**
* 查询缓存
* @param key
* @return
*/
public V get(K key){
V value = keyToValue.get(key);
if (Objects.isNull(value)){
return null;
}
// 统计使用次数
Integer count = keyToCount.get(key);
keyToCount.put(key,count + 1);
LinkedHashSet<K> keys = countToKey.get(count);
keys.remove(key);
if (keys.size() == 0){
countToKey.remove(count);
}
LinkedHashSet<K> newCountKeys = countToKey.get(count + 1);
if (Objects.isNull(newCountKeys)){
newCountKeys = new LinkedHashSet<>();
}
newCountKeys.add(key);
countToKey.put(count+1,newCountKeys);
return value;
}
/**
* 缓存计数字
* @param key
*/
private void keyCount(K key){
Integer count = keyToCount.get(key);
if (count == null){
count = 0;
}
keyToCount.put(key,count + 1);
LinkedHashSet<K> keys = countToKey.get(count);
if (Objects.nonNull(keys)){
keys.remove(key);
if (keys.size() == 0){
countToKey.remove(count);
}
}
LinkedHashSet<K> newCountKeys = countToKey.get(count + 1);
if (Objects.isNull(newCountKeys)){
newCountKeys = new LinkedHashSet<>();
}
newCountKeys.add(key);
countToKey.put(count+1,newCountKeys);
}
/**
* 获取缓存
* @param key
* @param value
*/
public void put(K key,V value){
if (keyToValue.containsKey(key)){
keyToValue.put(key,value);
// 计数
keyCount(key);
return;
}
if (keyToValue.size() >= size){
// 删除最少使用的元素
keyToCount.remove(key);
keyToValue.remove(key);
Map.Entry<Integer,LinkedHashSet<K>> countKeys = countToKey.firstEntry();
Integer count = countKeys.getKey();
LinkedHashSet<K> keys = countKeys.getValue();
keys.remove(key);
if (keys.size() == 0){
countToKey.remove(count);
}
}
// 加入新元素
keyToValue.put(key,value);
keyCount(key);
}
}
文章最后,赠送大家一套即可时间后端存储实战 极客时间后端存储实战 - IT资源小站















 446
446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









