







自然语言与人工语言的区别是什么?
自然语言通常是指一种自然地随文化演化的语言。例如,汉语、英语、日语都是自然语言的例子,这一种用法可见于自然语言处理一词中。自然语言是人类交流和思维的主要工具。自然语言是人类智慧的结晶,自然语言处理是人工智能中最为困难的问题之一,而对自然语言处理的研究也是充满魅力和挑战的,也是各国人表达的方法其中之一。
人工语言即"人造语言",为了各种目的,由某些人制造出的语言,其制造者或是致力于世界大同或自由沟通的理想主义者,或是有特殊爱好的作家,也可能是非法或秘密组织的成员。
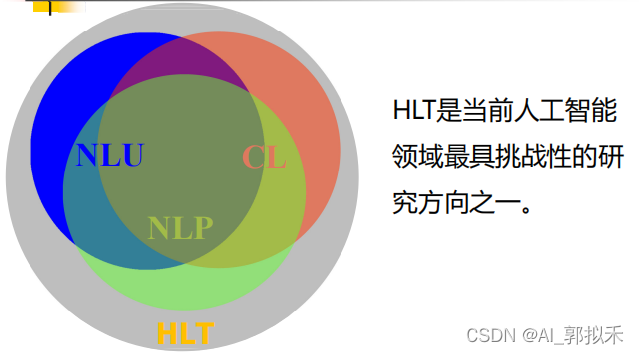
自然语言理解(Natural Language Understanding,NLU)
自然语言理解是探索人类自身语言能力和语言思维活动的本质,研究模仿人类语言认知过程的自然语言处理方法和实现技术的一门学科。它是一门在语言学、计算机科学、认知科学、信息论和数学等多学科基础上形成的交叉学科。其更偏重于对语言认知和理解过程等方面的问题的研究。
图灵(Turing)测试
指测试者与被测试者(一个人和一台机器)隔开的情况下,通过一些装置(如键盘)向被测试者随意提问。进行多次测试后,如果机器让平均每个参与者做出超过30%的误判,那么这台机器就通过了测试,并被认为具有人类智能。
自然语言处理(Natural Language Processing, NLP)
自然语言处理是研究如何利用计算机技术对语言文本(句子、篇章或话语等)进行处理和加工的一门学科,研究内容包括对词法、句法、语义和语用等信息的识别、分类、提取、转换和生成等各种处理方法和实现技术。
计算语言学(Computational Linguistics)
其包括以语音为主要研究对象的语音学基础机器语音处理技术研究和以词汇、句子、话语或语篇及其词法、句法、语义和语用等相关信息为主要研究对象的处理技术研究。计算语言学更加侧重计算方法和语言学理论的研究。
人类语言技术(Human Language Technology,HLT)
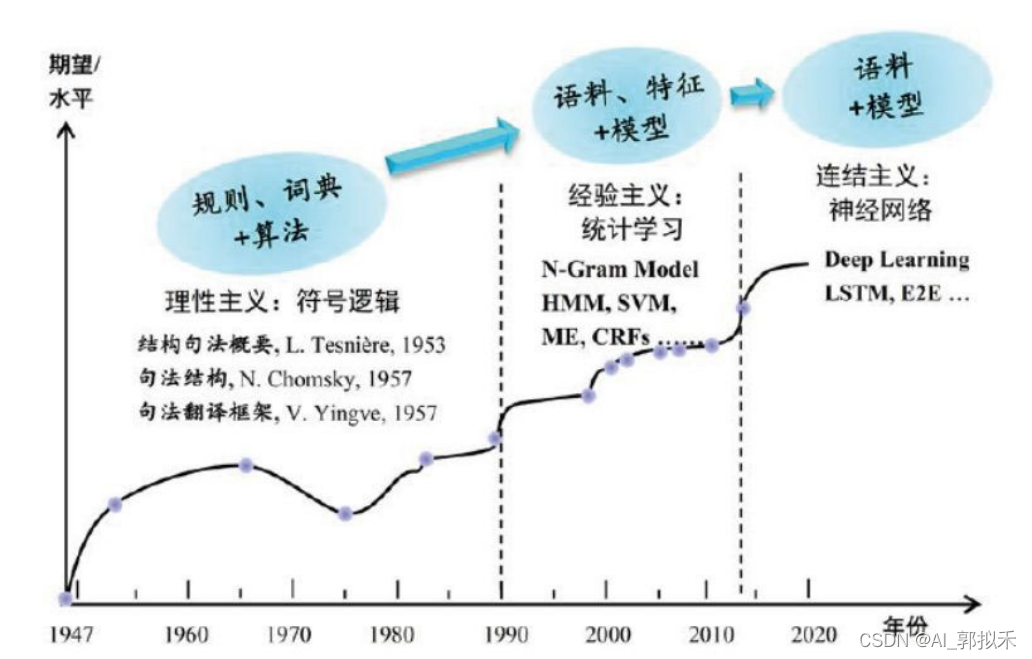
NLP经历的三个阶段
研究内容
- 机器翻译(Machine translation, MT):实现一种语言到另一种语言的自动翻译。
- 信息检索(Information retrieval):信息检索也称情报检索,就是利用计算机系统从大量文档中找到符合用户需要的相关信息。
- 自动文摘(Automatic summarization l Automaticabstracting):将原文档的主要内容或某方面的信息自动提取出来,并形成原文档的摘要或缩写。
- 问答系统(Question-answering system):通过计算机系统对人提出的问题的理解,利用自动推理等手段,在有关知识资源中自动求解答案并做出相应的回答。问答技术有时与语音技术和多模态输入/输出技术,以及人机交互技术等相结合,构成人机对话系统(man-computer dialogue system)。
- 信息过滤(Information filtering):通过计算机系统自动识别和过滤那些满足特定条件的文档信息。
- 信息抽取(Information extraction):从指定文档中或者海量文本中抽取出用户感兴趣的信息。
- 文档分类(Document categorization):文档分类也叫文本自动分类(Text categorization lclassification)或信息分类(Information categorization /classification),其目的就是利用计算机系统对大量的档按照一定的分类标准(例如,根据主题或内容划等)实现自动归类。
- 情感分类(Sentimental classification):应用:图书管理、情报获取、网络内容监控等。
- 文语转换/语音合成(text-to-speech synthesis):将书面文本自动转换成对应的语音表征。应用:朗读系统、人机语音接口等等。
- 说话人识别/认同/验证(speaker recognition/identification/ verification):对一言语样品做声学分析,依此推断(确定或验证)说话人的身份。
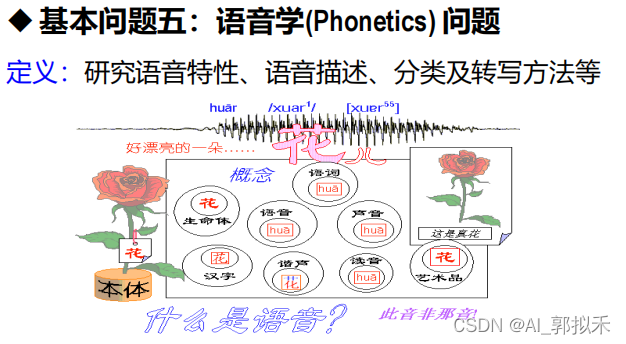
基本问题




困难和挑战
困难一:大量歧义(ambiguity)现象
困难二:大量未知语言现象
归纳起来,NLU所面临的挑战:
- 普遍存在的不确定性(消除歧义):词法、句法、语义、语用和语音各个层面
- 未知语言现象的不可预测性:新的词汇、新的术语、新的语义和语法无处不在
- 始终面临的数据不充分性:有限的语言集合永远无法涵盖开放的语言现象
- 语言知识表达的复杂性:语义知识的模糊性和错综复杂的关联性难以用常规方法有效地描述,为语义计算带来了极大的困难
基本研究方法




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











