







 文章详细介绍了Self-attention机制的工作原理,包括计算向量的相关性、矩阵乘法的并行化优势、Softmax的归一化处理,以及在大型输入(如dk较大)时为何要除以根号dk以稳定梯度。此外,还提到了多头自注意力(Multi-headSelf-attention)用于学习不同类型的关联性,并通过PositionalEncoding引入序列位置信息。
文章详细介绍了Self-attention机制的工作原理,包括计算向量的相关性、矩阵乘法的并行化优势、Softmax的归一化处理,以及在大型输入(如dk较大)时为何要除以根号dk以稳定梯度。此外,还提到了多头自注意力(Multi-headSelf-attention)用于学习不同类型的关联性,并通过PositionalEncoding引入序列位置信息。
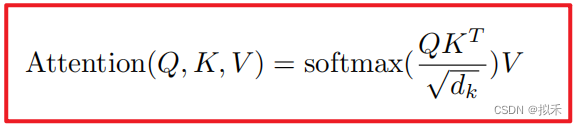
在实践中,我们同时计算一组query上的注意力函数,它们被打包成一个矩阵Q。键和值也被打包成矩阵K和V。我们计算输出的矩阵的数学公式如上。
1 Self-attention🙉
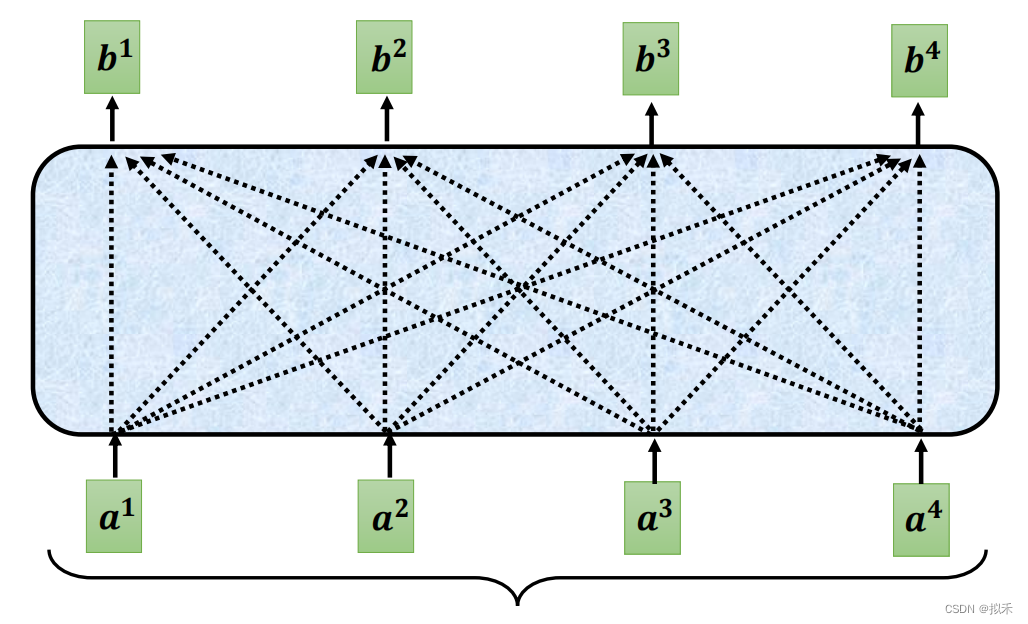
- 上图中a1、a2、a3、a4是sequence中的四个向量,通常是由Word Embedding生成的vector,b1、b2、b3、b4是通过自注意力机制计算出的结果向量。
- 下面我们以b1的计算过程为例吧。
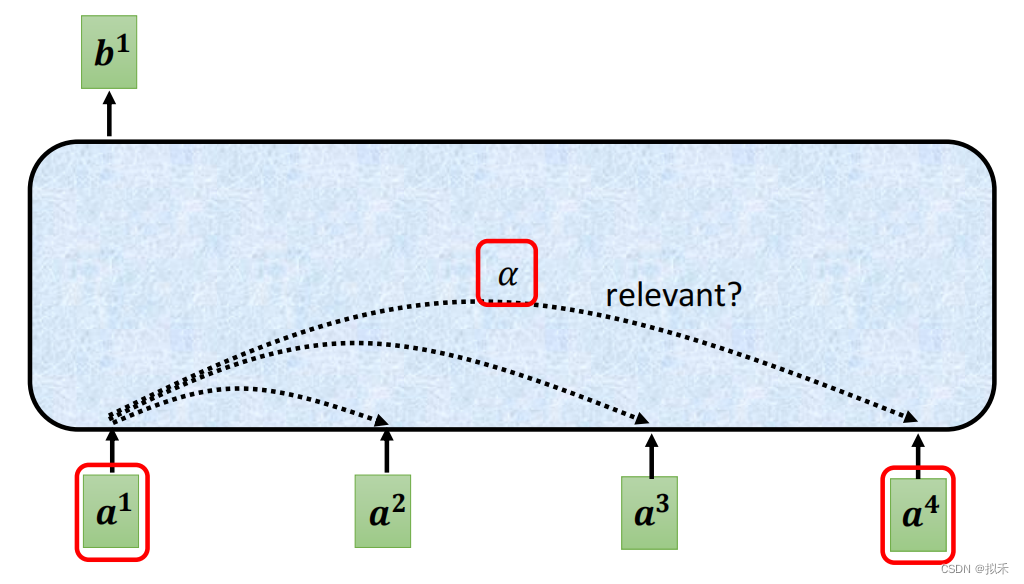
我们要设法找到a1和a2、a3、a4的相关性。
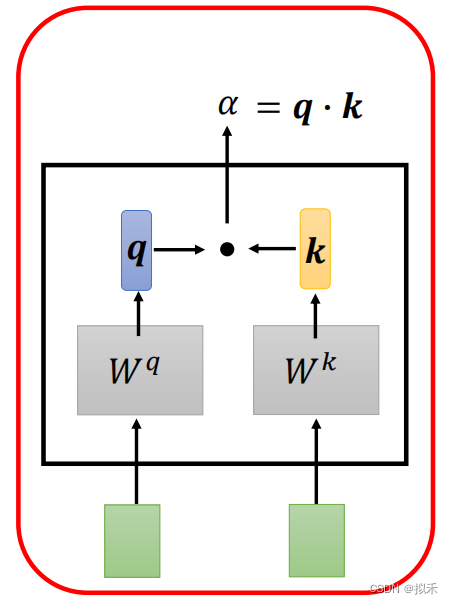
- 如何计算两个向量vector的相关性呢,如上图所示,sequence中的两个vector。
- 其中一个vector乘上一个Wq矩阵形成vector q。
- 另一个vector乘上一个Wk矩阵形成vector k。
- 最后q和k做dot product(也就是向量内积)形成一个scalar(标量),就是一个数字啦,即为attention score(注意力分数)。
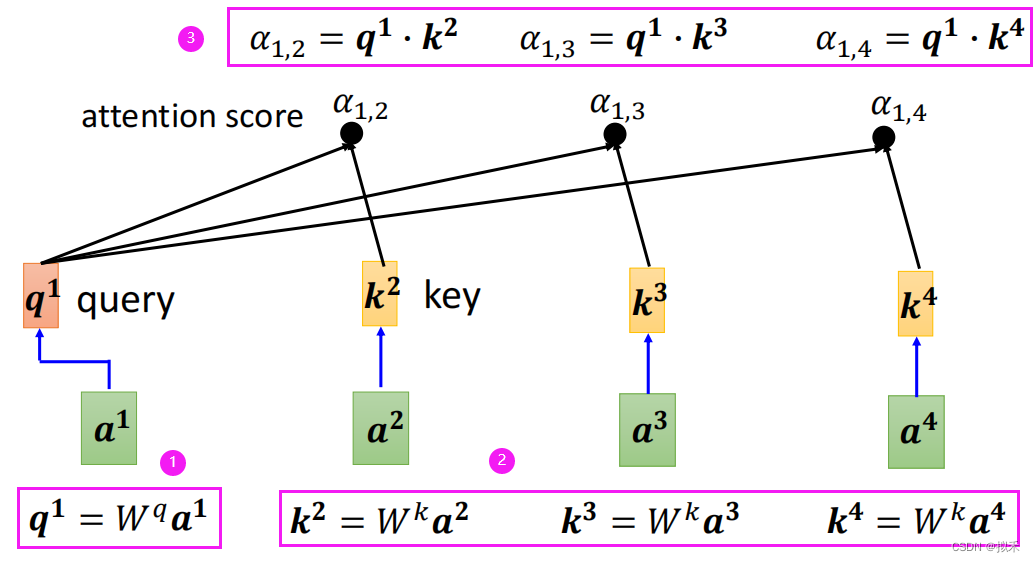
- 这样我们就可以分别计算a1和a2、a3、a4的相关性了,如上图所示,步骤和刚刚介绍的一样。
- 有同学可能疑惑为什么向量内积的结果可以用作描述两个向量的相关性呢?
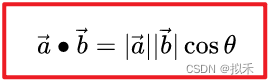
- 如上图所示是两个向量内积的公式,结果一定是一个数,我们可以根据这个数的大小描述向量间的空间位置关系。
- 这个数越大,证明夹角就小,距离就较"近",相似度就高,相反,两个向量的夹角大,距离就"远"。相似度就低,如下图所示。
- 这里感兴趣的同学可以看看这篇博客:余弦定理和新闻分类
- 当然a1也要计算自己和自己的相关性,如下图所示。
- 这样通过上面的操作,我们得到了a1和a2、a3、a4,以及和自己的相关性了。
- 然后通过Softmax对四个scalar进行归一化处理。
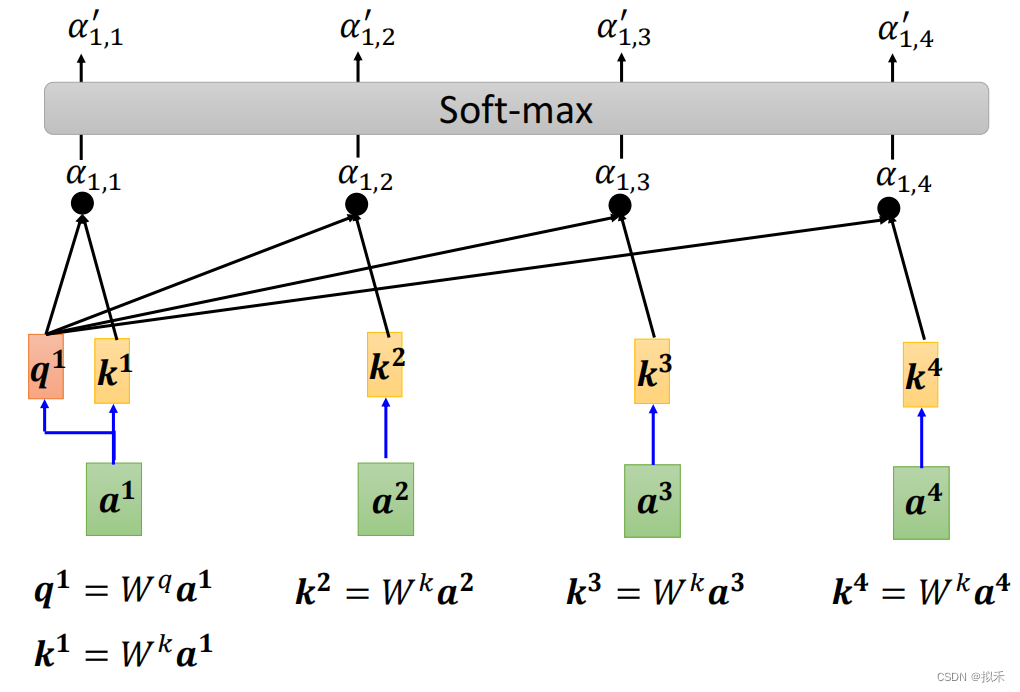
- 最后一步就是Weighted sum(加权就和),去下图所示。
- 根据注意力分数提取信息。
- 首先每个vector都乘上一个Wv矩阵形成vector v,也就是v1、v2、v3、v4。
- 然后vector v乘以各自的attention score后进行向量求和得到小可爱vector b1。
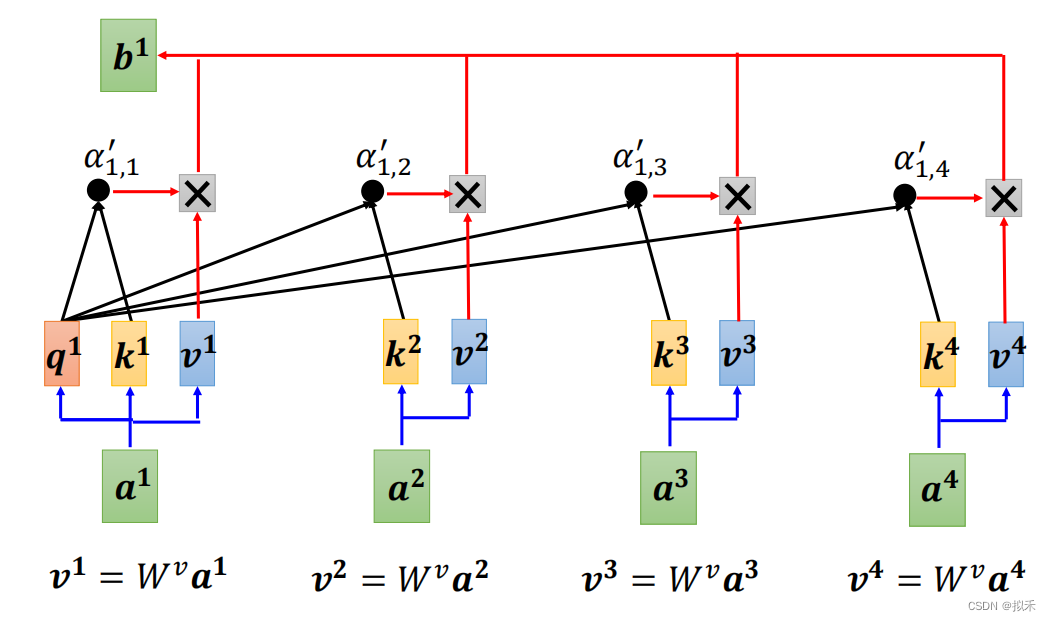
同理可以计算vector b2、b3、b4。
2 Matrix multiplication🐰
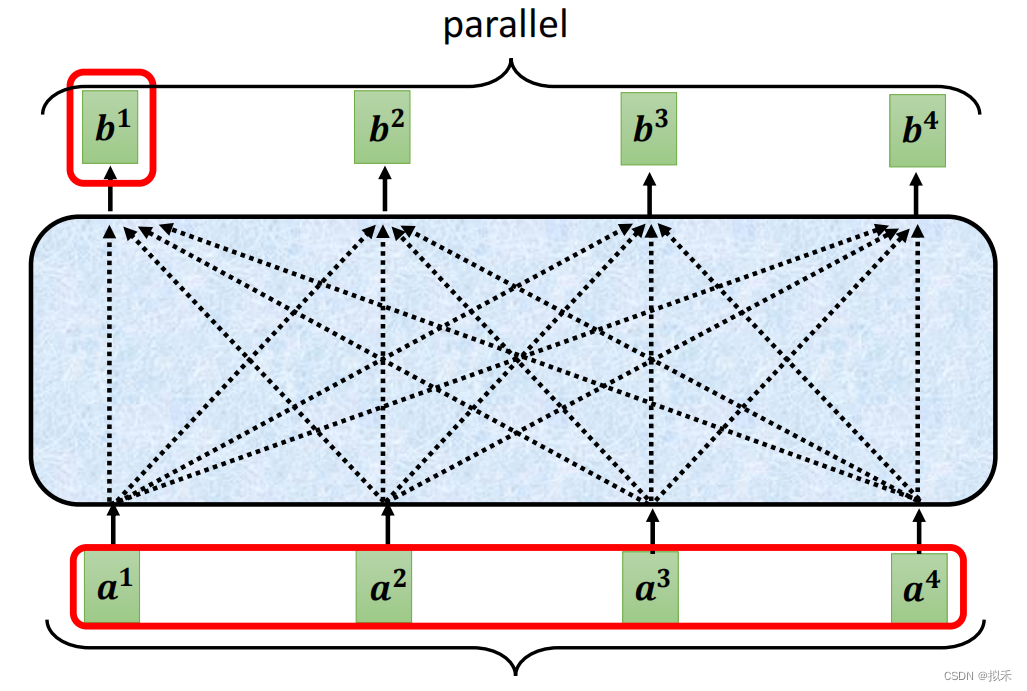
- 显示,b1、b2、b3、b4是可以同时计算的,也就是可以并行化计算得到。
- 这也是Self-attention的优势之一,显著优于循环神经网络RNN的串行化运行过程。
- 当然计算机不会傻到每次都计算一个vector b,而是会利用矩阵乘法同时计算多个vector b,讲究的就是一个高效。
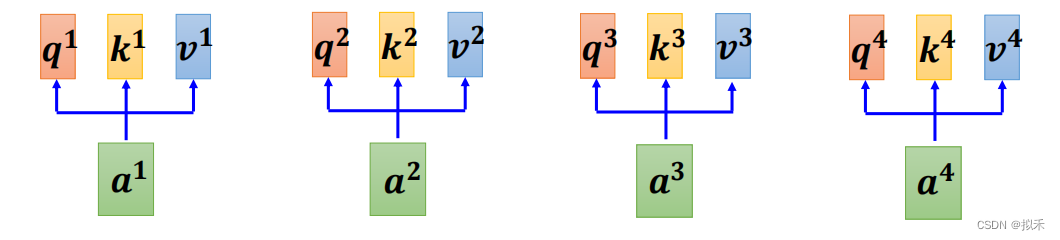
我们知道每一个input vector都会通过矩阵计算得到自己的vector q、k、v,如上图所示。
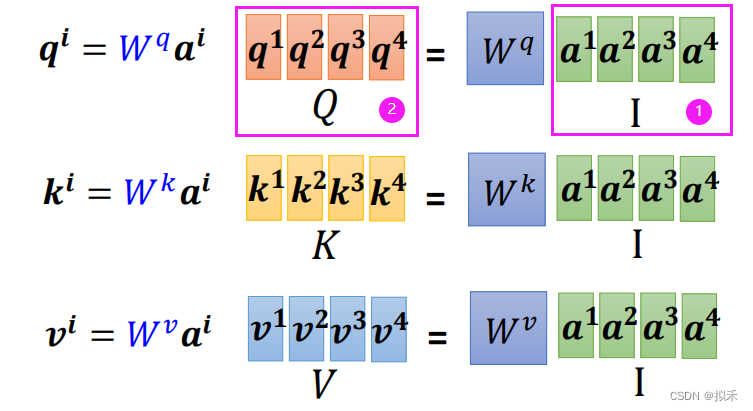
- 如上图所示,我们考虑吧input vector合并成一个矩阵。
- 分别和矩阵Wq、Wk、Wv进行矩阵乘法得到矩阵Q、K、V。
- Q矩阵中的每一列都是input vector的q,以此类推啦。
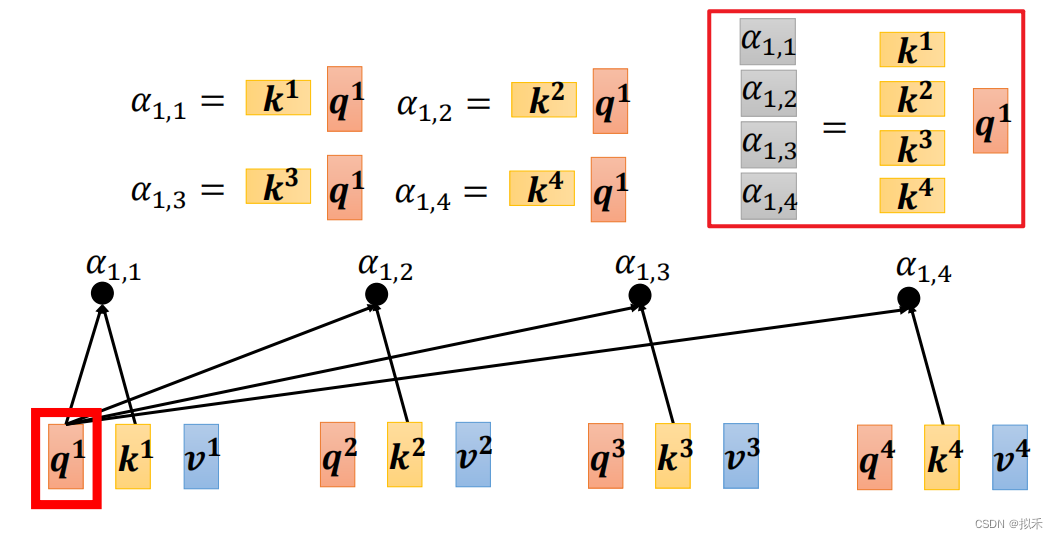
- 如何计算attention score呢,由上可知,attention score是vector q和k的向量内积得来。
- 所以我们考虑把所有的vector k合并成一个矩阵,也就是上面计算得到的矩阵K。
- 把所有的vector q合并成一个矩阵,也就是上面计算得到的矩阵Q。
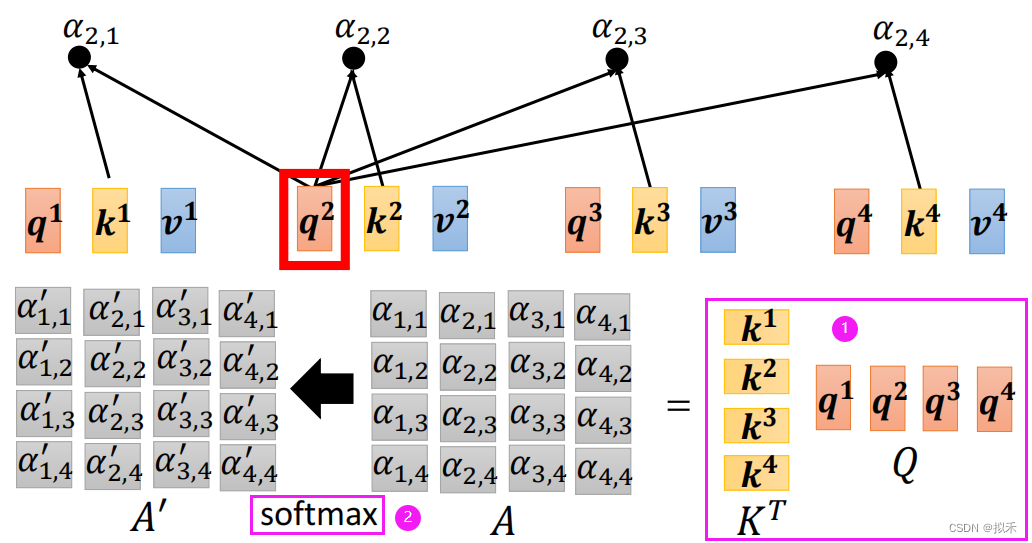
- 再由下图所示,把矩阵K进行transpose(转置),和矩阵Q进行乘法运算。
- 对得到的结果矩阵的每一列单独进行Softmax处理进而得出最终的注意力分数所构成的矩阵。
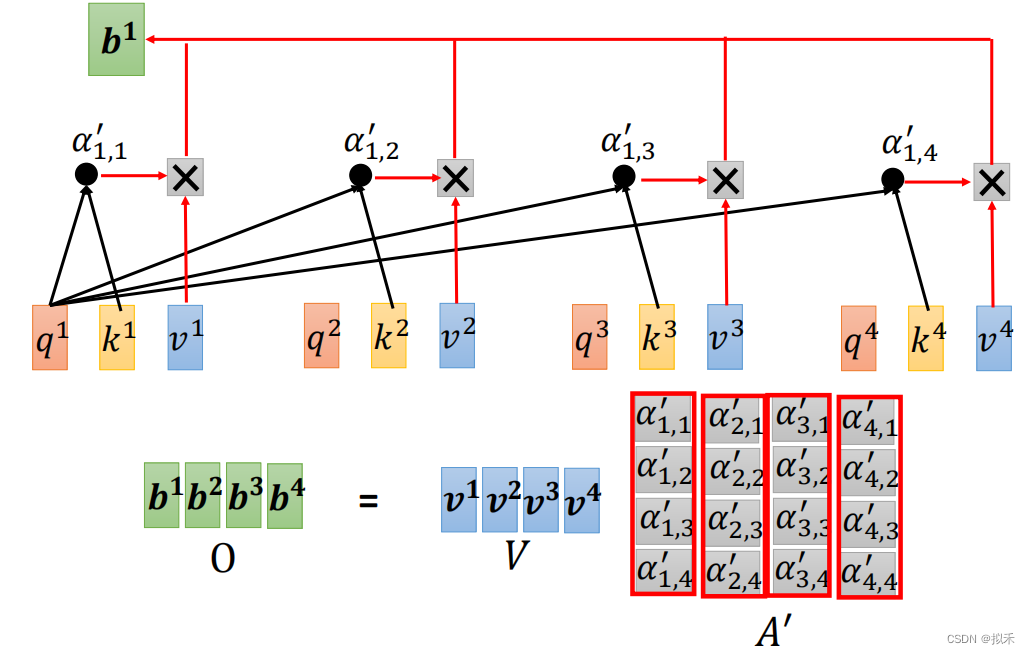
- 最后进行的就是加权平均。
- 把所有的vector v合并成一个矩阵,也就是之前计算得到的矩阵V。
- 与上面求得的注意力分数矩阵做乘积运算,最后得到的结果就是我们想要的vector b所构成的矩阵。
Tips:上述的矩阵乘法运算可以多多利用分块矩阵进行分析哈~
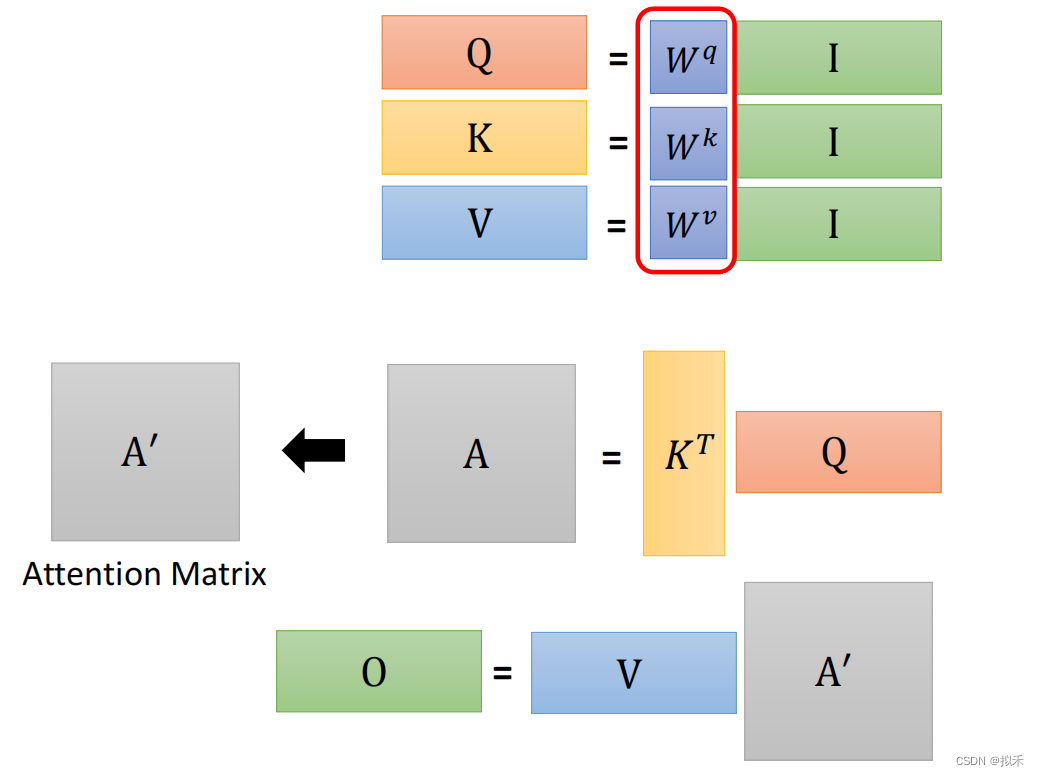
- 综上,Self-attention的计算流程可以抽象为上述步骤。
- 其中的矩阵Wq、Wk、Wv其实是一组参数,通过反向传播自动更新,也就是模型需要学习的地方。
- 我们似乎忘记了一个东西(⊙﹏⊙)
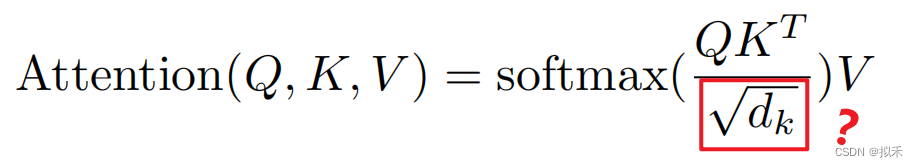
- 这是干啥的?
- 其中dk就是input vector的长度,当dk不是很大的时候,其实除不除这个都没关系。但是当你的dk比较大的时候,比如等于512的情况下,两个向量的内积的绝对值就会比较大。当你的值相对比较大的时候,值之间的相对差距就会变大,就导致你值最大的那一个值做softmax就会更加靠近于1,剩下的那些值就会更加靠近于0,你的值就更会向两端靠拢,这种情况下,计算梯度时,发现梯度会比较小,因为softmax的结果就是希望置信的结果更靠近于1,不置信结果更靠近于0,这样会导致模型误以为模型收敛的差不多了,这时候梯度就会变得比较小,那你就跑不动了,所以在dk比较大的情况下,除以根号dk是一个不错的选择。
- 一句话来说就是:使得训练过程中梯度值保持稳定。
3 Multi-head Self-attention🐠
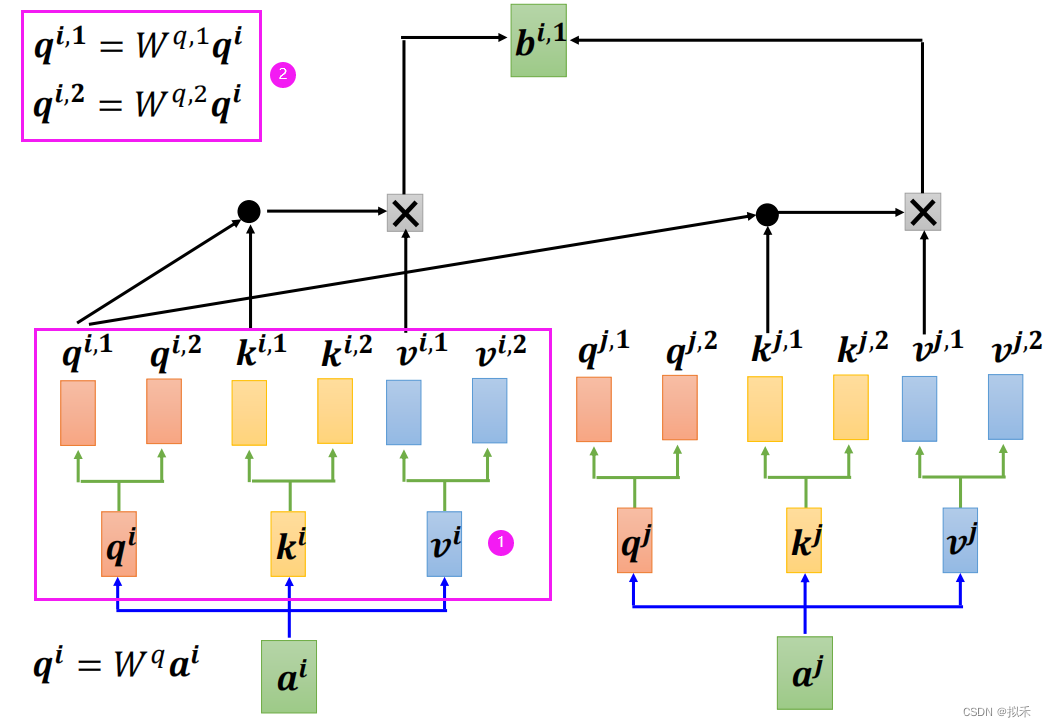
- 为了学习不同类型的相关性,提出了多头自注意力模型,我们以head = 2为例,如上图所示。
- qi分别乘以矩阵Wq1、Wq2形成vector qi1、qi2,依此类推。
- 这样我们就有了两组Q、K、V矩阵。
- 然后分别各组单独进行计算得到vector bi1、bi2,进行合并。
- 最后可以通过一个线性层得到vector bi,如下图所示。
4 Positional Encoding🐋
- No position information in self-attention.(没有位置信息)
- Each position has a unique positional vector ei.(那就设置位置向量)
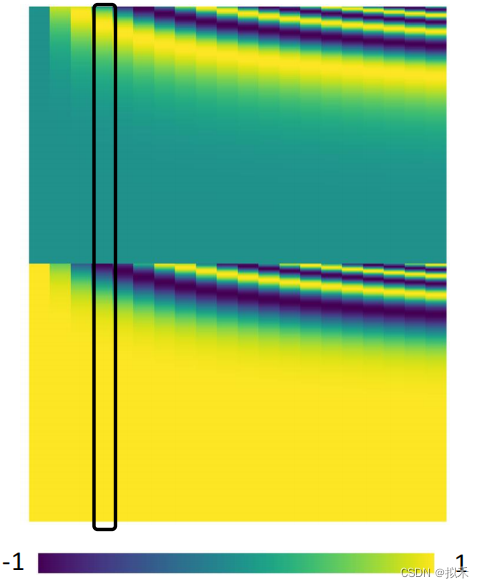
每一列表示一个位置向量。
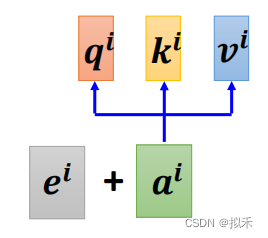
和input vector进行相加就好啦。
















 1512
1512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











