






关键字: [Amazon Web Services re:Invent 2023, State Services, Iterate Faster, Security Risk, Business Risk, Deployment Options, Immutable Infrastructure, Mutable Infrastructure, Managed Services, Standalone Containers, Configuration Management]
本文字数: 1500, 阅读完需: 8 分钟
视频
如视频不能正常播放,请前往bilibili观看本视频。>> https://www.bilibili.com/video/BV1AN411j7FW
导读
Netflix 一直以来都是通过 "不可变基础设施 "将不断变化的软件与不断变化的硬件结合在一起,但这对于需要在不丢失其宝贵状态的情况下快速迭代软件和配置的有状态服务来说并不是最佳选择。为了将有状态机群的内核、基础软件、配置和用户软件变更的部署时间从几个月缩短到几分钟,Netflix 计算和数据平台团队建立了 "有状态计算平台"。在本论坛中,我们将了解如何通过组合软件和先进的状态管理技术来实现数量级更快的机群升级。
演讲精华
以下是小编为您整理的本次演讲的精华,共1200字,阅读时间大约是6分钟。如果您想进一步了解演讲内容或者观看演讲全文,请观看演讲完整视频或者下面的演讲原文。
演讲主要围绕着云计算中具有状态服务的快速迭代这一重要话题展开。演讲者解释道,与诸如Web应用程序之类的无状态服务不同,具有状态的服务类似于数据库系统,会随着时间维护状态或数据。演讲者强调,具有状态的工作负载非常特殊,因为状态或数据本身是关键组件,而不仅仅是软件。数据的巨大重要性使得具有状态的工作负载在部署和升级方面比无状态服务更具挑战性。
演讲者强调了能够快速在具有状态服务上进行迭代和创新的重要性,并提出几个令人信服的理由:
首先且最重要的原因是缓解安全风险。演讲者以2021年底针对Log4j等漏洞的紧急需求为例,展示了快速部署安全补丁和加强环境的能力对于安全的重要性。
其次,无法快速迭代可能会阻碍新产品和服务的创新速度,这些产品和服务需要为其定制的数据存储系统。演讲者以Netflix推出游戏等新产品和服务为例,展示了一旦需要快速迭代具有状态服务以满足新举措的加速开发时间表,这些产品的成功。
最后,频繁的部署锻炼了适应不可避免失败所需的机制。混沌工程原则同样适用——如果某个过程痛苦,那就更频繁地练习。具有状态服务的频繁受控部署使组织在面对意外中断时更加有弹性。
演讲者随后提供一个示例时间线,展示了Netflix的有状态服务部署架构如何在过去十多年里随着其风险承受能力的变化和对迭代速度的需求而演变:
-
起初,Netflix在自己的数据中心完全运行自己的基础设施。在2008年的那次重大故障导致DVD发货中断数天后,Netflix决定将业务迁移至亚马逊云科技。
-
在2009-2010年期间,Netflix首先将其Web和移动应用程序等无状态服务迁移至亚马逊云科技。然而,在此后的两年时间里,具有状态的数据库和服务仍留在现场。
-
在2010年,Netflix开始将其部分服务(如SimpleDB)迁移至亚马逊云科技。经过大约一年的学习和实践后,他们决定在自己的亚马逊云科技上运行基于Cassandra的NoSQL数据库集群。
-
起初,Netflix采用可变基础设施方法部署Cassandra,通过软件包更新就地更新EC2实例。然而,在经过多年痛苦的中断后,他们最终转向了不可变基础设施以提高可靠性。
-
2018年,Netflix引入了"AMI闪存"技术,即在部署新AMI的同时替换EC2实例的根卷,同时保留外部EBS数据卷。这使得他们的状态服务得以实现不可变基础设施,从而提高了稳定性。
-
近年来,Netflix已经开始利用在EC2实例上运行的独立Kubernetes(K8s)容器,以享受容器化带来的优势,同时保持不可变基础设施。状态数据仍存储在附接到EC2实例的EBS卷上。
过去十年的演变展示了Netflix如何根据自身经验和外部环境调整其风险承受能力和迭代速度,从而实现了逐步的架构变革。演讲者强调了让观众能够做出明智权衡的能力,以便选择适合自己独特环境和需求的方法。
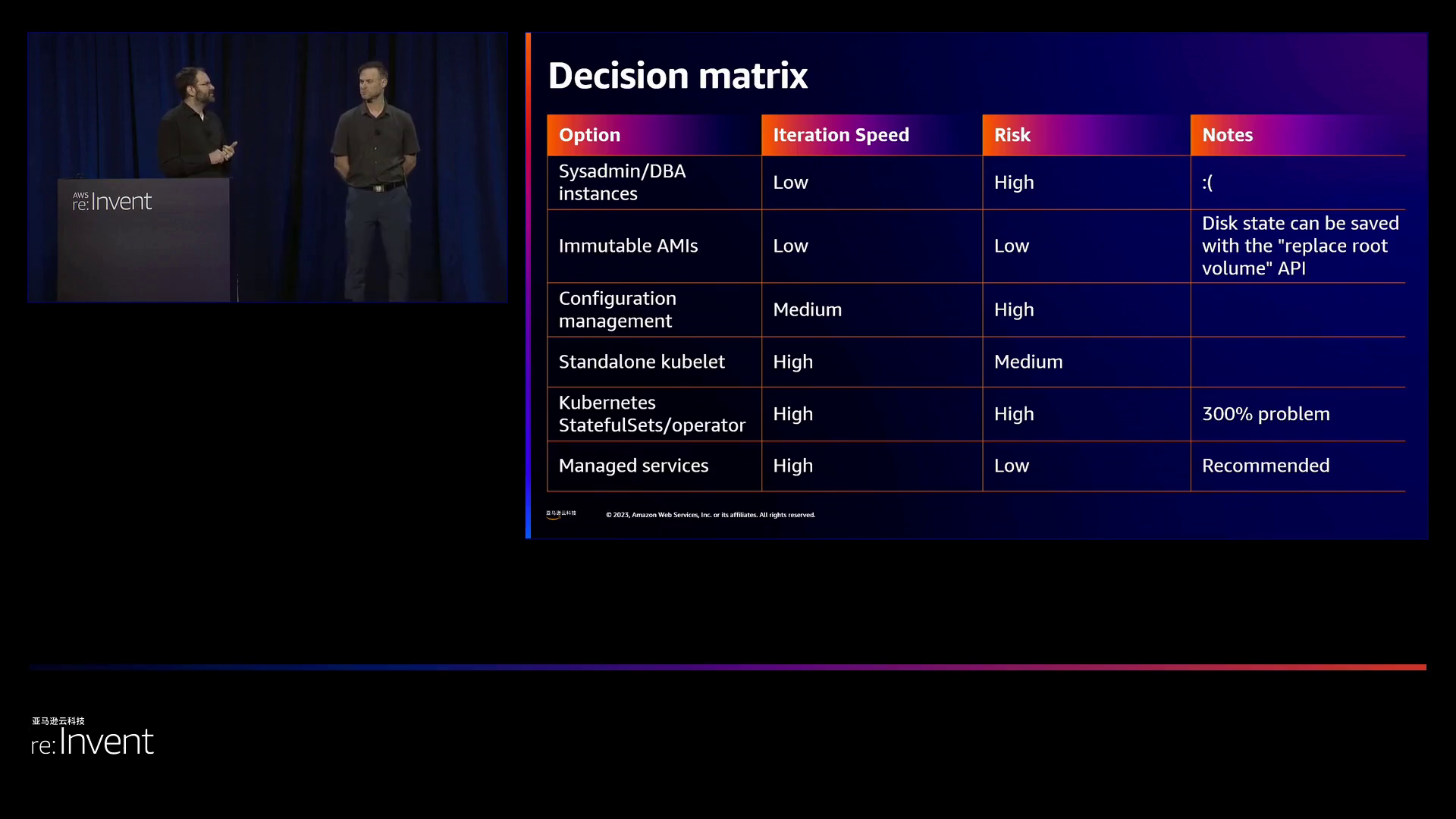
接下来,演讲者系统性地探讨了部署状态服务的几种方案:
-
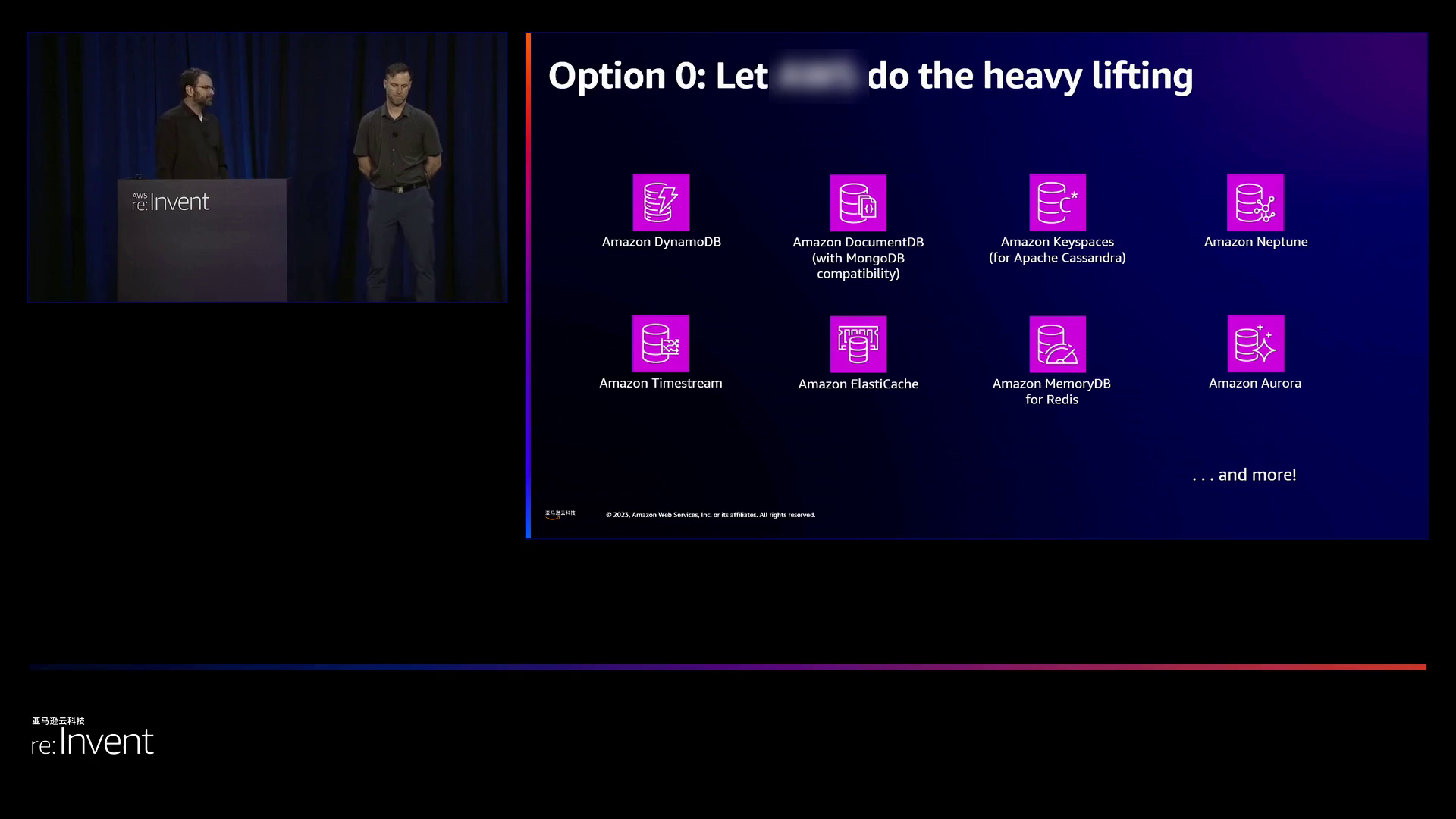
方案0:尽量使用完全托管的服务,如亚马逊云科技的RDS,以避免自己管理复杂的部署和集群协调。
-
方案1:使用Puppet、Chef、Ansible等配置管理工具。演讲者建议避免使用这种复杂且脆弱的方法。
-
方案2:使用原生EC2 API调用替换根卷。演讲者认为这是一种被低估但有效的方法,值得深入研究。
-
方案3:使用Kubernetes和EKS。虽然允许快速迭代,但演讲者指出,由于需要深入的Kubernetes专业知识,这选择了巨大的复杂性。对于大多数状态工作负载来说,这不是理想的选择。
-
方案4:在EC2上使用独立的K8s容器。这种混合模型利用了容器的优点,同时限制了K8s的复杂性。这是Netflix目前根据自己的需求所选择的首选方法。
演讲者随后现场演示了选项4,展示了如何快速更新Java sidecar容器和底层EC2 AMI,以应用关键的Log4j安全修复程序。具体而言,演示内容包括:
- 在Priam sidecar代理的Dockerfile中更新包含查找和替换命令,以便从Log4j核心JAR文件中剥离脆弱的Log4j代码。
- 将更改推送至CI/CD,从而触发新的Docker镜像构建。在几秒钟内,该管道将更新后的镜像发布到Docker注册表。
- 使用Spinnaker作为模拟控制面,抓取新的Priam容器的不可变SHA摘要并更新Kubernetes pod规格。
- 在EC2实例上,这触发kubelet拉取新的Priam映像并以固定的容器重启pod。
- 创建一个新的Debian包来注入一个环境变量,以在操作系统级别全局禁用Log4j漏洞代码路径。
- 使用新的AMI烘焙Debian包更改大约需要7分钟。
- 使用EC2控制台替换根卷并使用新的加固AMI重新启动实例。
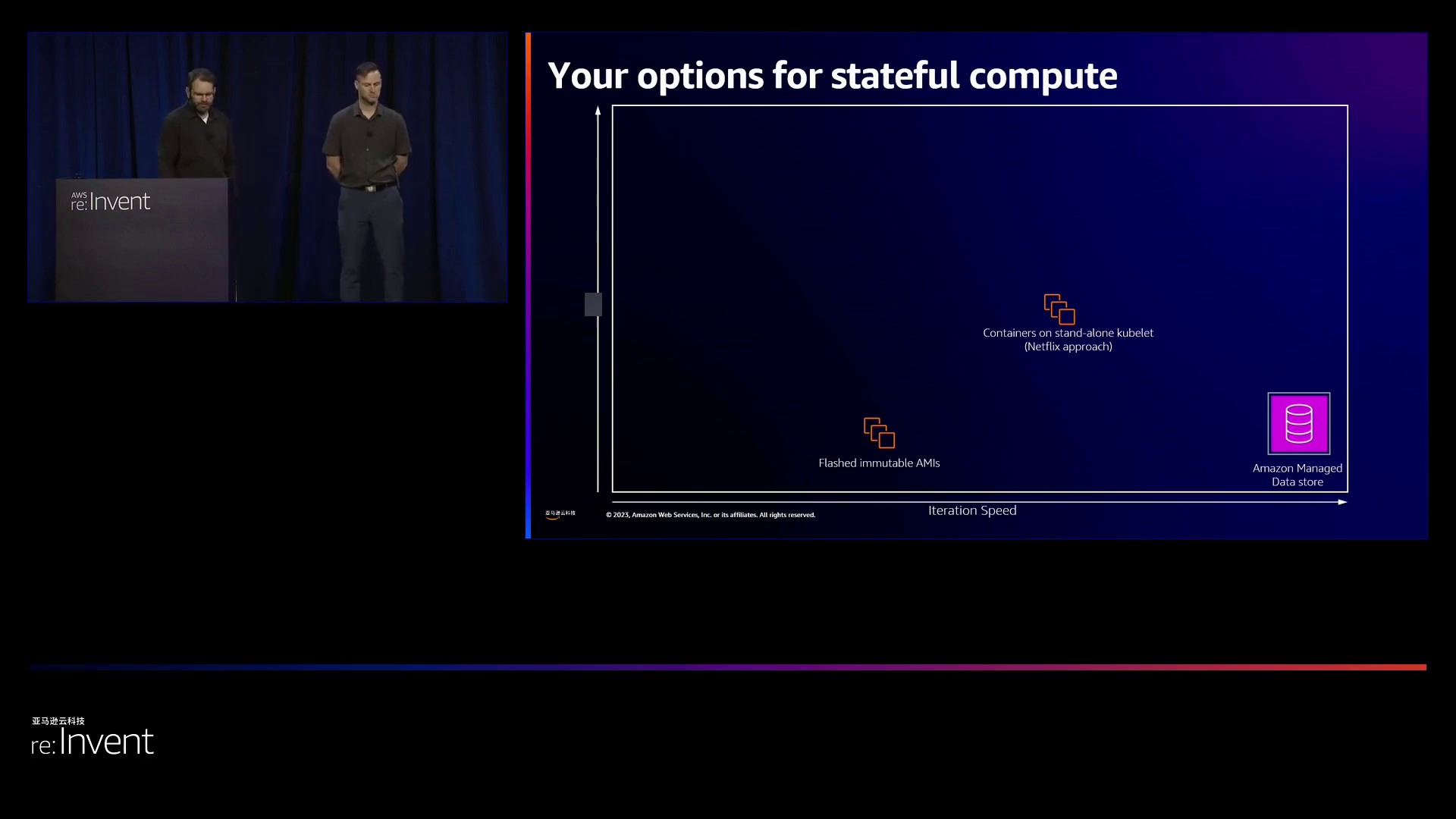
演讲者重申,最佳方法取决于每个组织独特的风险容忍度、迭代速度要求和其他因素。演讲者有帮助地提供了一张图表,描绘了通过风险与速度的透镜各种选项的比较。完全管理的服务提供了极低的风险和高速度。使用诸如Puppet之类的工具的可变配置管理是高风险的。在EC2上独立运行的K8s pod代表中等风险和高迭代速度之间的合理平衡,满足了Netflix当前的需求和环境。
总的来说,关键收获包括:
-
由于它们的数据重力和复杂性,有状态的负载很重且难以部署。
-
存在令人信服的业务原因来快速迭代有状态的服务,包括安全性、创新速度和恢复力。
-
Netflix在过去十年里随着内部需求的改变,已经迭代发展了他们的有状态服务架构,实现了不可变的基础设施和快速迭代。
-
有多种选择,如管理服务、配置管理工具、容器和AMI刷新-根据您的独特环境谨慎评估权衡。
-
在亚马逊的EC2平台上运行独立的K8s Pods可以为用户提供一种混合模式,这种模式既提高了效率又降低了复杂性。
-
为了增强组织的适应性,用户需要不断进行频繁的部署实践,因为如果一个过程让人感到痛苦,那么就应该多做一些来改善这种情况。
-
在设计和实施有状态服务时,用户需要深入理解自身组织的风险承受能力和迭代速度需求,并根据这些需求采取相应的措施。
演讲者通过提供各种全面的选项和权衡考虑,向观众展示了如何在云环境中有效地部署和迭代有状态服务的方法。他们帮助观众根据自己的独特环境和需求做出最佳的决策。
下面是一些演讲现场的精彩瞬间:
领导者探讨了有状态服务的关键因素以及如何支持这些服务。

据演讲者介绍,在Netflix进行拆分之前,他们开始采用可变和不可变的基础设施,随后又将其合并,以满足其主要的工作负载需求。
演讲者指出,在Kubernetes中部署和运营如MySQL之类的应用程序需要了解三大复杂系统(即应用、Kubernetes和操作员),这比仅运行该应用程序本身所需的知识量要多出300%。

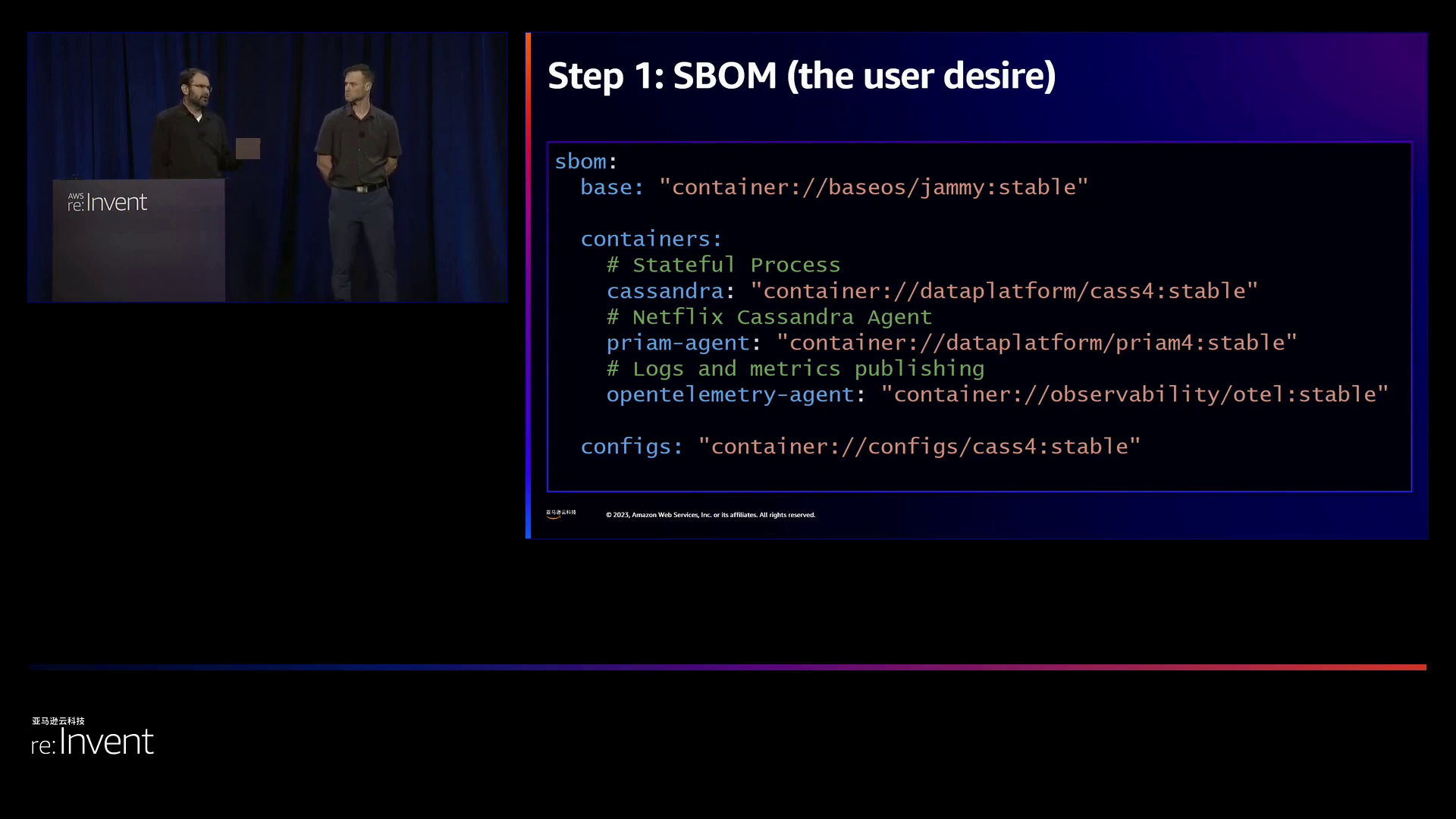
演讲者强调,SBOM(Software Bill of Materials)的重要性在于其应包含的内容不仅限于pod规范,还应包括基本操作系统、内核、kubelet版本和配置等信息。
对于Amazon EKS,由于闪存的不可变基础架构镜像方法具有较小的风险,因为更换根卷时不会发生状态传输,同时EC2实例ID、主机名和IP地址均保持不变。
领导者强调了在通过不可变基础设施降低风险的同时,实现快速迭代速度之间的平衡的重要性。
总结
亚马逊云科技在re:Invent上的一次演讲中,主要探讨了在云端进行有状态服务的快速迭代策略。演讲者从Netflix从运营自己的数据中心到迁移至亚马逊云科技并多年以来不断尝试各种部署策略的过程中,强调了上下文的重要性——你的环境和风险承受能力将对有状态服务的最佳方法产生重要影响。
接着,演讲者分析了有状态工作负载的特性和其与数据的紧密联系、附属依赖以及强大的数据影响力。随后,演讲者阐述了快速迭代的重要性,例如降低安全风险、推动创新以及应对突发事件。如果无法重启数据库或使其离线,这可能导致需要加快迭代速度。
随后,演讲者探讨了多种部署选择,包括提供最高速度和最低风险的托管服务(如RDS和DynamoDB),然后讨论了其他针对特定有状态工作负载的选项:
- 使用诸如Puppet等配置管理工具,但可能存在潜在风险;
- 通过闪存AMI更换操作系统,速度较快且风险较低;
- 在EKS上使用Kubernetes,功能丰富但复杂且存在“300%问题”;
- 在EC2上使用独立容器,结合不可变操作系统和快速的容器升级。
Netflix采用了闪存AMI和容器的混合方式,以平衡风险和速度。演讲者最后呼吁观众审视自身的特殊限制,并根据自身环境而非盲目模仿Netflix来进行优化。如今提供了这些选项,以便每个人都可以重新评估并在有状态服务上进行更快速的迭代。
演讲原文
https://blog.csdn.net/just2gooo/article/details/134824384
想了解更多精彩完整内容吗?立即访问re:Invent 官网中文网站!
2023亚马逊云科技re:Invent全球大会 - 官方网站
点击此处,一键获取亚马逊云科技全球最新产品/服务资讯!
点击此处,一键获取亚马逊云科技中国区最新产品/服务资讯!
即刻注册亚马逊云科技账户,开启云端之旅!
【免费】亚马逊云科技中国区“40 余种核心云服务产品免费试用”
亚马逊云科技是谁?
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者,自 2006 年以来一直以不断创新、技术领先、服务丰富、应用广泛而享誉业界。亚马逊云科技可以支持几乎云上任意工作负载。亚马逊云科技目前提供超过 200 项全功能的服务,涵盖计算、存储、网络、数据库、数据分析、机器人、机器学习与人工智能、物联网、移动、安全、混合云、虚拟现实与增强现实、媒体,以及应用开发、部署与管理等方面;基础设施遍及 31 个地理区域的 99 个可用区,并计划新建 4 个区域和 12 个可用区。全球数百万客户,从初创公司、中小企业,到大型企业和政府机构都信赖亚马逊云科技,通过亚马逊云科技的服务强化其基础设施,提高敏捷性,降低成本,加快创新,提升竞争力,实现业务成长和成功。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









