






关键字: [Knowledge Base, 游戏行业对话识别预警, 大模型语言处理, 评论分析系统, 辱骂识别系统, 知识增强引擎]
本文字数: 3300, 阅读完需: 16 分钟
导读
李开元先生在演讲中介绍了亚马逊云科技如何利用大模型和知识库技术,为游戏行业提供对话识别和预警服务。他详细阐述了利用大模型进行舆情分析、不当言论识别和风险控制的解决方案,以及如何通过知识库增强大模型的理解能力。这些技术可以帮助游戏公司高效地监控用户评论、过滤不当内容,从而优化产品和改善用户体验。演讲还介绍了亚马逊云科技AI Database服务,可以简化相关系统的开发和部署。
演讲精华
以下是小编为您整理的本次演讲的精华,共3000字,阅读时间大约是15分钟。
李开元先生,来自亚马逊云科技的解决方案架构师,今天分享了一个深圳市AI在沐瞳游戏公司的应用案例。沐瞳游戏是一家在东南亚地区运营的游戏公司,其地位相当于国内的王者荣耀。自2016年上线以来,该游戏的累计下载量已达到了14亿,月活跃用户超过1.1亿,日活跃用户超过5000万,在整个东南亚地区具有非常大的影响力。
沐瞳游戏是一款多人在线梦幻游戏,但在东南亚地区的实际运营过程中,它遇到了两个主要挑战。首先,东南亚地区的语种特别多,由于国家和地理文化的多样性,同一个国家甚至存在多种不同的语言,有些语言甚至属于小语种,基于传统的翻译方式无法很好地覆盖所有语言。其次,无论是进行社区类型的运营,还是整个语言环境的防护,比如玩家在游戏过程中发生争吵,都需要一种简单的方式来快速改善整个环境。
最终,沐瞳游戏找到了一种解决这些挑战的方式,这是来自客户的证言。在合作过程中,亚马逊云科技和沐瞳游戏一起制定了多种有趣的解决方案,今天李开元先生将介绍其中的两个。
第一个解决方案是舆情分析。如何收集所有用户对产品的评论和反馈,并对产品进行优化和改进?在这个第一部分,李开元先生将进行比较深入的讲解。第二个解决方案是辱骂识别和战场风控。
首先,什么是舆情分析?现场可能有做TOC(面向消费者)产品的同行,但似乎都是做TOB(面向企业)产品的。在做TOB技术产品时,总会有客户的评论、案例和工单,反映客户的情绪。对于TOC产品,更多是商店页面的评论,对于做用户研究和下一个战略级项目投资(可能上亿成本)有很大的指导意义。在这种情况下,如何确保所做的东西完全匹配客户的实际需求,就需要建立这样一套舆论分析系统。
沐瞳游戏每天会有14000条评论数据。传统方式是将数据扒下来做词云,也就是关键词匹配加小模型分析做成概率词云,然后基于词云分析或抽样。但这种方式存在以下缺陷:
- 用户不一定能清晰传达我们需要做什么。
- 它是有损的抽样,14000条评论做成词云一定会有大量信息损失。
- 如果让人工去分析14000条评论,工作量太大。
因此,我们的解决方案分为三步:
- 分类打标:所有评论在入库前先用大模型(小杯、中杯、大杯)进行分类打标,如日期、满意度、赞扬内容等,然后入库到Elasticsearch服务。
为什么需要这个打标入库过程?即使使用大模型,如果要分析一年的数据,处理量会非常大。我们只想分析其中一部分,把全量数据直接丢进去不管对大模型还是传统数据分析都不是很好的形式,所以需要先打标归档,为了做更精细化的过滤分类。在入库之后,我们实际分析的时候,就可以做更精准的过滤,比如说我想做一个月的总结,我就按照标签把这一个月的数据全部抽出来;如果我想分析某一个英雄的评价,我就把这个英雄相关的评论按照标签的形式全部抽出来;如果我想分析游戏音效的评论,我就把游戏音效相关的评论全部抽出来,然后再丢给大模型去做总结。
现在的大模型,像我们的中杯,以及超大杯,都已经支持了2000k token的上下文,这相当于你可以把整本红楼梦丢给它,让它为你做数据分析和总结,是一个非常强大的工具。
- 开源了一个工具,可以将任何App在谷歌和苹果应用商店的所有评论扒下来,然后按天去分析该App的信息,比如大家可以把这个工具下载下来,自己分析一些受欢迎的App的评论,目前这是一个非常有效的工具。
第二个解决方案是辱骂识别和战场风控。对于一款拥有5000万日活跃用户的游戏来说,每天需要处理3亿到4亿条的对话数据,要想有效地处理这么大量的不当内容,传统的关键词匹配方式是远远不够的。
我们采用了一种更加有效的方式,那就是使用大模型。大模型相比传统的关键词匹配或语言意图识别,有两个非常好的优势:第一,它摆脱了关键词的限制;第二,在这个过程中,它可以有效地识别不带脏字的辱骂内容。特别是在国内运营一些社区或社交类服务时,往往会出现很多不当或政治敏感的话题,它们不会通过直接的关键词体现,如果根据关键词过滤,可能会导致很多正常内容都无法发出。
那么如何解决这个问题呢?最后,比较传统的方式是这样的:每一句话结束后,系统会检测是否有人举报,如果有人举报,就先拉取聊天记录,然后与用户数据做ETL处理后进行关键词匹配,如果可以匹配,就直接判罚;如果不能匹配,再由人工判断是否属于辱骂。但这种方式对于3亿条数据来说,即使过滤掉90%,还有3000万条需要人工审核,这基本上是不可能的。
我们的大模型解决方案很好地解决了这个问题,它是一个更大更精准的漏斗,把关键词匹配的过程直接替换成了大模型处理的过程,置信度相对更高。如果置信度高,我们就直接做出判罚;如果置信度低,我们就交给海外的客服团队处理,可以将整个海外客服团队的成本压缩到一个相对较低的量级。
在使用大模型的过程中,最关键的一步就是Prompt调优。我们开发了一个工具叫做Prompt Generator,它可以把你输入的简单句子变成一个非常有效的Prompt,用于大模型的使用。比如说,在这个场景下,我就希望把用户的输入输进去后,它能够给我输出一个JSON格式的输出,这样我就可以把它作为一个接口的输出,传递给下一个系统进行处理。
第二,我们会在中间使用大量的存储引擎,用来做所谓的知识增强(RAG)。因为这是一个纯文本的服务场景,所以我们使用了OpenSearch。为什么要使用OpenSearch呢?这个原因我们稍后会讲到。大模型就像我们的思考模块,我们既然有思考模块,就需要一个记忆体,因为我们会有很多私域的知识,有一些可能只有我们这个领域才知道的知识,但是大模型不一定知道。在输入时,我们就需要把这些知识一并提供给大模型,让它更好地理解和处理。
一个比较简单的例子就是,在游戏场景或医学场景下,有一些非常关键的黑话或俚语,这些大模型是不会收录的。所以在给大模型处理之前,我们需要先把这些信息写到Prompt里面,这样大模型就能更好地理解和处理所有内容。我们用于存储所有这些信息的工具,一般称为RAG,即知识增强系统。我们目前使用的系统就是OpenSearch平台,对于不同的数据,AI Database还提供了不同的RAG存储介质。
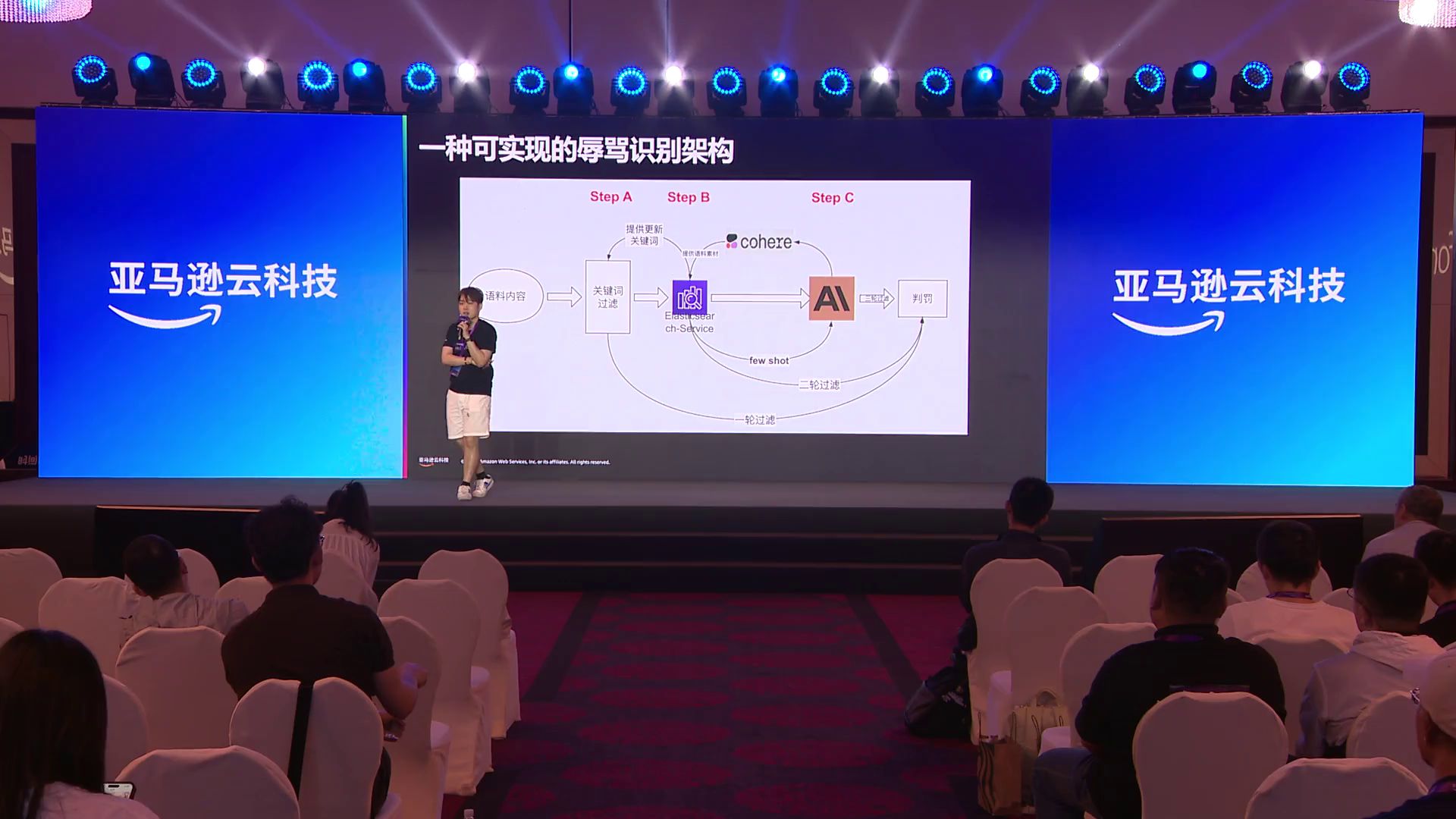
这套系统是如何实现的呢?可以从左边往右边看。所有的评论流式进来后,先做关键词过滤,因为有些关键词一定会触发问题,比如在美国,你在评论中说出FWord或N Word,那一定是非常不礼貌的;在中文中,你说”傻叉”或类似的词,也一定会有问题。这些高度匹配的关键词,我们会在第一步就过滤掉,大概处理掉10%到20%的内容。
剩下的内容会过第二个环节,也就是我刚才说的OpenSearch系统。它相当于是我们之前所有语料的存储器,当我们输入一条语料时,它可以通过向量匹配的方式,在我们的语料库里找到与之语义非常相关的句子。一旦匹配到与之前判定为辱骂的句子相似度达到90%以上的语料,我们就基本可以默认它也是辱骂内容,不需要再丢给大模型处理了,因为大模型处理目前而言消耗的GPU资源是相对昂贵的。
这个过程大概能处理掉60%的线上辱骂问题,前两层一共能过滤掉80%,剩下的20%才会丢给我们的AI大模型去做识别处理。
这是我们看这个图的第一种方式,但这个图还可以从右边往左边看,就跟我们人类思考问题的过程一样。我们一开始接触到一个新的事物,会经过认真思考,将这个知识记录下来,进入我们的记忆;第二次遇到同样的问题时,我们就不会再思考,而是直接从记忆中调用已有的知识并应用。这套系统的处理逻辑也是一样的,大模型就类似于我们的思考模块,大模型思考过的、已经判罚过的所有语料可以变成我们的记忆,用于未来的判罚。
我们会把从Step C这个部分大模型处理过的所有语料,再回存到Elasticsearch中。就像我刚才说的,如果在这个过程中,我们再遇到类似的辱骂内容,在这一层我们就可以直接过滤了。而如果一个语料被命中的概率非常高,达到了一个水位线,我们就会把它提取出关键词,变成关键词过滤的步骤,因为关键词过滤的处理效率是最快的。然后是Elasticsearch这个向量库,它需要做Embedding和Re-Rank,这个过程需要一些消耗,但肯定没有第三步那么多。最后是大模型识别,是最慢但最精准的一步。通过这样的设计,我们可以把看起来非常昂贵的AI系统,做成一个线上实时且非常便宜的系统。目前这一套系统已经在沐瞳游戏上线,帮助他们解决了非常大的辱骂识别难题。
这套系统还能不能再去做优化呢?我们可以回到传统搜索引擎的两阶段检索系统(Two-Stage Retrieval System)的逻辑。就是说,我们先通过一个非常粗略的向量化的Embedding模型,把所有的东西先粗略召回出来,然后再对这个内容去做Re-Rank。为什么要这么做呢?因为Embedding模型虽然是一个小模型,在大量文本中召回时速度比较快,开销也比较小,但它的精准度没有那么高。而Re-Rank模型的开销稍微大一些,但精准度更高。我们用Re-Rank模型对Embedding模型找出的前30-40条数据重新排序,就能获得更佳的向量,提高12.7%到13.1%的精确度,是一种非常有效的优化方式。
这就是传统的两阶段检索系统,一开始大量的查询去做排序,找出大概前25条语料,然后再经过Re-Rank模型,找出匹配度最高的几条语料,从而获得较高的语料精确度。
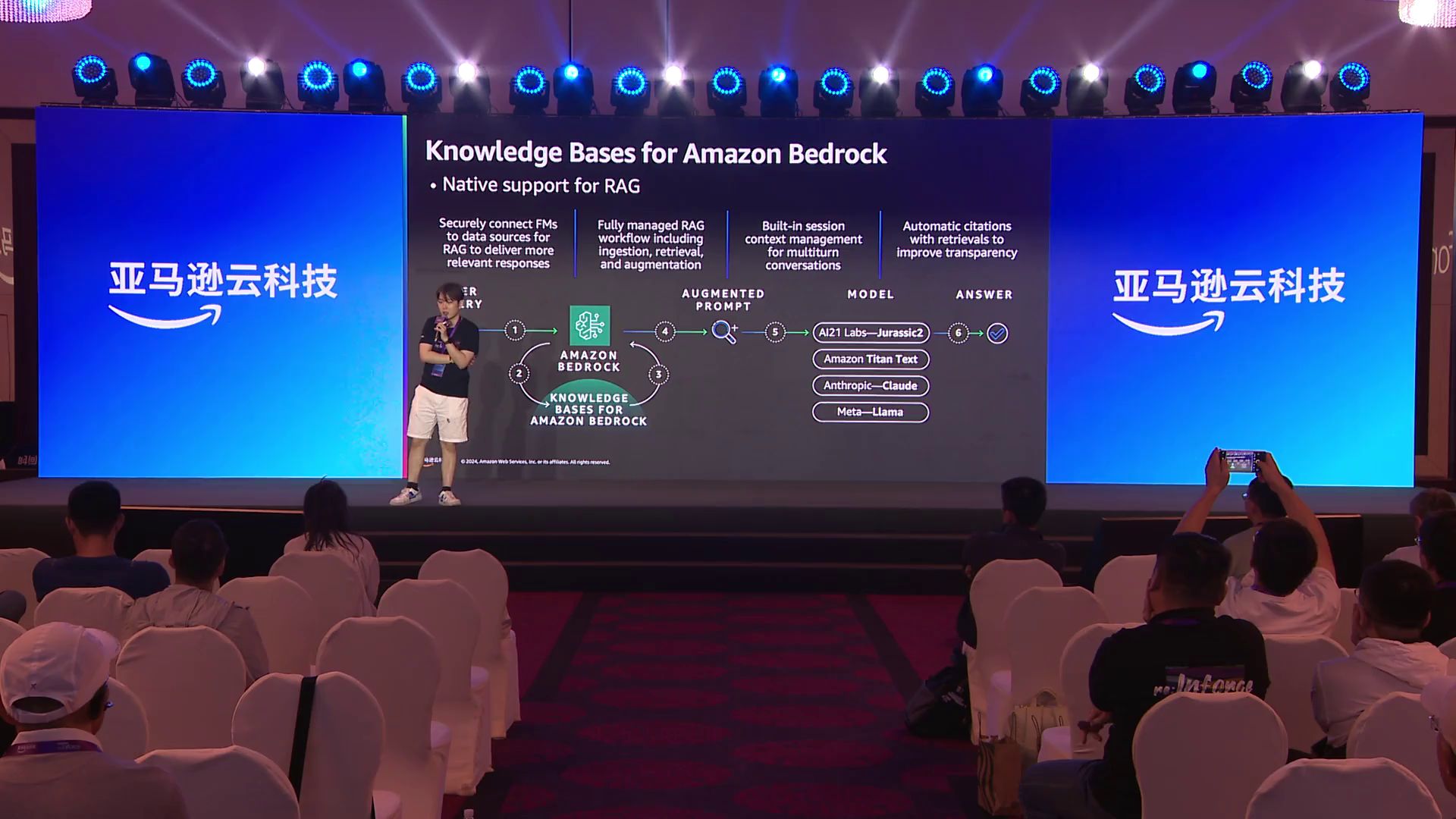
如果觉得上述系统过于复杂,不想自己开发,没关系,AI Database已经为大家准备好了。AI Database不仅提供了AI模型服务,还有Knowledge Base知识库服务,支持非常多样的文本输入形式,甚至支持从其他平台获取知识并存储。无论是Embedding、Re-Rank,还是对文本做分块等工作,大家都不用自己实现了,只需依赖它的文本服务即可。
基于亚马逊的生态,我们不仅可以简化复杂的开发过程,Knowledge Base还支持将对象存储S3中的所有文件直接读入。在这个过程中,我们可以用GuardDuty对S3中的所有数据进行提前检测,确保数据本身是安全的,不会被其他用户破解。
李开元先生举了一个例子,他曾为一家公司服务,该公司运营了一个大型游戏。然而,这个游戏上线不到12个小时,就有黑客直接在YouTube上发布了一个视频,声称自己已经破解了这个游戏,并将服务器上的所有代码全部泄露到了一个公开的对象存储桶中。最后查明,原因就是当时他们在做数据防护时没有做得很好。如果当时就有GuardDuty这个服务,一定就不会出现这种问题。
这就是李开元先生今天想要分享的所有内容。他的分享主要包括两个部分:第一是如何通过舆情分析来收集用户评论、反馈,指导产品优化和下一步投资方向;第二是如何利用大模型、领域知识增强等技术,实现高效的辱骂识别和游戏语言环境改善。
在舆情分析方面,传统的词云分析存在信息损失和工作量大的问题。他们的解决方案是:1)使用大模型对评论进行分类打标并存入Elasticsearch;2)根据标签过滤出所需数据,再用大模型总结;3)开源了一个工具,可分析任何App的商店评论。
在辱骂识别方面,传统的关键词匹配方式效果不佳。他们的解决方案是:1)使用大模型识别辱骂,能有效识别不带脏字的辱骂;2)通过Prompt调优,生成高效Prompt输入给大模型;3)使用OpenSearch存储领域知识,增强大模型理解能力;4)三级过滤:关键词、语义匹配、大模型识别;5)反馈训练,持续优化大模型判断能力;6)使用AI Database的Knowledge Base服务,简化系统开发。
该解决方案已在沐瞳游戏上线,解决了大量辱骂识别难题,显著改善了游戏语言环境。李开元还介绍了如何基于传统的两阶段检索系统,使用Embedding模型和Re-Rank模型,进一步优化系统的精确度和效率。
总的来说,这是一个利用大模型、云服务和创新技术,为游戏行业提供舆情分析和辱骂识别的解决方案,具有很好的通用性和应用前景。通过与客户的紧密合作,他们不断优化和完善这一解决方案,帮助游戏公司有效改善用户体验。
下面是一些演讲现场的精彩瞬间:
亚马逊云科技的 SA 李开元在分享会上热情洋溢地向观众介绍亚马逊云科技的产品和服务。

通过向量匹配和语义相关性分析,系统能够快速识别出骂人等不当言论,从而避免将它们送入耗费大量GPU资源的大型语言模型进行处理。
这个图还可以从右边往左边看,人类思考问题和学习的过程就像大模型处理逻辑一样
通过多层过滤和优化,我们能够构建一个实时且高效的AI内容审核系统,为海外用户解决了重大难题。
AI Database 提供了开箱即用的 AI 模型服务和知识库服务,无需自行开发复杂系统。

一款游戏在上线不到12小时就被黑客攻击,源代码被公开,原因是安全防护措施不足。
总结
亚马逊云科技在游戏行业的一个案例展示了如何利用大模型和知识库技术来优化游戏环境和用户体验。这个案例涉及东南亚地区一款大型多人在线游戏,面临着多语种用户和不当言论管控的挑战。
通过采用大模型进行舆情分析和辱骂识别,结合知识库增强和向量匹配技术,实现了高效的用户评论分类和不当言论实时检测。这种方法不仅提高了分析和审核的准确性,还大幅降低了人工成本。
最后,亚马逊云科技推出了AI Database服务,集成了知识库、大模型和安全防护等功能,为游戏等行业提供了开箱即用的AI解决方案,简化了复杂系统的开发过程。这种创新应用为游戏行业带来了全新的AI赋能体验。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









