







1、什么是JVM
JVM是Java Virtual Machine(Java虚拟机)的缩写,是一个虚构的计算机,这个计算机用来运行我们的Java程序。
JVM运行在操作系统之上。
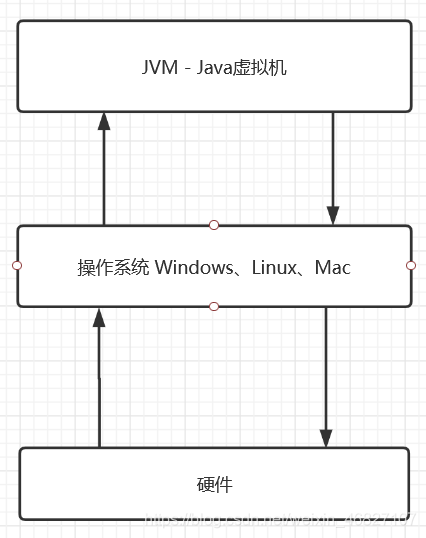
2、JVM运行流程
线程私有:jvm虚拟机栈,本地方法栈,程序计数器
线程共享:堆和方法区
- 编写好java源文件
- 通过编译器编译为class文件
- 经过类加载器初始化
- 进入JVM运行数据区
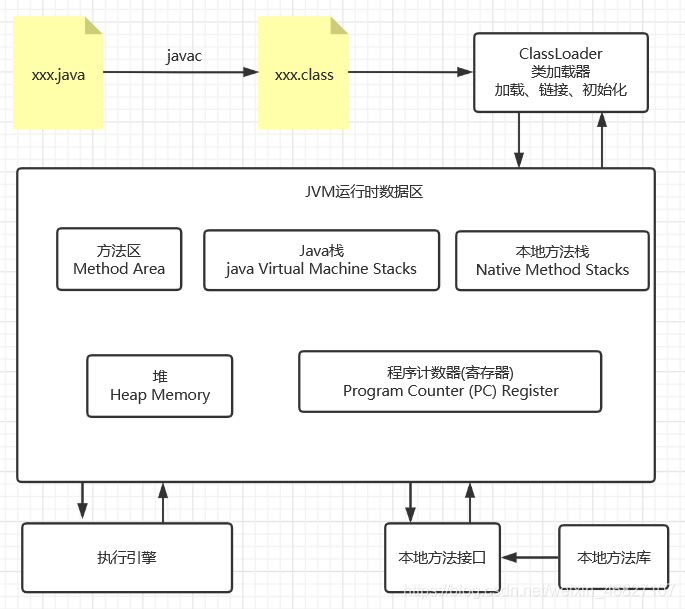
线程私有:jvm虚拟机栈,本地方法栈,程序计数器
线程共享:堆和方法区
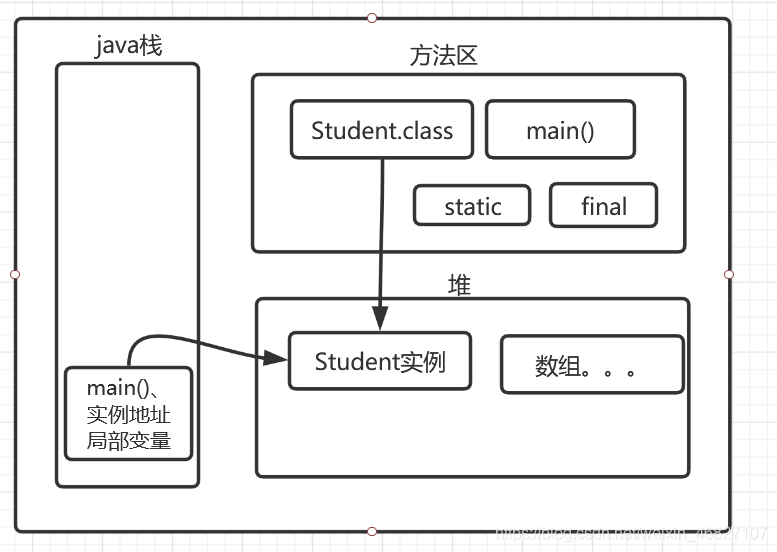
2.1 java栈
- 基础数据类型
- 方法的形式参数,局部变量,方法调用完后从栈空间回收
- 引用对象的地址,引用完后,栈空间地址立即被回收,堆空间等待GC
2.2 方法区
- 字符串常量
- 常量
- static
- 所有的class
2.3 堆
- new出来的对象(实例)
- 数组
2.4 堆栈方法区关系
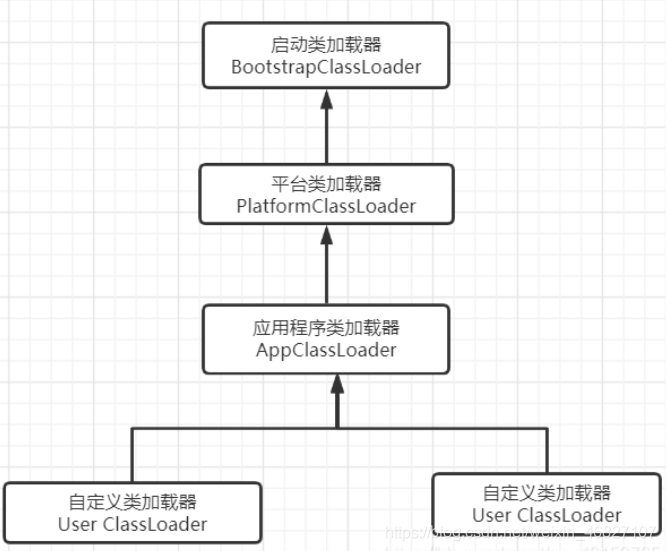
3、类加载器与双亲委派机制
Java 虚拟机自带的加载器包括以下几种:
- 启动类加载器:
BootstrapClassLoader加载rt.jar - 平台类加载器(
PlatformClassLoader) JDK8:扩展类加载器(ExtensionClassLoader)加载ext下的扩展jar - 应用程序类加载器(
AppClassLoader)加载自定义的类 - 用户自定义的加载器:是 java.lang.ClassLoader 的子类,用户可以定制类的加载方式;只不过自定义类加载器其加载的顺序是在所有系统类加载器的最后
public class Test01 {
public static void main(String [] args) {
Test01 test01 = new Test01();
ClassLoader loader = test01.getClass().getClassLoader();
System.out.println("自定义的对象类加载器:"+loader); // AppClassLoader
System.out.println("自定义的对象类加载器的父加载器:"+loader.getParent()); // ExtClassLoader
System.out.println("自定义的对象类加载器的祖父加载器:"+loader.getParent().getParent()); // null
}
}
双亲委派机制就是在类加载的时候会一直往上找对应的类加载器去加载这个类。
如果找到了,停止,如果没有找到就抛出异常给下一级类加载器加载。
双亲委派机制的优点是保证了安全性,意思也就是说防止有与Java核心类同名的方法。
我们自定义的User类,首先会由BootstrapClassLoader加载,然后被ExtensionClassLoader加载,加载不到,最终会被AppClassLoader加载。
而如果我们自定义了一个String类,按照上面的流程,它最终会被BootstrapClassLoader加载到,然后就不往下了,也就是说我们自定义的String根本加载不到!
这也就保证了我们的Java核心不会被篡改。
4、堆分区
public class Test04 {
public static void main(String[] args) {
// 能够从操作系统挖到得最大内存
long max = Runtime.getRuntime().maxMemory();
// 当前得总内存
long total = Runtime.getRuntime().totalMemory();
// 从操作系统挖过来的内存没有用到的部分
long free = Runtime.getRuntime().freeMemory();
System.out.println("能够从操作系统挖到得最大内存:"+max +"\t"+max / 1024/1024 +"M");
System.out.println("当前得总内存:"+total+"\t"+total / 1024/1024 +"M");
System.out.println("空闲内存:"+free+"\t"+free / 1024/1024 +"M");
/*
默认
能够从操作系统挖到得最大内存:1648361472 1572M
当前得总内存:112721920 107M
空闲内存:110365728 105M
调整后:-Xms1024m -Xmx1024m
(-Xms设置当前的总内存,-Xmx准要从操作系统挖多少内存)
能够从操作系统挖到得最大内存:1029177344 981M
当前得总内存:1029177344 981M
空闲内存:1018439896 971M
-XX:+PrintGCDetails查看详细堆内存参数
Heap(堆)
(新生区)PSYoungGen total 149504K, used 7711K [0x00000000eab00000, 0x00000000f5180000, 0x0000000100000000)
(伊甸园区)eden space 128512K, 6% used [0x00000000eab00000,0x00000000eb287c70,0x00000000f2880000)
(幸存1区)from space 20992K, 0% used [0x00000000f3d00000,0x00000000f3d00000,0x00000000f5180000)
(幸存2区)to space 20992K, 0% used [0x00000000f2880000,0x00000000f2880000,0x00000000f3d00000)
(养老区)ParOldGen total 341504K, used 0K [0x00000000c0000000, 0x00000000d4d80000, 0x00000000eab00000)
object space 341504K, 0% used [0x00000000c0000000,0x00000000c0000000,0x00000000d4d80000)
(元空间)Metaspace used 3195K, capacity 4496K, committed 4864K, reserved 1056768K
class space used 347K, capacity 388K, committed 512K, reserved 1048576K
在实际工作中,我们可以直接将初始的堆大小与最大堆大小相等,
这样的好处是可以减少程序运行时垃圾回收次数,从而提高效率
*/
}
}
5、GC回收算法
5.1 复制算法
这个方法适合实例比较少的情况,主要使用在新生区中的幸存区,from/to
to区总是空的那块,从eden区如果没有被GC回收,那就会到from区,再到to区
这时候to区有了,from区空了,此时的from区就变成了to区,如果实例在经过了15次回收还没被回收,就进入养老区。
复制算法快,效率高,但是对应的,那会多使用一份内存,也就是那块to区
5.2 标记算法
标记算法是对每一个被引用了的实例做一个标记,如果这个实例没有被引用,就会被回收,但是这样会产生很多的内存碎片,效率又下来了。
5.3 标记压缩算法
通过压缩的方式,将我们标记的实例都放在同一块地方,其他没引用的就会被回收,这样虽然不会产生内存碎片,但是压缩会损耗一些时间。
所以总的来说每个算法都各有优势。尽可能选择合适的算法,对jvm来说才是最好的。















 5707
5707











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









