









 本文介绍了一个基于并查集实现的股票推荐系统设计方案。系统能够根据用户的关注情况推荐未关注的股票,通过并查集处理用户间关注的股票的连通性问题。
本文介绍了一个基于并查集实现的股票推荐系统设计方案。系统能够根据用户的关注情况推荐未关注的股票,通过并查集处理用户间关注的股票的连通性问题。
LeetCode高频题:设计一个股票推荐系统,自动根据注册用户的关注情况进行推荐,询问时,会推荐那个人多少只他还没有关注的股票?
提示:本题是系列LeetCode的150道高频题,你未来遇到的互联网大厂的笔试和面试考题,基本都是从这上面改编而来的题目
互联网大厂们在公司养了一大批ACM竞赛的大佬们,吃完饭就是设计考题,然后去考应聘人员,你要做的就是学基础树结构与算法,然后打通任督二脉,以应对波云诡谲的大厂笔试面试题!
你要是不扎实学习数据结构与算法,好好动手手撕代码,锻炼解题能力,你可能会在笔试面试过程中,连题目都看不懂!比如华为,字节啥的,足够让你读不懂题

基础知识:并查集
【1】并查集:解决连通性问题的利器:并查集
我也拿并查集解决过相关连通性的问题,类似本题:
【2】图的最小生成树:Kruskal算法–并查集的经典应用,解决连通性问题
【3】岛问题:1是陆地,0是水域,请问矩阵arr中有几个岛,并查集并行加速
文章目录
- LeetCode高频题:设计一个股票推荐系统,自动根据注册用户的关注情况进行推荐,询问时,会推荐那个人多少只他还没有关注的股票?
-
- 题目
- 一、审题
- 理解本题的关键是知道推荐系统的连通性,解决连通性的利器:并查集
- 有了上面的理解,其实你应该明白,每一次查询,都需要把所有集合走一遍,看看没有合并的集合,是否有交集,有就需要合并连通
-
- ACM格式输入,主函数操作q次,每次可能是1或者2,是1就注册,是2就查询
- 总结
文章目录
- LeetCode高频题:设计一个股票推荐系统,自动根据注册用户的关注情况进行推荐,询问时,会推荐那个人多少只他还没有关注的股票?
- 题目
- 一、审题
- 理解本题的关键是知道推荐系统的连通性,解决连通性的利器:并查集
- 有了上面的理解,其实你应该明白,每一次查询,都需要把所有集合走一遍,看看没有合并的集合,是否有交集,有就需要合并连通
- ACM格式输入,主函数操作q次,每次可能是1或者2,是1就注册,是2就查询
- 总结
题目
完成设计一个股票推荐系统,该系统会自动根据注册用户的关注情况进行推荐。
例如,对于通知关注Zoom和Warmart的人而言,推荐算法会根据它的信息认为,关注了Zoom的人,可能对Warmart也感兴趣,反之亦然,关注了Warmart的人,可能对Zoom也感兴趣。
因此,对于另一个关注了Warmart,但是没有关注Zoom的人来说,该系统就会推荐他关注Zoom。
请注意,该系统会计算连锁的信息,例如,假设在刚刚的前提下(存在同时关注Warmart和Zoom的人),存在一个同时关注Zoom和Apple的人,那么对于另一个只关注了Warmart的人,该系统会同时推荐他Zoom和Apple。
现在给出一些人的注册信息和询问,你需要回答每次询问时,推荐系统会推荐那个人多少只他还没有关注的股票?
输入描述:
第一行输入一个整数q,代表操作次数
接下来输入q次操作,
共有2种操作:
1,注册,格式为:
第一行输入1 name n,代表1个名字为anme的人注册了该系统,它关注了n只股票
第二行输入n个仅仅包含英文名字母字符的str,代表这个人关注的股票名字
保证不会重复注册,这n个字符串互不相同。
2,查询,格式为:
仅有一行,输入为2 name,代表询问该推荐系统,会给这个人推荐多少只股票。
1<=q<=10000
1<=n<=5
所有字符串均只包含引文字母,且长度不会超过10.
保证至少有1次询问。
输出描述:
对于每次询问:
若查询的人不存在则输“error”。
一、审题
示例:
q=5
拢共要干5次操作
2 Bob
第一次询问时,系统内还没有名字为Bob的用户,输出error
1 Alice 2
Apple Zoom
2 Alice
第2次询问时,系统不会给Alice推荐任何股票,输出0
因为没别的用户,并查集查了集合,合并然后也不行
1 Bob 2
Apple Microsoft
2 Bob
第三次查询,由于Bob也注册了,所以看看并查集中的俩集合,把代表们依次查一遍,看看需要合并的合并,不需要的不管,这样算前后差,得到了1只股票,输出1
这里因为Alice和Bob都关注了APPLE,所以必然要给Bob推荐ZOOM
理解本题的关键是知道推荐系统的连通性,解决连通性的利器:并查集
为啥呢???
题目说:
请注意,该系统会计算连锁的信息,例如,
假设在刚刚的前提下(存在同时关注Warmart和Zoom的人),咱叫这个人名字为A
存在一个同时关注Zoom和Apple的人,咱叫这个人名字为B
那么对于另一个只关注了Warmart的人,咱叫这个人名字为C
该系统会同时推荐他Zoom和Apple。
下面我解释:
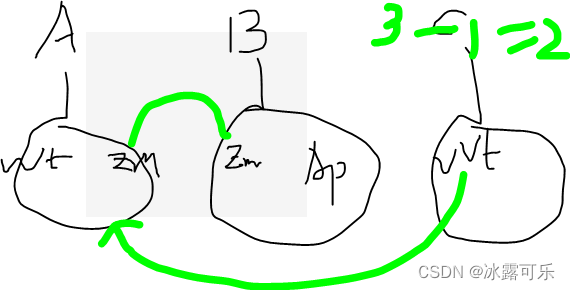
显然C和A是有交集的,可以将AC连同,由于AB有交集,所以AB也需要连同
我们待会用哈希表表示这些股票的话,重复的自动去重,因此合集的有效股票就3只
Warmart,Zoom,Apple
合并之后的数量是3,合并之前C的数量是1
结果ans=3-1=2只
懂?
有了上面的理解,其实你应该明白,每一次查询,都需要把所有集合走一遍,看看没有合并的集合,是否有交集,有就需要合并连通
因此,解决这个题目的关键点在于用:并查集
我之前透彻讲过并查集,也自己多次手撕过并查集
这个玩意,是必须要会的
【1】并查集:解决连通性问题的利器:并查集
我也拿并查集解决过相关连通性的问题,类似本题:
【2】图的最小生成树:Kruskal算法–并查集的经典应用,解决连通性问题
【3】岛问题:1是陆地,0是水域,请问矩阵arr中有几个岛,并查集并行加速
并查集的集合中装的节点Node代表股票
它包裹的value就是股票名字name–字符串
//并查集的集合中装的节点**Node**代表股票
//它包裹的value就是股票名字name--字符串
public static class Node{
public String name;
public Node(String s){
name = s;
}
}
我们的并查集数据结构设计为UnionSet
内部有这么几个结构
(1)nodes(哈希表):key–股票名字字符串,value–股票包裹节点Node
(2)parentMap(哈希表):key–股票节点Node,value–它所在集合的代表——这里就是并查集最经典的地方,具体你看上面我写的并查集的基础文章
(3)sizeMap(哈希表):keya–股票代表节点Node,value:它股票节点代表所在集合的节点个数,也就是当前这个股票集合拢共的张数
(4)普通并查集所没有的属性,我为了本题设计的数据结构(哈希表),holder:key–股票主人,value:主人所持股票仓,一个哈希集,立里面放的是所持股票的名字字符串
只需要根据这些股票就能跟踪大集合的所有情况,
比如,我只看C用户的warmart就知道,其实ABC仨都是一个大集合,
第一次用户C进来的时候,C独立成集合,我们查C数量为1
当合并ABC之后,其实再查C的数量,已经是3了
我为啥要设计(4)这个玩意呢???
你看看下面这图,假如A已经注册了Warmart和zoom
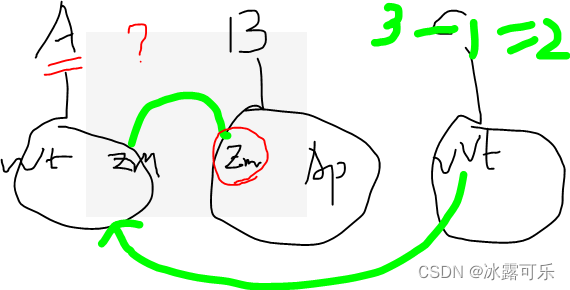
现在又来注册B,形成一个集合(zoom和apple)
now,我需要查一下,B中所有元素,比如,目前zoom已经在哪些集合里面了???
查到zoom在集合A中,我们就需要立马把B和A集合union了
我怎么知道B中的元素是否在集合A中呢?????
很显然需要提前把A的股票仓库用holder保存好,B的股票仓库也是用holder保存
这样遍历holder中B的所有股票名字,看看holder的A股票仓库里面有没有这些名字
如果有,那AB只要合并一次,就可以
okay,有了(1)–(4)这几个属性,我们就可以玩各种并查集的操作了
由于我们是先建并查集,后面根据ACM格式输入注册用户,所以默认构造函数就很简单
//我们的并查集数据结构设计为**UnionSet**
public static class UnionSet{
//所有参数类型统统实在写类型
//内部有这么几个结构
//(1)nodes(哈希表):key--股票名字字符串,value--股票包裹节点Node
public HashMap<String, Node> nodes;
//(2)parentMap(哈希表):key--股票节点Node,value--它所在集合的**代表**——这里就是并查集最经典的地方,具体你看上面我写的并查集的基础文章
public HashMap<Node, Node> parentMap;
//(3)sizeMap(哈希表):keya--股票代表节点Node,value:它股票节点代表所在集合的节点个数,也就是当前这个股票集合拢共的张数
public HashMap<Node, Integer> sizeMap;
//(4)**普通并查集所没有的属性**,我为了本题设计的数据结构(哈希表),**holder**:key--股票主人,value:主人所持股票仓,
// 一个哈希集,立里面放的是所持股票的名字字符串
public HashMap<String, HashSet<String>> holder;
//构造函数
public UnionSet(){
nodes = new HashMap<>();
parentMap = new HashMap<>();
sizeMap = new HashMap<>();
holder = new HashMap<>();//为了方便ACM格式,输入,暂时就先置空
}
代码接着下面的放
一切都是为了o(1)速度查a和b是否同属一个集合?isSameSet(a,b)?中间必然要用一个函数过度,查单个股票它所在集合的代表是谁?findFather(a)
findFather(a)查节点Node a的所在集合的代表是谁?将沿途所有的节点扁平化,全挂代表上
这个思想基础文章里面我说过了哦,很巧妙的,为了加速查询o(1)速度,需要扁平化所有节点,直接他们挂在集合的代表上面
//## 一切都是为了o(1)速度查a和b是否同属一个集合?isSameSet(a,b)?中间必然要用一个函数过度,
// 查单个股票它所在集合的代表是谁?findFather(a)
//### findFather(a)是谁?将沿途所有的节点扁平化,全挂代表上
public Node findFather(Node cur){
//扁平化所有节点,挂到代表cur上
Stack<Node> path = new Stack<>();//沿途收集
while (parentMap.get(cur) != cur){
path.push(cur);//沿途挂接的加入path
cur = parentMap.get(cur);//没找到代表就继续往上
}
//结果就是cur作为代表
while (!path.isEmpty()){
parentMap.put(path.pop(), cur);//改挂代表,下一次就一次找到了
}
return cur;
}
isSameSet(a,b)问,ab在同一个集合吗?
//### isSameSet(a,b)问,股票ab在同一个集合吗?
public boolean isSameSet(String a, String b){
if (!nodes.containsKey(a) || !nodes.containsKey(b)) return false;
//存在了俩
return findFather(nodes.get(a)) == findFather(nodes.get(b));//俩地址相等就是同一个代表,在同一个集合
}
然后看看是否需要合并ab所在的集合?union(a,b)
//## 然后看看是否需要合并ab所在的集合?union(a,b)
public void union(String a, String b){
if (!nodes.containsKey(a) || !nodes.containsKey(b)) return ;
//存在了俩,才看看是否同属一个集合?
Node aHead = findFather(nodes.get(a));
Node bHead = findFather(nodes.get(b));
//在同一个集合就算了
if (aHead != bHead){
Integer aSize = sizeMap.get(aHead);
Integer bSize = sizeMap.get(bHead);
//合并策略:小集合挂大集合
Node big = aSize >= bSize ? aHead : bHead;
Node small = big == aHead ? bHead : aHead;
parentMap.put(small, big);//小集合的代表换为big,挂好了,合并好了也
sizeMap.put(big, aSize + bSize);//大集合数量变了
sizeMap.remove(bSize);//小集合消失
}
}
可以查当前并查集的集合数量:getSetNum()–本题中好像这个不重要
//## 可以查当前并查集的集合数量:getSetNum()--本题中好像这个不重要
public int getStockSetNum(){
return sizeMap.size();//拢共多少个集合?本题不知道用还是不用
}
对于本题,咱们还需要对应ACM输入格式,注册一个用户,会来一串股票,我们一次性构建独立集合,并union他们所有
这个功能好比咱们普通并查集的构造函数一样,不过呢,本题的构造函数就随意了
每次注册,咱们直接把用户user的所有股票,放列表里面,然后一鼓作气加入并查集
所以并查集需要准备add函数,拿着user名字,和它的所有股票
这样的话我们的哈希表holder就能保存user–股票们
这是本题的重头戏
后面再查询阶段,我们需要先合并可能的集合,那就要更新user,合并之后,它手里有哪些股票了,这样才知道推荐系统应该推荐多少个user手里没有的股票
add手撕代码,非常非常关键:
//## 对于本题,咱们还需要对应ACM输入格式,注册一个用户,会来一串股票,我们一次性构建独立集合,并union他们所有
//这个功能好比咱们普通并查集的构造函数一样,不过呢,本题的构造函数就随意了
public void add(String user, List<String> arr){
//送进来的是用户,还有它全部股票:一个字符串数组
//有了咱就不需要建了,直接合并即可
//同时,把用户,和股票所属关系表填好
HashSet<String> set = new HashSet<>(arr);
holder.put(user, set);
for(String str : arr){
if (!nodes.containsKey(str)) {
Node cur = new Node(str);
nodes.put(str, cur);//没有咱再考虑加
//新来的都是独立成集合的
parentMap.put(cur, cur);//自己代表自己
sizeMap.put(cur, 1);
}
}
//加完之后,立马把该用户的所有股票合并成一个集合,其实这时候,几乎相同的用户都合并在一起了
for (int i = 1; i < arr.size(); i++) {
union(arr.get(0), arr.get(i));//这用户的集合得聚到一起
}
}
对于本题,我们需要查询用户user,系统会给它推荐多少股票?
我们需要看看目前用户独立情况下,股票仓中的股票数量是多少?
holder里面要是压根没有用户user,那就不必查了,返回error
上面的holder保存的就是这个数据,好说,不妨设为x
然后咱们就要考虑合user所有集合与别的集合,一连串合并之后,新集合的股票仓数量是y
——这个很关键
中途,我们可能需要查一下,user的每个股票,它在不在其他的集合中?合并,并返回合并后股票的总量【看下面单独模块】
则应该给user推荐的股票数量是y-x,这就是本题要的结果
//## 对于本题,我们需要查询用户user,系统会给它推荐多少股票?
//我们需要看看目前用户独立情况下,股票仓中的股票数量是多少?
public int query(String user){
if (!holder.containsKey(user)) return 0;//没这个用户,返回0;
//上面的holder保存的就是这个数据,好说不妨设为x
int x = holder.get(user).size();
//然后咱们就要考虑合user所有集合与别的集合,一连串合并之后,新集合的股票仓数量是y——这个过程其实加入的时候已经搞定了
//我们需要把这个用户原来没有的股票,互相加入自己的阵营
//也就是挨个查用户user的那些股票,是否与其他用户的股票是同一集合,是就让两者相互加
checkAndUnionTowUsers(user);
int y = holder.get(user).size();//合并后user用户的最新数量为y
//则合并之后给user推荐的股票数量是**y-x,这就是本题要的结果**
return y - x;
}
中途,我们可能需要查一下,user的每个股票,它在不在其他的集合中?合并,并返回合并后股票的总量
怎么搞呢?
就是拿着用户user的每一个股票stock
然后跟别的用户(所有的其他用户)u的股票otherStock对比
(1)如果stock和otherStock确实已经在一个集合,说明这俩用户赢合并过了
这时候,就只需要把user和u相互补充一波
补充怎么做?
就是拿着用户user的每一个股票stock
然后跟别的用户(所有的其他用户)u的股票otherStock对比
如果u手里的股票没有stock,需要补充stock
如果user手里的股票没有otherStock,需要补充otherStock
(2)接着(1)
如果stock和otherStock确实不再在一个集合,需要查一波u和user他们手里的股票有没有交集,如果有交集那这俩用户集合就得合并
OK,逻辑屡清楚,那就要手撕代码了
//### 中途,我们可能需要查一下,user的每个股票,它在不在其他的集合中?
// 在就合并,既然合并,那就要考虑更新holder,保证用户和股票是对应好的
public void checkAndUnionTowUsers(String user){//目前user它有的股票
HashSet<String> set = holder.get(user);//user的所有股票们
for(String u:holder.keySet()){
if (!u.equals(user)){//自己跟自己就不用查了
boolean in = false;
for(String otherStock:holder.get(u)){
//跟用户user挨个对比,看看在同一个集合就好,不在需要合并的
for(String stock:set){
if (isSameSet(otherStock, stock)){
in = true;//它背后俩集合一定在一起的
break;
}
//in是false,即不在一个集合,需要查,是否user,可能和现在的u有交集stock,有就要合并的
if (set.contains(otherStock)) union(otherStock, stock);
}
if (in) break;//我们需要互相补充然后直接退出不管
}
if (in){//我们需要互相补充然后直接退出不管
List<String> uNeed = new ArrayList<>();//加给当前user
List<String> userNeed = new ArrayList<>();//加给user的
for(String otherStock:holder.get(u)) {
//跟用户user挨个对比,看看在同一个集合就好,不在需要合并的
for (String stock : set) {//我们需要互相补充
if (!holder.get(user).contains(otherStock)) userNeed.add(otherStock);
if (!holder.get(u).contains(stock)) uNeed.add(stock);
}
}
for(String str:uNeed) holder.get(u).add(str);
for(String str:userNeed) holder.get(user).add(str);//互相加
}
}
}
}
}//并查集结束
ACM格式输入,主函数操作q次,每次可能是1或者2,是1就注册,是2就查询
咱们算是一气呵成!!
终于把我们要用的并查集UnionSet数据结构设计好了
该有的属性我们有了
该有的函数,我们有了
现在就是操作q次
根据操作类型:注册,或者是查询
来完成任务即可
//主函数,ACM输入格式
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int q = in.nextInt();//q个操作
in.nextLine();
//提前准备好并查集
UnionSet unionSet = new UnionSet();
while (q-- > 0){
//每操作一次q--
String s = in.nextLine();//一行字符串
String [] str = s.split(" ");
String user = str[1];//用户名字
if (str[0].equals("1")){
//1,注册,格式为:
//第一行输入1 name n,代表1个名字为anme的人注册了该系统,它关注了n只股票
//第二行输入n个仅仅包含英文名字母字符的str,代表这个人关注的股票名字
int n = str[2].toCharArray()[0] - '0';//转化为n个
//输入n个股票
List<String> stocks = new ArrayList<>();
String[] stk = in.nextLine().split(" ");
for (int i = 0; i < n; i++) {
stocks.add(stk[i]);//加入之后放入并查集
}
unionSet.add(user, stocks);
}else {//str[0].equals("2")
//2,查询,格式为:
//仅有一行,输入为2 name,代表询问该推荐系统,会给这个人推荐多少只股票。
int ans = unionSet.query(user);
System.out.println(ans == 0 ? "error" : ans);
}
}//q次操作结束
}//main结束
测试一把:
5
1 Bob 2
apple mirco
1 Alice 2
apple zoom
2 Bob
1
1 A 2
zoom jjj
2 A
2
连着注册俩用户Bob和Alice
查Bob,系统应该给它推荐1个micro
再注册一个用户A
查A,系统应该给A推荐两个,apple和micro
本题十足不容易,必须熟透了并查集,才能拿下
难点在于你需要造一个holder来存放每个用户user手里的所有股票
输入的时候,合并user所有的集合,但是同时可能合并了别的集合
查询的时候,先检查user可能和其他的用户是否需要合并,合并就要更新user和其他用户u手里的股票
查询之后再看holder的user手里是否多了股票,多出来的就是系统应该给它推荐的
不容易,这是zoom的秋招笔试题,难到爆炸,非常难,所以平时好好练习,否则上场了题目都看不懂的,更别说写出来了。
最后,甩出整体的代码
可能还能继续优化,但是为了理解并查集的本质,我这个过程很清楚
public static class Main {
//并查集的集合中装的节点**Node**代表股票
//它包裹的value就是股票名字name--字符串
public static class Node{
public String name;
public Node(String s){
name = s;
}
}
//我们的并查集数据结构设计为**UnionSet**
public static class UnionSet{
//所有参数类型统统实在写类型
//内部有这么几个结构
//(1)nodes(哈希表):key--股票名字字符串,value--股票包裹节点Node
public HashMap<String, Node> nodes;
//(2)parentMap(哈希表):key--股票节点Node,value--它所在集合的**代表**——这里就是并查集最经典的地方,具体你看上面我写的并查集的基础文章
public HashMap<Node, Node> parentMap;
//(3)sizeMap(哈希表):keya--股票代表节点Node,value:它股票节点代表所在集合的节点个数,也就是当前这个股票集合拢共的张数
public HashMap<Node, Integer> sizeMap;
//(4)**普通并查集所没有的属性**,我为了本题设计的数据结构(哈希表),**holder**:key--股票主人,value:主人所持股票仓,
// 一个哈希集,立里面放的是所持股票的名字字符串
public HashMap<String, HashSet<String>> holder;
//构造函数
public UnionSet(){
nodes = new HashMap<>();
parentMap = new HashMap<>();
sizeMap = new HashMap<>();
holder = new HashMap<>();//为了方便ACM格式,输入,暂时就先置空
}
//## 一切都是为了o(1)速度查a和b是否同属一个集合?isSameSet(a,b)?中间必然要用一个函数过度,
// 查单个股票它所在集合的代表是谁?findFather(a)
//### findFather(a)是谁?将沿途所有的节点扁平化,全挂代表上
public Node findFather(Node cur){
//扁平化所有节点,挂到代表cur上
Stack<Node> path = new Stack<>();//沿途收集
while (parentMap.get(cur) != cur){
path.push(cur);//沿途挂接的加入path
cur = parentMap.get(cur);//没找到代表就继续往上
}
//结果就是cur作为代表
while (!path.isEmpty()){
parentMap.put(path.pop(), cur);//改挂代表,下一次就一次找到了
}
return cur;
}
//### isSameSet(a,b)问,股票ab在同一个集合吗?
public boolean isSameSet(String a, String b){
if (!nodes.containsKey(a) || !nodes.containsKey(b)) return false;
//存在了俩
return findFather(nodes.get(a)) == findFather(nodes.get(b));//俩地址相等就是同一个代表,在同一个集合
}
//## 然后看看是否需要合并ab所在的集合?union(a,b)
public void union(String a, String b){
if (!nodes.containsKey(a) || !nodes.containsKey(b)) return ;
//存在了俩,才看看是否同属一个集合?
Node aHead = findFather(nodes.get(a));
Node bHead = findFather(nodes.get(b));
//在同一个集合就算了
if (aHead != bHead){
Integer aSize = sizeMap.get(aHead);
Integer bSize = sizeMap.get(bHead);
//合并策略:小集合挂大集合
Node big = aSize >= bSize ? aHead : bHead;
Node small = big == aHead ? bHead : aHead;
parentMap.put(small, big);//小集合的代表换为big,挂好了,合并好了也
sizeMap.put(big, aSize + bSize);//大集合数量变了
sizeMap.remove(bSize);//小集合消失
}
}
//## 可以查当前并查集的集合数量:getSetNum()--本题中好像这个不重要
public int getStockSetNum(){
return sizeMap.size();//拢共多少个集合?本题不知道用还是不用
}
//## 对于本题,咱们还需要对应ACM输入格式,注册一个用户,会来一串股票,我们一次性构建独立集合,并union他们所有
//这个功能好比咱们普通并查集的构造函数一样,不过呢,本题的构造函数就随意了
public void add(String user, List<String> arr){
//送进来的是用户,还有它全部股票:一个字符串数组
//有了咱就不需要建了,直接合并即可
//同时,把用户,和股票所属关系表填好
HashSet<String> set = new HashSet<>(arr);
holder.put(user, set);
for(String str : arr){
if (!nodes.containsKey(str)) {
Node cur = new Node(str);
nodes.put(str, cur);//没有咱再考虑加
//新来的都是独立成集合的
parentMap.put(cur, cur);//自己代表自己
sizeMap.put(cur, 1);
}
}
//加完之后,立马把该用户的所有股票合并成一个集合,其实这时候,几乎相同的用户都合并在一起了
for (int i = 1; i < arr.size(); i++) {
union(arr.get(0), arr.get(i));//这用户的集合得聚到一起
}
}
//## 对于本题,我们需要查询用户user,系统会给它推荐多少股票?
//我们需要看看目前用户独立情况下,股票仓中的股票数量是多少?
public int query(String user){
if (!holder.containsKey(user)) return 0;//没这个用户,返回0;
//上面的holder保存的就是这个数据,好说不妨设为x
int x = holder.get(user).size();
//然后咱们就要考虑合user所有集合与别的集合,一连串合并之后,新集合的股票仓数量是y——这个过程其实加入的时候已经搞定了
//我们需要把这个用户原来没有的股票,互相加入自己的阵营
//也就是挨个查用户user的那些股票,是否与其他用户的股票是同一集合,是就让两者相互加
checkAndUnionTowUsers(user);
int y = holder.get(user).size();//合并后user用户的最新数量为y
//则合并之后给user推荐的股票数量是**y-x,这就是本题要的结果**
return y - x;
}
//### 中途,我们可能需要查一下,user的每个股票,它在不在其他的集合中?
// 在就合并,既然合并,那就要考虑更新holder,保证用户和股票是对应好的
public void checkAndUnionTowUsers(String user){//目前user它有的股票
HashSet<String> set = holder.get(user);//user的所有股票们
for(String u:holder.keySet()){
if (!u.equals(user)){//自己跟自己就不用查了
boolean in = false;
for(String otherStock:holder.get(u)){
//跟用户user挨个对比,看看在同一个集合就好,不在需要合并的
for(String stock:set){
if (isSameSet(otherStock, stock)){
in = true;//它背后俩集合一定在一起的
break;
}
//in是false,即不在一个集合,需要查,是否user,可能和现在的u有交集stock,有就要合并的
if (set.contains(otherStock)) union(otherStock, stock);
}
if (in) break;//我们需要互相补充然后直接退出不管
}
if (in){//我们需要互相补充然后直接退出不管
List<String> uNeed = new ArrayList<>();//加给当前user
List<String> userNeed = new ArrayList<>();//加给user的
for(String otherStock:holder.get(u)) {
//跟用户user挨个对比,看看在同一个集合就好,不在需要合并的
for (String stock : set) {//我们需要互相补充
if (!holder.get(user).contains(otherStock)) userNeed.add(otherStock);
if (!holder.get(u).contains(stock)) uNeed.add(stock);
}
}
for(String str:uNeed) holder.get(u).add(str);
for(String str:userNeed) holder.get(user).add(str);//互相加
}
}
}
}
}//并查集结束
//主函数,ACM输入格式
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int q = in.nextInt();//q个操作
in.nextLine();
//提前准备好并查集
UnionSet unionSet = new UnionSet();
while (q-- > 0){
//每操作一次q--
String s = in.nextLine();//一行字符串
String [] str = s.split(" ");
String user = str[1];//用户名字
if (str[0].equals("1")){
//1,注册,格式为:
//第一行输入1 name n,代表1个名字为anme的人注册了该系统,它关注了n只股票
//第二行输入n个仅仅包含英文名字母字符的str,代表这个人关注的股票名字
int n = str[2].toCharArray()[0] - '0';//转化为n个
//输入n个股票
List<String> stocks = new ArrayList<>();
String[] stk = in.nextLine().split(" ");
for (int i = 0; i < n; i++) {
stocks.add(stk[i]);//加入之后放入并查集
}
unionSet.add(user, stocks);
}else {//str[0].equals("2")
//2,查询,格式为:
//仅有一行,输入为2 name,代表询问该推荐系统,会给这个人推荐多少只股票。
int ans = unionSet.query(user);
System.out.println(ans == 0 ? "error" : ans);
}
}//q次操作结束
}//main结束
}
总结
提示:重要经验:
1)并查集核心参数nodes表,打包节点的,parentMap,并查集集合的代表节点,sizeMap表,每个结合有几个节点
2)本题外加一个哈希表holder,用来保存用户user手里有多少只股票的,然后并查集内部的加入函数变了,同时多了查询函数,查询的关键在于合并user和u之后,需要更新user和u双方手里的股票
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











