






一、概述
直入正题,首先,要明白相对于V1的什么问题,V2到底做了哪些改进,具体有什么作用。主要就是带着这三个问题对论文进行阅读探究,前一篇我已经写过了关于Bevformerv1的模块分析,感兴趣也可以去看看BEVformer论文模块解读-CSDN博客
二、Bevformer存在的问题
①由于Bevformer是一个二阶段的模型,第一阶段负责生成2D的多视图特征,第二阶段负责将特征转化为BEV空间下的进行推理,得到3D信息。也就是说损失从第二阶段反向传播到第一阶段的时候是间接的,其次BEV监督相对于image features而言是稀疏的。只有参与到object queries的少量BEV grids对loss有贡献。更进一步来说,只有这些少量grids所对应2D reference points周围的稀疏像素点才能获得监督信号。对于backbone来说不利于多视角特征的生成。
②在V1的decoder里面的head参考的是DETR3D的检测头,2D reference points是通过embedding生成的,也就是说参考点需要不断学习生成,会导致学习时间较长。
③Temporal encoder改进,在V1中只对前面几帧的BEV特征进行融合,但是这种继承式时域融合方式有遗忘的特点,即无法利用较长时间的历史信息。
三、v2改进
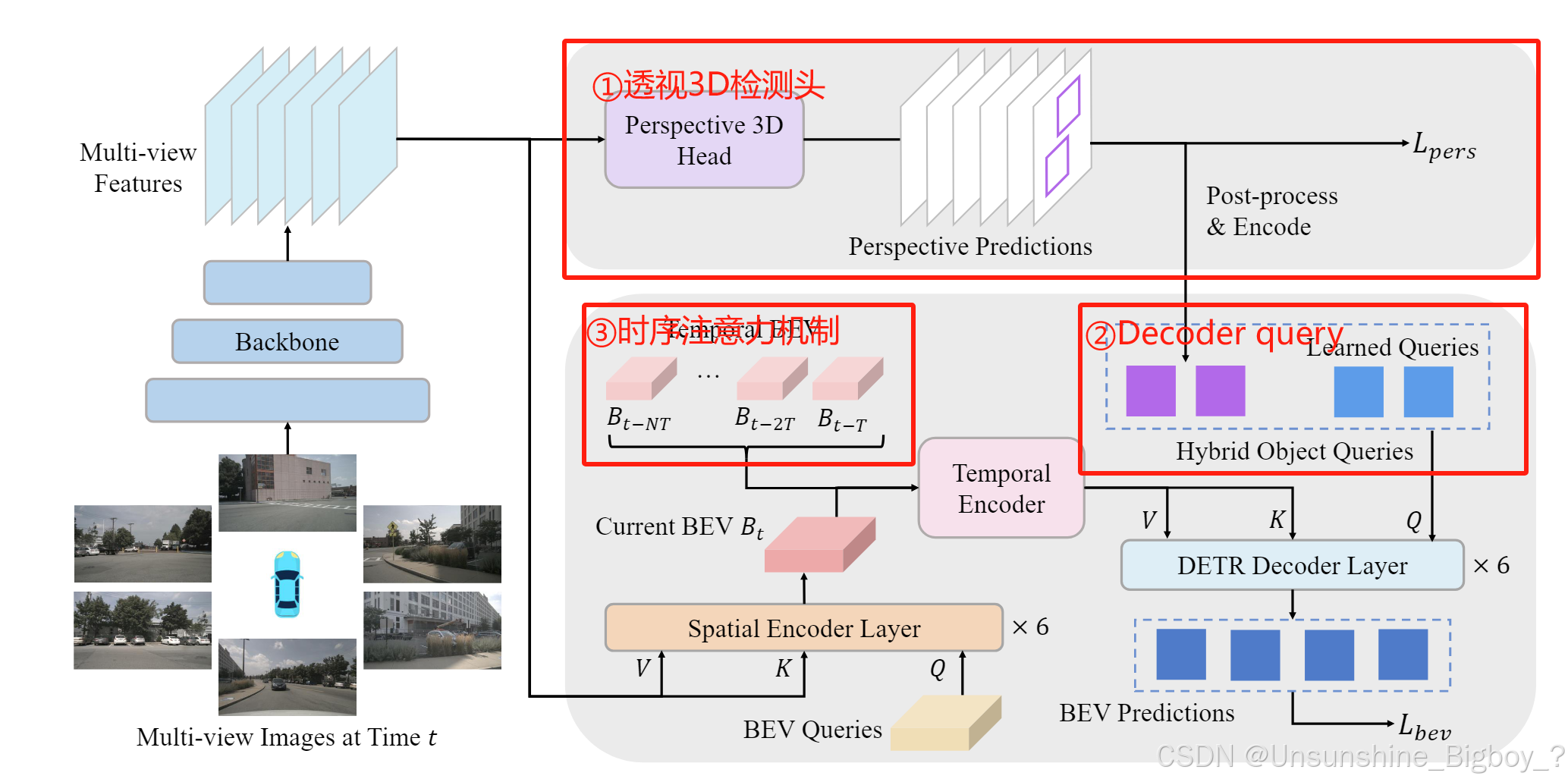
如上图所示,主要改进就是三点:
①透视3D检测头,将第一阶段推理得到的多视角几何特征,直接采用类似FCOS3D的检测头,它能预测3D B-boxes的中心位置(center location)、尺寸(size)、朝向(orientation)和投影的中心度(projected center-ness),并计算损失。通过这个透视3D检测头可以使得第一阶段的backbone监督更加直接。
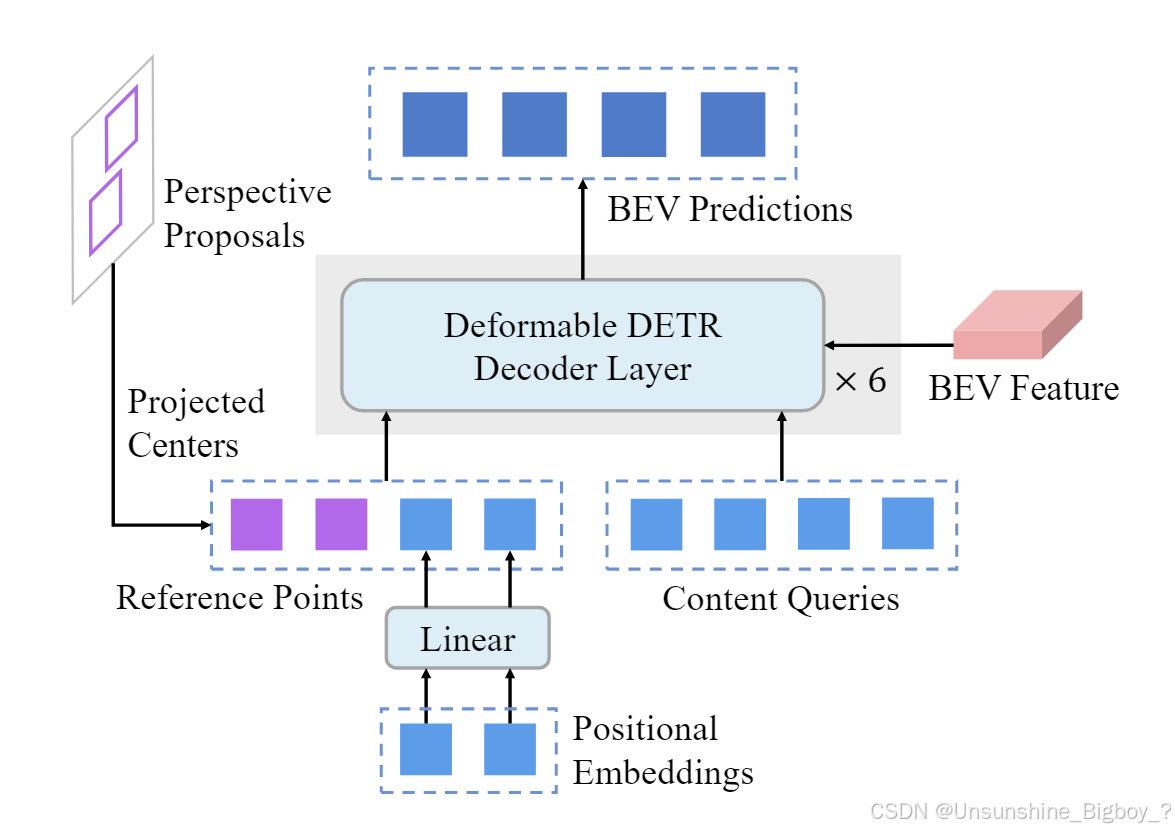
②Decoder的query的生成,在V1中是query和reference points都是通过embedding直接生成并学习的,这样缺点是需要不断学习来寻找正确的reference points。既然在一阶段3D检测头可以输出3D信息,这些信息可以经过后处理后作为先验加入到reference points中。也就是说,第一阶段大概推理出了物体在哪个位置,具体位置又第二阶段进行精细化的推理。如何生成混合Reference points:首先从透视头(perspective head)获取proposals,通过后处理选取其中一部分,把选出proposals在BEV 平面的投影box中心作为per-image reference points,然后与类似BEVFormer那样通过positional embedding来生成的per-dataset reference points合并在一起,作为整体的混合reference points。
③Temporal encoder改进,在V1中只对前面几帧的BEV特征进行融合,但是这种继承式时域融合方式有遗忘的特点,即无法利用较长时间的历史信息。具体方法是:针对任何一帧过去时刻k的BEV feature Bk ,先根据k时刻到当前时刻t的ego motion转移矩阵 Ttk=[R|t]∈SE3 对齐(双线性插值)到当前时刻得到 Bkt ,然后把对齐后的多帧历史BEV features和当前时刻BEV features在channel维度进行concat,最后采用residual模块降低channel数目。
四、作用
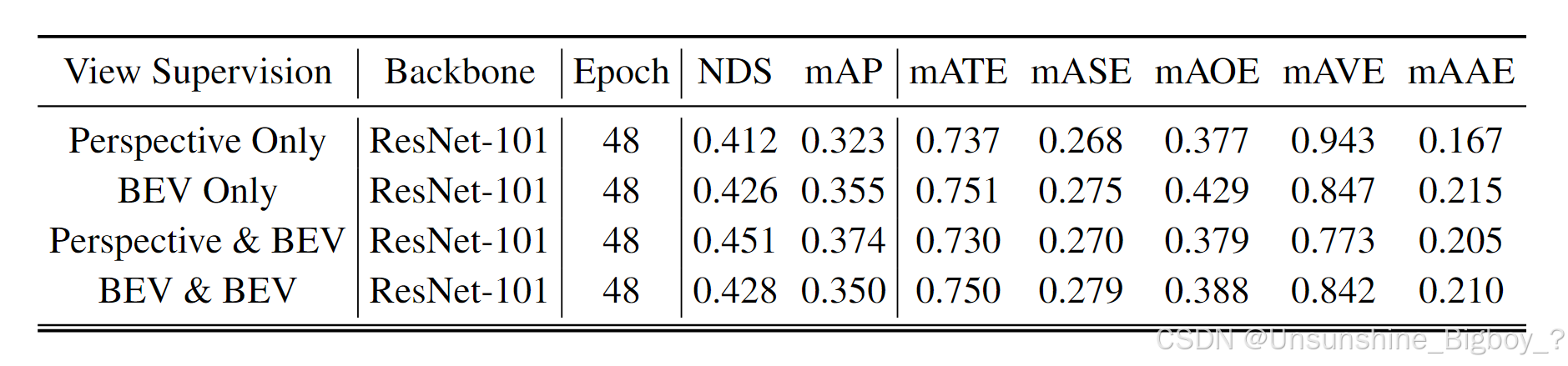
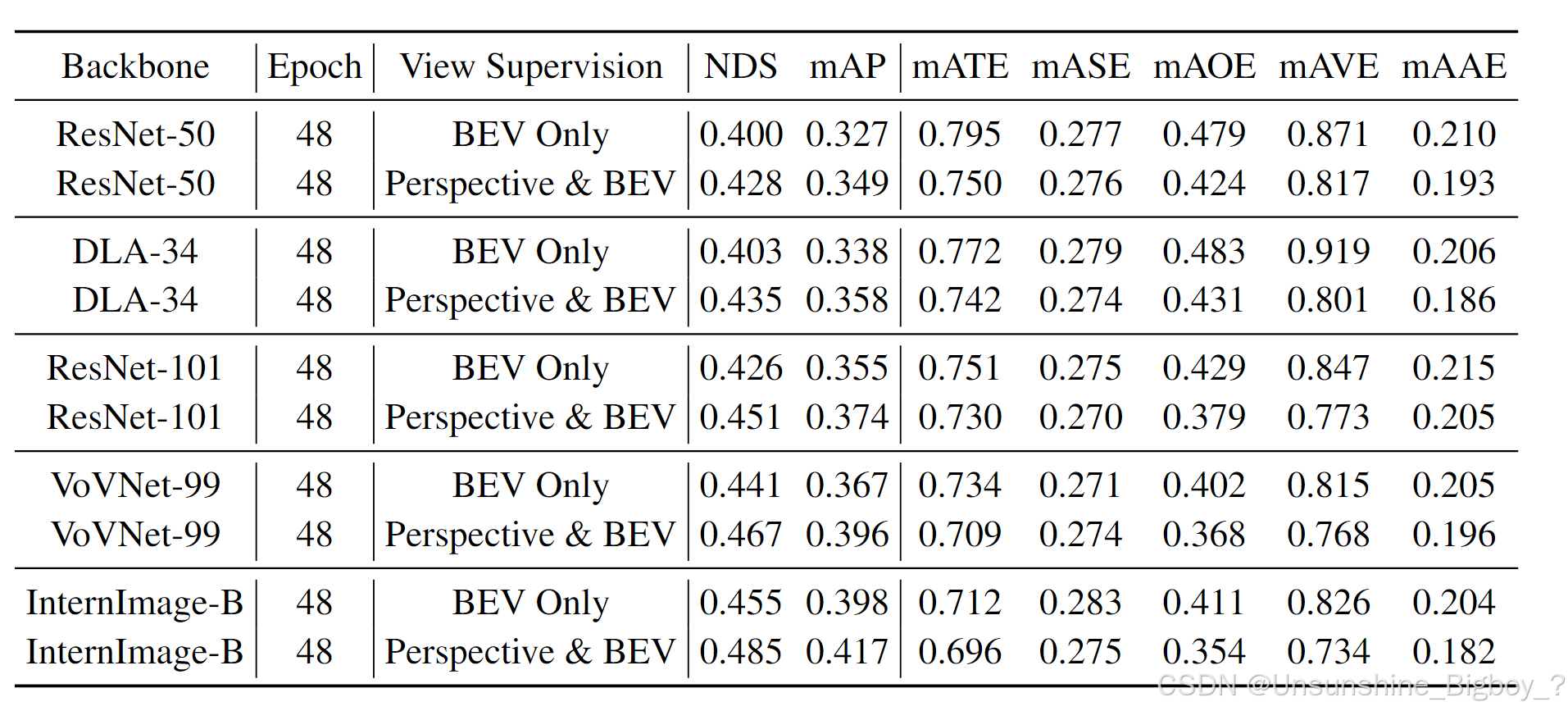
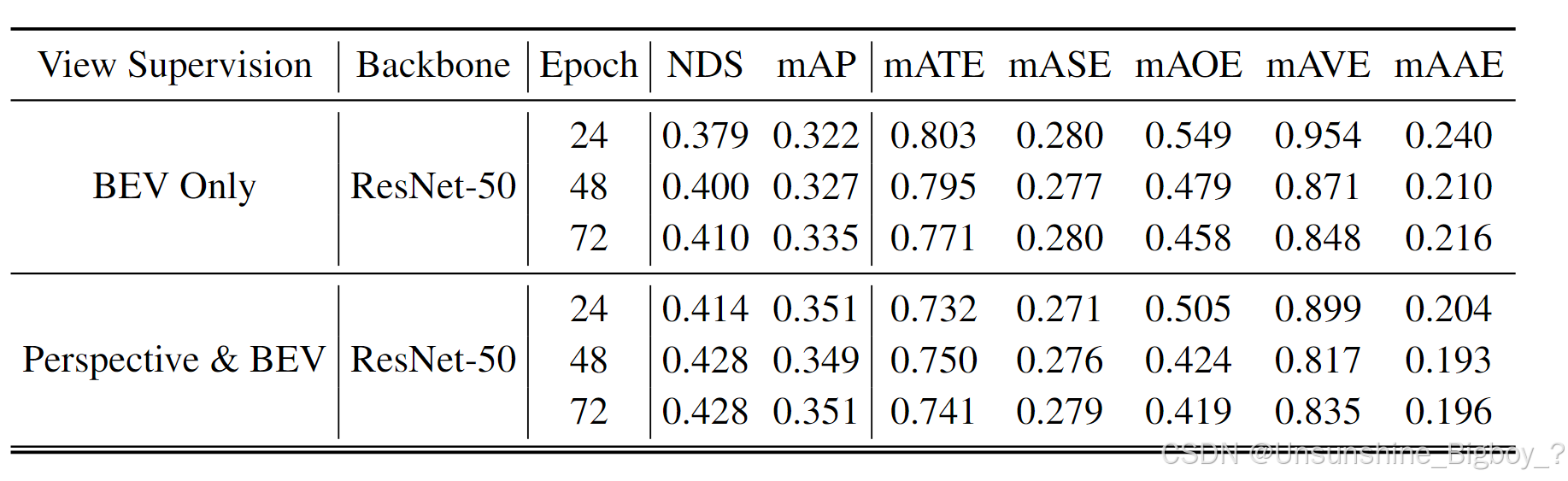
从实验结果可以观察到,加入透视检测头来监督第一阶段的backbone确实能够带来提升,一方面是由于对第一阶段的有效监督,另外一方面是源于对decoder中query的reference points先验。但是其实这也给模型的复杂度上升,论文没有给出具体推理时间、参数、等指标来证明高效性,到底这样做值不值得。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









