



引言:这是一个全民看视频、发视频的时代,身边越来越多的人发视频了,我制作视频的时候还是在大学时期用Premiere,处理音频用CoolEditor(早已改名为Edition),还有个Midi音乐,没想到这么多年,视频制作又换一种方式出现了,人人都会用剪映了,我有点Out了,最近研究了一下,先从扣图开始研究,基本能实现扣图的功能,但以我啥都要批量的陋习,我又把不安的小手伸向了大模型,今天来盘一下MattePro,看看效果。
一、剪映扣图扣视频试了一下
还是先赠送一下剪映扣像的方法分享一下,主要包括以下几个方式。
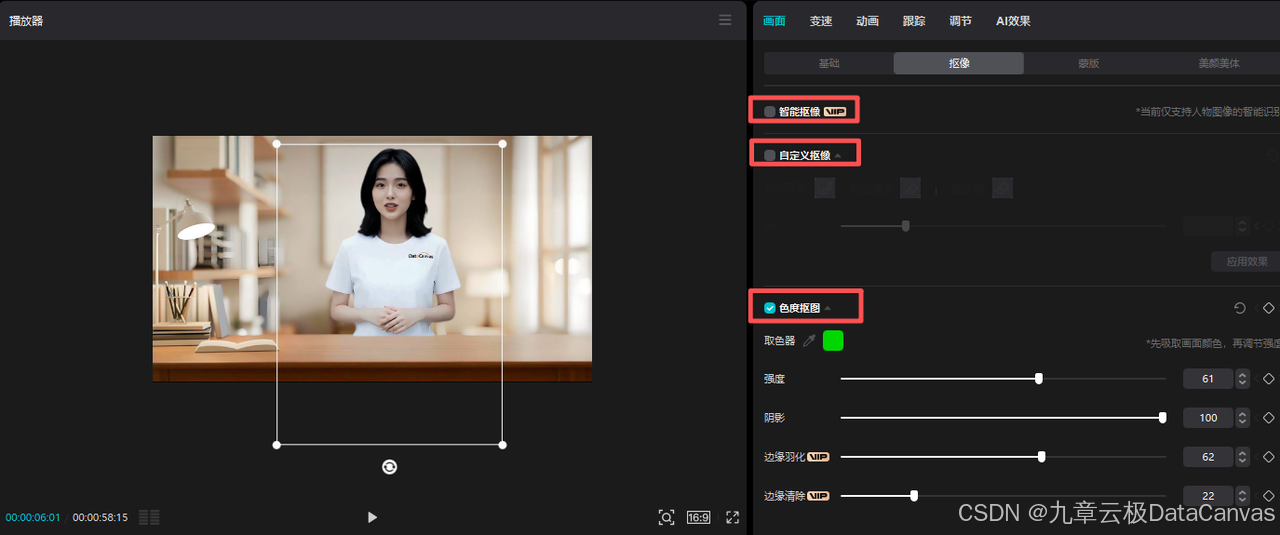
智能抠图:这是剪映中较为常用的一种抠图方式,操作简便,适用于人物或物体的抠取。用户只需点击“智能抠图”功能,系统会自动识别并抠出主体,支持更换背景等操作。智能抠图在处理人物背景简单、边缘清晰的素材时效果较好。
自定义抠像:相比智能抠图,自定义抠像提供了更多的控制选项,用户可以通过画笔工具手动调整抠图区域,适合处理复杂或精细的抠图任务。例如,用户可以使用快速画笔工具进行精细调整。
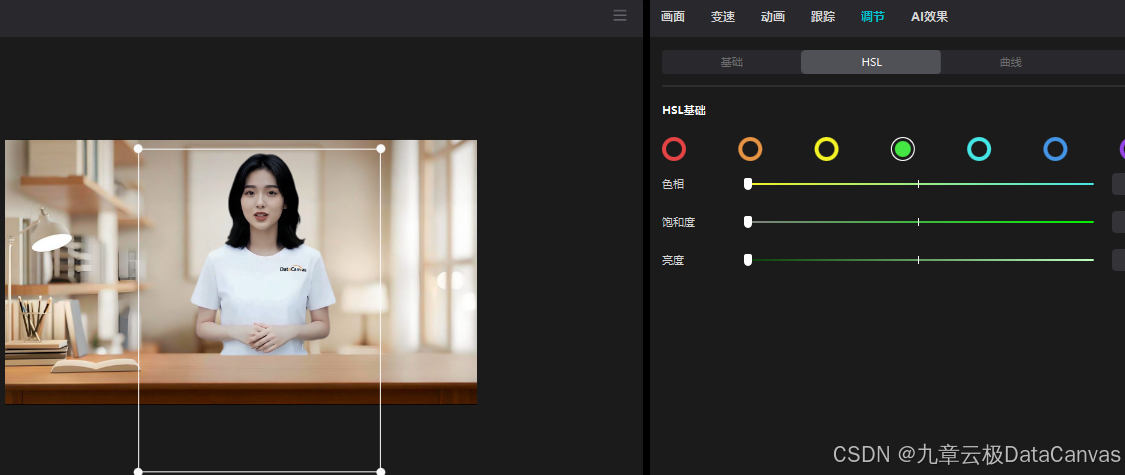
色度抠图:该方法适用于绿幕或橙色背景的素材,通过调整色度参数来实现抠图。例如,通过调整HSL参数可以精准抠取绿幕素材。
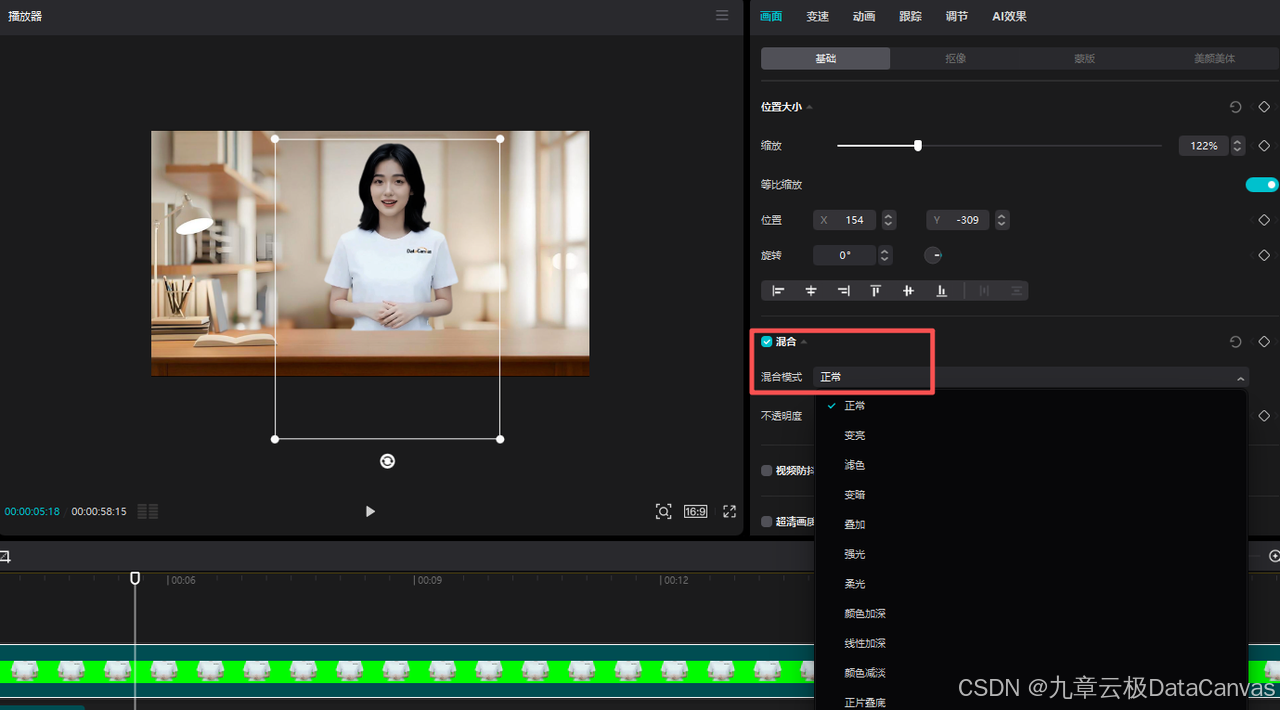
混合模式抠图:通过混合模式(如正片叠底、叠加、柔光等)可以实现更复杂的抠图效果。
但是,我的一贯作风是要实现批量的,连续点开剪映软件都是一个问题。
二、用大模型来扣图像与视频的图像
MattePro其实是把SAM2、BiRefNet都整合起来了,可以实现图像和视频的扣图,可以到发丝级别,效果非常好,就是扣视频时有一点点慢。我们制作数字人使用频率不会太高,耗时多点就多点吧,忍了,毕竟毕Wan2.2要快很多。
先介绍一下这两个名声在外的大模型。
SAM 2 和 BiRefNet 都是计算机视觉领域专注于图像分割的先进模型,但它们在设计目标、技术思路和应用场景上有着显著的差异。下面的表格能让你快速把握它们的核心特点。
| 特性维度 | SAM 2 (Segment Anything Model 2) | BiRefNet (Bilateral Reference Network) |
| 核心目标 | 通用型的“分割一切”模型,强调零样本泛化能力 | 专精于高分辨率二值化图像分割,追求极致精度 |
| 处理对象 | 统一处理图像与视频 | 主要针对静态图像 |
| 技术核心 | 基于提示的交互式分割,引入流式记忆机制处理时序信息 | 双边参考机制,融合底层细节与高层语义 |
| 主要优势 | 多功能性、实时性、强大的零样本迁移能力 | 在复杂边缘、细小结构分割上具有超高精度 |
| 典型应用 | 增强/虚拟现实(AR/VR)、视频编辑、自动驾驶、内容创作 | 图像抠图、医学影像分析、电商产品展示、卫星图像分析 |
🔧 技术原理深入
-
SAM 2 的记忆机制与统一架构 SAM 2 的强大之处在于其将图像视为单帧视频的统一视角。为了处理视频中随时间变化的信息,它引入了一个流式记忆机制。当处理视频时,模型会将先前帧中关于分割对象的信息(如外观、位置)存储在一个记忆库中。在处理新帧时,SAM 2 会通过一个“记忆注意”模块来回顾这些信息,从而在整个视频序列中保持对目标对象跟踪的一致性。这使得它能够智能地处理物体的出现、消失、被遮挡和重现等复杂情况。对于静态图片,这个记忆组件为空,模型就退化为一个强大的图像分割器。
-
BiRefNet 的双边参考机制 BiRefNet 的创新点在于其双边参考(Bilateral Reference) 设计,旨在解决高分辨率图像中细节保留的难题。该机制包含两个部分:
-
内部参考:模型在解码(重建图像)过程中,会直接参考原始高分辨率图像被划分的图像块。这确保了最底层的像素级细节信息能够被充分利用,避免因多次下采样和上采样造成的细节丢失。
-
外部参考:模型会利用通过计算得到的图像梯度图作为辅助信息。梯度图能突出显示物体的边缘和纹理变化区域,相当于告诉模型“应该重点关注这些地方”,从而显著提升对毛发、透明物体等细微边界的分割精度。这种机制使其特别擅长处理需要精细边缘的任务。
-
📊 性能与应用场景
-
SAM 2:通用性与实时性的标杆 SAM 2 在多项基准测试中表现出色,其处理速度相比前代提升显著,能够达到实时处理的要求(例如约每秒44帧)。它的应用场景非常广泛,几乎涵盖所有需要理解像素级内容的领域:
-
视频编辑:实现“一键抠视频”,快速替换背景或追踪特定物体。
-
混合现实(MR):实时分割和交互现实世界中的对象。
-
科学研究和数据标注:用于快速标注海量的图像和视频数据,提升科研效率。
-
-
BiRefNet:高精度分割的利器 BiRefNet 在多个高精度分割数据集(如DIS5K、HRSOD)上取得了领先的性能。它的应用场景更偏向于对分割质量有严苛要求的领域:
-
人像抠图与商业摄影:生成发丝级精度的透明背景,效果出众。
-
医学影像分析:精确分割细胞、器官或病变区域,辅助诊断。
-
工业视觉:例如对汽车等多角度、结构复杂的物体进行精细分割和检测。
-
💎 如何选择
简单来说,你的选择完全取决于任务需求:
-
如果你需要处理视频,或者希望一个模型就能灵活应对各种未知的图像分割任务(通过点、框等简单提示),SAM 2 是更合适的选择。
-
如果你的工作是处理高分辨率的静态图片,并且对边缘精度、细节保留的要求极高(如专业抠图),那么 BiRefNet 更能满足你的需要。
到这里,你是不是还在想我是选SAM2还是BiRefNet呢?
打住,现在好了,你不用选了,成年人,选都要。这不,那就选MattePro,它就是将这两个大模型都封装在一起的大模型开源应用。当然,两个模型的在线体验地址也双手奉上:
https://huggingface.co/spaces/ZhengPeng7/BiRefNet_demo
https://huggingface.co/spaces/fffiloni/SAM2-Image-Predictor
三、MattePro部署与应用实践
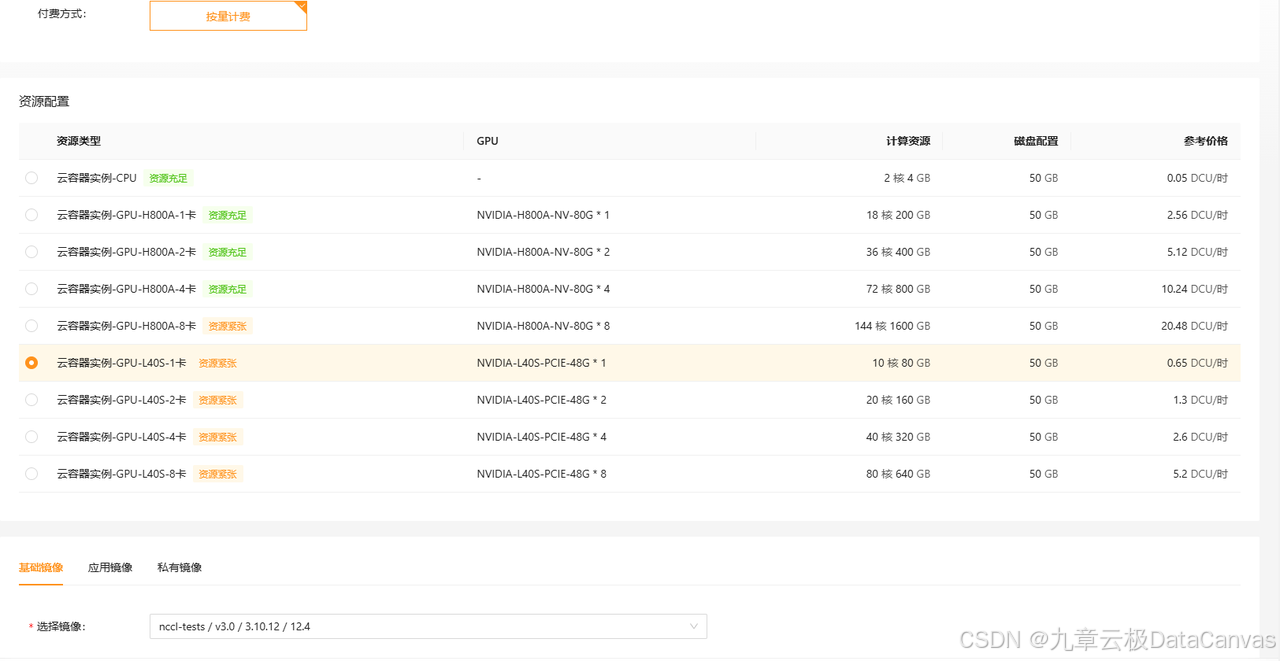
话不多说,开整。本次部署环境仍然为AlayaNeW云容器实例CCI,为啥用它呢?核心理由是便宜,按秒付费,GPU动态挂载,50G存储免费容量,特别适合非常有弹性算力的需求的朋友。我选了配置如下:

当然也可以选L40S 48G的GPU,足够了。镜像还是选带GPU的基础镜像nccl-tests。
1、开通CCI(云容器实例)
注册并开通CCI:https://www.alayanew.com/?id=online
关于CCI的介绍请移步:https://www.alayanew.com/product/cloudContainer,关于CCI的使用请参考之前的文章:https://mp.weixin.qq.com/s/xuYAmigHFIQ1MCc6H5FgJg
选一下如图所示的镜像:
2、下载github代码及相关模型权重
MattePro的github代码下载地址:https://github.com/ChenyiZhang007/MattePro
模型权重下载地址:
MEMatte.pth:https://drive.usercontent.google.com/download?id=1R5NbgIpOudKjvLz1V9M9SxXr1ovAmu3u&export=download&authuser=0&confirm=t&uuid=b11d081d-86c9-408d-b022-1605530a3db3&at=AKSUxGNTRsg1dEIkK_gCP-0YixTT%3A1762227843826
MattePro.pth:https://drive.usercontent.google.com/download?id=1b8eXjzDRPfF_SU-4nULc_YUZ9ytDqekh&export=download&authuser=0&confirm=t&uuid=82587791-296d-447a-b5a4-5a224674d907&at=AKSUxGP1XEzf4otDz3qPnu5-W_vI%3A1762227561703
BiRefNet-HRSOD_D-epoch_130.pth
https://drive.usercontent.google.com/download?id=1f7L0Pb1Y3RkOMbqLCW_zO31dik9AiUFa&export=download&authuser=0&confirm=t&uuid=3c1fbf8a-e457-42b7-9f17-19963897cb33&at=AKSUxGPPg-yOq9qAtkSeGWUJcgjr%3A1762236467824
下载后目录结构如下:我将模型权重放到新创建的weights目录下。
3、MattePro安装过程
1.安装Python环境
conda create -n mattepro python==3.10
conda activate mattepro
当然也可以用python -m venv myenv命令安装。
2.安装torch相关包
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu121
pip install wheel
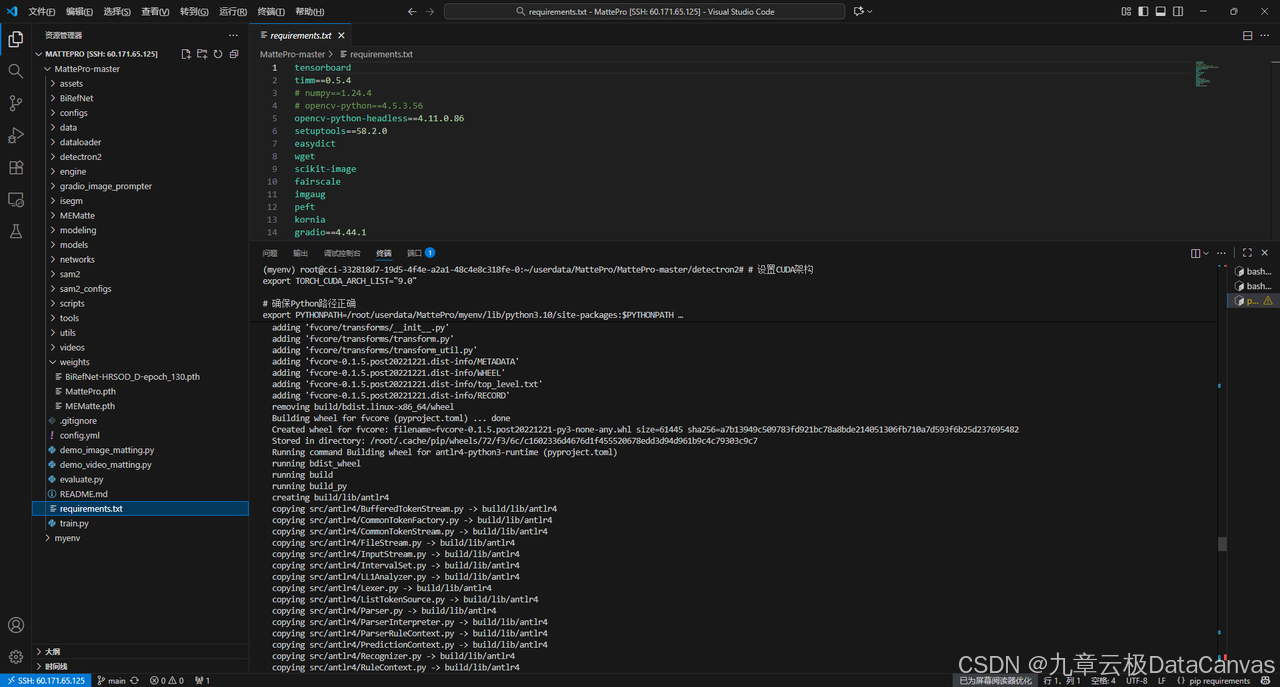
3.安装requirements.txt中的包
pip install -r requirements.txt
整个过程最重要的是detectron2的安装,按官网的以下代码安装报错了:
python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
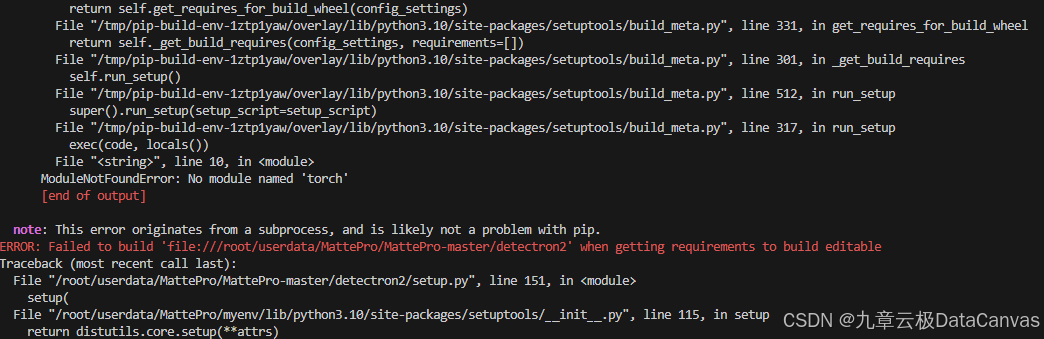
经多次测试,把Pytorch重装了也不行,最后按以下方式安装成功:
-
激活虚拟环境
source /root/userdata/MattePro/myenv/bin/activate
-
设置环境变量
export TORCH_CUDA_ARCH_LIST="9.0"
export FORCE_CUDA=1
export PYTHONPATH=/root/userdata/MattePro/myenv/lib/python3.10/site-packages:$PYTHONPATH
-
进入detectron2目录
cd /root/userdata/MattePro/MattePro-master/detectron2
-
清理可能的旧构建
rm -rf build/ **/*.so
-
安装(使用清华镜像)
pip install -e . \
--no-build-isolation \
--index-url https://pypi.tuna.tsinghua.edu.cn/simple
上述代码也可以一次性运行。
-
验证
python -c "
import torch
print('PyTorch版本:', torch.__version__)
print('CUDA可用:', torch.cuda.is_available())
import detectron2
print('Detectron2版本:', detectron2.__version__)
from detectron2 import model_zoo
print('模型库加载成功!')
如果碰到其它问题,可以直接将错误信息发给DeepSeek或Qwen,让大模型帮你解决。
四、验证效果
1.扣图像
python demo_image_matting.py
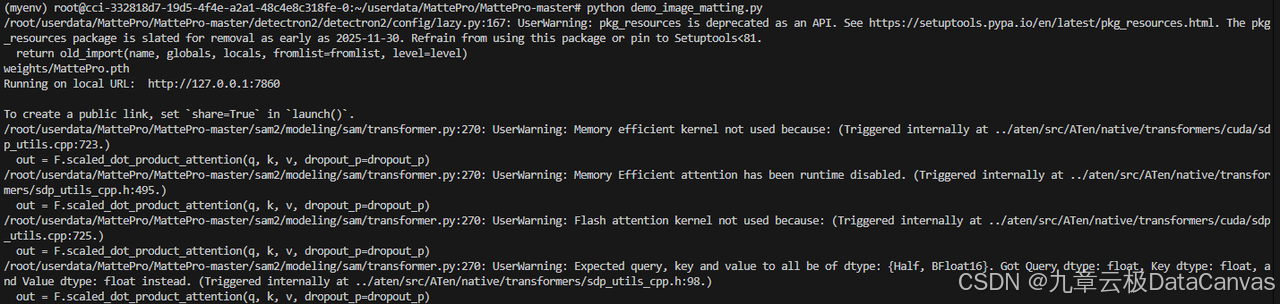
运行并访问启动的网页:
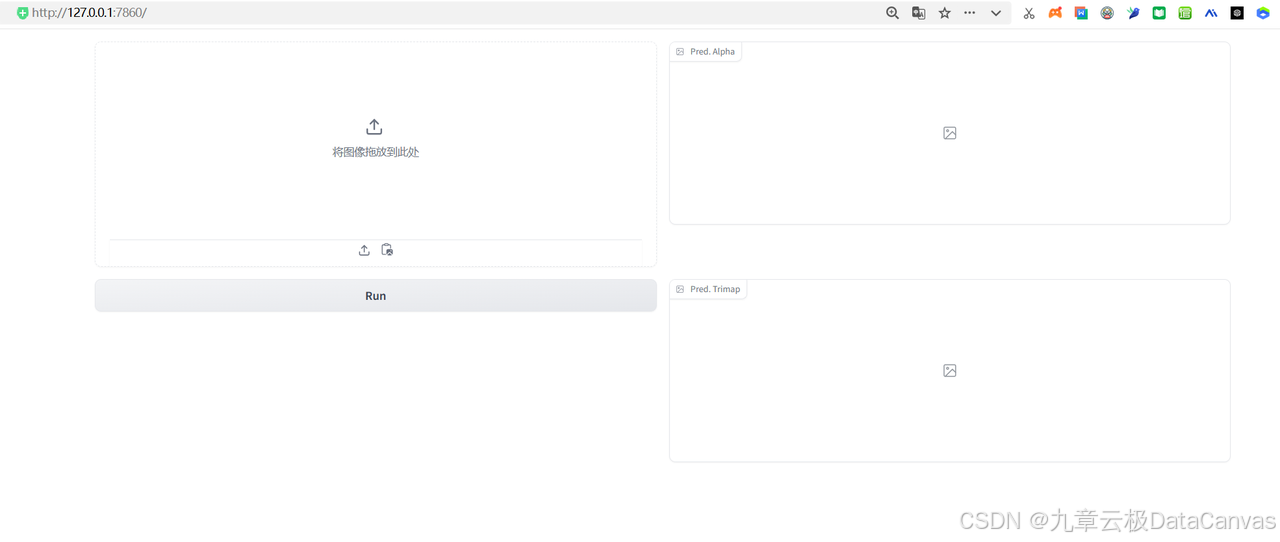
通过鼠标来选择需要扣取的区域,如果是纯色背景基本不需要点选:
-
单击前景区域上的鼠标左键
-
单击未知区域上的鼠标滚轮
-
单击背景区域上的鼠标右键
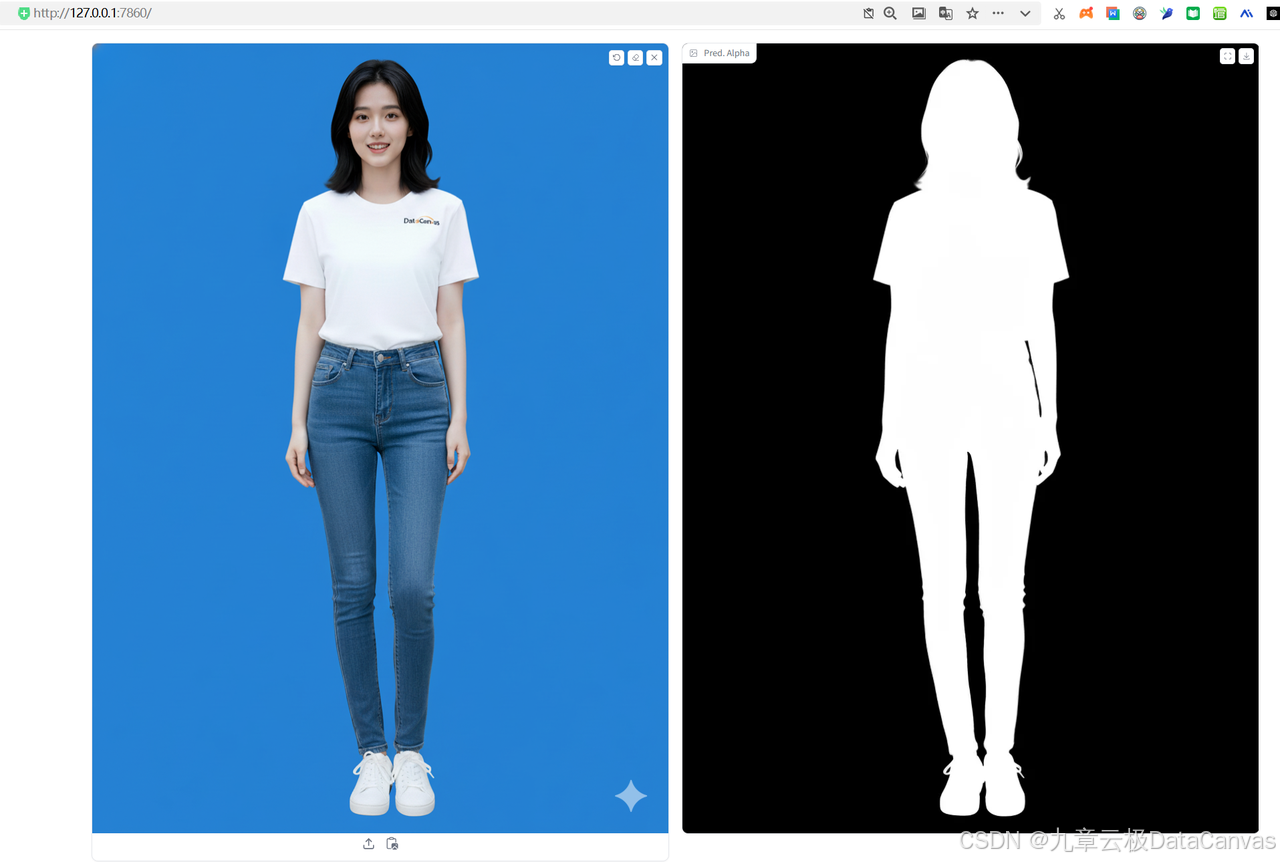
咋的,图呢?咋扣一个空白出来了,原来官方代码只能扣出Alpha通道图像,扣完啥都没有了。
我改了改代码:实现RGB扣像:
import argparse
import gradio as gr
from gradio_image_prompter import ImagePrompter
from detectron2.config import LazyConfig, instantiate
from detectron2.checkpoint import DetectionCheckpointer
import cv2
import numpy as np
import torch
import torch.nn.functional as F
import torchvision
from PIL import Image
def matting_inference(model,rawimg,trimap,device):
data = {}
data['trimap'] = torchvision.transforms.functional.to_tensor(trimap)[0:1, :, :].unsqueeze(0)
data['image'] = torchvision.transforms.functional.to_tensor(rawimg).unsqueeze(0)
for k in data.keys():
data[k].to(model.device)
patch_decoder = True
output = model(data, patch_decoder)[0]['phas'].flatten(0, 2)
# output = model(data, patch_decoder)['phas'].flatten(0, 2)
# trimap = data['trimap'].squeeze(0).squeeze(0)
# output[trimap == 0] = 0
# output[trimap == 1] = 1
output *= 255
output = output.cpu().numpy().astype(np.uint8)[:,:,None]
return output
def load_matter(ckpt_path, device):
"""
Load the matting model.
"""
cfg = LazyConfig.load('MEMatte/configs/MixData_ViTMatte_S_topk0.25_1024_distill.py')
cfg.model.teacher_backbone = None
cfg.model.backbone.max_number_token = 12000
matmodel = instantiate(cfg.model)
matmodel = matmodel.to(device)
matmodel.eval()
DetectionCheckpointer(matmodel).load(ckpt_path)
return matmodel
def load_model(config_path, ckpt_path, device):
cfg = LazyConfig.load(config_path)
model = instantiate(cfg.model)
model.lora_rank = 4
model.lora_alpha = model.lora_rank
model.init_lora()
model.to(device)
checkpoint = torch.load(ckpt_path, map_location=device)
new_state_dict = {key.replace("module.", ""): value for key, value in checkpoint['state_dict'].items()}
model.load_state_dict(new_state_dict)
model.eval()
print(ckpt_path)
return model
def preprocess_inputs(batched_inputs,device):
"""
Normalize, pad and batch the input images.
"""
pixel_mean = [123.675 / 255., 116.280 / 255., 103.530 / 255.],
pixel_std = [58.395 / 255., 57.120 / 255., 57.375 / 255.],
pixel_mean = torch.Tensor(pixel_mean).view(-1, 1, 1).to(device)
pixel_std = torch.Tensor(pixel_std).view(-1, 1, 1).to(device)
output = dict()
if "alpha" in batched_inputs:
alpha = batched_inputs["alpha"].to(device)
else:
alpha = None
bbox = batched_inputs["bbox"].to(device)
click = batched_inputs["click"].to(device)
images = batched_inputs["image"].to(device)
images = (images - pixel_mean) / pixel_std
assert images.shape[-2] == images.shape[-1] == 1024
if 'trimap' in batched_inputs.keys():
trimap = batched_inputs["trimap"].to(device)
assert len(torch.unique(trimap)) <= 3
else:
trimap = None
output['images'] = images
output['bbox'] = bbox
output['click'] = click
output['alpha'] = alpha
output['trimap'] = trimap
if 'hr_images' in batched_inputs.keys():
hr_images = batched_inputs["hr_images"].to(device)
hr_images = (hr_images - pixel_mean) / pixel_std
_, _, H, W = hr_images.shape
if hr_images.shape[-1] % 16 != 0 or hr_images.shape[-2] % 16 != 0:
new_H = (16 - hr_images.shape[-2] % 16) + H if hr_images.shape[-2] % 16 != 0 else H
new_W = (16 - hr_images.shape[-1] % 16) + W if hr_images.shape[-1] % 16 != 0 else W
new_hr_images = torch.zeros((hr_images.shape[0], hr_images.shape[1], new_H, new_W)).to(device)
new_hr_images[:,:,:H,:W] = hr_images[:,:,:,:]
del hr_images
hr_images = new_hr_images
output['hr_images'] = hr_images
output['hr_images_ori_h_w'] = (H, W)
if 'dataset_name' in batched_inputs.keys():
output['dataset_name'] = batched_inputs["dataset_name"]
output['condition'] = None
return output
def transform_image_bbox(prompts):
if len(prompts["points"]) != 1:
raise gr.Error("Please input only one BBox.", duration=5)
[[x1, y1, idx_3, x2, y2, idx_6]] = prompts["points"]
if idx_3 != 2 or idx_6 != 3:
raise gr.Error("Please input BBox instead of point.", duration=5)
x1, y1, x2, y2 = int(x1), int(y1), int(x2), int(y2)
img = prompts["image"]
ori_H, ori_W, _ = img.shape
scale = 1024 * 1.0 / max(ori_H, ori_W)
new_H, new_W = ori_H * scale, ori_W * scale
new_W = int(new_W + 0.5)
new_H = int(new_H + 0.5)
img = cv2.resize(img, (new_W, new_H), interpolation=cv2.INTER_LINEAR)
padding = np.zeros([1024, 1024, 3], dtype=img.dtype)
padding[: new_H, : new_W, :] = img
img = padding
# img = img[:, :, ::-1].transpose((2, 0, 1)).astype(np.float32) / 255.0
img = img.transpose((2, 0, 1)).astype(np.float32) / 255.0
[[x1, y1, _, x2, y2, _]] = prompts["points"]
x1, y1, x2, y2 = int(x1 * scale + 0.5), int(y1 * scale + 0.5), int(x2 * scale + 0.5), int(y2 * scale + 0.5)
offset = 10
bbox = np.clip(np.array([[x1-offset, y1-offset, x2+offset, y2+offset]]) * 1.0, 0, 1024.0)
return img, bbox, (ori_H, ori_W), (new_H, new_W)
def resize_coordinates(points, orig_width, orig_height, target_size=1024):
"""
将原图坐标点转换为目标分辨率下的坐标点,同时保持flag位不变。
参数:
points: np.ndarray, 形状为(n, 3),表示 n 个点的坐标和flag。
orig_width: int, 原图的宽度。
orig_height: int, 原图的高度。
target_size: int, 目标图像的边长,默认为 1024。
返回:
np.ndarray, 形状为(n, 3),转换后的坐标和原始flag。
"""
points = [[coord[0], coord[1], flag] for coord, flag in points]
points = np.array(points) # 转换为 NumPy 数组
# 计算宽度和高度的缩放比例
scale_x = target_size / orig_width
scale_y = target_size / orig_height
# 仅缩放坐标部分
scaled_points = points.copy()
scaled_points[:, 0] = points[:, 0] * scale_x # 缩放x坐标
scaled_points[:, 1] = points[:, 1] * scale_y # 缩放y坐标
# flag部分保持不变
return scaled_points
def resize_box(box, ori_H, ori_W):
[[x1, y1, _, x2, y2, _]] = box
x1, y1, x2, y2 = int(x1), int(y1), int(x2), int(y2)
# Adjust bbox coordinates to match the new image size
scale_x = 1024.0 / ori_W
scale_y = 1024.0 / ori_H
x1, y1, x2, y2 = int(x1 * scale_x), int(y1 * scale_y), int(x2 * scale_x), int(y2 * scale_y)
bbox = np.clip(np.array([[x1, y1, x2, y2]]) * 1.0, 0, 1024.0)
return bbox
def resize_click(clicks, ori_H, ori_W):
clicks = [[click[0],click[1],click[2]] for click in clicks]
clicks = np.array(clicks)
# 计算宽度和高度的缩放比例
scale_x = 1024 / ori_W
scale_y = 1024 / ori_H
# 仅缩放坐标部分
scaled_points = clicks.copy()
scaled_points[:, 0] = clicks[:, 0] * scale_x # 缩放x坐标
scaled_points[:, 1] = clicks[:, 1] * scale_y # 缩放y坐标
# flag部分保持不变
return scaled_points.astype(int)
def enlarge_and_mask(image, bbox, scale=1.1):
"""
放大框的尺寸,并将框外区域设置为0像素。如果框超出了图像范围,会限制框在图像范围内。
:param image: 输入图像 (numpy 数组)
:param bbox: 框的坐标,格式为 [x1, y1, x2, y2]
:param scale: 放大比例 (默认为1.1,表示放大10%)
:return: 处理后的图像
"""
# 获取原始框坐标
x1, y1, x2, y2 = bbox[0][0], bbox[0][1], bbox[0][3], bbox[0][4]
# 计算框的中心和宽高
center_x = (x1 + x2) / 2
center_y = (y1 + y2) / 2
width = x2 - x1
height = y2 - y1
# 放大框的尺寸
new_width = width * scale
new_height = height * scale
# 重新计算放大后的框坐标
new_x1 = int(center_x - new_width / 2)
new_y1 = int(center_y - new_height / 2)
new_x2 = int(center_x + new_width / 2)
new_y2 = int(center_y + new_height / 2)
# 限制框坐标在图像范围内
new_x1 = max(new_x1, 0)
new_y1 = max(new_y1, 0)
new_x2 = min(new_x2, image.shape[1])
new_y2 = min(new_y2, image.shape[0])
# 创建一个与原图相同大小的全黑图像
new_image = np.zeros_like(image)
# 提取图像中框内的区域并放置到新的图像上
new_image[new_y1:new_y2, new_x1:new_x2] = image[new_y1:new_y2, new_x1:new_x2]
return new_image
def resize_image_bbox(prompts,box_aug):
# get click and bbox
click = []
bbox = []
for point in prompts["points"]:
if point[3] != 0.0 and point[4] != 0.0:
bbox.append(point)
else:
if point[2]==1:
click.append([point[0],point[1],1])
if point[2]==5:
click.append([point[0],point[1],4])
if point[2]==0:
click.append([point[0],point[1],0])
# get image
img = prompts["image"]
if box_aug:
img = enlarge_and_mask(img, bbox, scale=1.1)
ori_H, ori_W, _ = prompts["image"].shape
img = cv2.resize(img, (1024, 1024), interpolation=cv2.INTER_LINEAR)
img = img.transpose((2, 0, 1)).astype(np.float32) / 255.0
# compute click and bbox
if not bbox:
bbox = [[-1,-1,-1,-1]]
else:
bbox = resize_box(bbox, ori_H, ori_W)
if not click:
click = [[-1,-1,-1]]
else:
click = resize_click(click, ori_H, ori_W)
return img, np.array(click), np.array(bbox), (ori_H, ori_W), (1024, 1024)
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('--mattepro-config-path', default='configs/MattePro_SAM2.py', type=str)
parser.add_argument('--mattepro-ckpt-path', default='weights/MattePro.pth', type=str)
parser.add_argument('--mematte-ckpt-path', default='weights/MEMatte.pth', type=str)
parser.add_argument('--device', default='cuda:0', type=str)
parser.add_argument('--box-aug', default=False, type=bool)
parser.add_argument('--show-trimap', default=True, type=bool)
return parser.parse_args()
if __name__ == '__main__':
args = parse_args()
device = args.device
model = load_model(args.mattepro_config_path, args.mattepro_ckpt_path, device)
matter = load_matter(args.mematte_ckpt_path, device)
def inference_image(prompts):
image, click, bbox, ori_H_W, pad_H_W = resize_image_bbox(prompts,args.box_aug)
input_data = {
'image': torch.from_numpy(image)[None].to(model.device),
'bbox': torch.from_numpy(bbox)[None].to(model.device),
'click': torch.from_numpy(click)[None].to(model.device),
}
with torch.no_grad():
inputs = preprocess_inputs(input_data, device)
images, bbox, gt_alpha, trimap, condition = inputs['images'], inputs['bbox'], inputs['alpha'], inputs['trimap'], inputs['condition']
click = inputs['click']
if model.backbone_condition:
condition_proj = model.condition_embedding(condition)
elif model.backbone_bbox_prompt is not None or model.bbox_prompt_all_block is not None:
condition_proj = bbox
else:
condition_proj = None
prompt = (click, bbox)
pred = model.forward((images, prompt))
pred = F.interpolate(pred, size=prompts["image"].shape[0:2], mode='bilinear', align_corners=False)
trimap = torch.clip(torch.argmax(pred, dim=1) * 128, min=0, max=255)[0].cpu().numpy().astype(np.uint8)
# Apply matting inference to the result
alpha = matting_inference(matter, prompts["image"], trimap, device).squeeze()
# Return the results: compose RGBA foreground and return with trimap if requested
if args.show_trimap:
img_np = prompts["image"].copy()
if img_np.dtype != np.uint8:
img_np = (img_np * 255).astype(np.uint8)
a = alpha if alpha.ndim == 2 else alpha[:, :, 0]
rgba_pil = Image.fromarray(np.dstack((img_np, a.astype(np.uint8))))
return rgba_pil, Image.fromarray(trimap)
else:
img_np = prompts["image"].copy()
if img_np.dtype != np.uint8:
img_np = (img_np * 255).astype(np.uint8)
a = alpha if alpha.ndim == 2 else alpha[:, :, 0]
rgba_pil = Image.fromarray(np.dstack((img_np, a.astype(np.uint8))))
return rgba_pil
with gr.Blocks() as demo:
with gr.Row():
with gr.Column(scale=45):
img_in = ImagePrompter(type='numpy', show_label=False, label="Input Image")
with gr.Column(scale=45):
img_out = gr.Image(type='pil', label="Pred. Alpha")
with gr.Row():
with gr.Column(scale=45):
bt = gr.Button()
if args.show_trimap:
with gr.Column(scale=45):
trimap_out = gr.Image(type='pil', label="Pred. Trimap")
if args.show_trimap:
bt.click(inference_image, inputs=[img_in], outputs=[img_out,trimap_out])
else:
bt.click(inference_image, inputs=[img_in], outputs=[img_out])
demo.launch()
'''
按以下方式执行:
python demo_image_matting_2.py --mattepro-config-path configs/MattePro_SAM2.py --mattepro-ckpt-path weights/MattePro.pth --mematte-ckpt-path weights/MEMatte.pth --device cuda:0
'''
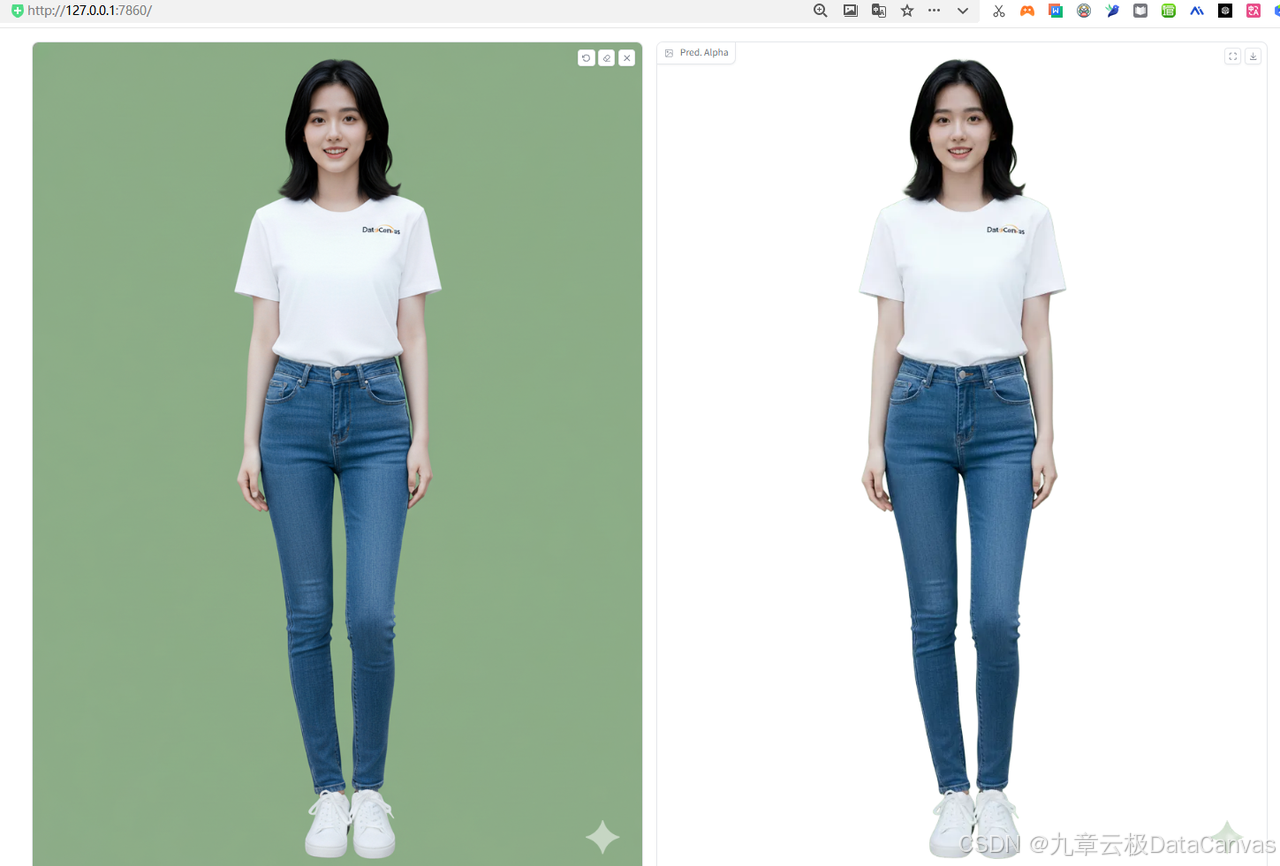
再来弄一个保存绿色背景的,以便于后边在剪映里扣图,修改代码:
import gradio as gr
from PIL import Image
import numpy as np
def echo(image):
# image will be a PIL.Image or numpy array depending on Gradio
if isinstance(image, np.ndarray):
return Image.fromarray(image)
return image
with gr.Blocks() as demo:
inp = gr.Image(type='pil')
out = gr.Image(type='pil')
btn = gr.Button('Run')
btn.click(echo, inputs=[inp], outputs=[out])
if __name__ == '__main__':
demo.launch()
'''
python demo_image_matting_2.py --mattepro-config-path configs/MattePro_SAM2.py --mattepro-ckpt-path weights/MattePro.pth --mematte-ckpt-path weights/MEMatte.pth --device cuda:0
'''

2.扣视频
官方代码视频也只能扣出Alpha通道(显示白色,没有原图像)。我重新修改了程序,以实现原视频的扣取代码如下,导出带Alpha通道的视频,确保Alpha通道视频文件格式正确,通常为 .mov格式,并且编码方式支持透明通道(例如ProRes 4444或H.264 with Alpha)。
代码如下:
import os
import sys
sys.path.append('./BiRefNet')
import cv2
import numpy as np
import torch
import torch.nn.functional as F
from PIL import Image
import torchvision
import subprocess
import shutil
from tqdm import tqdm
from detectron2.config import LazyConfig, instantiate
from detectron2.checkpoint import DetectionCheckpointer
import argparse
import numpy as np
from BiRefNet.models.birefnet import BiRefNet
from torchvision import transforms
def init_biref(device):
model = BiRefNet(bb_pretrained=False)
# Load model weights
state_dict = torch.load('weights/BiRefNet-HRSOD_D-epoch_130.pth', map_location='cpu', weights_only=True)
model.load_state_dict(state_dict)
model = model.to(device)
model.eval()
return model
def matting_inference(model, rawimg, trimap, device):
"""
Perform matting inference.
"""
data = {}
data['trimap'] = torchvision.transforms.functional.to_tensor(trimap)[0:1, :, :].unsqueeze(0)
data['image'] = torchvision.transforms.functional.to_tensor(rawimg).unsqueeze(0)
for k in data.keys():
data[k].to(model.device)
patch_decoder = True
output = model(data, patch_decoder)[0]['phas'].flatten(0, 2)
# output = model(data, patch_decoder)['phas'].flatten(0, 2)
# trimap = data['trimap'].squeeze(0).squeeze(0)
# output[trimap == 0] = 0
# output[trimap == 1] = 1
output *= 255
output = output.cpu().numpy().astype(np.uint8)[:,:,None]
return output
def load_matter(ckpt_path, device):
"""
Load the matting model.
"""
cfg = LazyConfig.load('MEMatte/configs/MixData_ViTMatte_S_topk0.25_1024_distill.py')
cfg.model.teacher_backbone = None
cfg.model.backbone.max_number_token = 12000
matmodel = instantiate(cfg.model)
matmodel = matmodel.to(device)
matmodel.eval()
DetectionCheckpointer(matmodel).load(ckpt_path)
return matmodel
def load_model(config_path, ckpt_path, device):
cfg = LazyConfig.load(config_path)
model = instantiate(cfg.model)
model.lora_rank = 4
model.lora_alpha = model.lora_rank
model.init_lora()
model.to(device)
checkpoint = torch.load(ckpt_path, map_location=device)
new_state_dict = {key.replace("module.", ""): value for key, value in checkpoint['state_dict'].items()}
model.load_state_dict(new_state_dict)
model.eval()
return model
def preprocess_image(image, image_size):
"""
Preprocess the image for inference.
Args:
image_path (str): Path to the input image.
image_size (tuple): Target size (height, width).
Returns:
torch.Tensor: Preprocessed image tensor.
"""
# Load image using PIL
# image = Image.open(image_path).convert('RGB')
image = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
# Define the transform pipeline
transform_image = transforms.Compose([
transforms.Resize(image_size[::-1]), # Resize to target size
transforms.ToTensor(), # Convert to tensor
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # Normalize
])
# Apply transformations
image = transform_image(image)
return image.unsqueeze(0) # Add batch dimension
def get_bbox_from_birefnet(model,image,device):
image_size=(1024,1024)
input_image = preprocess_image(image, image_size).to(device)
with torch.no_grad():
scaled_preds = model(input_image)[-1].sigmoid()
# Resize prediction back to original size
# original_image = cv2.imread(image_path, cv2.IMREAD_COLOR)
res = torch.nn.functional.interpolate(
scaled_preds,
size=image.shape[:2],
mode='bilinear',
align_corners=True
)
binary_mask = (res>0.5)[0,0].cpu().numpy()
if binary_mask.sum() == 0:
binary_mask = np.ones_like(binary_mask)
rows = np.any(binary_mask, axis=1)
cols = np.any(binary_mask, axis=0)
if rows.sum()==1 or cols.sum()==1:
binary_mask = np.ones_like(binary_mask)
rows = np.any(binary_mask, axis=1)
cols = np.any(binary_mask, axis=0)
y_min, y_max = np.where(rows)[0][[0, -1]]
x_min, x_max = np.where(cols)[0][[0, -1]]
return [x_min, y_min, x_max, y_max]
def preprocess_inputs(batched_inputs, device):
"""
Normalize, pad and batch the input images.
"""
pixel_mean = torch.Tensor([123.675 / 255., 116.280 / 255., 103.530 / 255.]).view(-1, 1, 1).to(device)
pixel_std = torch.Tensor([58.395 / 255., 57.120 / 255., 57.375 / 255.]).view(-1, 1, 1).to(device)
output = dict()
images = batched_inputs["image"].to(device)
images = (images - pixel_mean) / pixel_std
assert images.shape[-2] == images.shape[-1] == 1024
bbox = batched_inputs["bbox"].to(device)
click = -1 * torch.ones((1,9,3),dtype=torch.float64).to(device)
output['images'] = images
output['bbox'] = bbox
output['click'] = click
return output
def resize_image_prompt(prompts):
[[x1, y1, _, x2, y2, _]] = prompts["bbox"]
x1, y1, x2, y2 = int(x1), int(y1), int(x2), int(y2)
img = prompts["image"]
img = cv2.resize(img, (1024, 1024), interpolation=cv2.INTER_LINEAR)
img = img.transpose((2, 0, 1)).astype(np.float32) / 255.0
ori_H, ori_W, _ = prompts["image"].shape
scale_x = 1024.0 / ori_W
scale_y = 1024.0 / ori_H
x1, y1, x2, y2 = int(x1 * scale_x), int(y1 * scale_y), int(x2 * scale_x), int(y2 * scale_y)
bbox = np.clip(np.array([[x1, y1, x2, y2]]) * 1.0, 0, 1024.0)
return img, bbox, (ori_H, ori_W), (1024, 1024)
def batch_inference(args, input_path, output_path):
device = torch.device(args.device)
model = load_model(args.mattepro_config_path, args.mattepro_ckpt_path, device)
matter = load_matter(args.mematte_ckpt_path, device)
birefnet = init_biref(device)
# Set up input/output paths
# Open video file
cap = cv2.VideoCapture(input_path)
# Get video properties
fps = int(cap.get(cv2.CAP_PROP_FPS))
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# Prepare output: we'll save PNG frames with alpha (transparent background)
# and also optionally write a color MP4 with black background for quick preview.
base_out, ext = os.path.splitext(output_path)
output_frames_dir = base_out + '_frames'
os.makedirs(output_frames_dir, exist_ok=True)
out_video = None
if output_path.lower().endswith('.mp4') or output_path.lower().endswith('.avi'):
# write a preview color video where background is black (no alpha)
out_video = cv2.VideoWriter(output_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (width, height), True)
# Get total frame count
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
# Process frames with progress bar
for frame_idx in tqdm(range(total_frames), desc=f"Processing {input_path}"):
ret, frame = cap.read()
if not ret:
break
bbox = get_bbox_from_birefnet(birefnet, frame, device)
prompts = {"image": frame, "bbox": [[bbox[0], bbox[1], 2, bbox[2], bbox[3], 3]], "click": frame}
image_resized, bbox_resized, ori_H_W, pad_H_W = resize_image_prompt(prompts)
input_data = {
'image': torch.from_numpy(image_resized)[None].to(device),
'bbox': torch.from_numpy(bbox_resized)[None].to(device),
}
# Generate alpha matte
with torch.no_grad():
inputs = preprocess_inputs(input_data, device)
images, bbox, click = inputs['images'], inputs['bbox'], inputs['click']
pred = model.forward((images, (click,bbox)))
pred = F.interpolate(pred, size=ori_H_W, mode='bilinear', align_corners=False)
trimap_pred = torch.clip(torch.argmax(pred, dim=1) * 128, min=0, max=255)[0].cpu().numpy().astype(np.uint8)
alpha = matting_inference(matter, frame, trimap_pred, device).squeeze()
# Ensure alpha is uint8 HxW with values 0-255
if alpha.dtype != np.uint8:
alpha = alpha.astype(np.uint8)
# Create RGBA image: convert BGR->RGB then stack alpha as 4th channel
# Use PIL to save to avoid channel-order issues some viewers have.
rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# Ensure alpha is HxW uint8
a = alpha if alpha.ndim == 2 else alpha[:, :, 0]
rgba_np = np.dstack((rgb, a))
frame_filename = os.path.join(output_frames_dir, f'frame_{frame_idx:06d}.png')
Image.fromarray(rgba_np).save(frame_filename)
# Also write a color preview video (foreground composited on pure green background)
if out_video is not None:
alpha_norm = (alpha.astype(np.float32) / 255.0)[..., None]
fg = frame.astype(np.float32) * alpha_norm
# BGR green
bg_color = np.array([0, 255, 0], dtype=np.float32)
bg = np.ones_like(frame, dtype=np.float32) * bg_color
composited = (fg + bg * (1.0 - alpha_norm)).astype(np.uint8)
out_video.write(composited)
cap.release()
if out_video is not None:
out_video.release()
# If requested, assemble the PNG frames into a MOV with alpha using ffmpeg (ProRes 4444)
if hasattr(args, 'alpha_output_path') and args.alpha_output_path:
alpha_out = args.alpha_output_path
# the frame pattern saved above
frame_pattern = os.path.join(output_frames_dir, 'frame_%06d.png')
if not shutil.which('ffmpeg'):
print('ffmpeg not found in PATH. Cannot create alpha MOV. Please install ffmpeg or set --alpha-output-path to empty.')
else:
# ProRes 4444 (alpha) using prores_ks. pix_fmt yuva444p10le keeps alpha channel.
cmd = [
'ffmpeg', '-y', '-framerate', str(fps), '-i', frame_pattern,
'-c:v', 'prores_ks', '-profile:v', '4', '-pix_fmt', 'yuva444p10le',
alpha_out
]
print('Running:', ' '.join(cmd))
try:
subprocess.run(cmd, check=True)
print(f'Created alpha MOV: {alpha_out}')
except subprocess.CalledProcessError as e:
print('ffmpeg failed with code', e.returncode)
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('--mattepro-config-path', default='configs/MattePro_SAM2.py', type=str)
parser.add_argument('--mattepro-ckpt-path', default='weights/MattePro.pth', type=str)
parser.add_argument('--mematte-ckpt-path', default='weights/MEMatte.pth', type=str)
parser.add_argument('--input-path', default='videos/example.mp4', type=str, help='a directory containing test videos')
parser.add_argument('--output-path', default='output.mp4', type=str, help='output path for the results')
parser.add_argument('--device', default='cuda:0', type=str)
parser.add_argument('--alpha-output-path', default='', type=str,
help='If set, assemble PNG frames into a MOV with alpha (ProRes 4444) using ffmpeg')
return parser.parse_args()
if __name__ == '__main__':
args = parse_args()
batch_inference(args, args.input_path, args.output_path)
#按以下方式执行
'''
python demo_video_matting_2.py \
--input-path videos/example.mp4 \
--output-path output.mp4 \
--mattepro-config-path configs/MattePro_SAM2.py \
--mattepro-ckpt-path weights/MattePro.pth \
--mematte-ckpt-path weights/MEMatte.pth \
--device cuda:0 \
--alpha-output-path output_with_alpha.mov
'''
执行结果如下:
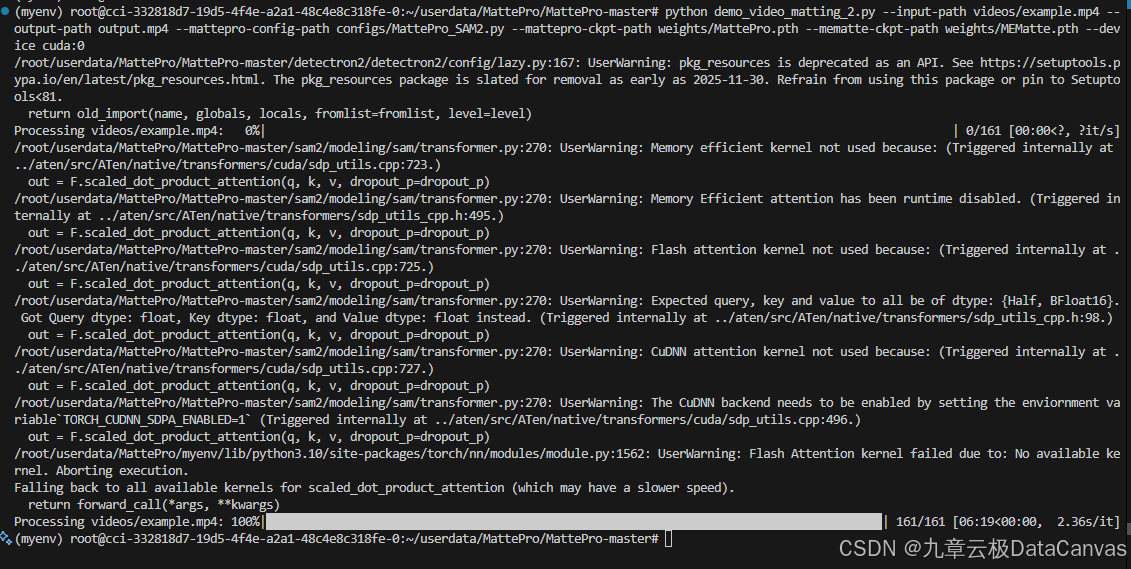
对比一下,在剪映里扣像,各种操作,会有一些颜色上的损失,MattePro扣的视频颜色没有太大修改。但我个人感觉还是没有百分之百的扣除,但应该达到一般要求了。原图是带绿幕背景视频(绿幕颜色为纯绿色#FF00FF)。视频扣像后的效果:

MattePro官方视频扣像效果示例:

如果不支持Alpha通道,我们还是存为带绿色背景的视频,把代码改一下即可:
import os
import sys
sys.path.append('./BiRefNet')
import cv2
import numpy as np
import torch
import torch.nn.functional as F
from PIL import Image
import torchvision
from tqdm import tqdm
from detectron2.config import LazyConfig, instantiate
from detectron2.checkpoint import DetectionCheckpointer
import argparse
import numpy as np
from BiRefNet.models.birefnet import BiRefNet
from torchvision import transforms
def init_biref(device):
model = BiRefNet(bb_pretrained=False)
# Load model weights
state_dict = torch.load('weights/BiRefNet-HRSOD_D-epoch_130.pth', map_location='cpu', weights_only=True)
model.load_state_dict(state_dict)
model = model.to(device)
model.eval()
return model
def matting_inference(model, rawimg, trimap, device):
"""
Perform matting inference.
"""
data = {}
data['trimap'] = torchvision.transforms.functional.to_tensor(trimap)[0:1, :, :].unsqueeze(0)
data['image'] = torchvision.transforms.functional.to_tensor(rawimg).unsqueeze(0)
for k in data.keys():
data[k].to(model.device)
patch_decoder = True
output = model(data, patch_decoder)[0]['phas'].flatten(0, 2)
# output = model(data, patch_decoder)['phas'].flatten(0, 2)
# trimap = data['trimap'].squeeze(0).squeeze(0)
# output[trimap == 0] = 0
# output[trimap == 1] = 1
output *= 255
output = output.cpu().numpy().astype(np.uint8)[:,:,None]
return output
def load_matter(ckpt_path, device):
"""
Load the matting model.
"""
cfg = LazyConfig.load('MEMatte/configs/MixData_ViTMatte_S_topk0.25_1024_distill.py')
cfg.model.teacher_backbone = None
cfg.model.backbone.max_number_token = 12000
matmodel = instantiate(cfg.model)
matmodel = matmodel.to(device)
matmodel.eval()
DetectionCheckpointer(matmodel).load(ckpt_path)
return matmodel
def load_model(config_path, ckpt_path, device):
cfg = LazyConfig.load(config_path)
model = instantiate(cfg.model)
model.lora_rank = 4
model.lora_alpha = model.lora_rank
model.init_lora()
model.to(device)
checkpoint = torch.load(ckpt_path, map_location=device)
new_state_dict = {key.replace("module.", ""): value for key, value in checkpoint['state_dict'].items()}
model.load_state_dict(new_state_dict)
model.eval()
return model
def preprocess_image(image, image_size):
"""
Preprocess the image for inference.
Args:
image_path (str): Path to the input image.
image_size (tuple): Target size (height, width).
Returns:
torch.Tensor: Preprocessed image tensor.
"""
# Load image using PIL
# image = Image.open(image_path).convert('RGB')
image = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
# Define the transform pipeline
transform_image = transforms.Compose([
transforms.Resize(image_size[::-1]), # Resize to target size
transforms.ToTensor(), # Convert to tensor
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # Normalize
])
# Apply transformations
image = transform_image(image)
return image.unsqueeze(0) # Add batch dimension
def get_bbox_from_birefnet(model,image,device):
image_size=(1024,1024)
input_image = preprocess_image(image, image_size).to(device)
with torch.no_grad():
scaled_preds = model(input_image)[-1].sigmoid()
# Resize prediction back to original size
# original_image = cv2.imread(image_path, cv2.IMREAD_COLOR)
res = torch.nn.functional.interpolate(
scaled_preds,
size=image.shape[:2],
mode='bilinear',
align_corners=True
)
binary_mask = (res>0.5)[0,0].cpu().numpy()
if binary_mask.sum() == 0:
binary_mask = np.ones_like(binary_mask)
rows = np.any(binary_mask, axis=1)
cols = np.any(binary_mask, axis=0)
if rows.sum()==1 or cols.sum()==1:
binary_mask = np.ones_like(binary_mask)
rows = np.any(binary_mask, axis=1)
cols = np.any(binary_mask, axis=0)
y_min, y_max = np.where(rows)[0][[0, -1]]
x_min, x_max = np.where(cols)[0][[0, -1]]
return [x_min, y_min, x_max, y_max]
def preprocess_inputs(batched_inputs, device):
"""
Normalize, pad and batch the input images.
"""
pixel_mean = torch.Tensor([123.675 / 255., 116.280 / 255., 103.530 / 255.]).view(-1, 1, 1).to(device)
pixel_std = torch.Tensor([58.395 / 255., 57.120 / 255., 57.375 / 255.]).view(-1, 1, 1).to(device)
output = dict()
images = batched_inputs["image"].to(device)
images = (images - pixel_mean) / pixel_std
assert images.shape[-2] == images.shape[-1] == 1024
bbox = batched_inputs["bbox"].to(device)
click = -1 * torch.ones((1,9,3),dtype=torch.float64).to(device)
output['images'] = images
output['bbox'] = bbox
output['click'] = click
return output
def resize_image_prompt(prompts):
[[x1, y1, _, x2, y2, _]] = prompts["bbox"]
x1, y1, x2, y2 = int(x1), int(y1), int(x2), int(y2)
img = prompts["image"]
img = cv2.resize(img, (1024, 1024), interpolation=cv2.INTER_LINEAR)
img = img.transpose((2, 0, 1)).astype(np.float32) / 255.0
ori_H, ori_W, _ = prompts["image"].shape
scale_x = 1024.0 / ori_W
scale_y = 1024.0 / ori_H
x1, y1, x2, y2 = int(x1 * scale_x), int(y1 * scale_y), int(x2 * scale_x), int(y2 * scale_y)
bbox = np.clip(np.array([[x1, y1, x2, y2]]) * 1.0, 0, 1024.0)
return img, bbox, (ori_H, ori_W), (1024, 1024)
def batch_inference(args, input_path, output_path):
device = torch.device(args.device)
model = load_model(args.mattepro_config_path, args.mattepro_ckpt_path, device)
matter = load_matter(args.mematte_ckpt_path, device)
birefnet = init_biref(device)
# Set up input/output paths
# Open video file
cap = cv2.VideoCapture(input_path)
# Get video properties
fps = int(cap.get(cv2.CAP_PROP_FPS))
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# Prepare output: we'll save PNG frames with alpha (transparent background)
# and also optionally write a color MP4 with black background for quick preview.
base_out, ext = os.path.splitext(output_path)
output_frames_dir = base_out + '_frames'
os.makedirs(output_frames_dir, exist_ok=True)
out_video = None
if output_path.lower().endswith('.mp4') or output_path.lower().endswith('.avi'):
# write a preview color video where background is black (no alpha)
out_video = cv2.VideoWriter(output_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (width, height), True)
# Get total frame count
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
# Process frames with progress bar
for frame_idx in tqdm(range(total_frames), desc=f"Processing {input_path}"):
ret, frame = cap.read()
if not ret:
break
bbox = get_bbox_from_birefnet(birefnet, frame, device)
prompts = {"image": frame, "bbox": [[bbox[0], bbox[1], 2, bbox[2], bbox[3], 3]], "click": frame}
image_resized, bbox_resized, ori_H_W, pad_H_W = resize_image_prompt(prompts)
input_data = {
'image': torch.from_numpy(image_resized)[None].to(device),
'bbox': torch.from_numpy(bbox_resized)[None].to(device),
}
# Generate alpha matte
with torch.no_grad():
inputs = preprocess_inputs(input_data, device)
images, bbox, click = inputs['images'], inputs['bbox'], inputs['click']
pred = model.forward((images, (click,bbox)))
pred = F.interpolate(pred, size=ori_H_W, mode='bilinear', align_corners=False)
trimap_pred = torch.clip(torch.argmax(pred, dim=1) * 128, min=0, max=255)[0].cpu().numpy().astype(np.uint8)
alpha = matting_inference(matter, frame, trimap_pred, device).squeeze()
# Ensure alpha is uint8 HxW with values 0-255
if alpha.dtype != np.uint8:
alpha = alpha.astype(np.uint8)
# Create RGBA image: convert BGR->RGB then stack alpha as 4th channel
# Use PIL to save to avoid channel-order issues some viewers have.
rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# Ensure alpha is HxW uint8
a = alpha if alpha.ndim == 2 else alpha[:, :, 0]
rgba_np = np.dstack((rgb, a))
frame_filename = os.path.join(output_frames_dir, f'frame_{frame_idx:06d}.png')
Image.fromarray(rgba_np).save(frame_filename)
# Also write a color preview video (foreground composited on pure green background)
if out_video is not None:
alpha_norm = (alpha.astype(np.float32) / 255.0)[..., None]
fg = frame.astype(np.float32) * alpha_norm
# BGR green
bg_color = np.array([0, 255, 0], dtype=np.float32)
bg = np.ones_like(frame, dtype=np.float32) * bg_color
composited = (fg + bg * (1.0 - alpha_norm)).astype(np.uint8)
out_video.write(composited)
cap.release()
if out_video is not None:
out_video.release()
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('--mattepro-config-path', default='configs/MattePro_SAM2.py', type=str)
parser.add_argument('--mattepro-ckpt-path', default='weights/MattePro.pth', type=str)
parser.add_argument('--mematte-ckpt-path', default='weights/MEMatte.pth', type=str)
parser.add_argument('--input-path', default='videos/example.mp4', type=str, help='a directory containing test videos')
parser.add_argument('--output-path', default='output.mp4', type=str, help='output path for the results')
parser.add_argument('--device', default='cuda:0', type=str)
return parser.parse_args()
if __name__ == '__main__':
args = parse_args()
batch_inference(args, args.input_path, args.output_path)
#按以下方式执行
'''
python demo_video_matting_2.py \
--input-path videos/example.mp4 \
--output-path output.mp4 \
--mattepro-config-path configs/MattePro_SAM2.py \
--mattepro-ckpt-path weights/MattePro.pth \
--mematte-ckpt-path weights/MEMatte.pth \
--device cuda:0
'''
运行完成后,打开output.mp4,应看到前景区域保留,背景为纯绿色 (绿色用于后期替换或查看)。这次我换了一个视频,把我们的数字人小九放上。

到此全文结束,为了进一步提高扣视频的效果,我觉得原始图像或视频要有绿幕,且前景颜色要尽量与绿色不要太相近,另外一点就是需要原始视频或图像尺寸足够大,效果会更好一点,因此我决定下期再整一个视频变高清的大模型测试,再重新扣一下视频,看看效果。
对了,要想自己测试一下的宝子们,赶紧去注册一下,再次给出注册地址:https://www.alayanew.com/?id=online
整个模型已经打好了镜像,需要免费获取的同学可以联系平台客服。


















 205
205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









