







大家好,我是YU。从今天起我将开启我的个人学习博客专栏,将系统性的总结现代计算机发展历史和基本原理,希望能和各位开发者和发烧友们一起交流!!
今天我们要探讨的是计算机最底层的知识,从现代计算机的设计结构思路来思考一下当年桌面端的CPU大战中,为什么奔腾4会输的如此之惨?为了彻底明白这个问题,我想我们应当从0开始回顾一下现代计算机架构是怎么样的。
1.现代计算机体系
对于某些不了解现代电子工业和计算机发展的人来讲,计算机是一个很神奇的物件,它可以完成各式各样的不同种类的任务。但计算机归根结底来讲,仍然是一个用于计算的机器,那么用于计算的机器,我们就需要计算的指令,来告诉计算机如何做,以及数据,告诉计算机算什么数。如果你能看出这一点那么恭喜你,你也能成为像冯诺·依曼一样的伟大科学家了。😀!!!
开个玩笑,那么让我们看看冯诺依曼是如何思考这个问题的。
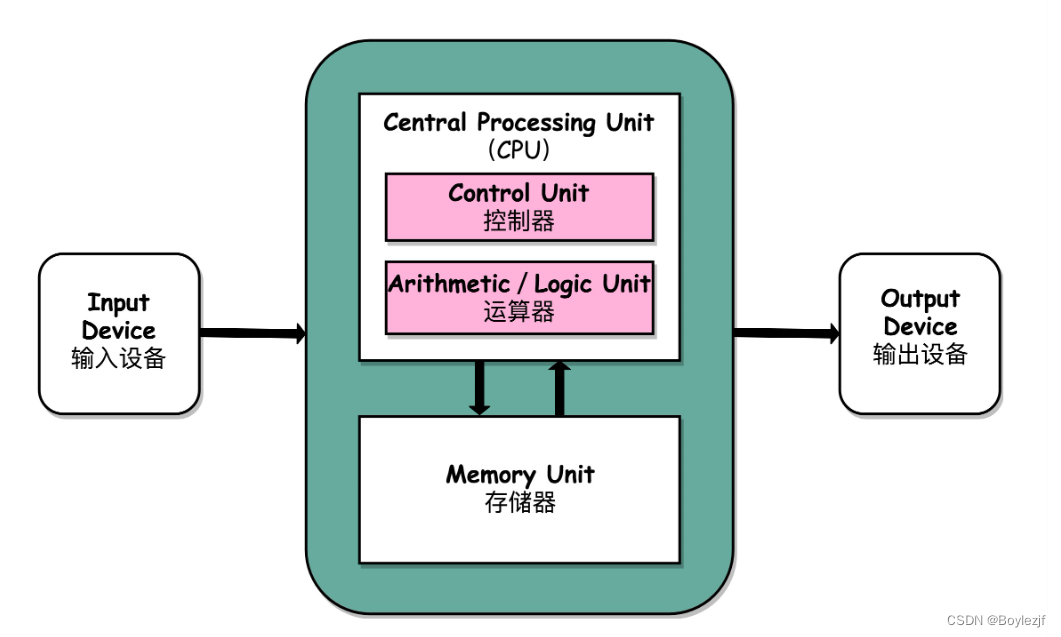
在冯诺依曼体系结构中,我们输入所计算的数据和输入的计算逻辑都储存在储存器单元中,运算器(ALU)和控制器从储存器中提取所需进行计算,再将计算结果进行写回。输出设备再从储存器中提取数据进行展示。其中控制器单元和ALU单元集成为中央处理器,当然了现代中央处理器(CPU)不仅仅包含这两个单元。
或许你好奇我们的输入是如何储存到储存器中,以及计算过程是怎么样发生的?这就牵扯到数电,模电等知识,我们先不要思考这么多。我们只认为其是底层的一个封装。
2. 指令执行能有多快?
也许你经常听到指令集这个概念,例如大名鼎鼎的x86指令集。所谓指令集,我们可以理解成计算器所提供的加减乘除这些运算。利用指令集所支持的这些运算,我们可以构建更加复杂的任务,这就是计算机的可编程性。而在计算机中,让这些指令依次执行的动力来源于哪里呢?这就要谈到我们的计算机主频这一参数。在计算机执行程序的过程中,我们有一个程序计数器,每经过一个时钟周期,计算机就将一条指令从内存中拿出来进行计算。因此,可想而知只要我们的计算机主频越来越高,那么我们计算机就会越来越快!!但事实真的是这样吗?奔腾 4 的 CPU 主频上限定格在 3.8GHz,但大家发现,奔腾 4 的主频虽然高,但是它的实际性能却配不上同样的主频。想要用在笔记本上的奔腾 4 2.4GHz 处理器,其性能只和基于奔腾 3 架构的奔腾 M 1.6GHz 处理器差不多。这是由于主频越高,其功耗也就越大!!
3. 程序如何执行?
对于当代程序来说,可能没人经历过打孔计算的年代。但许多人仍然不清楚程序是究竟如何执行的。我们以hello_world.c为例看看一个程序究竟经历了什么?
首先我们使用键盘打出hello_world.c的源代码,程序在正式执行之前会经历如下过程。
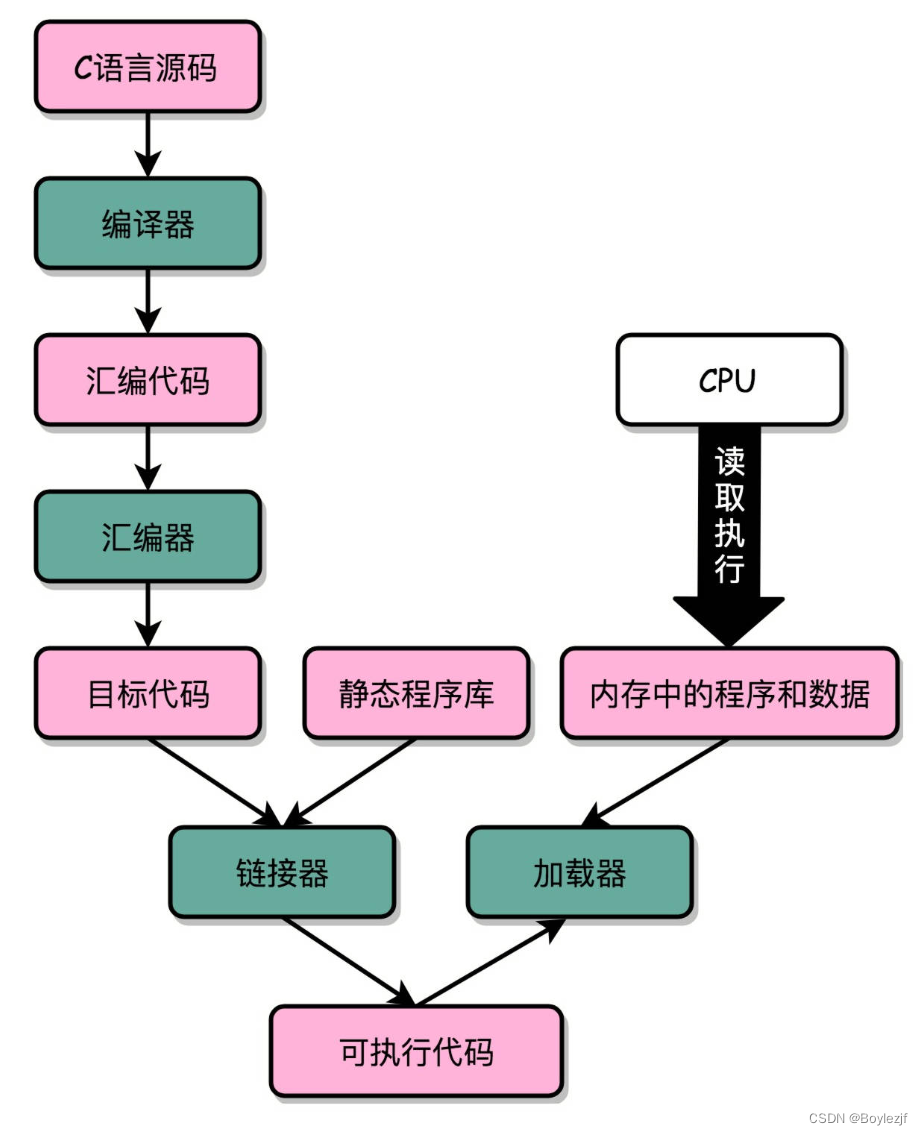
由于前人的努力造轮子,因此我们可以很轻松的完成许许多多的复杂任务,这也是计算机学科的一大思想,封装,抽象。如上图,从源码开始到可执行代码,我们需要将自然语言翻译成计算机所能理解的二进制代码,其中链条上的每一层我们都进行了封装。而单单依靠我们所写的代码程序是无法进行执行的,因此静态程序库的代码会在链接器这一层加入到我们的代码中,但这种方式会造成大量的内存浪费,而动态链接技术改变了这一现状,他的代码只在内存中有一份,程序通过跳转的形式去使用其代码,这也就要求了动态链接库是物理地址不敏感的。经过编译后的可执行代码,此时我们已经获得了计算机的指令,但我们仍然不知道需要计算什么数据,这一任务就交给了加载器来做。好的,你现在已经明白了,一个程序执行的大概过程,下面让我们更加深入一些。
4. 内存管理
让我们思考这样一个问题,再3中的可执行代码,其需要用到的内存必须是连续内存。那么当我们的电脑有许多的程序在执行。
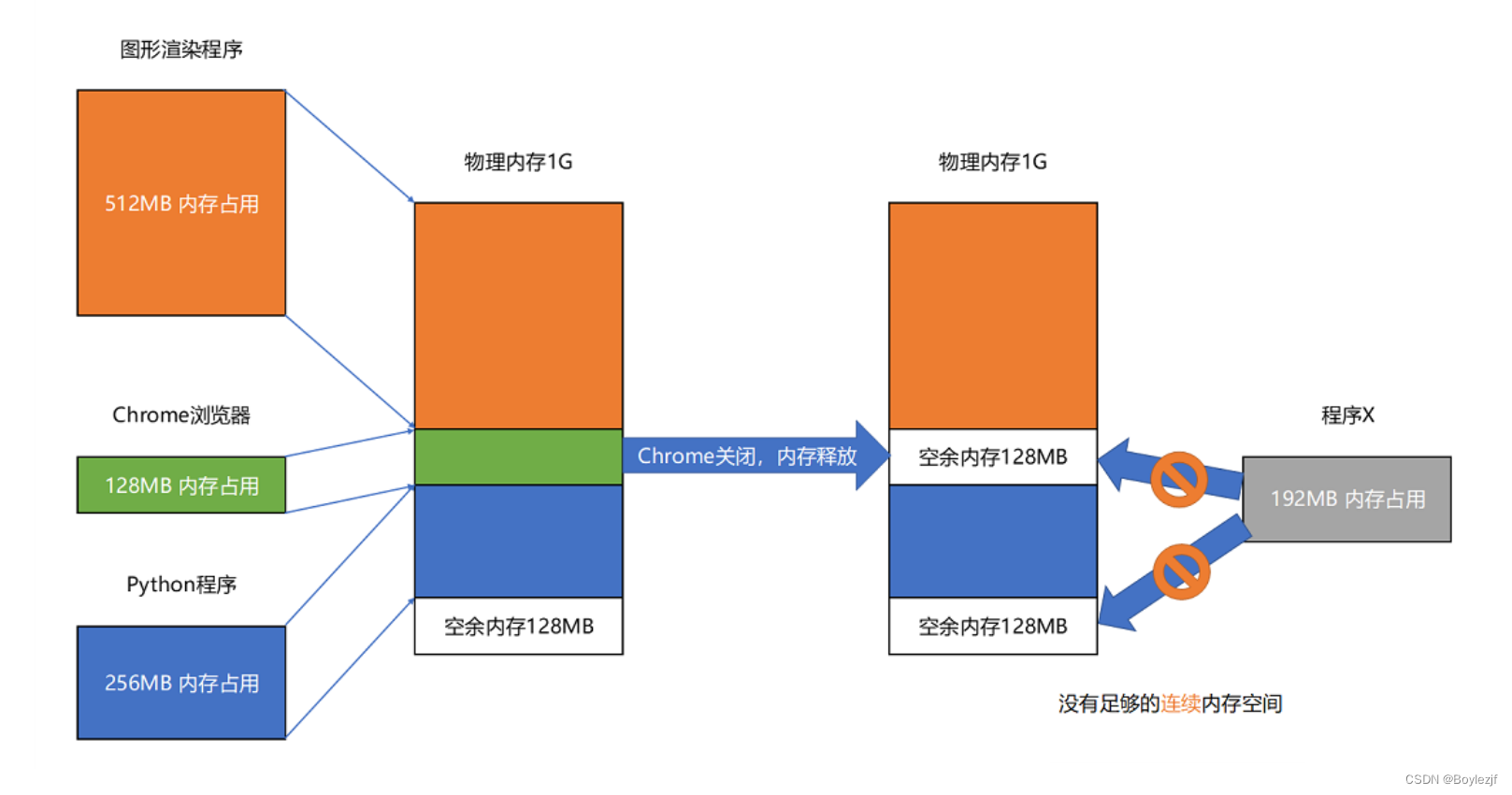
如上图所示,当某个程序结束后,就会产生许多的内存碎片,此时无法加载其他程序。聪明的你肯定想到了,我们可以将下面的程序往上移动。使得,在实际的操作中,下方的程序通常会借助于磁盘进行内存交换,以消除上方的内存碎片。但这种开销往往是难以接受的。因此为了减少这种开销,聪明的科学家们发明了内存分页技术。通过对内存进行页的分割,可以减少内存的使用(我们只将需要用到的数据加载到内存的页上,用完的页就进行释放)。
5.流水线
从更加底层来看一条指令的执行周期分为,取指,译码,计算,写回,等步骤。当然了不管是什么任务,我们也可以更加的细分。在流水线技术出现一起,一个时钟周期内,我们希望完成当前这个指令的取指,译码,计算,写回过程,然而事实是前1/5个周期取值单元在工作,而其他单元没有工作,同样的,在某一时刻cpu上的单元并不是全都在工作!!因此聪明的科学家们参考工厂流水线的思路,当指令1执行完取指之后,取指单元并不休息而是立马取下一指令。因此效率立马提高了1/5!!!但别急,我们之前说过计算机的计算单元是受到时钟周期控制的其是一令一动的,所以我们需要将主频提高!!这样才能真正的实现cpu的计算速度提升。
我们今天故事的主角奔腾4也是这么干的,其采用了超长流水线,以适应其超高的主频。但其最终还是倒在了功耗这一难题上。
我们还应当注意到,其实我们的cpu也不能完全流水起来,例如当指令2的计算依赖于指令1的计算结果,所以指令2必然会卡在指令1写回之前。因此科学家们基于此又发明了乱序执行,冒险等策略。总而言之,当今cpu的各项性能提升方案,例如前面提到的乱序执行,或者是intel的超线程技术,都是基于如何使得我们的流水线更忙的目标!
总结:
这周的博客主要是浅析了一下计算机性能的相关话题,在我看来,计算机性能提升的最终目标只有两种,一是提高计算机速度,二是加速计算机的执行吞吐率。虽然这周的博客没有系统性的讲述前者,但计算机速度其实极大程度上取决于我们的访存速度,这就是经典的木桶效应。因此,现代计算机大多采用了多级缓存的形式来加速我们的访存速度以加快单条指令的计算速度。对于提升吞吐量来说,如何进行并行是我们所关注的。在底层硬件层面,流水线技术的出现就是并行化的一种体现,其是一种指令级并行。针对于流水线的优化,始终以流水线更忙碌为目标,因此出现了乱序执行,超线程,冒险,(细分任务颗粒度,提高主频)等策略。
下一周博客,我们将会把视角移动到网络上,来看看现代网络系统究竟是如何工作的。如果感兴趣,欢迎大家关注,点赞!















 3567
3567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









