







目录
应用场景
实例
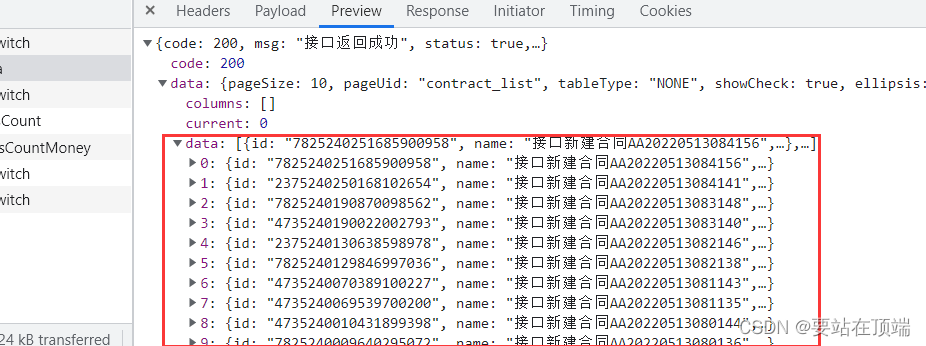
接口响应参数,字典中包含了列表,而列表中又有了字典,如下图
使用原因
比如我们,在断言的时候我们经常需要判断某一个ID是否在响应结果中,传统的方法,需要结合for循环,取出对应的值放在空列表中进行处理
# 比如需要断言 id = 666666 是否在响应结果中
id_list = []
for i in data:
id_list.append(i["id"])
assert 666666 in id_list
下面我们提供一种更加简洁并且可读性更好、可扩展性都更强的方法
from pandas import DataFrame
assert 666666 in DataFrame(data).loc[ : ,"name"].tolist()
那么在后续的接口封装中我们就可以直接返回一个需要的字段的列表,供后续的用例调用,这样就很方便了
def get_contact_list(slef):
response = request("GET", url, headers=headers, data=payload).json()
return DataFrame(response["data"]["data"]).loc[ : ,"name"].tolist()
DataFrame用法
创建DataFrame数据
以json作为数据源创建
data = [
{
"id":"7825240251685900958",
"name":"接口新建合同AA20220513084156",
"createTime":1652402517000,
"module":"contract",
"commentCount":0
},
{
"id":"2375240250168102654",
"name":"接口新建合同AA20220513084141",
"createTime":1652402502000,
"module":"contract",
"commentCount":0
},
{
"id":"7825240190870098562",
"name":"接口新建合同AA20220513083148",
"createTime":1652401909000,
"module":"contract",
"commentCount":0
}
]
DataFrame(data)

以CSV作为数据源创建
DataFrame.read_csv("path")
创建时自定义行列名称
# 定义行和列(需要同时定义所有数据)
DataFrame(data, index=["行1","行2","行3"],columns=["姓名","年龄","createTime","module","commentCount"])
# 定义所有行行(需要同时定义所有数据)
DataFrame(data, index=["行1","行2","行3"])
# 根据列名选择保留的列(注意只会保留定义了的行列数据)
DataFrame(data, columns=["姓名","年龄","createTime","module","commentCount"])
获取DataFrame的值
获取dataframe values值
DataFrame(data).values

获取dataframe index值
DataFrame(data).index

获取dataframe columns值
DataFrame(data).columns

loc、iloc 获取某行、某列数据(常用)
loc、iloc的区别
- loc:通过行、列的名称或标签来索引
- iloc:通过行、列的索引位置来寻找数据
loc方法
loc方法是通过行、列的名称或者标签来寻找我们需要的值。
# 索引第二行的值,行标签是“1”
data1 = data.loc[1] # 等价于data.loc[1] == data.loc[1,:]
# 读取第二列全部值
data2 = data.loc[ : ,"B"]
# 读取第1行,第B列对应的值
data3 = data.loc[ 1, "B"]
# 读取第1行到第3行,第B列到第D列这个区域内的值
data4 = data.loc[ 1:3, "B":"D"]
# 读取第B列中大于6的值
data5 = data.loc[ data.B > 6] #等价于 data5 = data[data.B > 6]
# 进行切片操作,选择B,C,D,E四列区域内,B列大于6的值
data1 = data.loc[ data.B >6, ["B","C","D","E"]]
iloc方法
#读取第二行的值,与loc方法一样
data1 = data.iloc[1] #等价于data1 = data.iloc[1, :]
#读取第二列的值
data1 = data.iloc[:, 1]
















 7949
7949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











