









文章目录
一、应用层
1.简单介绍
应用层是程序猿最经常打交道的层,而其他四层——传输层,网络层,数据链路层,物理层都是操作系统,驱动,硬件已经实现好的了。一般来说不需要程序猿去理会,除非你是系统工程师或者驱动开发工程师。
那么,在应用层这里,最重要的事情——设计并实现一个应用层协议。实际上,这是一个相对来说比较简单的事情,同时也是我们在工作之中经常要做的事情。
举个例子:公司在开发一个项目——点外卖的软件。这时候,要开发一个功能——获取用户的订单历史,这个一般存放在数据库里,我们的服务器去拿。那么这样的功能就会设计到前端(客户端)和后端(开发端)彼此之间的交互。
此时,前端与后端就会通过网络进行交互。在这个交互过程中,就需要约定好前端发送怎么样的数据,然后后端回应对应的数据,如下图。
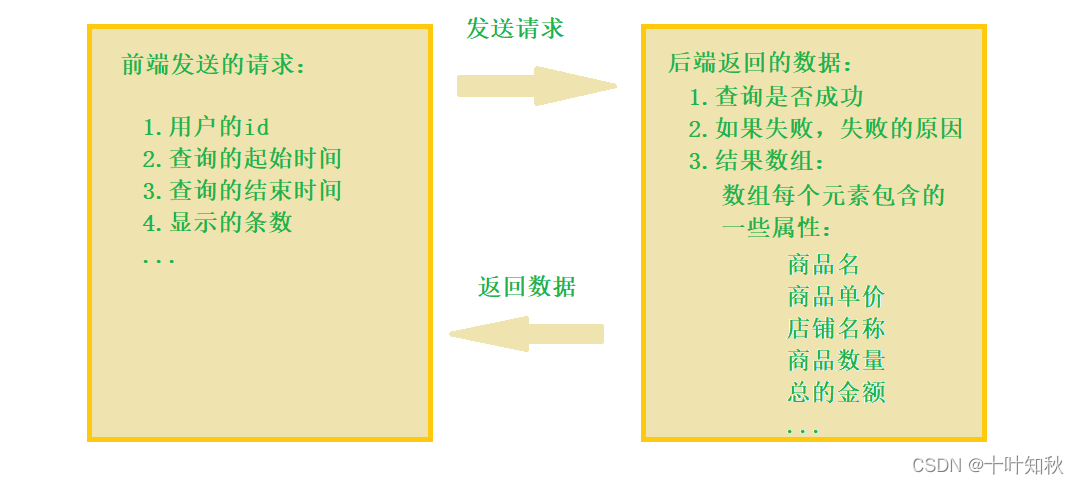
像上面这个例子,其实就是在设计一个应用层协议,上图的内容,实际上就是在规划请求和响应之间要传递的信息。但是光约定传递的信息还不够,我们还得约定一个具体的格式,不然的话返回的内容的格式就会千奇百怪。假如我们约定的格式如下图:
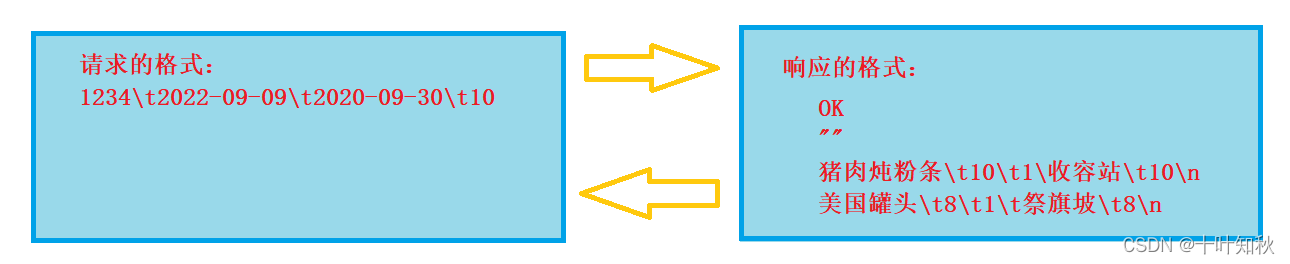 提醒一下,上图的格式只是我们提供的很多种可能格式的一种,实际上这里的格式,是可以按照你的设计要求来设计的,只要能够让客户端与服务器都按照一样的格式来交互就可以了。
提醒一下,上图的格式只是我们提供的很多种可能格式的一种,实际上这里的格式,是可以按照你的设计要求来设计的,只要能够让客户端与服务器都按照一样的格式来交互就可以了。
因此,我们设计一个应用层协议,主要就包含两个工作:
- 明确传输的信息
- 明确数据的组织格式
正是由于这里的应用层协议,可以随心所欲的设计,这就导致了两个极端的结果,一是大佬设计的协议非常好,二是新手设计的协议非常糟糕。比如说我们上面设计的应用层协议,就是一个不太好的设计,它的输出传输效率不高,导致运行效率低;此外可读性也不好,开发效率低。
因此,出于这样的考量,我们就可以借用一些大佬们设计的协议的模板,然后直接往上套,就可以让我们设计出不那么糟糕的协议了。
那么,当下比较流行的协议模板,也就是组织数据的格式,有下面这些:
- xml(Simple Object Access Protocol )简单对象访问协议.
- json(JavaScript Object Notation)JavaScript 对象表示法
- protobuffer(Google Protocol Buffer)Google 公司内部的混合语言数据标准。
2.xml(Simple Object Access Protocol )
xml 是一种比较老牌的数据格式了,现在虽然也在用,但是用得越来越少了。xml的格式很有特色,是用标签构成的。
<标签名> 内容 <标签名>
比如说我们上面那个外卖的例子的应用层协议就可写成以下:
<request>
<userId>1234</userId>
<startTime>2022-09-09</startTime>
<finishTime>2022-09-30</finishTime>
<count>10</count>
</request>
这实际上也是采用键值对的方式,标签名是key,标签值(内容)是value。通过这些标签,可以看到很好的表现出了这个数据的可读性,哪个部分的意思是什么,都一目了然。
虽然xml的可读性是高,但是同时也存在一定的缺点。就是引入了太多的辅助信息,比如说很多标签名。对于xml来说,为了表示这些辅助信息,就会导致传输相同数目请求的时候,占用的带宽是更高的,如果一个网络的带宽固定,那么相同时间能传输的请求个数就更少了。而对于我们的服务器程序来说,最贵的硬件资源就是网络带宽了。
因此,xml在现在已经很少作为应用层协议的设计模板了,它现在主要用来作为一些配置文件在用。
2.json(JavaScript Object Notation)
json是当下最流行的一种设计应用层协议的数据格式。它的结构如下:
{
键:值,
键:值,
…
}
通过{ }构成了键值对的结构,一个{ }中有很多个键值对,键值对之间用逗号隔开,键和值之间用冒号隔开,要求键必须是字符串类型的,值则需要很多种,比如数字,字符串,布尔,数组,另一个json等等。
上述的外卖应用层协议设计用json可以表示为:
{
userId:1234,
startTime:‘2022-09-09’,
finishTime:‘2020-09-30’,
count:10
}
json中表示字符串,单引号或者双引号都可以,没什么区别,类似于SQL。最后一个键值对,后面可以有逗号也可以没有,实际上标准是要求没有的,但是一般json解析器都不会处理这个细节。json要求key一定是字符串,因此key这里的引号可以省略,除非key中包含一些特殊符号,比如像空格,或者“-”之类的则必须要加上引号。
相比于xml,json同样能保证可读性,同时又没有xml那么繁琐,占用的带宽要少一些。
虽然json的传输效率比xml要高,但是仍然要传递一些冗余信息,就是key的名字,这一点在表示数组的时候,尤为明显。例如使用json响应格式:
{
ok:true,
reason:“”,
data:[
{
name:‘猪肉炖粉条’,
price:10,
count:1,
totalPrice:10
},
{
name:'美国罐头‘,
price:8,
count:1,
totalPrice:8
}
]
}
可以看到,当我们用json表示一个更复杂的数据的时候,比如数组此时这里的很多key就会重复N次,也就占用了更多额外的宽带。因此,这里就可以用到protobuffer(Google Protocol Buffer)了。
4.protobuffer(Google Protocol Buffer)
protobuffer是一种二进制格式的数据,在protobuffer的数据中,不再包含上面的key的名字,而是通过顺序以及一些特殊符号,来区分每个字符的含义.同时再通过一个IDL文件,来描述这个数据格式的每个部分是什么意思,IDL只是起到一个辅助开发的效果,并不会真正的进行传输,传输的只是二进制的纯粹的数据。比如上述的例子用protobuffer来表示:
1\3\3 猪头炖粉条\210\21\210\3 美国罐头\28\2\1\28
通过二进制的数据重新对这些内容进行编排,甚至可能还会进行一些数据压缩,因此这样传输的效率会更高一些,但是同时也会让这个数据难以观察,调试起来就不是很方便了。
所以可以看到,设计应用层协议是一件非常普遍的事情,也是一件并不复杂的事情。设计应用层协议,要做的工作
- 明确传输的信息(根据需求)
- 明确传输的格式(参考现有模板, json, xml, protobuffer)
但是除此之外,业界也有一些现成的,已经被设计好,已经被广泛使用了的应用层协议,但也不是所有的时候,都需要从零设计,很多时候,可以直接基于现成的协议,稍加修改,稍加扩充,进行这种二次开发,类似B站的鬼畜。
实际上,最有名的应用层协议,我们还没讲,就是HTTP协议,这个我们在后面用一篇文章单独讲。
二、传输层
我们前面虽然讲了传输层是操作系统内核实现了,不需要程序猿直接与其打交道,但是了解并熟悉传输层对程序猿来说还是很有必要的。比如,我们进行网络编程的时候会用到socket,一旦我们调用了socket,那么代码就会进入到传输层的范畴。
在这个时候,如果我们的代码能顺利运行的话,那么还好。可是如果一旦出现bug,需要我们解决bug的时候,我们一些传输层的知识了。
此外,传输层的协议,也是面试中的常考内容,比如说tcp协议之类的。
在传输层里面的协议有很多,其中最常见的就是TCP和UDP协议。
1.UDP协议
1.1.UDP协议端格式
我们在学习一个协议的时候,很多时候都是在研究报文格式。下面是UDP协议端格式。
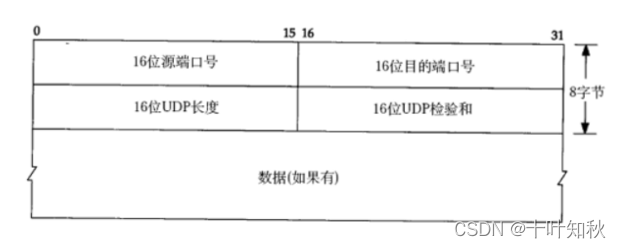
很多计算机网络的书上都会有这个画法,实际上这是不怎么正确,这些书之所以这样画,主要还是为了印刷的时候排版方便。我们下面来重新画一个相对来说比较正确的。

在这里,我们代码中写的端口号,就会被打包到这样的UDP数据报中,在报头中体现。而所谓把应用层数据报分装成UDP数据报,本质上就是在应用层数据报的基础上,添加了8个字节的报头。
以UDP客户端为例
 那我们能不能把UDP这里的端口改成4个字节之类的呢?
那我们能不能把UDP这里的端口改成4个字节之类的呢?
答案是改不了,一方面这个东西是操作内核实现,你改不了里面的东西。另一方面就算你把你系统操作内核里面的代码改了,但是跟你通信的其他主机的UDP你还是改不了。
上面的报文长度是2个字节,范围是0-65535,或者0-64k。那么64k是大还是小呢?够不够用?
实际上,64k的大小在当下互联网时代的程序中已经是捉襟见肘了。这也是UDP使用中的一个非常致命的缺陷——无法表示一个比较大的数据报。
那么如果我们确实要传输一个大的数据,那该咋办?
解决方案有以下:
- 可以在应用层中针对数据报,进行分包,拆成多个部分,然后再通过多个UDP数据报分别发送,这个时候接收方再把收到的几个包重新拼接成完整的数据。这个方法是下策,因为太麻烦了,拆包组包的代码,写起来非常复杂,要考虑到很多情况,比如说包丢了怎么办?包的顺序错了怎么办?
- 第二个方法就是改成TCP,因为TCP没有这样的长度限制,这是一个上策。
上面的校验和时候是什么呢?
校验和是用来验证网络传输的这个数据是否正确的。我们知道,网络上传递数据的本质是光信号和电信号。如果有一些外界干扰,例如磁场之类的,就可能会导致一些传递的信息发生改变。因此我们需要校验和来帮助我们发现数据中的错误。
校验过程:
首先发送方要计算checksum
- 将段的内容看作16bits的整数
- 校验和计算:计算所有整数的和,进位加到和的后面,将得到的值按位取反,得到校验和
- 发送方把checksum放入header的校验和字段里面
接着,当接收方收到后,验证的思路是
- 计算所收到的段的校验和
- 把它和校验和字段进行对比
- 不相等即发现了错误,相等并不代表一定没有错误
相等只代表我们没有检测出错误,但其实可能有错误,比如有2个位发生翻转的情况就检测不出来。
1.2.UDP特点
UDP传输的过程类似于寄信。特点如下:
- 无连接
- 不可靠
- 面向数据报
- 缓冲区
- 大小受限
(1)无连接
UDP只需要知道对端的IP和端口号就直接进行传输,不需要建立连接。
(2)不可靠
没有任何安全机制,发送端发送数据报以后,如果因为网络故障该段无法发到对方,UDP协议层也不会给应用层返回任何错误信息
(3)面向数据报
应用层交给UDP多长的报文,UDP原样发送,既不会拆分,也不会合并;
用UDP传输100个字节的数据:如果发送端一次发送100个字节,那么接收端也必须一次接收100个字节;而不能循环接收10次,每次接收10个字节。
(4)只有接收缓冲区,没有发送缓冲区
UDP只有接收缓冲区,没有发送缓冲区:
UDP没有真正意义上的 发送缓冲区。发送的数据会直接交给内核,由内核将数据传给网络层协议进行后续的传输动作;
UDP具有接收缓冲区,但是这个接收缓冲区不能保证收到的UDP报的顺序和发送UDP报的顺序一致;如果缓冲区满了,再到达的UDP数据就会被丢弃;
UDP的socket既能读,也能写,这个概念叫做 全双工。
(5)大小受限
UDP协议首部中有一个16位的最大长度。也就是说一个UDP能传输的数据最大长度是64K(包含UDP首
部)
基于UDP的应用层协议
- NFS:网络文件系统
- TFTP:简单文件传输协议
- DHCP:动态主机配置协议
- BOOTP:启动协议(用于无盘设备启动)
- DNS:域名解析协议
经典面试题:
- UDP本身是无连接,不可靠,面向数据报的协议,如果要基于传输层UDP协议,来实现一个可靠传输,应该如何设计?
- UDP大小是受限的,如果要基于传输层UDP协议,传输超过64K的数据,应该如何设计?
以上两个问题答案类似,都可以参考TCP的可靠性机制在应用层实现类似的逻辑:
- 引入序列号,保证数据顺序;
- 引入确认应答,确保对端收到了数据;
- 引入超时重传,如果隔一段时间没有应答,就重发数据
三、最后的话
一开始这篇文章写得挺长的,是非常长,搞了几天,然后后面自己尝试阅读的时候,发现这也太久了。花费时间过多,实际上很多时候,我们可能没这么久的注意力来阅读一篇文章,于是就将其拆分开了。一方面也是方便了自己阅读,另一方面,可能很多网上查资料的小伙伴要的不是你写的这一堆东西,而是某个特定的点,比如说UDP协议是啥,TCP的三次握手和四次挥手是怎么回事之类的。
因此,还是觉得文章长度不宜太长,但也不能太短,保持在10-15分钟的阅读量即可。















 553
553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











