







一、requests模块
1 requests模块介绍
①官方文档
https://docs.python-requests.org/zh_CN/latest/index.html
②requests模块作用
模拟浏览器发送http请求,获取响应数据
requests是第三方类库,需要你在python(虚拟)环境中额外安装
pip/pip3 install requests
③requests入门
# 导入requests模块
import requests
# 目标url
url = "https://www.baidu.com"
# 使用get请求请求数据
response = requests.get(url)
# 输出html文本
print(response.text)
2 response响应对象
①解决乱码问题
观察上边代码运行结果发现,有好多乱码;这是因为编解码使用的字符集不同早造成的;我们尝试使用下边的办法来解决中文乱码问题

代码实现
# 导入requests模块
import requests
# 目标url
url = "https://www.baidu.com"
# 使用get请求请求数据
response = requests.get(url)
# # 输出html文本
# print(response.text)
# 调用decode函数进行解码
print(response.content.decode())
说明:
- response.text****是requests模块按照chardet模块推测出的编码字符集进行解码的结果
- 网络传输的字符串都是bytes类型的,所以response.text = response.content.decode(‘推测出的编码字符集’)
- 我们可以在网页源码中搜索 charset ,尝试参考该编码字符集,注意存在不准确的情况
②text和content说明
response.text
- 类型:str
- 编码类型:request模块会通过request请求头对响应的编码进行判断,然后使用对应编码返回的结果
response.content
- 类型:bytes
- 解码类型:需要手动指定
③解决中文乱码
通过response.content的decode函数来设置解码的编码集,默认是utf-8
设置其他的编码集 :response.content.decode("gbk")
常见的编码字符集:
- utf-8
- gbk
- gb2312
- ascii (读音:阿斯克码)
- iso-8859-1
④response常用属性和函数
- response.url 响应的url;有时候响应的url和请求的url并不一致
- response.status_code 响应状态码
- response.request.headers 响应对应的请求头
- response.headers 响应头
- response.request._cookies 响应对应请求的cookie;返回cookieJar类型
- response.cookies 响应的cookie(经过了set-cookie动作;返回cookieJar类型
- response.json() 自动将json字符串类型的响应内容转换为python对象**(dict or list)**
代码实现
# 导入requests模块
import requests
# 目标url
url = "https://www.baidu.com"
# 使用get请求请求数据
response = requests.get(url)
# # 输出html文本
# print(response.text)
# 调用decode函数进行解码
# print(response.content.decode())
print(response.url) # 相应的url
print(response.status_code) # 响应的状态码
print(response.request.headers) # 响应的请求头
print(response.headers) # 响应头
print(response.request._cookies) # 响应对应请求的cookie
print(response.cookies) # 响应的cookie
3 requests模块发送请求
①发送带header的请求
requests.get(url, headers=headers)
- headers参数接收字典形式的请求头
- 请求头字段名作为key,字段对应的值作为value
代码实现
# 导入requests模块
import requests
# 目标url
url = "https://www.baidu.com/"
# 设置请求头
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36"}
# 带上请求头发送请求
response = requests.get(url, headers=headers)
print(response.content)
# 输出请求头
print(response.request.headers)
②发送带参数的请求
url的?后面连接的就是参数,k-v形式
1.在url中携带参数
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36"}
# 目标url
url = "https://www.baidu.com/s?wd=广东"
# 调用get函数
resp = requests.get(url, headers=headers)
print(resp.url)
2.通过params携带参数字典
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36"}
# 目标url
url = "https://www.baidu.com/s?"
params = {"wd": "广东"}
# 调用get函数
resp = requests.get(url, headers=headers, params=params)
print(resp.url)
③ headers参数中携带cookie
网站经常利用请求头中的Cookie字段来做用户访问状态的保持,那么我们可以在headers参数中添加Cookie,模拟普通用户的请求。我们以github登陆为例:
1.github登录抓包分析
- 打开浏览器,右键-检查,点击Net work,勾选Preserve log
- 访问github登陆的url地址 https://github.com/login
- 输入账号密码点击登陆后,访问一个需要登陆后才能获取正确内容的url,比如点击右上角的Yourprofile访问 https://github.com/USER_NAME
- 确定url之后,再确定发送该请求所需要的请求头信息中的User-Agent和Cookie

2.代码实现
- 从浏览器中复制User-Agent和Cookie
- 浏览器中的请求头字段和值与headers参数中必须一致
- headers请求参数字典中的Cookie键对应的值是字符串
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36",
"cookie": "浏览器中复制来的cookie"}
# 目标url
url = "https://github.com/mazhi-oss"
# 调用get函数
resp = requests.get(url, headers=headers, params=params)
print(resp.text)
3.执行结果
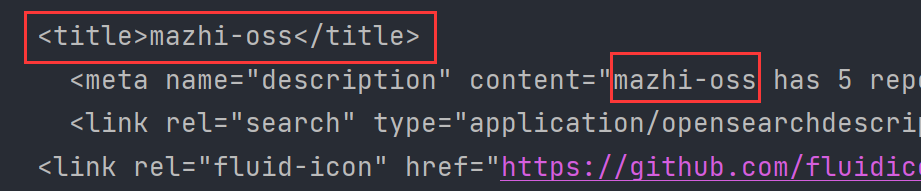
④ cookie参数的使用
-
cookies参数的形式:字典
cookies = {"cookie的name":"cookie的value"}该字典对应请求头中Cookie字符串,以分号、空格分割每一对字典键值对
等号左边的是一个cookie的name,对应cookies字典的key
等号右边对应cookies字典的value
-
cookies参数的使用方法
response = requests.get(url, cookies)
-
将cookie字符串转换为cookies参数所需的字典:
cookies_dict = {cookie.split(’=’)[0]:cookie.split(’=’)[-1] for cookie in cookies_str.split(’; ')}
-
注意:cookie****一般是有过期时间的,一旦过期需要重新获取
代码实现
import requests
url = "https://github.com/mazhi-oss"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36"}
cookies_str = "网页复制的cookie"
cookies_dict = {cookie.split('=')[0]:cookie.split('=')[-1] for cookie in cookies_str.split('; ')}
resp = requests.get(url, headers=headers, cookies=cookies_dict)
print(resp.text)
⑤ cookieJar转为cookie字典
使用requests获取的resposne对象,具有cookies属性。该属性值是一个cookieJar类型,包含了对方服务器设置在本地的cookie。我们如何将其转换为cookies字典呢?
-
转换方法
cookies_ dict = requests.utils.dict _from_ cookiejar(response . cookies) -
其中response.cookies返回的就是cookieJar类型的对象
-
requests.utils.dict from_ cookiejar 函数返回cookies字典
⑥ 超时参数timeout的使用
设置超时时间,超过指定的时间就报超时错误
-
超时参数timeout的使用方法
response = requests.get(url, timeout=3)
-
timeout=3表示:发送请求后,3秒钟内返回响应,否则就抛出异常
代码实现
import requests
url = 'https://twitter.com'
response = requests.get(url, timeout=3) # 设置超时时间,超过3秒就报错
⑦ 了解代理和proxy代理参数
1.理解使用代理的过程
- 代理ip是一个ip,指向的是一个代理服务器
- 代理服务器能够帮我们向目标服务器转发请求(工具人)
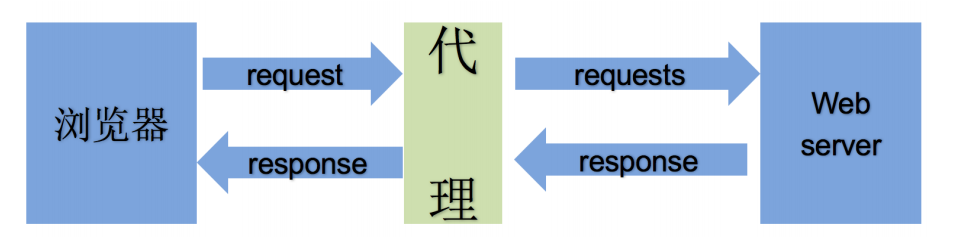
2.正向代理和反向代理的区别
- 从发送请求的一方的角度,来区分正向或反向代理
- 为浏览器或客户端(发送请求的一方)转发请求的,叫做正向代理
- 浏览器知道最终处理请求的服务器的真实ip地址,例如VPN
- 不为浏览器或客户端(发送请求的一方)转发请求、而是为最终处理请求的服务器转发请求的,叫做反向代理
- 浏览器不知道服务器的真实地址,例如nginx
3.代理ip(代理服务器)的分类
-
根据代理ip的匿名程度,代理IP可以分为下面三类:
-
透明代理(Transparent Proxy):透明代理虽然可以直接“隐藏”你的IP地址,但是还是可以查到你是谁。目标服务器接收到的请求头如下:
REMOTE_ADDR = Proxy IP HTTP_VIA = Proxy IP HTTP_X_FORWARDED_FOR = Your IP -
匿名代理(Anonymous Proxy):使用匿名代理,别人只能知道你用了代理,无法知道你是谁。目标服务器接收到的请求头如下:
REMOTE_ADDR = proxy IP HTTP_VIA = proxy IP HTTP_X_FORWARDED_FOR = proxy IP -
高匿代理(Elite proxy或High Anonymity Proxy):高匿代理让别人根本无法发现你是在用代理,所以是最好的选择。毫无疑问使用高匿代理效果最好。目标服务器接收到的请求头如下:
REMOTE_ADDR = Proxy IP HTTP_VIA = not determined HTTP_X_FORWARDED_FOR = not determined
-
-
根据网站所使用的协议不同,需要使用相应协议的代理服务。从代理服务请求使用的协议可以分为:
- http代理:目标url为http协议
- https代理:目标url为https协议
- socks隧道代理(例如socks5代理)等:
- socks 代理只是简单地传递数据包,不关心是何种应用协议(FTP、HTTP和HTTPS等)。
- socks 代理比http、https代理耗时少。
- socks 代理可以转发http和https的请求
4.proxies代理参数的使用
为了让服务器以为不是同一个客户端在请求;为了防止频繁向一个域名发送请求被封ip,所以我们需要使用代理ip;那么我们接下来要学习requests模块是如何使用代理ip的
-
用法:
response = requests.get(url, proxies=proxies) -
proxies的形式:字典
-
例如:
proxies = { "http": "http://12.34.56.79:9527", "https": "https://12.34.56.79:9527", }注意:如果proxies字典中包含有多个键值对,发送请求时将按照url地址的协议来选择使用相应的代理ip
⑧ 使用verify参数忽略CA证书
在使用浏览器上网的时候,有时能够看到下面的提示(2018年10月之前的12306网站):
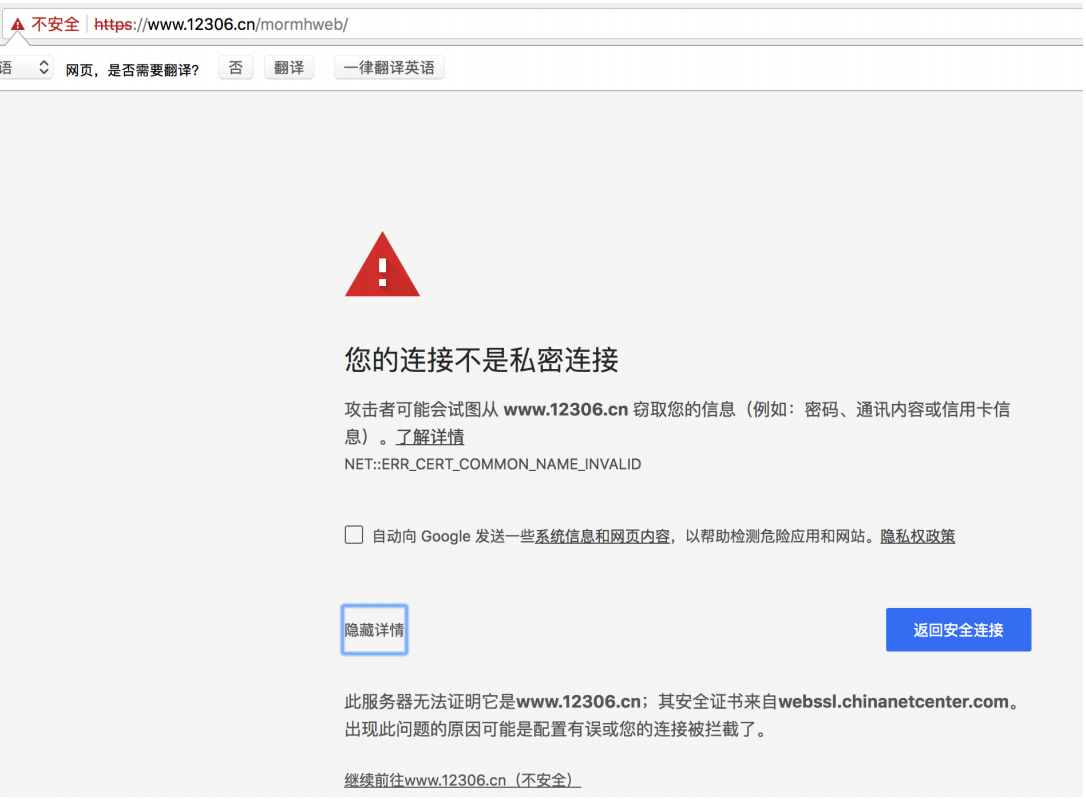
原因:该网站的CA证书没有经过【受信任的根证书颁发机构】的认证
CA证书方面的可以看这个博客:https://blog.csdn.net/yangyuge1987/article/details/79209473/
①向不安全的链接发起请求
import requests
url = "https://sam.huat.edu.cn:8443/selfservice/"
response = requests.get(url)
执行结果

这是因为CA证书的原因
②解决方案
为了在代码中能够正常的请求,我们使用 verify=False 参数,此时requests模块发送请求将不做CA证书的验证:verify参数能够忽略CA证书的认证
import requests
url = "https://sam.huat.edu.cn:8443/selfservice/"
response = requests.get(url,verify=False)
4 requests模块发送post请求
金山翻译:https://www.iciba.com/fy
import json
import requests
headers = {"User-Agent"
: "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36"}
dates = {"from": "zh",
"to": "en",
"q": "靓仔是你,我是靓仔"}
url = "https://ifanyi.iciba.com/index.php?c=trans&m=fy&client=6&auth_user=key_ciba&sign=831446ec181de140"
response = requests.post(url, headers=headers, data=dates);
data = response.text
# 将接收到的数据转换成字典数据
try:
jsonData = json.loads(data)
print(jsonData['content']['out'])
except:
print("程序异常")
说明:
- data参数就是请求体中的参数,以字典形式存储
- json.loads函数是将浏览器返回的json数据转换成字典数据
问题:
发现当内容发生变化的时候,sign参数值也会发生变化,sign是请求之前就已经存在的参数值,那么应该就是由前端js进行改变,所以我们要找到对应的规则
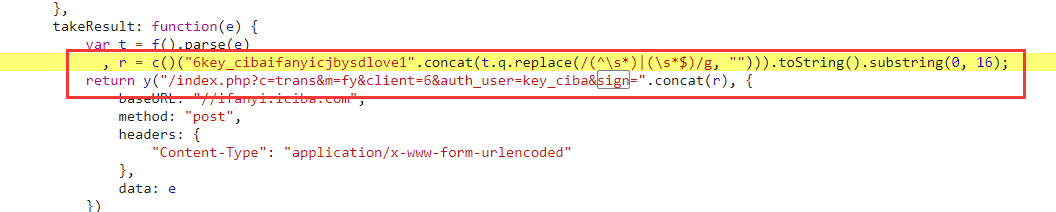
加密规则:
(盐+内容),然后进行md5加密,然后截取16位
import json
import requests
import hashlib
def fanyi(word):
headers = {"User-Agent"
: "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36"}
dates = {"from": "zh",
"to": "en",
"q": word}
sign = hashlib.md5(("6key_cibaifanyicjbysdlove1" + word).encode("utf-8")).hexdigest()[:16]
print(sign)
url = f"https://ifanyi.iciba.com/index.php?c=trans&m=fy&client=6&auth_user=key_ciba&sign={sign}"
response = requests.post(url, headers=headers, data=dates);
data = response.text
# 将接收到的数据转换成字典数据
try:
jsonData = json.loads(data)
print(jsonData['content']['out'])
except:
print("程序异常")
if __name__ == '__main__':
while True:
fanyi(input("请输入你要翻译的内容\n"))
使用session访问才是携带登录信息的,不然就没有登录信息,要注意
二、jsonPath模块-数据提取
1 jsonpath模块的使用场景
如果有一个多层嵌套的复杂字典,想要根据key和下标来批量提取value,这是比较困难的。
jsonpath模块就能解决这个痛点,接下来我们就来学习jsonpath模块
jsonpath可以按照key对python字典进行批量数据提取
2 jsonpath模块的使用方法
①安装
pip install jsonpath
② jsonpath模块提取数据的方法
from jsonpath import
jsonpath ret = jsonpath(a, 'jsonpath语法规则字符串')
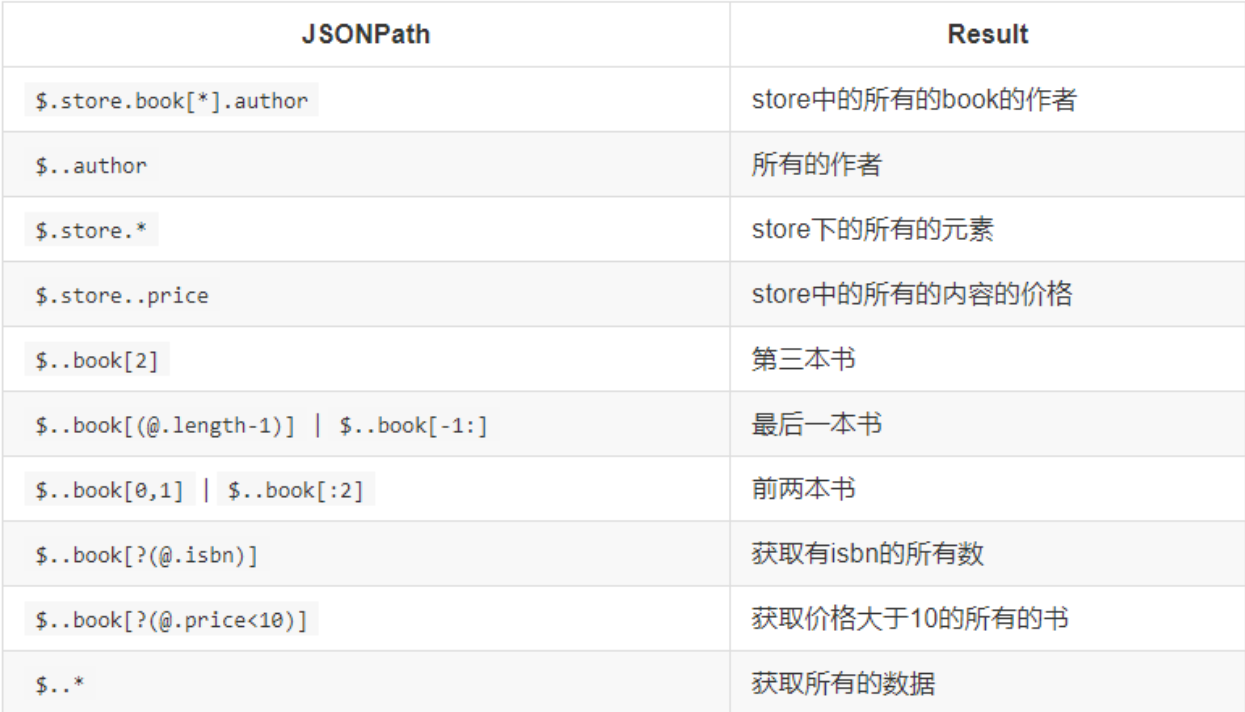
③jsonpath语法规则

④jsonpath示例
book_dict = {
"store": {
"book": [{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
from jsonpath import jsonpath
print(jsonpath(book_dict, '$..author')) # 如果取不到将返回False# 返回列表, 如果取不到将返回False
纠正上面图中的错误
# 获取价格大于10的所有书
print(jsonpath(book_dict, "$..book[?(@.price>10)]"))
3 jsonPath练习
我们以拉勾网城市JSON文件 http://www.lagou.com/lbs/getAllCitySearchLabels.json 为例,获取所有城市的名字的列表,并写入文件。
代码实现
import requests
import json
import jsonpath
url = "https://www.lagou.com/lbs/getAllCitySearchLabels.json"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"
}
res = requests.get(url, headers=headers)
res.encoding = "utf-8"
# 将数据转换成json
data = json.loads(res.text)
print(jsonpath.jsonpath(data, "$..name"))
四、selenium
1 简介
它是一个模拟浏览器的类库,通过这个我们可以模仿浏览器的行为,以此来控制我们网页的跳转和操作
它是一个第三方类库,所以需要进行安装
pip install selenium
①chrome浏览器的运行效果
代码实现
from selenium import webdriver
# 创建驱动
driver = webdriver.Chrome(executable_path='E:\Java\python爬虫\chromedriver.exe')
driver.get("https://www.baidu.com/")
# 获取到网页的标题
print(driver.title)
# 退出驱动
driver.quit()
执行结果 --> 自动打开谷歌浏览器进行网页的访问
②phantomjs无界面浏览器的运行效果
PhantomJS 是一个基于Webkit的“无界面”(headless)浏览器,它会把网站加载到内存并执行页面上的 JavaScript。下载地址:http://phantomjs.org/download.html
注意:最新版的selenium不再支持PhantomJS
③selenium的作用和工作原理
利用浏览器原生的API,封装成一套更加面向对象的Selenium WebDriver API,直接操作浏览器页面里的元素,甚至操作浏览器本身(截屏,窗口大小,启动,关闭,安装插件,配置证书之类的)
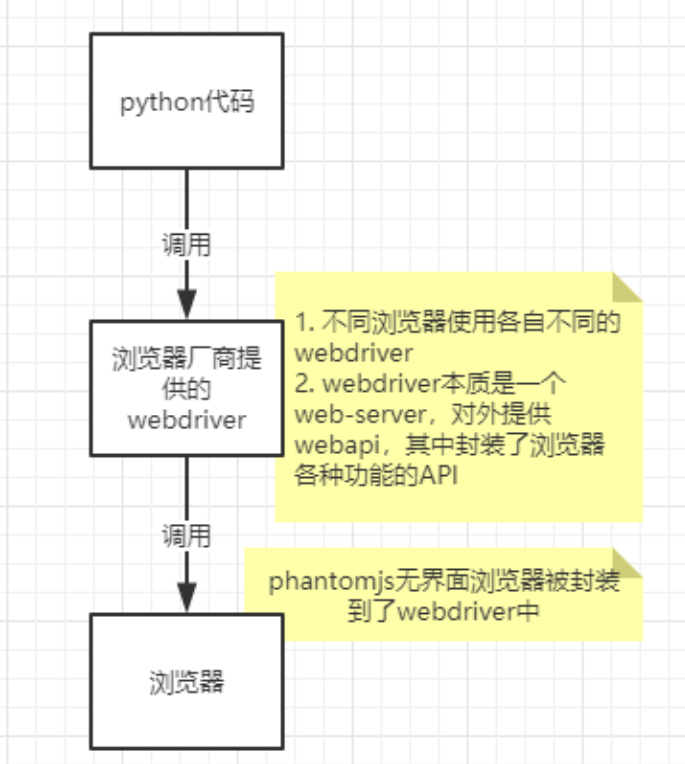
webdriver本质是一个web-server,对外提供webapi,其中封装了浏览器的各种功能不同的浏览器使用各自不同的webdriver
④ selenium驱动的安装
-
以谷歌浏览器为例,不同的版本有对应的驱动
-
访问https://npm.taobao.org/mirrors/chromedriver,点击进入不同版本的chromedriver下载页面
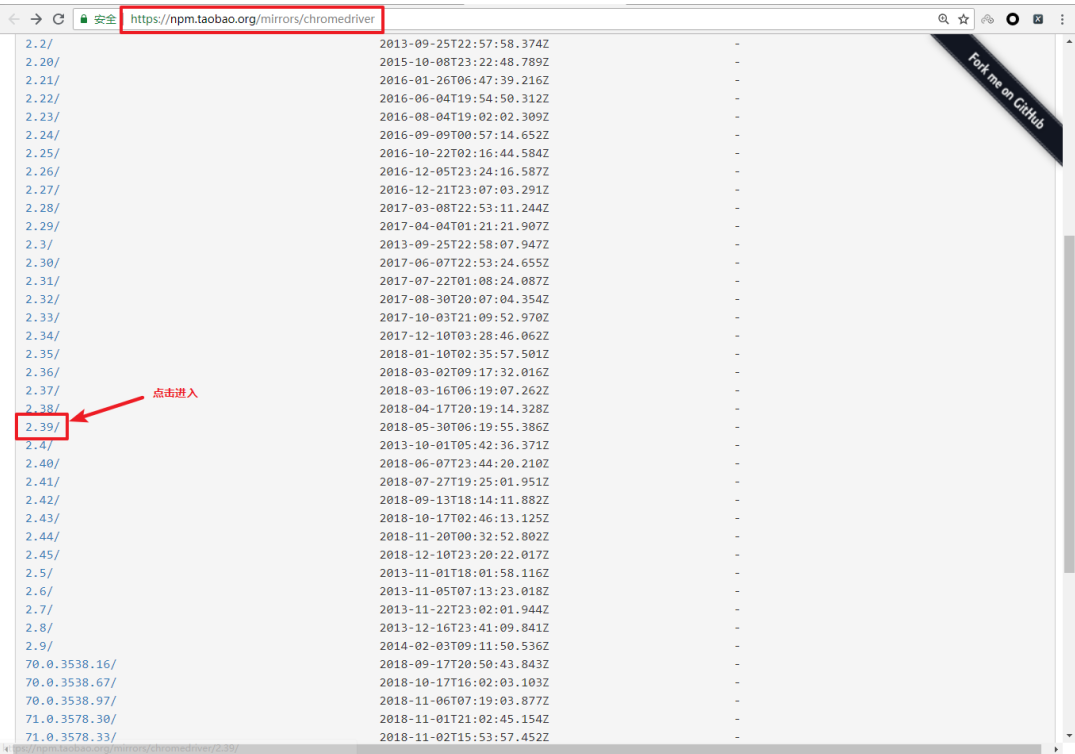
-
点击notes.txt进入版本说明页面
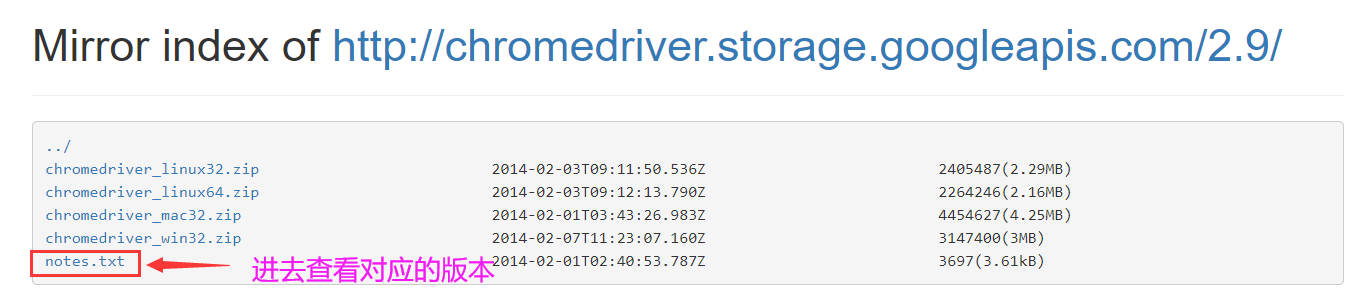
-
查看chrome和chromedriver匹配的版本

-
根据操作系统下载正确版本的chromedriver

-
解压压缩包后获取python代码可以调用的谷歌浏览器的webdriver可执行文件
- windows为 chromedriver.exe
- linux和macos为 chromedriver
2 selenium的简单使用
模拟百度搜索 – 代码实现
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome(executable_path='E:\Java\chromedriver.exe')
driver.get("https://www.baidu.com/")
# 在百度搜索中搜索python
driver.find_element(By.id, 'kw').send_keys('python')
# 点击百度搜索
driver.find_element(By.id, 'su').click()
time.sleep(6)
# 退出浏览器
driver.quit()
执行结果
说明:
- webdriver.Chrome(executable_path=’./chromedriver’) 中executable参数指定的是下载好的chromedriver文件的路径
- driver.find_element_by_id(‘kw’).send_keys(‘python’) 定位id属性值是’kw’的标签,并向其中输入字符串’python’
- driver.find_element_by_id(‘su’).click() 定位id属性值是su的标签,并点击
- click函数作用是:触发标签的js的click事件
3 selenium提取数据
①driver对象的常用属性和方法
- driver.page_source 当前标签页浏览器渲染之后的网页源代码
- driver.current_url 当前标签页的url
- driver.close() 关闭当前标签页,如果只有一个标签页则关闭整个浏览器
- driver.quit() 关闭浏览器
- driver.forward() 页面前进
- driver.back() 页面后退
- driver.screen_shot(img_name) 页面截图
②driver对象定位标签元素获取标签对象的方法
find_element_by_id (返回一个元素)
find_element(s)_by_class_name (根据类名获取元素列表)
find_element(s)_by_name (根据标签的name属性值返回包含标签对象元素的列表)
find_element(s)_by_xpath (返回一个包含元素的列表)
find_element(s)_by_link_text (根据连接文本获取元素列表)
find_element(s)_by_partial_link_text (根据链接包含的文本获取元素列表)
find_element(s)_by_tag_name (根据标签名获取元素列表)
find_element(s)_by_css_selector (根据css选择器来获取元素列表)
注意:
- find_element和find_elements的区别:
- 多了个s就返回列表,没有s就返回匹配到的第一个标签对象
- ‘find_element匹配不到就抛出异常,find_elements匹配不到就返回空列表
- by_link_text和by_partial_link_tex的区别:全部文本和包含某个文本
- 以上函数的使用方法
- driver.find_element_by_id(‘id_str’)
③标签对象提取文本内容和属性值
find_element仅仅能够获取元素,不能够直接获取其中的数据,如果需要获取数据需要使用以下方法
- 对元素执行点击操作 element.click()
- 对定位到的标签对象进行点击操作
- 向输入框输入数据 element.send_keys(data)
- 对定位到的标签对象输入数据
- 获取文本 element.text
- 通过定位获取的标签对象的 text 属性,获取文本内容
- 获取属性值 element.get_attribute(“属性名”)
- 通过定位获取的标签对象的 get_attribute 函数,传入属性名,来获取属性的值
代码实现
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome(executable_path='E:\Java\python爬虫\chromedriver.exe')
driver.get("https://www.qq.com/")
res = driver.find_elements(By.TAG_NAME, "h2")
print(res[0].text)
res = driver.find_elements(By.LINK_TEXT, '新闻')
print(res[0].get_attribute('href'))
driver.quit()
4 selenium的其它使用方法
①selenium标签页的切换
当selenium控制浏览器打开多个标签页时,如何控制浏览器在不同的标签页中进行切换呢?需要我们做以下两步:
-
获取所有标签页的窗口句柄(句柄可以理解为是一个指针对象,它的作用就是可以控制窗口)
-
利用窗口句柄字切换到句柄指向的标签页
-
这里的窗口句柄是指:指向标签页对象的标识
-
具体的方法
# 1. 获取当前所有的标签页的句柄构成的列表 current_windows = driver.window_handles # 2. 根据标签页句柄列表索引下标进行切换 driver.switch_to.window(current_windows[0])
代码实现
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome(executable_path='E:\Java\python爬虫\chromedriver.exe')
driver.get("https://www.baidu.com/")
time.sleep(1)
# 在百度搜索中搜索python
driver.find_element(By.id, 'kw').send_keys('python')
# 点击百度搜索
time.sleep(1)
driver.find_element(By.id, 'su').click()
time.sleep(1)
# 通过执行js代码来新开一个标签页
js = "window.open('https://www.sogou.com');"
driver.execute_script(js)
time.sleep(1)
# 1 获取当前所有窗口
windows = driver.window_handles
time.sleep(1)
# 2 根据窗口索引进行切换
driver.switch_to.window(windows[0])
time.sleep(2)
driver.switch_to.window(windows[1])
time.sleep(6)
# 退出浏览器
driver.quit()
②switch_to切换frame标签
iframe是html中常用的一种技术,即一个页面中嵌套了另一个网页,selenium默认是访问不了frame中的内容的,对应的解决思路是 driver.switch_to.frame(frame_element) 。
接下来我们通过qq邮箱模拟登陆来学习这个知识点
代码实现
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome(executable_path='E:\Java\python爬虫\chromedriver.exe')
url = 'https://mail.qq.com/cgi-bin/loginpage'
driver.get(url)
time.sleep(2)
# 定位到需要的元素
login_form = driver.find_element(By.id, "login_frame")
# 转到这个frame中
driver.switch_to.frame(login_form)
# 找到账号输入框
driver.find_element(By.XPATH, '//*[@id="u"]').send_keys('350884961@qq.com')
# 找到密码输入框
driver.find_element(By.XPATH, '//*[@id="p"]').send_keys('!!!1635088##520')
# 点击登录
driver.find_element(By.XPATH, '//*[@id="login_button"]').click()
time.sleep(6)
'''操作外边的元素需要切换出去'''
windows = driver.window_handles
driver.switch_to.window(windows[0])
content = driver.find_element(By.CLASS_NAME, "login_pictures_title").text
print(content)
driver
# 退出浏览器
driver.quit()
说明:
-
通过
driver.find_element定位到iframe元素中,然后就通过driver.switch_to.frame切换到iframe框中 -
通过下面切换出去
windows = driver.window_handles driver.switch_to.window(windows[0])
③selenium对cookie的处理
selenium能够帮助我们处理页面中的cookie,比如获取、删除,接下来我们就学习这部分知识
1.获取cookie
driver.get_cookies() 返回列表,其中包含的是完整的cookie信息!不光有name、value,还有domain等cookie其他维度的信息。所以如果想要把获取的cookie信息和requests模块配合使用的话,需要转换为name、value作为键值对的cookie字典
代码实现
import time
from selenium import webdriver
driver = webdriver.Chrome(executable_path='E:\Java\chromedriver.exe')
driver.get("https://www.baidu.com/")
# 获取当前标签页所有的cookie
# print(driver.get_cookies())
# 将cookie转换成字典
cookies_dict = { cookie['name']: cookie['value']
for cookie in driver.get_cookies() }
print(cookies_dict)
time.sleep(2)
# 退出浏览器
driver.quit()
2.删除cookie
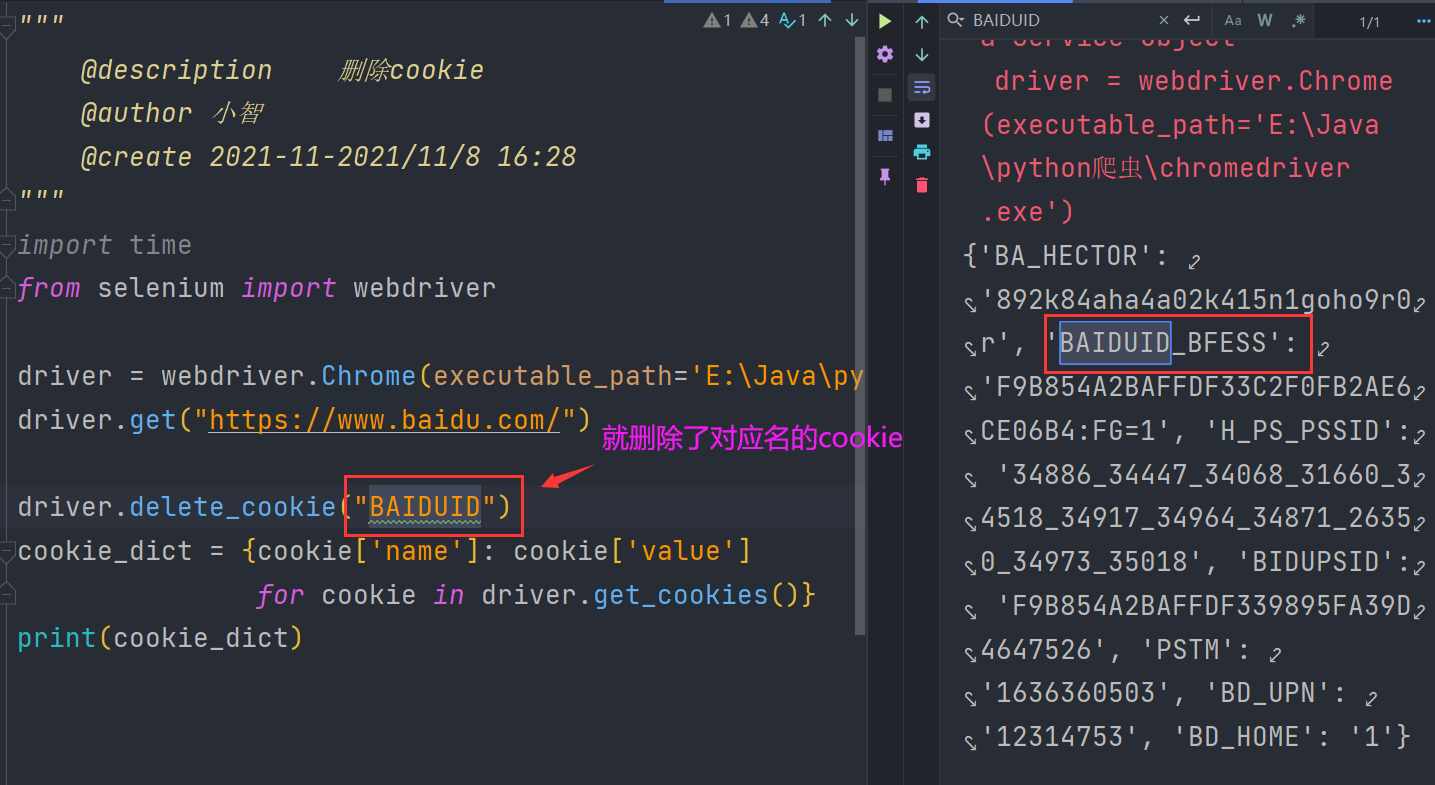
删除一条cookie
from selenium import webdriver
driver = webdriver.Chrome(executable_path='E:\Java\python爬虫\chromedriver.exe')
driver.get("https://www.baidu.com/")
driver.delete_cookie("BAIDUID")
cookie_dict = {cookie['name']: cookie['value']
for cookie in driver.get_cookies()}
print(cookie_dict)
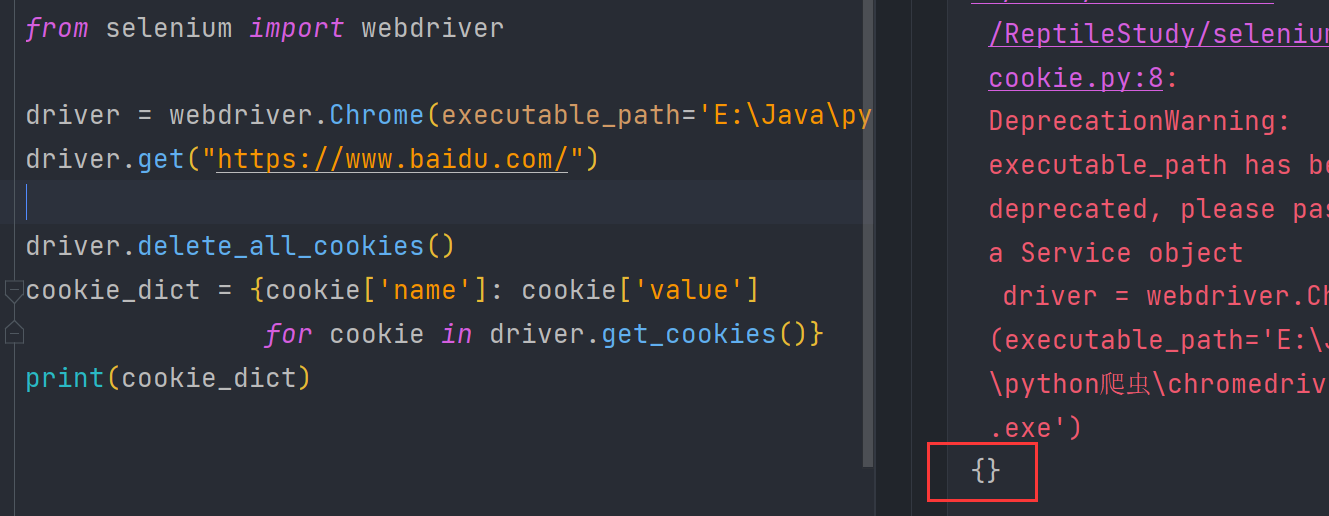
删除所有cookie
from selenium import webdriver
driver = webdriver.Chrome(executable_path='E:\Java\python爬虫\chromedriver.exe')
driver.get("https://www.baidu.com/")
driver.delete_all_cookies()
cookie_dict = {cookie['name']: cookie['value']
for cookie in driver.get_cookies()}
print(cookie_dict)
④selenium控制浏览器执行js代码
selenium可以让浏览器执行我们规定的js代码,运行下列代码查看运行效果
import time
from selenium import webdriver
driver = webdriver.Chrome(executable_path='E:\Java\python爬虫\chromedriver.exe')
url = 'https://mail.qq.com/cgi-bin/loginpage'
driver.get(url)
js = "console.log('haha')" # js语句
driver.execute_script(js)
time.sleep(5)
driver.quit()
F12打开开发者工具就可以看到控制台输出了haha
⑤页面等待
页面在加载的过程中需要花费时间等待网站服务器的响应,在这个过程中标签元素有可能还没有加载出来,是不可见的,如何处理这种情况呢?
- 强制等待介绍
- 显式等待介绍
- 隐式等待介绍
- 手动实现页面等待
注:这个就是说等待执行的时间,如果在指定的时间内找不到指定的元素或者操作,那么就会报错
注意:它会报错,所以一定要将它捕获,不然就会导致程序结束
1.强制等待(了解)
- 其实就是time.sleep()
- 缺点时不智能,设置的时间太短,元素还没有加载出来;设置的时间太长,则会浪费时间
2.隐式等待
- 隐式等待针对的是元素定位,隐式等待设置了一个时间,在一段时间内判断元素是否定位成功,如果完成了,就进行下一步
- 在设置的时间内没有定位成功,则会报超时加载
代码实现
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome(executable_path='E:\Java\chromedriver.exe')
# 隐式等待,最长等10秒
driver.implicitly_wait(10)
driver.get("https://www.baidu.com/")
content = driver.find_element(By.TAG_NAME, "title").text
print(content)
driver.quit()
3.显式等待(了解)
- 每经过多少秒就查看一次等待条件是否达成,如果达成就停止等待,继续执行后续代码
- 如果没有达成就继续等待直到超过规定的时间后,报超时异常
代码实现
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver = webdriver.Chrome(executable_path='E:\Java\chromedriver.exe')
driver.get("https://www.baidu.com/")
# 显示等待
WebDriverWait(driver, 20, 0.5).until(
EC.presence_of_element_located((By.LINK_TEXT, "好123")))
'''
参数20表示最长等待20秒
参数0.5表示0.5秒检查一次规定的标签是否存在
EC.presence_of_element_located((By.LINK_TEXT, '好123')) 表示通过链接文本内容定位标签
每0.5秒一次检查,通过链接文本内容定位标签是否存在,如果存在就向下继续执行;如果不存在,直
到20秒上限就抛出异常
'''
print(driver.find_element(By.LINK_TEXT, "好123").get_attribute("href"))
driver.quit()
4.手动实现页面等待
在了解了隐式等待和显式等待以及强制等待后,我们发现并没有一种通用的方法来解决页面等待的问题,比如“页面需要滑动才能触发ajax异步加载”的场景,那么接下来我们就以淘宝网首页为例,手动实现页面等待
原理:
- 利用强制等待和显式等待的思路来手动实现
- 不停的判断或有次数限制的判断某一个标签对象是否加载完毕(是否存在)
代码实现
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome(executable_path='E:\Java\chromedriver.exe')
driver.get('https://www.taobao.com/')
time.sleep(1)
# i = 0
# while True:
for i in range(10):
i += 1
try:
time.sleep(2)
element = driver.find_element(By.XPATH ,'//div[@class="shopinner"]/h3[1]/a')
print(element.get_attribute('href'))
break
except:
js = 'window.scrollTo(0, {})'.format(i * 500) # js语句
driver.execute_script(js) # 执行js的方法
driver.quit()
⑥selenium开启无界面模式
绝大多数服务器是没有界面的,selenium控制谷歌浏览器也是存在无界面模式的,这一小节我们就来学习如何开启无界面模式(又称之为无头模式)
说明:无界面模式就是不会弹出浏览器
- 开启无界面模式的方法
- 实例化配置对象
- options = webdriver.ChromeOptions()
- 配置对象添加开启无界面模式的命令
- options.add_argument("–headless")
- 配置对象添加禁用gpu的命令
- options.add_argument("–disable-gpu")
- 实例化带有配置对象的driver对象
- driver = webdriver.Chrome(chrome_options=options)
- 实例化配置对象
- 注意:macos中chrome浏览器59+版本,Linux中57+版本才能使用无界面模式!
代码实现
from selenium import webdriver
# 创建一个配置对象
options = webdriver.ChromeOptions()
# 开启无界面模式
options.add_argument("--headless")
options.add_argument("--disable-gpu")
# 实例化带有配置的Driver对象
driver = webdriver.Chrome(
executable_path='E:\Java\python爬虫\chromedriver.exe',
chrome_options=options)
driver.get("https://www.qq.com")
print(driver.title)
driver.quit()
⑦selenium使用代理ip
selenium控制浏览器也是可以使用代理ip的!
- 使用代理ip的方法
- 实例化配置对象
- options = webdriver.ChromeOptions()
- 配置对象添加使用代理ip的命令
- options.add_argument(’–proxy-server=http://202.20.16.82:9527’)
- 实例化带有配置对象的driver对象
- driver = webdriver.Chrome(‘chromedriver’, chrome_options=options)
- 实例化配置对象
代码实现
from selenium import webdriver
# 创建一个配置对象
options = webdriver.ChromeOptions()
# 开启无界面模式
options.add_argument("--proxy-server=http://59.42.30.41:4245")
driver = webdriver.Chrome(
executable_path='E:\Java\python爬虫\chromedriver.exe',
chrome_options=options)
driver.get('http://www.qq.com')
print(driver.title)
driver.quit()
⑧selenium替换user-agent
selenium控制谷歌浏览器时,User-Agent默认是谷歌浏览器的,这一小节我们就来学习使用不同的User-Agent
- 替换user-agent的方法
- 实例化配置对象
- options = webdriver.ChromeOptions()
- 配置对象添加替换UA的命令
- options.add_argument(’–user-agent=Mozilla/5.0 HAHA’)
- 实例化带有配置对象的driver对象
- driver = webdriver.Chrome(‘chromedriver’, chrome_options=options)
- 实例化配置对象
代码实现
from selenium import webdriver
# 创建一个配置对象
options = webdriver.ChromeOptions()
# 开启无界面模式
options.add_argument("--user-agent=Mozilla/5.0 HAHA")
driver = webdriver.Chrome(
executable_path='E:\Java\python爬虫\chromedriver.exe',
chrome_options=options)
driver.get('http://www.qq.com')
print(driver.title)
driver.quit()
tp://202.20.16.82:9527’)
- 实例化带有配置对象的driver对象
- driver = webdriver.Chrome(‘chromedriver’, chrome_options=options)
代码实现
from selenium import webdriver
# 创建一个配置对象
options = webdriver.ChromeOptions()
# 开启无界面模式
options.add_argument("--proxy-server=http://59.42.30.41:4245")
driver = webdriver.Chrome(
executable_path='E:\Java\python爬虫\chromedriver.exe',
chrome_options=options)
driver.get('http://www.qq.com')
print(driver.title)
driver.quit()
⑧selenium替换user-agent
selenium控制谷歌浏览器时,User-Agent默认是谷歌浏览器的,这一小节我们就来学习使用不同的User-Agent
- 替换user-agent的方法
- 实例化配置对象
- options = webdriver.ChromeOptions()
- 配置对象添加替换UA的命令
- options.add_argument(’–user-agent=Mozilla/5.0 HAHA’)
- 实例化带有配置对象的driver对象
- driver = webdriver.Chrome(‘chromedriver’, chrome_options=options)
- 实例化配置对象
代码实现
from selenium import webdriver
# 创建一个配置对象
options = webdriver.ChromeOptions()
# 开启无界面模式
options.add_argument("--user-agent=Mozilla/5.0 HAHA")
driver = webdriver.Chrome(
executable_path='E:\Java\python爬虫\chromedriver.exe',
chrome_options=options)
driver.get('http://www.qq.com')
print(driver.title)
driver.quit()















 5760
5760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









