









前言
看过很多技术文档,也浏览过很多种技术方案,也实际上简单了解上手和面临过类似这种线上问题,但是一直没有一个很完整的一个记录,JVM调优,一个看起来很高大上,但是一个基本上现在的Java工程师都需要掌握和面试必须要经历的一个技术,但实际上能在公司真正的线上能去上手调优的机会少之极少,很多人可能谈吐起JVM,哗啦哗啦,但是实际上一上手,就可能会小鹿乱撞,但是线上的系统,实际上试错率几乎为0,所以这样的机会,在大型互联网,或者是互联网公司,是压根给不了这个尝试性去调优jvm的机会的,这次分享一个我们线上的问题,和我自己处理线上JVM的一次算是半完整的机会,此片博客仅为分享和记录,本人并不是一个专业的运维人员,对于JVM掌握的也微不足道。
1. 线上环境突然慢了下来,但是重启系统就能解决这个慢的问题,为什么?【可能比较啰嗦,但是我希望记录一次完整的记录】
1.1:记得刚刚进入新公司的时候,老大就说过线上系统的jvm的问题,但是系统也不至于说到不能用的这个份上,由于我们系统是一个比较大型的ERP系统,而且每次需求都是十分急促的,导致代码可能就" 你懂的 ",很大一部分原因也是每个人都很忙,需求也是并行开发,而需求是又多又杂乱(有客服的需求,有线上的bug,有财务的需求,还有需要重构,组织架构的等等需求),每个人都是各自忙碌自己的工作,也少了一项< code review>这个重要的环境,大概就真的变成的网上传言的 “
千万别动我代码”,所以实际上很大一部分原因也是这个代码的不规范和不合理的写码导致的,但是压根没有时间去分析gc和线上系统的jvm问题,一直使用的都是默认的jvm配置,实际上是完全不合理的,突然有一天,也就是向前推移大约一周左右,系统需要12个小时左右重启一次,或者是说,系统慢下来了,甚至一些功能会直接超时,期间之前还导致过线上系统的OOM的情况发生,我们总共有三台服务器,曾经出现过宕机的情况。大体情况就是这样的一个情况,再介绍就没有过多的意义了。
2.线上系统的JVM排查过程,这里大概贴个图,时间紧,任务急,2天如何拯救线上环境,简单:派一个人专门负责重启系统就完事了,只是频率问题啦!
所以在这个一步步的同时也在请教大佬,去多取取经,吸收一下大佬们的解决方案,少走弯路,但是就如文章前言所说,真正上手线上系统的技术人员很少,但是确实很多大佬也给了一些建议,所以,也算是突破了一个受限,至少大概能从什么地方着手,下手,屁话不多说,开战!
3. 首先了解下几个JVM常用的一些命令和观察线上GC的一些基础命令,和线上环境的服务器分配比例
1、整个过程用到的Linux的一些操作命令(仅gc):
- jstat -gc PID 【gc日志】
- jmap -heap PID 【内存分配比例和使用率,实际上上面的命令也能看到,但是可能没有jmap观看起来这么方便】
- java -XX:+PrintCommandLineFlags-version 【查看线上使用的垃圾回收器】
- free -m 【这里留个伏笔,这个命令是后添加上去的,但是至于究竟是如何观察的,我自己也还在研究,没有想透彻,仅此分享一个案例】
【整个调优的过程我也就只是用到了以上的三个命令】
2、当然,jstat还有很多命令,这里就直接贴出来了,但是真正的我也只是用了其中的几个而已,大概就是如下:(这些东西是百度上的,基本上百度一下就有了)
jstat -gccapacity PID:堆内存分析
jstat -gcnewcapacity PID:年轻代内存分析
jstat -gcold PID:老年代GC分析
jstat -gcoldcapacity PID:老年代内存分析
jstat -gcmetacapacity PID:元数据区内存分析
jstat -gcnew PID:年轻代GC分析,这里的TT和MTT,可以看到对象在年轻代存活的年龄和存活的最大年龄
3、前提条件得准备充分,虽然之前对垃圾回收器是有比较拿手的一些方案和了解的垃圾回收器,但是真正是否使用,也是根据线上环境来的,于是我也提前了解好了,放入到了自己的本地文本文档上面,方便调试的时候,或者选择的时候更加的有针对性,更方便自己观看,这算是一种个人习惯,在下面给各位大佬贴出来:
Serial:几十兆
PS:上百兆 ~ 4G
CMS:4G ~ 10G
G1:10G~上百G (G1)
ZGC: 4T - 16T(JDK13)
4、我们线上环境服务器分配比例:
1、沙箱环境的服务器:4核 * 16G;
2、正式环境的服务器:三台,分别为:4核 * 16G 两台,8 * 32G 一台。
具体介绍大约也就是这里的,准备工作虽然不够充足,但是也基本上算是紧急调试够用了。
4. 逼也装完了,差不多就到这里了【仅调情】
1、java -XX:+PrintCommandLineFlags-version 【首先我就看了线上默认的垃圾回收器使用的是那个垃圾回收器,关于垃圾回收器,到时候有空专门整理一份,一直没有闲下来的时间去整理,实际上很早之前就已经深入的了解过了一些,但是可能没有这么完整,可以借鉴,等写完贴到此处】
命令日志如下:【以下就能看出使用的是那种此时采用的是哪种垃圾回收器】
-XX:InitialHeapSize=515083264 -XX:MaxHeapSize=8241332224 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC java version “1.8.0_261” Java™ SE Runtime Environment (build 1.8.0_261-b12) Java HotSpot™
64-Bit Server VM (build 25.261-b12, mixed mode)
2、jstat -gc PID 【敲完这个命令,出现的就是一下密密麻麻的一些东西了】
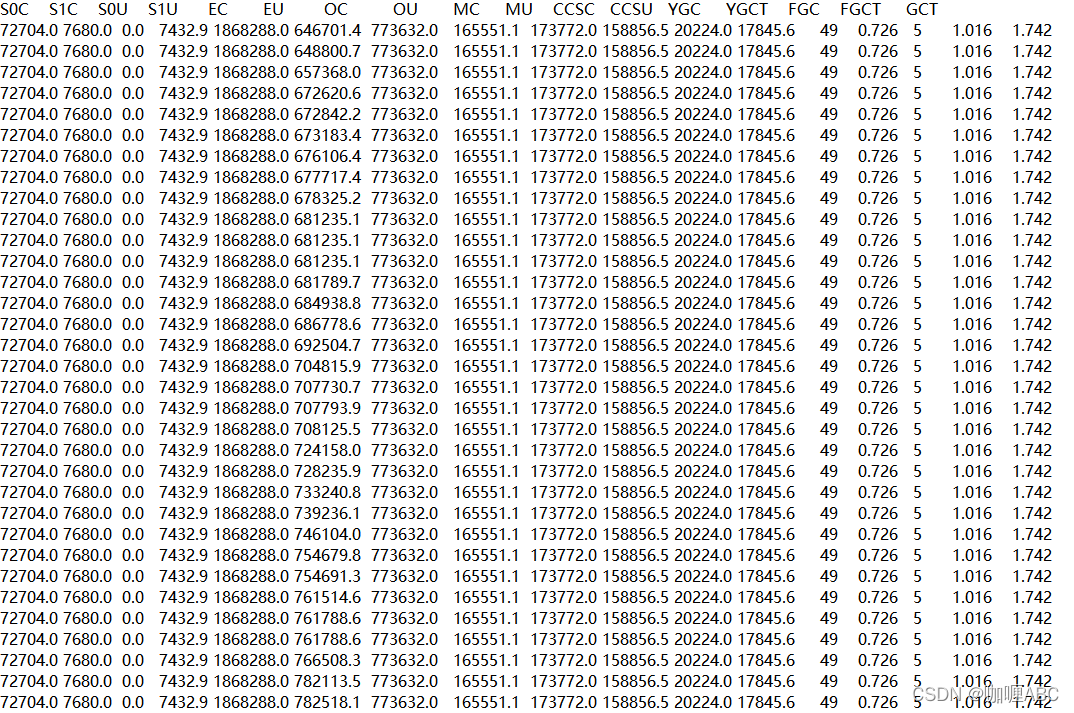
前提:需要对jvm有个大概了解的,可能看这篇文章没有如此的费劲,那么简单的再次截个图,标记几个重要的东西和重点观察的位置。

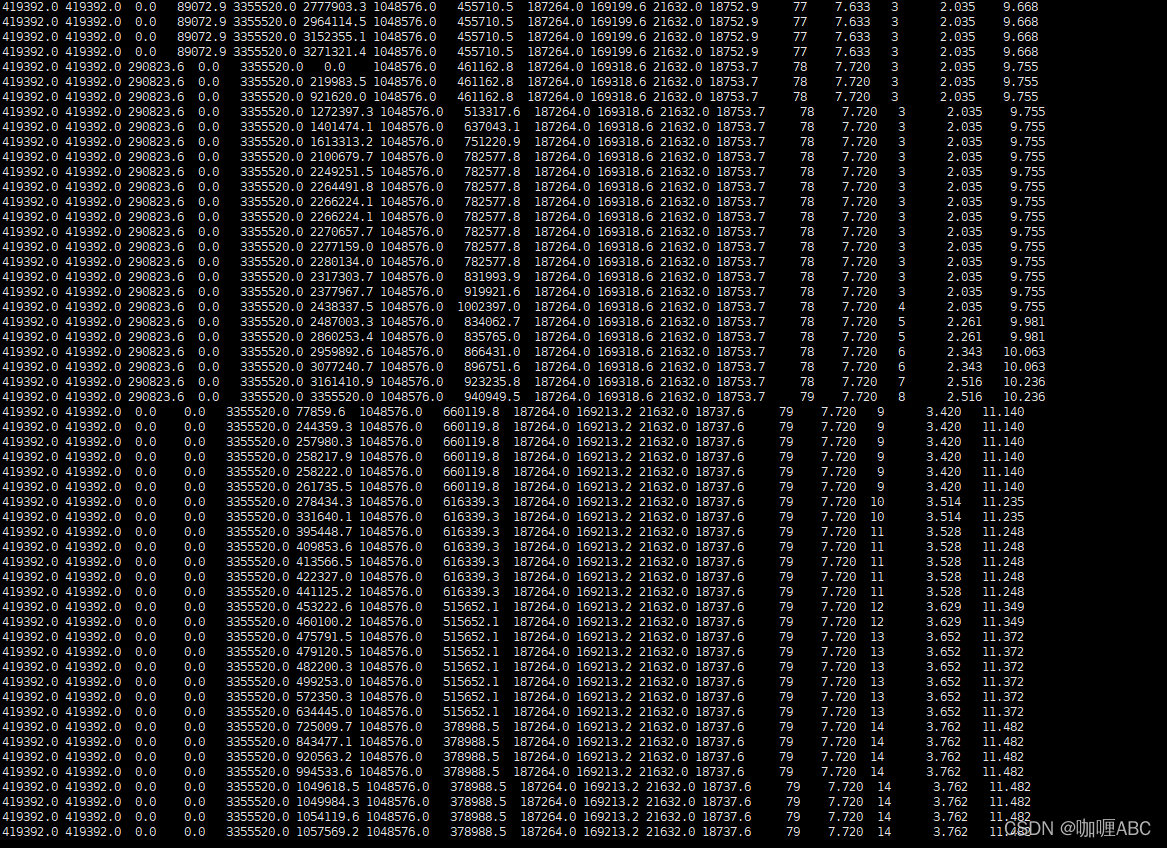
基本上圈出来,简单标注了一下下,我们简单的分析一下,首先简单的算一下这些个大概的数值,我们就以MB为单位。
1.72704KB ≈ 71 MB S-From区
2.7680KB ≈ 7MB S-To 区
卧槽,这不一下就看出问题来了,简直就是一个惊喜呀,第一次打日志就出现了问题,迅速飞转一下,为什么一下就看出问题了,可能稍微对gc有过稍稍了解的,就知道,堆内存的年轻代分区大约是这样的,我简短画个图,具体怎么演进的,大家可以去我的JVM专栏去看一眼。
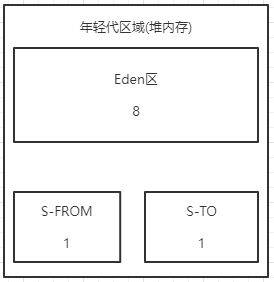
也不花里胡哨,简单的介绍一下,现目前基本采用的回收算法都是复制算法,但是这个复制算法会分为两种,这种是演进后的,也就是比例8:1:1,演进之前的是5:5的,为什么这样,这里也只是简单介绍一下,因为只是实战分享,而不是技术分享,所以不过多解释,为了就是让年轻代空间更多的被利用起来,那么为什么说第一眼就看出问题了,因为一次垃圾回收大约是这样的。
此时出发一次gc,从打印日志的gc情况来看,Eden区域为:1868288KB ≈ 1868MB 也就是当对象占用一定的内存,就会发生一次年轻代的GC,也就是YOUNG GC或者是说教MINOR GC,总体来说就是年轻代GC,那么此时会发生的事情就是,s0区会将自己本身还存活着的对象全部放入到s1区,还将本次gc存活的对象全部放入s1区,那么就会清空s0区,这样复制和清空的好处就是防止内存碎片化。但是问题来了,此时s1区的空间只有7MB,但是S0区的空间有71MB,如果移动,推测,s1区可能装不下,90%以上的几率会直接进入到老年代区域,那么我们顺藤摸瓜,直接将老年代的空间计算出来 773632 KB ≈ 773MB 这样一看老年代还是能装一些对象的,那么我们顺着思路继续…
哎,打字有点累了,推荐一首歌曲,老劲爆了 【三天三夜】每周5天,加班三天,三夜是睡不好的
由上分析,老年代有773MB,我们先暂停脚步,分析一下Eden区的一个增长速度,也就是new XXX()对象产生的新对象的速度,这里注释下:会有高峰期和低谷期,建议取区间最大的也就是高峰期去分析,然后做空间和gc频率调整 增长前:708125.5KB≈708MB 增长后:724158.0 KB ≈ 724MB,简单做个计算题(724MB - 708MB)= 16MB,那么我们再计算一下Eden区域的总大小为:1868288.0 KB ≈ 1868MB,再做一个计算1868MB / 16MB ≈ 116.75秒,然后再除以 60 ,那么大约也就是2分钟左右就是一次年轻代的gc。这样我们就推算出来了年轻代gc的一个频率和时间。
接下来,写了很久了,也要下班跑路了,祝你们圣诞节快乐,俺要去过圣诞节啦,先更新到这里。
5. 想了一下,还是更新在一篇文章,就不更新几篇了,连续思考
首先我们摘要一下上面段落的信息:
根据上面简单打印的日志,发现了几个稍微重要的信息:
1.1868288KB ≈ 1868MB Eden 区的总大小
2.S0 = 72704KB ≈ 71 MB 幸存者1区
3.S1 = 7680KB ≈ 7MB 幸存者2区
4.(724MB - 708MB)= 16MB 系统中每秒大约产生的对象
5.1868MB / 16MB ≈ 116.75m 年轻代大约的时间为1m30ms秒到2m
6. 773673KB ≈ 773MB 老年代的总大小
7. 165551 ≈ 165 MB 老年代已使用大小
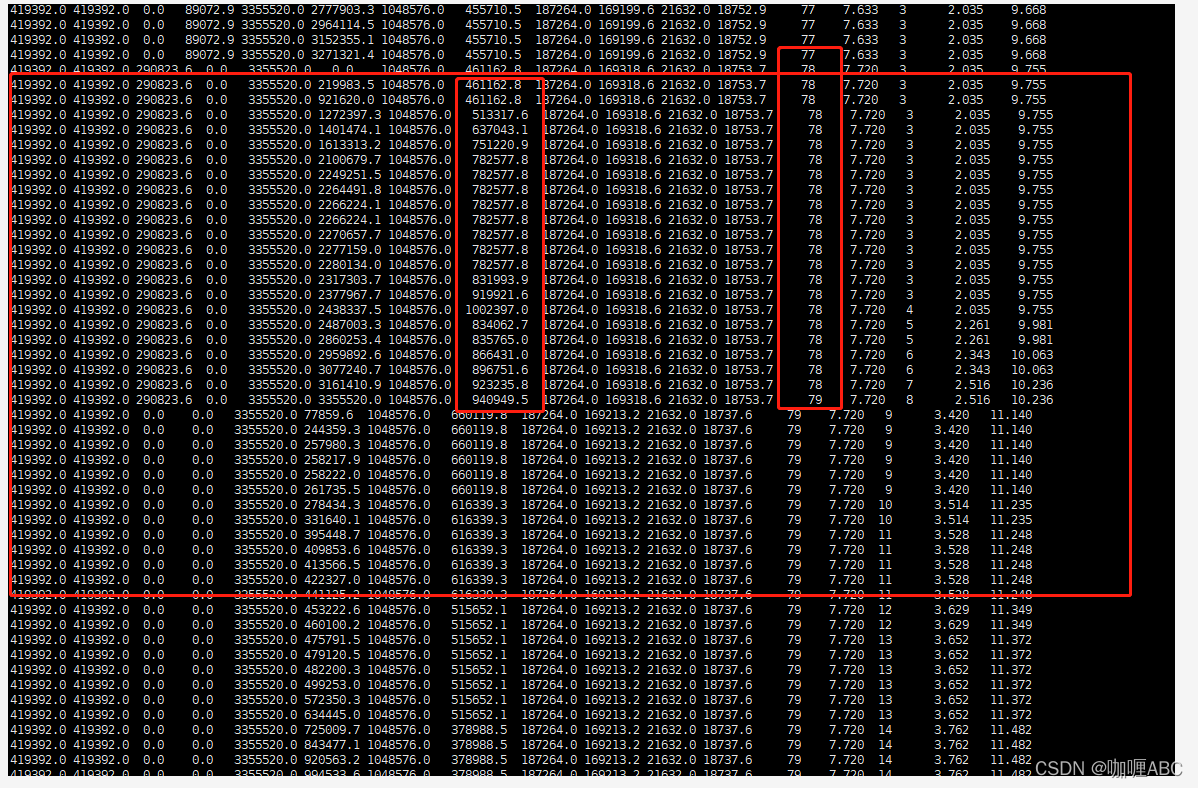
这样推算就能推算出来大概的一次完整gc过程了,于是就等待Eden区域快要填满的时候,观察gc的过程,于是大约等了大约和上面1mNms的时候,就看到了如下让我意想不到的截图。
如图:
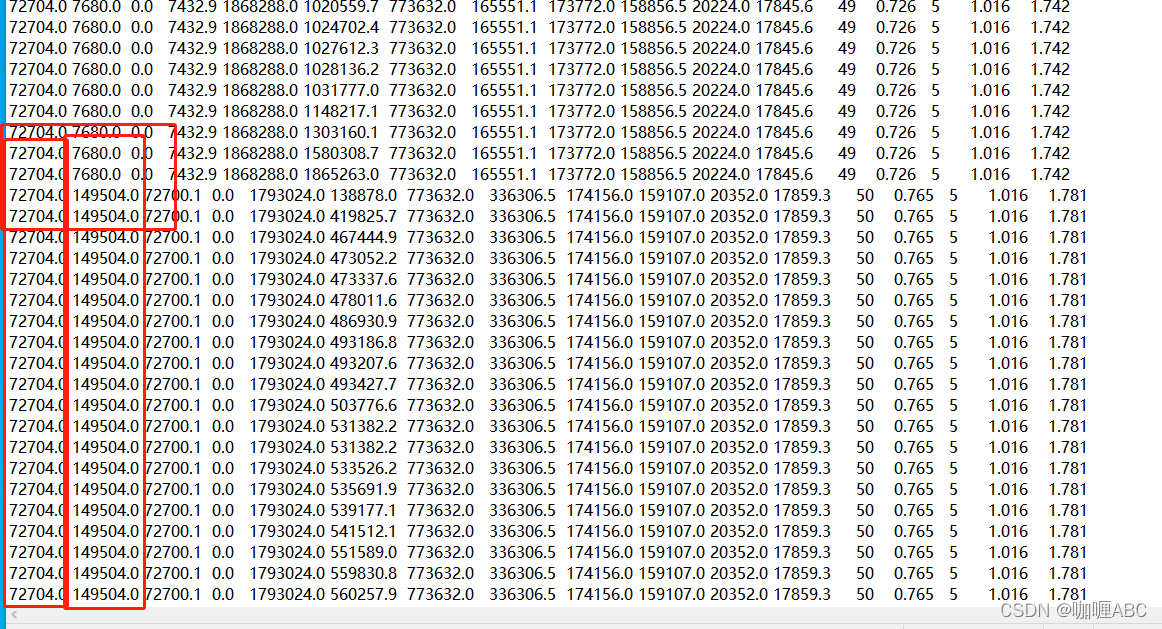
看起来是没有什么问题的,young gc叠加了一次,full gc叠加了0次,整个过程看着是没有什么问题的,但是我发现,也就是纵向红色框中的,幸存者区域自动“扩容了”,为什么呢,实际上在我了解的知识领域,我也不是很清楚,这就很尬,于是可能看到这里的大佬已经注意到了,文章的开头就看到了,没有指定垃圾回收器,jdk1.8使用的默认parallel收集器,并且parallel开着自适应调节,所以会动态变化幸存者区的大小,这也算是我听到和看到回答中的一个稍微能解释通的回答,现目前线上还是存在gc问题,只是没有极大影响到系统,所以这个问题可能在后面的jvm专栏会更新。【留问及伏笔-也希望如果有知道的大佬能在评论区解答下】
6.这下大约的找到了问题所在,能开始上手开始调优了?至少我开始了,先上下测试看看这堆参数丢上去是否生效了,于是有了第一个模板:
沙箱环境的服务器的配置为:4 * 16G
nohup java -jar
-Xms10240M
-Xmx10240M
-Xmn8192M
-Xss1M
-XX:MetaspaceSize=512M
-XX:MaxMetaspaceSize=512M
-XX:SurvivorRatio=8
-XX:MaxTenuringThreshold=15
-XX:PretenureSizeThreshold=1M
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:+UseCMSCompactAtFullCollection
-XX:CMSFullGCsBeforeCompaction=0
logisitics-modules-system-2.1.0-SNAPSHOT.jar &
上面的参数是什么意思,大概的解释一下,网上也有许多,前面三个参数就是堆内存的大小设置,其中的Xmn就是设置heap中的年轻代总大小,此时我的分配比例,大约是YC heap的5/4,OC heap的5/1,当然后面也做了调整,后面慢慢发现解决,其他的参数大约就是这些,大对象1m,元数据区域512mb,最后上生产我还是配置成了512,还有Eden区和S1,S2的分配比例,年轻代存活年龄多少进入到老年代中,指定年轻代垃圾回收器为ParNew,指定老年代的垃圾回收器为CMS,大概就这些信息,于是,我就在沙箱服务器上启动了项目。《这里八卦一下,顺带说下自己的骚操作,我打的命令是这样的:
nohup java -jar logisitics-modules-system-2.1.0-SNAPSHOT.jar -Xms10240M -Xmx10240M -Xmn8192M -Xss1M -XX:MetaspaceSize=512M -XX:MaxMetaspaceSize=512M -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=15 -XX:PretenureSizeThreshold=1M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0 &》,于是我就stat -gc
pid,发现没有生效,这必然是启动命令的问题,于是也发生了一些很尴尬的事情,就出现了其中的单词打错了,等等这些问题,就不一一举例了,以上红色字体的问题就是一个细节问题,所以注意下就行了,请和我一样的小白去和上面的启动命令对比一下,就知道问题了。
7.来来来,启动一个爷瞅瞅!
启动了,参数也生效了,自信满满,感觉没啥问题,能有啥问题,迷之自信,因为第一次排查的问题基本上在这个参数上就解决了,为什么这么说,我们简单解释一下,为什么不用G1的垃圾回收器,也是有笔者的考虑,先聊聊为什么直接就这么敲定了这个模板上线了,回想之前的问题,做了两个调整,第一个调整就是young 新生代的大小为了10g,这样一次gc的时间就从116ms,变成了大约 400ms 大约7-10分钟左右才会发生一次年轻代gc,Eden区的大小也分配为了6G-0.8G-0.8G,这样YGC发生之后,幸存者区域也有足够大的空间能够承受下来,大对象1mb也能直接进入到老年代(根据配置),也能保证幸存者区域的大小有足够的空间移动,尽可能这些对象在young
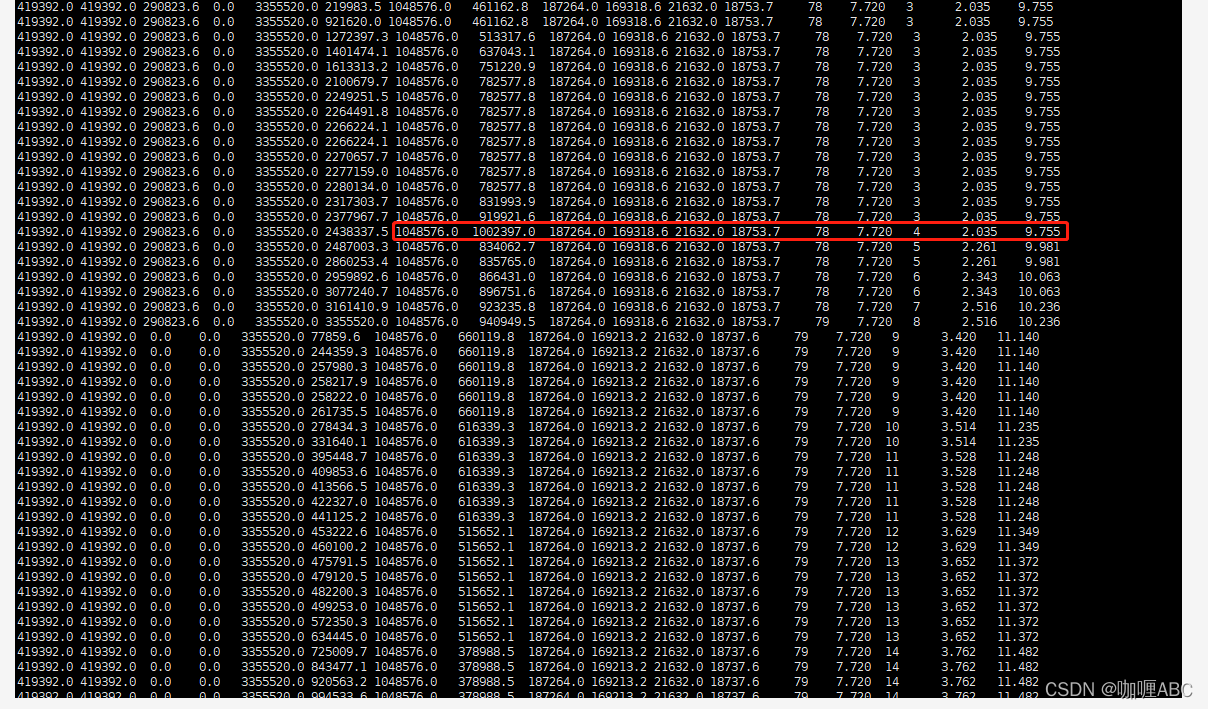
gc的时候就会被清理掉,但是这个时候我们暂且不要去预算老年代的动态年龄判断等等这规则和情况,我们暂且考虑这个15岁进入到老年代和大对象,那么这样的话,不考虑大对象的情况,推算大约系统运行100分钟会有一部分对象会进入到老年代,粗略的对比了一下,大约是21MB对象会进入老年代,这个也不是盲猜的,jmap看更方便,当然jstat -gc也能看: 如图:
总体就是867MB - 846MB ≈ 21MB【有图有证据】


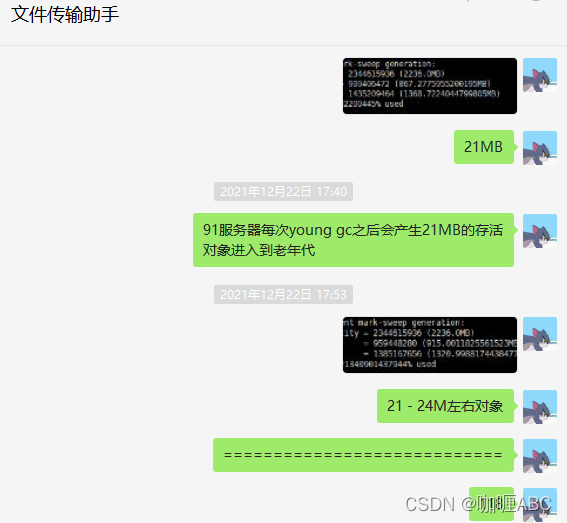
当然这个数据是线上截图出来的,会与上文有些不符合,但是将就看,哈哈哈,比较粗糙。所以只要够细,就能把一个系统算死,这样我们就能推测出,老年代一次gc和年轻代一次gc的大概时间了,也就是大约100分钟会产生21MB左右的对象,算30MB吧,当然jmap日志我也打了不止一次,算30mb只会多,不会少,那么老年代我设置的是92%才会发生一次gc,这样的话,我们就以线上的为准,2236mb* 92% / 30mb = 68次,也就是算出来了,年轻代大约gc68次才会发生一次FULL GC,而我们前面计算的年轻代大约是7-10分钟,这样我们将大对象考虑进去,算60次 * 7分钟,也就是420分钟 / 60 ≈ 7小时,个人感觉,这样算下来,基本上就够了。
【ps:希望理解一下笔者,我觉得重在理解,我也是拿着调试的时候的一些截图和线上的截图计算的,小弟在此谢过了】
8.那就上一版正式吧!服务器直接宕机90分钟,还好是中午上线的,不然早晚祭天,所以上线要中午上…
先讲下:正式服务器其中的一台配置为:4 * 16G
稍微总结一下:
年轻代GC: 大约7-10分钟左右才会发生一次年轻代gc;
老年代GC: 大对象考虑进去,算60次 * 7分钟,也就是420分钟 / 60 ≈ 7小时
当我打完这段命令之后,服务器也没有直接宕机,但是xshell直接卡死了,具体截图:
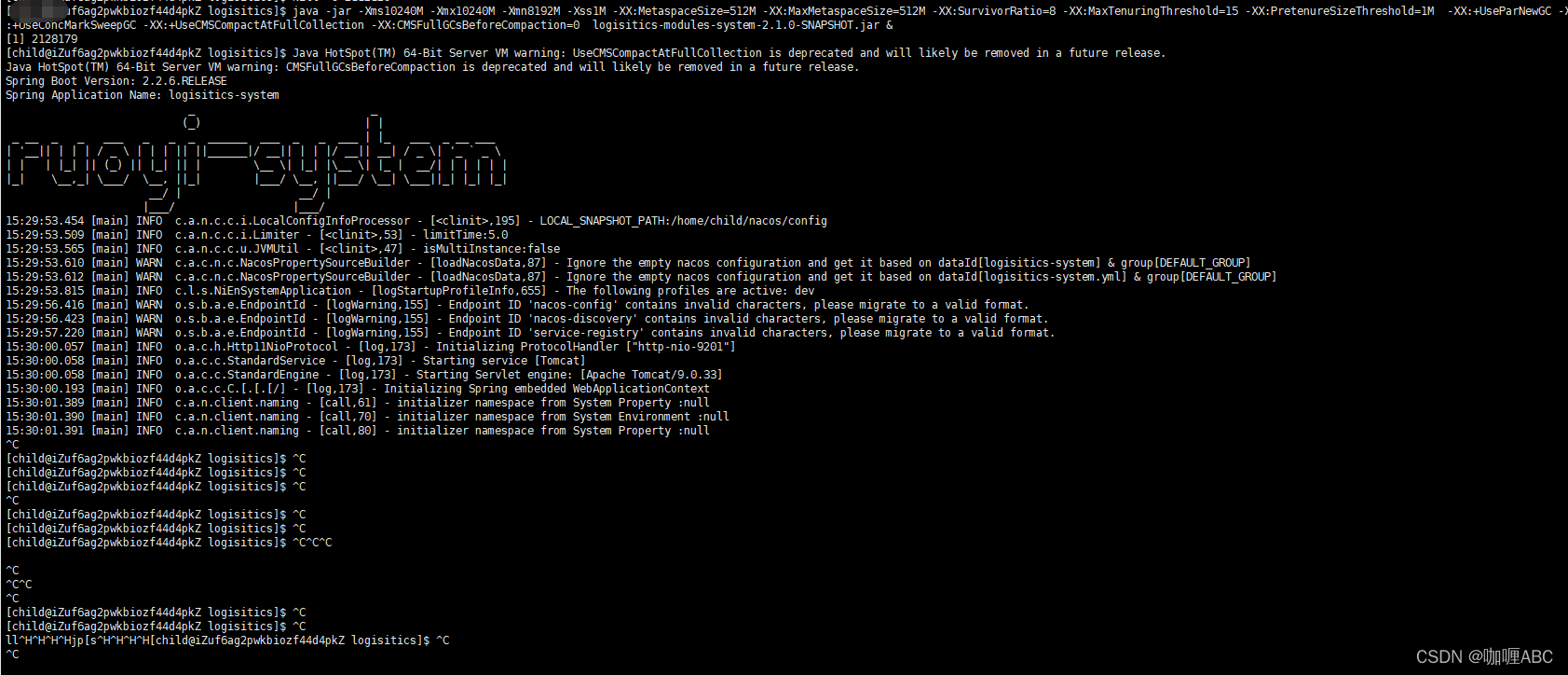
但是第一反应就停了公司的nginx,系统停机,也是一个线上事故了,于是第二反应就是ping 线上服务器,能ping通,说明服务器没有完全挂掉,但是只想分析出来具体原因,此时确实是比较慌的,毕竟属于生产事故了,太具体的原因由于笔者是一个开发岗,我们目前没有配置运维岗,也咨询了一部分运维大佬也未能解释的很清,也有一部分大佬直接说出了内存问题,最后推测是这样的,现在截图是线上的一个截图:

total大小:16G
used已使用 的物理内存大小:13G
free还有多少物理内存可用:273MB
buff/cache被buffer和cache缓存使用的物理内存大小:2G
available 还可以被引用程序使用的物理内存大小:1.9G
注意:free是真正未被使用的物理内存数量,available是应用程序认为可用的内存数量,这里有个大概的计算方式:available = free + buffer + cache
为什么突然要提这个内存,实际上也就是推测这个卡死的问题,假设:可用的物理内存还剩下5G,那么你上来就给分配了10G内存给heap,那么在分配时候,就会出现上面能启动,但是启动到一半直接卡死了,当然这也只是一部分的推理和推算,具体原因笔者现在也需要一个解释和回答,那么跟着推测的思路继续走,于是就ps -ef | grep java 看了一下本服务器上的服务:
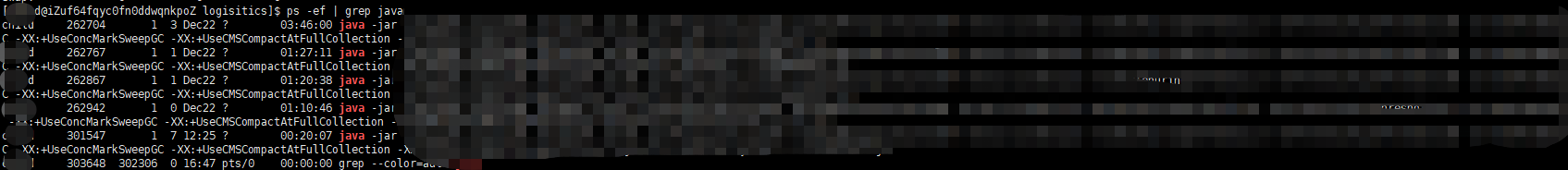
就出现了下面的一张内存分配图,这个也只是笔者的一个内存推算和分布,如图:
以上是其中一台服务器上面的内存分配,于是继续在沙箱服务上面继续玩,完事第二次上线上环境,也是抱着推测的心态,于是找了午休的这个时间段,直接停机更新服务,启动成功了,三台服务器都启动成功了,虽然现在还没有来得及去分析上次的这个故障,但是基本上推理也能推出来十有八九就是内存分配的问题,所以到现在也只是猜测,但是系统运行了接近一周,目前没有宕机。
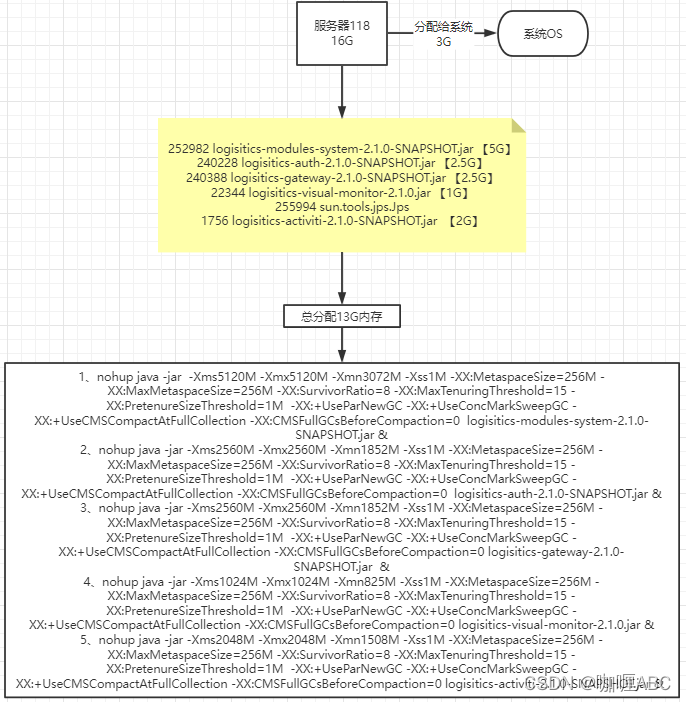
小总结:上正式需要谨慎,否则就是生产事故,严谨上线《所以我一股脑,启动命令一敲,服务器就挂了。。。哈哈哈哈,的确有些尴尬,也是一个low逼问题》
9.运行起来了,一眼盯着三台服务器的gc日志【完美收官?】
白天一直都是很稳定的,因为我们公司有国外的业务,国外的圣诞就是过年,所以我们要在22,23号这两天将国外业务对接完毕,所以就…通宵维护系统了,基本最后一次将jvm调上去之后,系统都算比较稳定,gc次数都比较合理,但是突然我们公司的打单很慢,超时,这就是代码的问题了,于是解决了打单的代码重新上线,基本系统就稳定下来了。
不可能,要是线上jvm调优如此简单,那基本上读过jvm的书,都可以完成实战
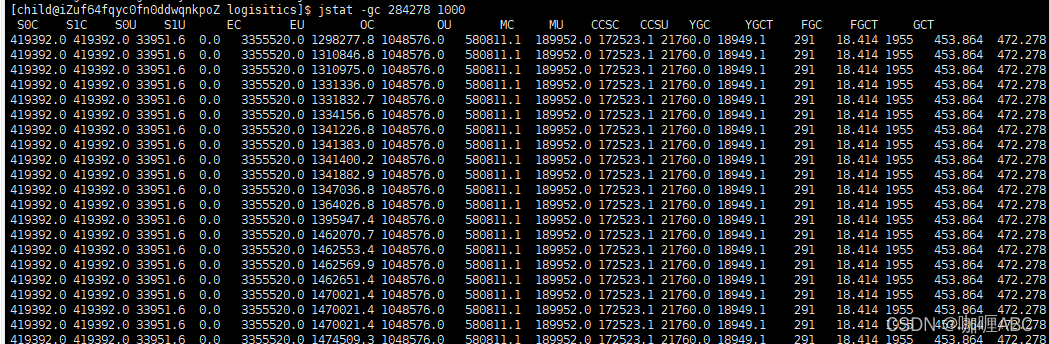
为什么这么说,实际上笔者在进行这一次jvm调优的时候,心里是有很多准备随时上线调整参数的,但是只要系统稳定下来,剩下的也无非就是微调了,所以老大也给了充足的时间和信任让我去做这件事情,我们来分析这一段线上就jstat-gc日志:
很好玩,也很惊悚的一段日志,这段日志正是在系统高峰期打出来的这段日志,如果内存迟迟不得释放,就会oom了,所以:很慌…
遇上不慌,欲速则不达,善于分析,推理,每个猿都是福尔摩斯,继续推算推理
首先了解三个问题:
1.为什么会出现这种情况:
猜测:(大胆推测,看日志大约是这样的【看截图】)
从图中看出:年轻代没有发生gc,但是老年代的内存在一直肥大,而且基本没有规则可言,我推测一种原因:大对象,此时也是系统使用的高峰期,可能产生了很多大对象,放入到老年代了,目前我能想到了也只有这一种原因去解释这种情况了。
2.老年代的垃圾次次无法被回收
从图中这一组日志向下分析,此时老年代触发gc 但是只是回收了大约1002 - 834 = 170MB左右的空间出来,但是老年代还在每秒生长,那么为什么第二次gc呢,也就是压根老年代没有达到92%我设定好的值,也发生了gc,实际上这点,笔者也需要深入去了解,这里我猜测是这样的,老年代触发了一个机制,也就是自动判断了年轻代gc之后的幸存者区域可能会过来290mb,老年代也有一个机制会去动态判断系统重启以来每次的存活对象进来老年代,可能会发现,自己可能装不下这些存活对象,自身继续触发回收,当然这个也只是推测,目前经过调节,也没有能捕捉到这样的日志,目前笔者也需要继续深入理解jvm,才能更好有理的解决这个问题,但是目前猜测和推测证明是有些原因的,于是老年代对象还是无法释放,这里老年代的释放规则可以去笔者的jvm专栏看回收机制。
3.虽然无动于衷,但是也准备了一些方案,期间也搜索过一些命令:强制手动Full gc
1、jmap -histo:live
或者
2、jmap -dump:live,file=dump_001.bin PID
然后删掉dump_001.bin文件
虽然实际上是没有执行这两行其中一行命令,因为是生产上,而且还是系统使用高峰期,我也无法预估
试错的可能。所以抱着侥幸,后面也未能看到这样的日志了侥幸渡过。
系统运行了近一周【继续打开日志】(美女-豪车选哪个?可怕的日志!该死)
YGC:291次
FGC 1955次
虽然没能看到上面发生的问题,但是猜测也出现了如上的老年代一直无法回收,并一直在回收,没有回收掉才会导致回收这么多次。于是这也是内存分配不合理出现的问题,文章前言也聊过了,例如heap总共分配了10g,那么年轻代分配了8g也就是5/4,
老年代分配了5/1,这样话的保住了年轻代,舍弃了老年代。这就是问题所在了
。
为什么要code review,做好code review,jvm不是事
实际上分析到这里,基本上很多都是代码的问题,所以每个项目都有每个项目的特征和需求,根据具体业务需求来,根据实际日志来,调优是一个漫长的过程,实际上我们目前的代码也在重构中,于是最后jvm分配区域内存为:Y:3/2,O:3/1,目前系统也在运行,具体后面还会引发和调整哪些参数,后续笔者会继续分享,此次分享很low,也很长,能看完也是真爱,评论区也希望得到大佬多一些的指点《来自菜鸡的分享暂时结束了》。















 2492
2492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











