







文件
长期存储在 长期存储设备上 的数据
长期存储设备: 硬盘;U盘; 移动硬盘; 光盘。
计算机 只能识别 二进制数据
文件文件 和 二进制文件
文件文件:可以用文本编辑查看
python的源程序,txt文件
二进制文件:提供给软件使用的文件
图片文件,音频文件,视频文件等
操作文件的基本操作
- 打开文件
- 读写文件
读 将文件内容读入到内存
写 将内存内容写入文件 - 关闭文件
操作文件的函数/方法
open 打开文件,并且返回文件操作对象
read 将文件内容读取到内存中
write 将指定内容写入文件
close 关闭文件
读取文件
open
read
close
打开文件后,不关闭,会造成 占用系统资源,文件后续不能访问。
# 打开文件
file = open("README")
# 读取文件内容
text = file.read()
print(text)
# 关闭文件
file.close()
文件指针
read方法 执行后,会把指针移动到 调用到文件 的 末尾。
打开文件的方式
f = open(“文件名”,’访问方式‘)

这种方式,会删除原文内容,从头开始写
# 打开文件
file = open("README", 'w')
# 写入文件
file.write("hello")
# 关闭文件
file.close()
在原文后面追加,传入参数a
# 打开文件
file = open("README", 'a')
# 写入文件
file.write("hello")
# 关闭文件
file.close()
加上 + 就是 读写 w+ a+,但会导致效率低下
readline
read 方法是一次性读取全部内容
readline 方法 是 一次 只读取 一行内容,方法执行之后,指针会移动到下一行
# 打开文件
file = open("README")
while True:
t = file.readline()
print(t)
# 判断是否读取到内容
if not t:
break
# 关闭文件
file.close()
复制文件
打开源文件1,复制出新文件1
只读方式打开源文件
只写方式打开新文件
将读取到的内容(源文件)写入到新文件中去。
# 打开原文件
file_read = open("README")
# 打开目标文件
file_write = open("README[复件]", 'w')
# 读写
text = file_read.read()
file_write.write(text)
# 关闭文件
file_read.close()
file_write.close()
大文件的话,需要一行一行操作
# 打开原文件
file_read = open("README")
# 打开目标文件
file_write = open("README[复件]", 'w')
# 读写
while True:
text = file_read.readline()
if not text:
break
file_write.write(text)
if not text:
break
# 关闭文件
file_read.close()
file_write.close()
针对文件 目录的管理操作
导入 os模块
os.rename 重命名
os.remove 删除文件

确定目录下面内容
os.list(“目录”)
例子: 查看当前目录下文件

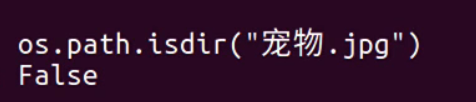
判断传入文件是否是目录
os.path.isdir(“文件名”)

创建目录
mkdir (目录名)

删除目录
rmdir(’目录名‘)

总结:

文本文件的编码格式
文本文件 本质上 是通过二进制保存的
ASCII编码 和 UNICODE编码
ASCII编码
256个字符
一个字符占1个字节
2**8个

英文26个字符,可以涵盖
但是汉字不可以
UNICODE编码
UTF-8编码: unicode的一种
使用1-6个字节,表示一个UTF-8字符,涵盖地球上所有文字
汉字 用 三个字节
小tips:
Python2 默认ASCII编码
Python3 默认 UTF-8编码
在文件第一行增加
# *-* coding:utf8 *-*
就是告诉python2.x的解释器,该文件要使用 utf8编码解释。
在python中,如何处理中文
# 引号前面的u告诉解释器,这是一个utf-8编码格式的字符串
hello_str = u"hello世界"
for c in hello_str:
print(c)















 2479
2479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









