







 本文通过获取2019年至2022年的股票交易数据,利用KDJ指标计算金死叉,并验证金叉后的市场表现。通过数据分析,提供不同时间段内的平均涨幅及分布情况。
本文通过获取2019年至2022年的股票交易数据,利用KDJ指标计算金死叉,并验证金叉后的市场表现。通过数据分析,提供不同时间段内的平均涨幅及分布情况。
目录
写在开始
疫情三年,记得2019年的春节前,以为疫情很快就会过去,3年后我还是这么认为,尽管我已经阳了。一边咳嗽,一边用哆嗦的手敲键盘。希望,未来的我,回想起来,会说,你不负韶华;劳资现在想说的是,我TM正在苦海里玩尿泥呢。
正好感觉现在是疫情的尾声,期望美好 的未来,经济形势一片大好,所以现在就是一个转个点。希望会是一片艳阳天。
书归正传,根据之前坑得只剩内裤的同志交待,他熟读KDJ、MACD、RSI、CCI、MFI等等技术指标,就是每个指标都是一个坑钱小技巧。
为了验证这些指标的靠谱度,我决定撸一把测试下,看看究竟是坑钱小技巧,还是这家伙的裤腰带太松。
先获取,在计算,最后验证。
获取股票交易信息
下载安装
方式1:pip install baostock
使用国内源安装:
pip install baostock -i https://pypi.tuna.tsinghua.edu.cn/simple/ --trusted-host pypi.tuna.tsinghua.edu.cn
方式2:访问 baostock · PyPI 下载安装
python setup.py install或pip install xxx.whl
注意:程序运行时,文件名、文件夹名不能是baostock。
获取2019年至今每日交易数据
简单讲解下,我的思路:遍历股票代码,读取每日的交易数据,因为需要经常用到这些股票日线数据,所以我存在了本地的sqlite数据库。
import sqlite3
import baostock as bs
import pandas as pd
'''
参数名称 参数描述 说明
date 交易所行情日期 格式:YYYY-MM-DD
code 证券代码 格式:sh.600000。sh:上海,sz:深圳
open 今开盘价格 精度:小数点后4位;单位:人民币元
high 最高价 精度:小数点后4位;单位:人民币元
low 最低价 精度:小数点后4位;单位:人民币元
close 今收盘价 精度:小数点后4位;单位:人民币元
preclose 昨日收盘价 精度:小数点后4位;单位:人民币元
volume 成交数量 单位:股
amount 成交金额 精度:小数点后4位;单位:人民币元
adjustflag 复权状态 不复权、前复权、后复权
turn 换手率 精度:小数点后6位;单位:%
tradestatus 交易状态 1:正常交易 0:停牌
pctChg 涨跌幅(百分比) 精度:小数点后6位
peTTM 滚动市盈率 精度:小数点后6位
psTTM 滚动市销率 精度:小数点后6位
pcfNcfTTM 滚动市现率 精度:小数点后6位
pbMRQ 市净率 精度:小数点后6位
isST 是否ST 1是,0否
'''
def 提取数据(gpdm):
#### 获取历史K线数据 ####
# 详细指标参数,参见“历史行情指标参数”章节
rs = bs.query_history_k_data_plus(gpdm,
"date,code,open,high,low,close,preclose,volume,amount,adjustflag,turn,tradestatus,pctChg,peTTM,pbMRQ,psTTM,pcfNcfTTM,isST",
start_date='2019-01-01', end_date='2022-12-23',
frequency="d", adjustflag="3") # frequency="d"取日k线,adjustflag="3"默认不复权
#### 打印结果集 ####
data_list = []
while (rs.error_code == '0') & rs.next():
# 获取一条记录,将记录合并在一起
data_list.append(rs.get_row_data())
result = pd.DataFrame(data_list, columns=rs.fields)
return result
def 获取code():
conn = sqlite3.connect(r"D:\sqlite3\2022.db")
con = conn.cursor()
conn.commit()
#stock_basic 为存储的股票信息,不考虑科创版和北交所
sql = "SELECT code FROM stock_basic WHERE type = 1 and status =1 and code " \
"NOT like 'sz.3%' and code NOT like 'sh.68%' "
df1 = pd.read_sql(sql=sql, con=conn)
conn.close()
return df1
if __name__ == '__main__':
#### 登陆系统 ####
lg = bs.login()
conn = sqlite3.connect(r"D:\sqlite3\2022.db")
con = conn.cursor()
data = pd.DataFrame()
for row in 获取code().itertuples():
# 通过getattr(row, ‘name')获取元素
code = getattr(row, 'code')
i = getattr(row,'Index')
print(i)
df= 提取数据(code)
data = pd.concat([data, df])
print(df)
data.to_sql(name='alldata', con=conn, if_exists='append', index=False)
####登出系统 ####
bs.logout()
计算KDJ的金死叉
KDJ的计算说明,来百度百科KDJ指标_百度百科
KDJ的计算比较复杂,首先要选择周期(n日、n周等),再计算当天的未成熟随机值(即RSV值),然后再计算K值、D值、J值等。
(1) RSV的计算公式为:
公式中,
C为当天的收盘价;
Ln为之前n日内的最低价;
Hn为之前n日内的最高价。
(2) 某一天的K值=2/3×前一日K值+1/3×当日RSV,即
Ki和RSVi分别表示某一天当天的K值和RSV值;
Ki-1表示前一天的K值,若无前一天的K值,则用50来代替。
(3) 某一天当天的D值=2/3×前一日D值+1/3×当日K值,即
Di和Ki分别表示当天的D值和K值;
Di-1表示前一天的D值,若无前一天的D值,则用50来代替。
(4) J值=3×当日K值-2×当日D值,即
例:手中有某只股票30日的数据,以9日为周期,想计算第9天的KDJ值,计算方法为
(1) 先计算第9天当天的RSV值:
RSV = (C−L) ÷ (H−L) × 100
公式中
C为第9天当天的收盘价;
L为从第1天到第9天这9天内的最低价;
H为从第1天到第9天这9天内的最高价。
(2) 计算第9天的K值:
K值=2/3×第8日K值+1/3×第9日RSV
第8日K值用50代替
(3) 计算第9天的D值:
D值=2/3×第8日D值+1/3×第9日K值
第8日D值用50代替
(4) 计算第9天的J值:
J值=3×第9日K值-2×第9日D值
(5) 有了第9天的K值和D值,则可以进一步计算第10天的K值、D值和J值,再用第10天的K值和D值计算出第11天的K值、D值和J值,以此类推。
KDJ 的计算代码源自:好文章 - www.baostock.com,感谢其分享
思路为:遍历股票code,计算每只股票的金死叉日期,存入本地sqlite
代码如下
import sqlite3
import pandas as pd
def 计算KDJ(code, ypj):
df_status = ypj.loc[ypj['code'] == code]
low = df_status['low'].astype(float)
del df_status['low']
df_status.insert(0, 'low', low)
high = df_status['high'].astype(float)
del df_status['high']
df_status.insert(0, 'high', high)
close = df_status['close'].astype(float)
del df_status['close']
df_status.insert(0, 'close', close)
# 计算KDJ指标,前9个数据为空
low_list = df_status['low'].rolling(window=9).min()
high_list = df_status['high'].rolling(window=9).max()
rsv = (df_status['close'] - low_list) / (high_list - low_list) * 100
df_data = pd.DataFrame()
df_data['K'] = rsv.ewm(com=2).mean()
df_data['D'] = df_data['K'].ewm(com=2).mean()
df_data['J'] = 3 * df_data['K'] - 2 * df_data['D']
df_data.index = df_status['date'].values
df_data.index.name = 'date'
# 删除空数据
df_data = df_data.dropna()
# 计算KDJ指标金叉、死叉情况
df_data['KDJ_金叉死叉'] = ''
kdj_position = df_data['K'] > df_data['D']
df_data.loc[kdj_position[(kdj_position == True) &
(kdj_position.shift() == False)].index, 'KDJ_金叉死叉'] = '金叉'
df_data.loc[kdj_position[(kdj_position == False) &
(kdj_position.shift() == True)].index, 'KDJ_金叉死叉'] = '死叉'
# df_data.plot(title='KDJ')
df_data['code'] = code
df_data = df_data[(df_data['KDJ_金叉死叉'] == '金叉')]
# plt.show()
return (df_data)
def 写入数据库验证(name, df):
conn = sqlite3.connect(r"D:\sqlite3\2022.db")
con = conn.cursor()
df.to_sql(name=name, con=conn, if_exists='replace')
# 关闭链接
conn.close()
def 遍历code():
# 连接数据库
conn = sqlite3.connect(r"D:\sqlite3\2022.db")
con = conn.cursor()
conn.commit()
# 获取数据库的股票日线
data_sql = "select date,code,open,close,low,high,volume from alldata " \
"where date >'2020-01-01' and tradestatus = 1 ORDER BY date"
data_df = pd.read_sql(sql=data_sql, con=conn, coerce_float=True)
# 获取数据库的股票代码
code_sql = "SELECT code FROM stock_basic WHERE type = 1 and status =1 and code " \
"NOT like 'sz.3%' and code NOT like 'sh.68%' "
code_df = pd.read_sql(sql=code_sql, con=conn)
datay = pd.DataFrame()
for row in code_df.itertuples():
# 通过getattr(row, ‘name')获取元素
code = getattr(row, 'code')
i = getattr(row, 'Index')
print(i)
datay = pd.concat([datay, 计算KDJ(code, data_df)])
写入数据库验证('KDj', datay)
if __name__ == '__main__':
遍历code()
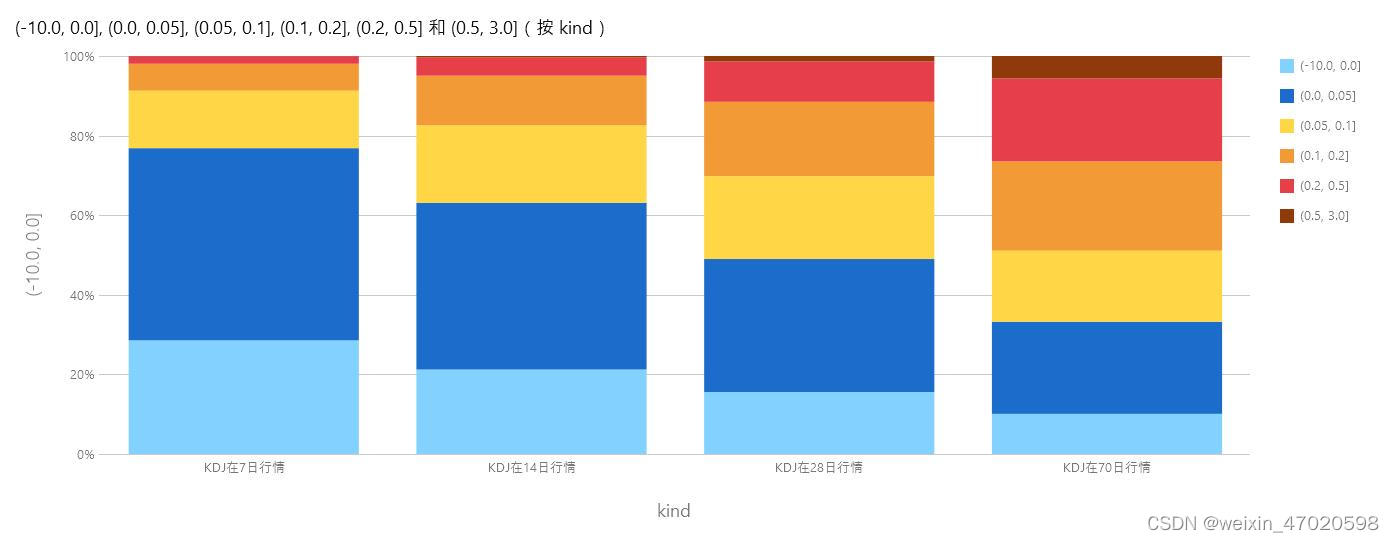
验证KDJ金叉后7天、14天、28天、70天、90天的行情
根据KDJ的日期及股票代码,获取其金叉日期后7-90天的最高收盘价格,然后 求出平均涨幅,再根据涨幅区间[-10, 0, 0.05, 0.1, 0.2, 0.5, 3],进行拆箱,统计相应涨幅的所占权重。
后附验证结果。
# 链接数据库
import sqlite3
import pandas as pd
def main(yzh_kind,days):
conn = sqlite3.connect(r"D:\sqlite3\2022.db")
con = conn.cursor()
sql = "SELECT a.code,a.date ksrq,date( a.date, '+{} days' ) jsrq," \
"b.date today,a.close close_min,b.close FROM 验证 a,alldata b " \
"WHERE a.code = b.code AND b.date > a.date AND b.date <= jsrq".format(str(days))
data = pd.read_sql(sql=sql, con=conn)
data['涨幅'] = round(((data['close'].astype("float") / data['close_min'].astype("float")) - 1), 3)
max1 = pd.DataFrame(data.groupby(['code', 'ksrq', 'close_min'], as_index=False)['涨幅'].max())#聚合求涨幅
#data.to_csv(str(days) + 'ererere.csv',encoding='gbk')
# 分箱
xz = [-10, 0, 0.05, 0.1, 0.2, 0.5, 3]
gl = pd.cut(max1['涨幅'], xz)
aa = pd.value_counts(gl)
zb = (100 * aa / aa.sum()).round(2)
df = pd.DataFrame([aa, zb])
df['kind'] = yzh_kind
df.set_axis(['数量','幅度_%'],axis = 0,inplace=True)
df['days'] = days
df['平均涨幅_%']= round(max1['涨幅'].astype("float") .mean(axis=0)*100,2)
pd.set_option('display.max_columns',None)
print(df)
print(20 * "-·-·")
df.to_sql(name='验证结果', con=conn, if_exists='append', index=True)
conn.close()
return df
if __name__ == '__main__':
for days in (7,14,28,70,98):
print("{}天内行情如下:".format(str(days)))
yanzheng_kind = 'KDJ 在{}日行情'.format(str(days))
main(yanzheng_kind,days)
#close_min2年至今最低值的3%以内、3天内连涨、在14日内的行情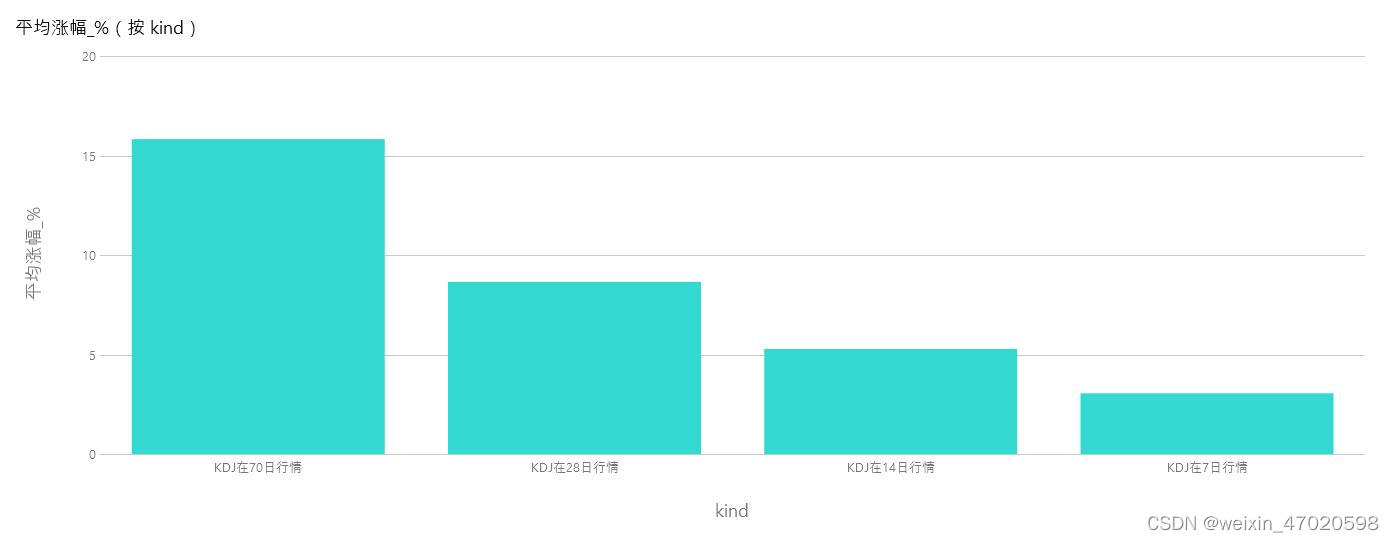


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









