






1.单例模式双重检查 代码 DCL单例 double check lock
面试题:需不需要加volatile(另外一重检查) :需要
public class xx{
private static volatile xx INSTANCE; // jit just in time ,votatile是什么??
private xx(){
}
ConcurrentHashMap chm=null;
public static xx getInstance(){
if(INSTANCE == null){//在多线程的情况下判断这个对象是否存在
synchronized(xx.class){ //加锁防止在其他线程初始化
if(INSTANCE==null){//再次检查,以防加锁期间有其他线程 初始化
try{
Tread.sleep(1);
}catch(InterruptedException e){
e.printStackTrace();
}
INSTANCE=new xx(); //因为参数化过程可能出现问题,可能出现半初始化的问题,导致始终不能new一个对象(因为不为null)
///,可能会发生指令重排的情况
}
}
}
}
}
//在Method是的main的Code 普通的new的指令 T t=new T();
new #2<top/jamsee/T> //申请内存
dup //
invokespecial #1 调用构造方法
astore_1 #赋值给t,可能先执行
return
//在 volatile T t= newT();
2.JMM(java memory model)硬件层数据一致
硬件层的并发优化基础知识
1.存储器的层次结构(深入理解计算机系统第三版p421)
L3在主板上, cpu内部 L0寄存器 L1 L2高速缓存
图 jvm13
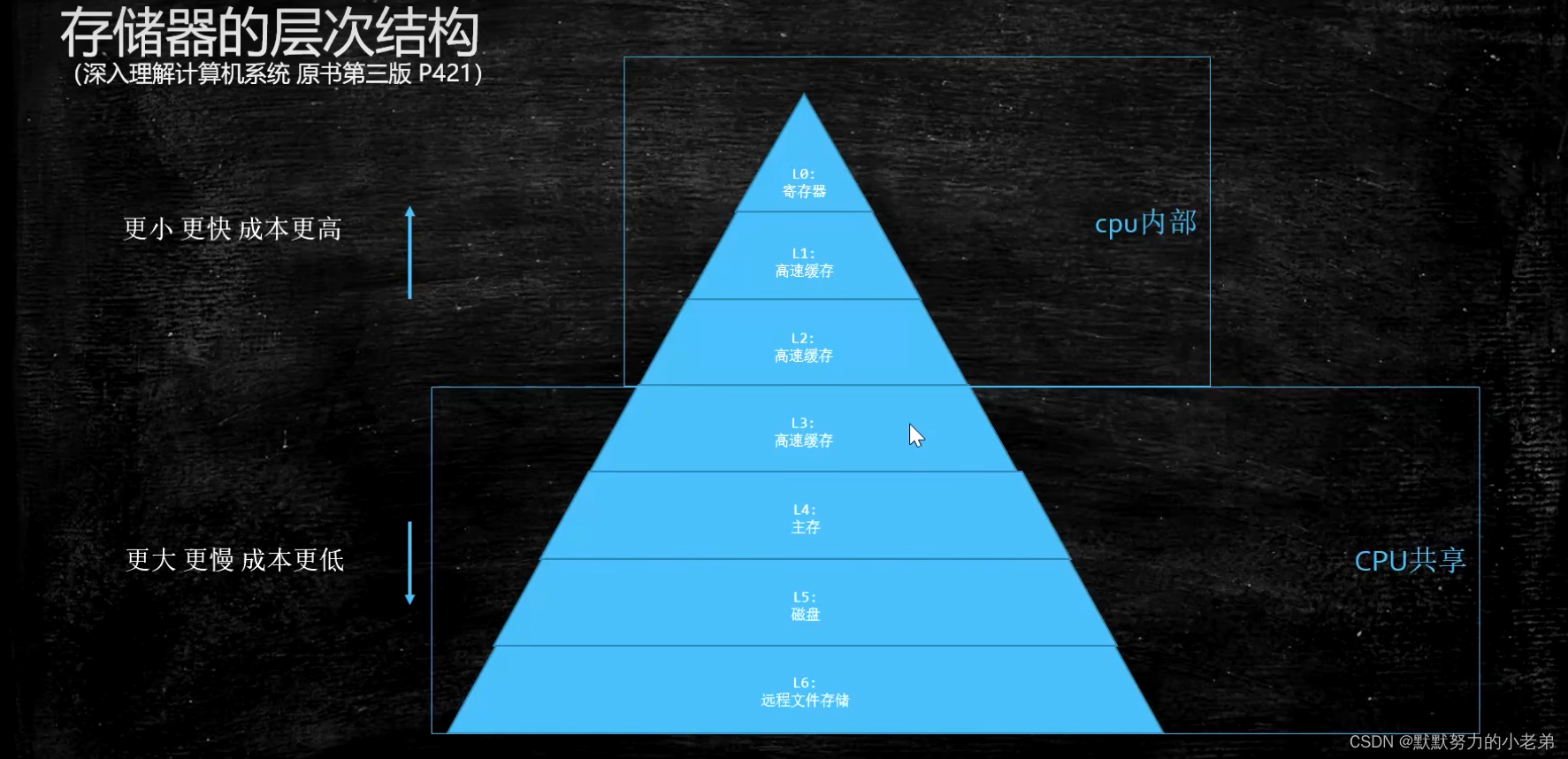
2. 数据存储的过程: 在硬盘里就读12这个数,如果速度慢就在L1里面找这个数,没有就在L2找Load到L1,一层一层往下找
,不断往上放,
图jvm14 纳秒(10亿分之一秒)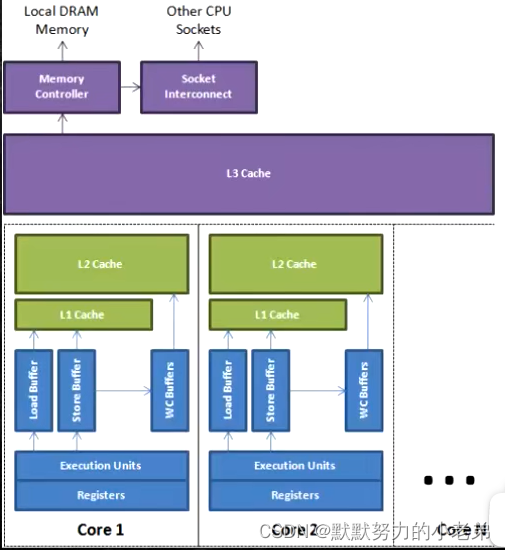
3.由于 主存load数据到cpu会load到不同的cpu内部 如 memory-->L1 memory-->L2 导致cpu内部数据不一致
4.解决方案
1.把bus总线锁住,老的cpu怎么做,cpu访问外部L3和memory不方便需要等待
2.多种数据一致性协议 主要Intel英特尔的MESI Cache一致性协议
缓存锁,有些无法被缓存的数据和跨越多个缓存的数据,还要使用总线锁
有四种状态(2bit标记) Modified被修改过了 改过,
Exclusive 独享的,cpu内只有这个值
Shared 共享的,我读别人也可以读
Invalid 无效的 modified我改过数据--->其他数据就失效了,如果我要就是这个数据,我再去内存读就变成有效状态了
文章: https://www.cnblogs.com/z00377750/p/9180644.html
现代cpu数据一致性=缓存锁+总线锁
//伪共享
public class T01_CacheLinePadding {
private static class T {
public volatile long x = 0L;
}
public static T[] arr = new T[2];
// 两个数组紧挨着的
static {
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
for (int i = 0; i < 1000_0000L; i++) {
arr[0].x = i;
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 1000_0000L; i++) {
arr[1].x = i;
}
});
final long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime() - start) / 100_0000);
}
}
//填充了缓存行
public class T02_CacheLinePadding {
private static class Padding{
public volatile long p1, p2, p3, p4, p5, p6, p7;
}
// Padding有56个字节数据 T有8个字节数据, 所以两个线程的X不会在一个缓存行中,即使加了volatile,效率也会大大提高
// 两个线程的x不会相互影响
private static class T extends Padding{
public volatile long x = 0L;
}
public static T[] arr = new T[2];
static {
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args) throws InterruptedException {
System.out.println(ClassLayout.parseInstance(arr[0]).toPrintable());
Thread t1 = new Thread(() -> {
for (int i = 0; i < 1000_0000L; i++) {
arr[0].x = i;
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 1000_0000L; i++) {
arr[1].x = i;
}
});
final long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime() - start) / 100_0000);
}
}
2.(面试) cache line 缓存行 读取以这个为基本单位 64bytes 512bits
位于统一缓存行的两个不同数据,被两个不同cpu锁定,产生相互影响的伪共享问题
(缓存行有2个数据,但是我们读的时候读一个数据,一旦锁定这个数据,整个缓存行锁定,导致每次数据invalid要重新到内存读,2个cpu变成了独立关系)
(缓存行多个数据一个修改,导致全部失效,需要重新加载)
//代码证明, 读取整个块效率高,但是导致伪共享问题
//Long的1000万怎么写 1000_0000L ,_是为了好看 1.8之后允许
//public long p1,p2,p3,p4,p5,p6,p7 进行缓存行的填充,可以提高效率
private volatile long cursor=xxx;
private long p8,p9,p10,p11,p12,p13,p14,保证一个缓存行不与其他数据混合在一起,discruptor开源项目里面有使用
3.乱序问题(当我们执行指令的时候其他指令可以同时运行) 类似于多线程
1.cpu的速度是内存的100倍,如果第一个指令执行到内存取数据的操作,那么cpu需要等100倍的时间返回数据
2. 为了优化 可以如果数据访问不冲突,可以执行下一条指令
3.数据返回cpu
//其实寄存器与L1之间有个 WCBuffer writeCombining 合并写
图jvm14,写操作也可以是合并(就是cpu内存速度不匹配,cpu写入数据,内存还没有数据写入完成,cpu处理内存 其他指令,合并一起回内存)
//wcbuffer有4个位置 必须填满 4个位才处理, 我们每次填4个 比 6个分为4个wc和2个L2 效率要高
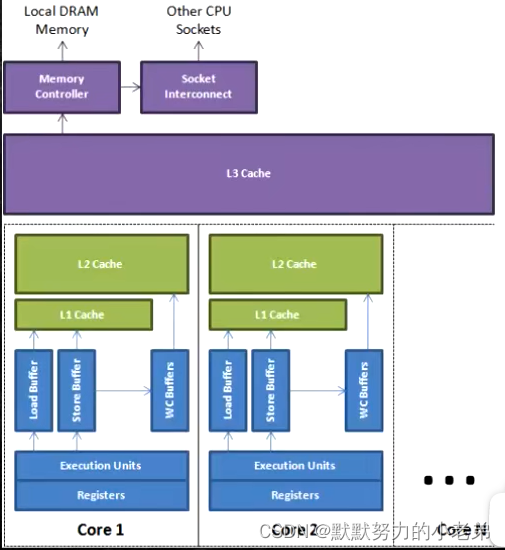
4.证明指令乱序代码
1.线程可能卡住等待
2. 如果顺序执行,那么不可能出现0 0 第27万才出现...非常小几率的重排
public class T04_Disorder {
private static int x = 0, y = 0;
private static int a = 0, b =0;
public static void main(String[] args) throws InterruptedException {
int i = 0;
for(;;) {
i++;
x = 0; y = 0;
a = 0; b = 0;
Thread one = new Thread(new Runnable() {
public void run() {
//由于线程one先启动,下面这句话让它等一等线程two. 读着可根据自己电脑的实际性能适当调整等待时间.
shortWait(100000);
a = 1;
x = b;
}
});
Thread other = new Thread(new Runnable() {
public void run() {
b = 1;
y = a;
}
});
one.start();other.start();
one.join();other.join();
String result = "第" + i + "次 (" + x + "," + y + ")";
if(x == 0 && y == 0) {
System.err.println(result);
break;
} else {
//System.out.println(result);
}
}
}
public static void shortWait(long interval){
long start = System.nanoTime();
long end;
do{
end = System.nanoTime();
}while(start + interval >= end);
}
}
5.如何保证有序? 硬件级保证有序
1.cpu内存屏障(主要intel) 硬件上
(save)sfense: 前面的写指令,必须在后面的写指令前写完
loadfense: 读 如上
mfence: sfense+loadfense 读写都有序
2.jvm的汇编 屏障 java实现的 lock指令
6.面试题
1. (美团7连问)Object object=new Object(); 创建过程?
//会发生半初始化的情况
java源代码:
class T{
int m=8;
}
T t=new T();
jvm汇编代码:
new #2 <T> #为T这个指向的引用 开辟空间
dup
invokespecial #3 <T.<init>> #特殊调用 构造方法
astore_1 #小t指向new出来这个大T的对象
2.加问 DCL单例(Double Check Lock)到底需不需要volatile?
答:需要,必须要,可能发生指令重排序,jvm规定happens-before规定8种规则之外可以重排序
volatile是什么? 1.线程间可见 2.禁止重排序(内存慢cpu快,两个独立的语句,cpu为了优化,顺序会倒着指向)
什么是单例? 一个类在内存只能new出一个对象
//饿汉式 直接上来就new,占大量cpu资源和内存资源,不管之前有没有创建对象,先干
//线程不安全,线程之间数据不同步(sleep后会创建不同的对象) class必须加锁(力度太大了) 业务代码加锁(不行,又不是安全的)
//使用dcl (线程不用先抢锁,提高效率)上锁前后判断对象是否非空(有点像CAS 锁compare and set or swap 比较并交换,自旋锁,乐观锁, 两次判断,先取出来改值,改后比较他是否为原来的值,是就交换,不是就把被改的值,拿出来改后回来)
// CAS A-B-A问题(增加版本号解决) 就是 多个线程改值,导致把值改回来,你女朋友与你分手复合了还是你女朋友,但是你不知道她经历了多少个男朋友
3.对象在内存中的存储布局(大厂markword,小厂知道4部分)
答: 全部有4部分64字节,object header包括markword(8个字节),class pointer(类型指针 是什么类型的对象如T.class,String.class 正常4个字节 不正常8个字节)
instance data (小t T t=new T()) padding 对齐(补齐8个字节效率高,成块)
看见这4个信息怎么看导入依赖 jol-core
Object o=new Object();
String s=ClassLayout.parseInstance(o).toPrintable();
sout();
4.对象头包括什么?(要了解复习计算机组成原理)
1.markword 包括锁信息 gc信息 identityHashCode(可识别的hashcode)
在代码加 synchronize(o){} 看变化, -->锁可以锁类也可以锁局部变量
//为什么32g时压缩指针会变为8位的而不是4位的,与总线的宽度(偷工减料)有关,总线包括数据总线,地址总线(64位,但是寻不了那么高地址,超过32g寻址不到),控制总线
- 对象怎么定位?
1.直接指针(Hotspot使用直接指针 t--堆-> m=0 类型数据指针--方法区--->T.class)
2.间接指针t--堆->实例数据指针(堆) -->m=0;(初始化数据)
类型数据指针(堆)--(方法区)->T.class
6.对象怎么分配?
start-->new对象()----?Y如果可以分配到栈---->栈(为什么不是到堆?,没有逃逸的对象可以放堆中,效率很高)
------?N太大并放逃逸--->老年代
(栈帧:包括 main方法 方法m1 方法m2 ,不需要gc介入,效率高,所以jvm的XSS参数可以调最大栈大小,提升效率)
(逃逸对象: 下面是栈结构,m1有个指针指m2,如果m2 pop() 那么m1指针失效,就叫逃逸对象[对象之间不能有逃了对象,丢数据的现象])(对象之间不能有依赖关系)
(TLAB:Thread Local Allocation Buffer,就是在eden区,为了线程之间资源不相互抢占,直接给线程在eden里面分配属于他自己的空间,)
|m2 |
|m1 |
|m |
//servival1后面到g1 zgc就不适用了
如图jvm15
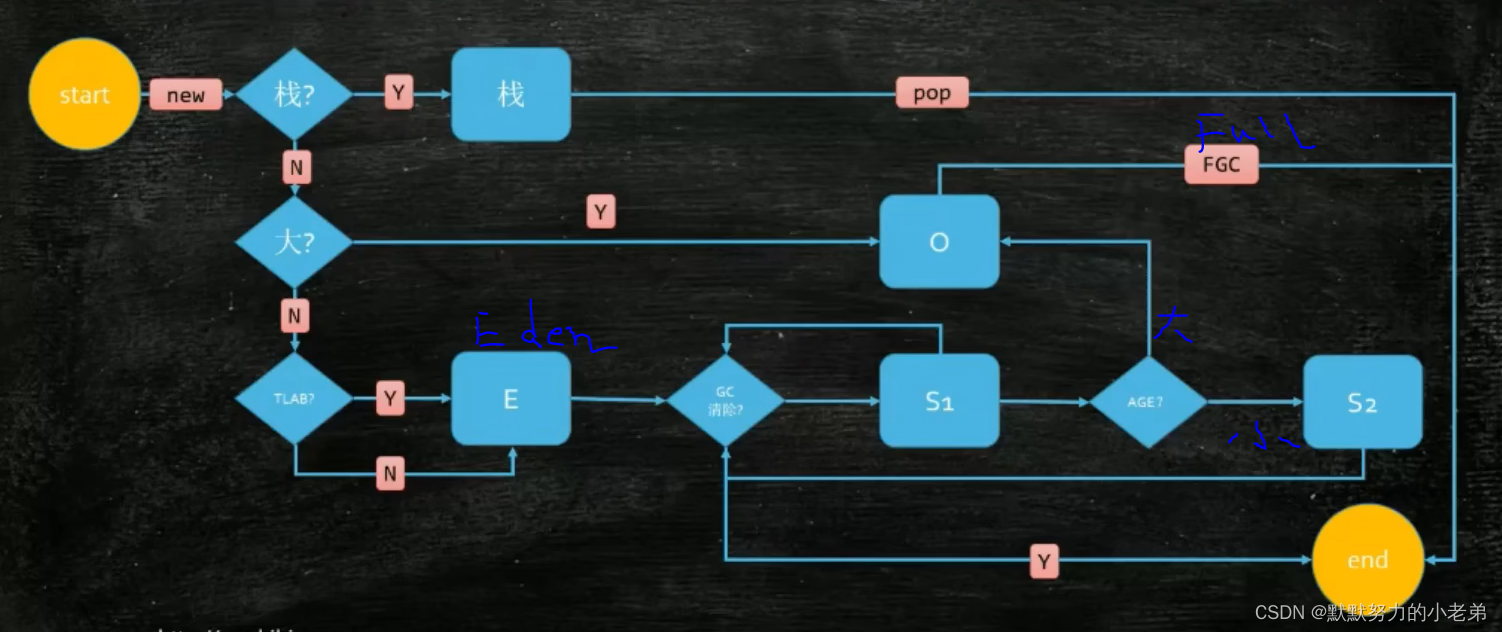
7.Object o=new Object();一个Object占多少字节? 16个字节=markword8个
class pointer4个+对齐4个
8.新问题 为什么hotspot不使用c++对象代表java对象?
答:hospot使用oop/class二元模型(new的对象,和class对象)
c++使用虚函数表(就是他的对象还有其他附加的信息),占空间大.
9.新问题 Class对象在堆还是在方法区?
答: 和版本有关系, method area包括Perm generation jdk1.7和jdk1.8 Meta space
jdk1.8 小o对象指向堆的对象堆指向 方法区--指回堆->O.class(其实在堆里面的,间接经过方法区)
class对象放在堆中,方便反射,放在方法区也是为了底层c++调用,如OOM异常
7.相关数据推荐
1.先建立知识体系
2.后揪细节
8.冯诺依曼体系QQ.exe执行的流程 在计算机内部
图jvm16
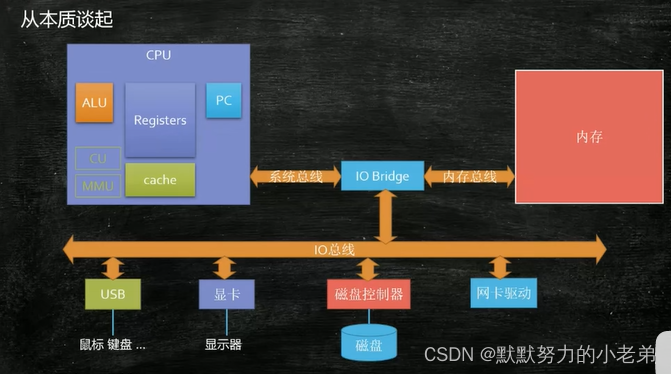
点击QQ.exe
QQ.exe会从磁盘通过io总线加载到内存(其中会形成计算机指令和数据)
<—>到cpu执行
9.内存中的栈(栈帧 stack frame)每个线程一个
1.过程
main{
Object o=new Object();
m();
}
//会生成方法的调用路径,m()方法也会生成一个栈帧
//栈小o调用堆的对象
| m() |
| main(o对象)|
//堆
| Object |
2.栈与堆的区别,(调用后pop出去)栈是自动释放内存的,堆需要gc回收
10.程序最难调试的bug
1.野指针(同一个对象,有两个指针指向,一个释放了,另外一个不知道是否使用)
(同一指针,不同位置)
(不在指向任何对象的指针)java的 NullPointerException
图jvm17 这个对象被其他修改,另外一个可能出问题
java py go..语言不用手动去管理gc(内存指针)
c++手动管理,忘记释放 memory leak内存泄漏,过多内存溢出 out of memory(开发效率低,运行效率高)
释放多次,(把别人来的数据free掉),一个线程空间莫名其妙的被删除
java: garbage collector java 还是没有解决空指针的问题 如 o.name(); o可能不存在
go: 也有垃圾回收卡顿的问题
rust: 1.运行效率超高(对表asm汇编 c c++) 不用手工管理内存(没有gc) 但是学习难
2.ownership所有权 栈的对象只对应堆一个对象,(一夫一妻制,指针消失,对象消失)
3.写不出bug ,每个值有对应的所有者
kotlin :运行在jvm上
scala:
图jvm17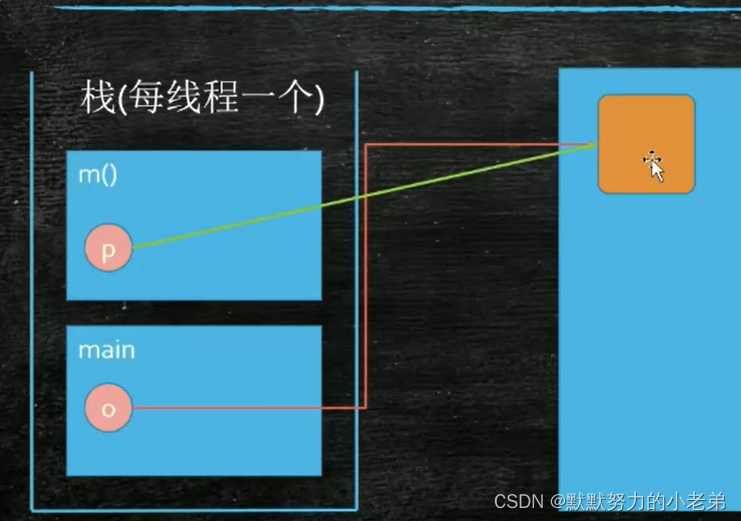
2.并发问题()
11.什么是垃圾?怎么找垃圾
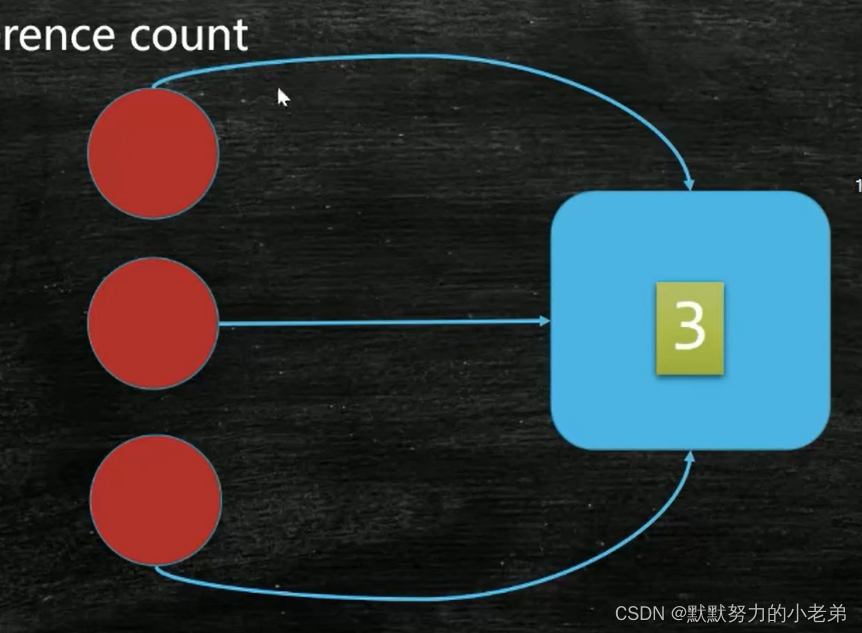
1. reference count引用计数,py使用这个,就是全部对象使用我的次数
一个对象如果计数为0 就是垃圾
如图jvm18 19
//缺点,对象有间接引用,就是一坨垃圾,却清理不了
jvm20

2.root searching 根可达算法 在main方法开始搜索,找不到的是垃圾
jvm21
1.(大厂面试题)学习方法:要建立知识体系(大概的知识点)到(树叶,细节)
//看jvmspefication规范
线程栈变量 静态变量 常量池 JNI指针
例如 Object o=new Object();
// o放在栈就是根
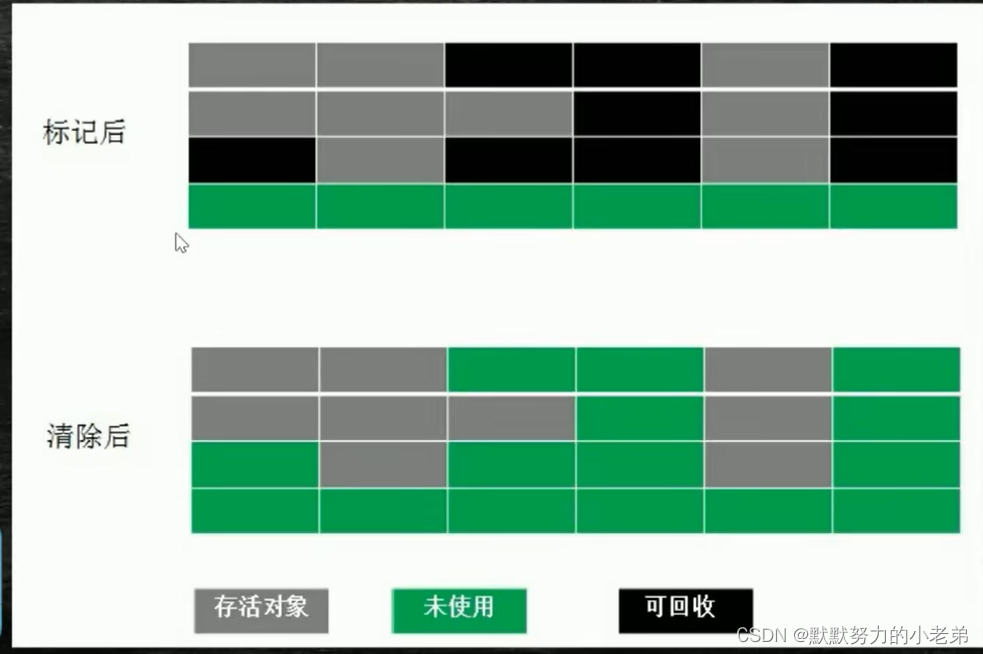
2. 常见垃圾回收(分代)算法(三种综合运用,新生代(清除90%对象 minor gc)用copy,sur1,sur2用拷贝,用来统计年龄,老年代使用标志清除或压缩)
老年代满了就Fullgc,(!!!不是永久代 Permanent area 是在方法区的,放jvm运行的环境的)
1.mark-sweep 标记清除 打上标记是黑色就清除 碎片化严重
图jvm22
2.copying 复制后把垃圾整理成连续的空间 浪费内存
3.mark-compact标准压缩 在原来的内存压缩成连续的内存,在三种之中效率最低
12.10种垃圾回收器(面试可用) !!随着内存大小不断增长而发展
图jvm23,凡是虚线,都可以相互配合使用
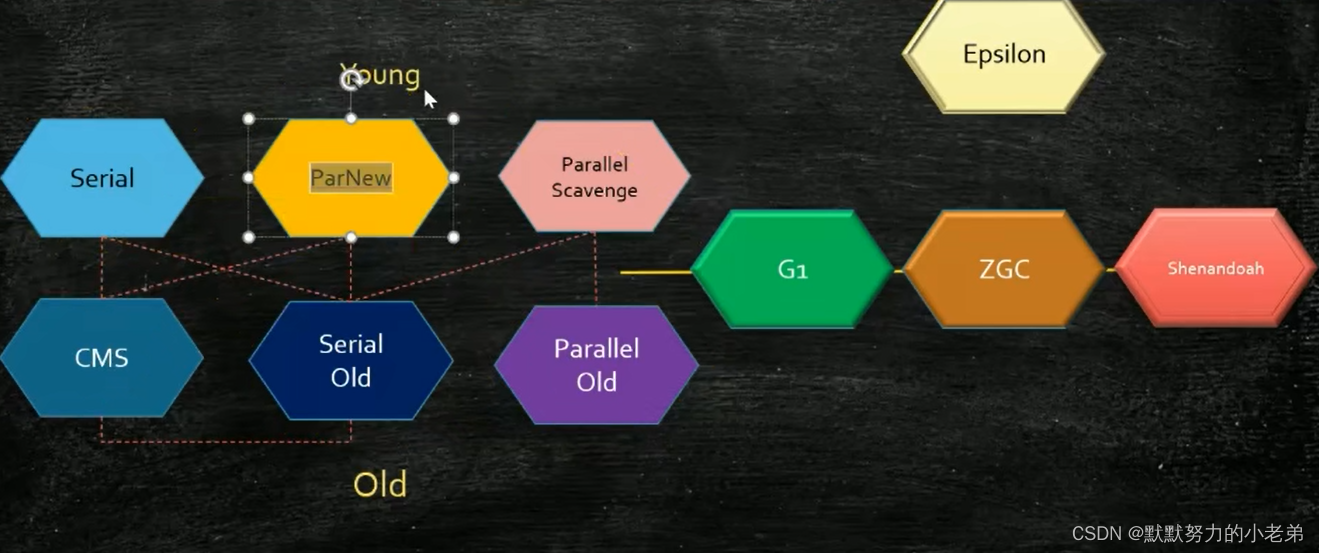
1.serial 在年轻代 STW stop-the-world 业务停止,垃圾清理开始,使用单线程 copying算法
几兆-几十兆
2.serial old 使用标记清除算法使用单线程
3.parallel scavenge 在年轻代 多线程 你妈妈一个人扫半个小时垃圾,之前2分钟
几十兆-上百兆1G,
4.parallel old 在老年代 ps+po(jdk1.8使用,默认垃圾回收器)
java -XX:+PrintCommandLineFlags -version #可以查看默认的垃圾回收器,-XX:+UseParalleGC
5. concurrent gc(并发,同时可以使用,gc线程和业务线程同时使用)包括了 parNew,cms,g1,zgc,shenandoah 5种垃圾回收器
几十G,
问题:是不是线程效率是不是会提高? 错误,线程到一定程度会慢,例如 1w个线程 但是cpu只有8核,线程切换的资源>线程运行的资源
问题: 1.我们不小心把他变成垃圾,我们要使用的,但是被垃圾回收器提前回收,
1.cms 在老年代
2. 而parNew在年轻代,与cms配合使用
stop-of-world 与parllel scavenge的区别,parNew专门和cms配合使用
13.定位jvm问题的参数设置
jstat -gc 1180 500#进程号每500№观察一次gc的信息,jdk自带,阿里阿尔萨斯替代
jstack #查看java栈调用情况,如果线程waiting on condition某一把锁就会产生死锁的情况
#(面试)如果jvmcpu满了查看怎么办
top #先查看哪个查询占得高
top -Hp #列出所有进程,查看哪个进程 占用高
jstack #进程占用与jstack(VMGC出问题[双11,内存回收不了,内存泄漏,查看gc日志],还是业务的代码有什么方法)进程信息 对比
#gc日志 19995k(回收前)--->19990(回收后)k(199916k全部内存大小)
#!!!(面试) full gc怎么知道 垃圾回收不了, normal: 2000k-->1000k,error:2000k-->2000k
#怎么打开gc日志
java -Xms200M -Xmx200M --XX: +PrintGC top.jamsee.xxclassName
#类信息分析 bug(heap信息), 但是jmap不可以在生产环境使用,我是在测试环境查看的,会让jvm停顿,半夜执行也不行,可能问题没有出来,测试环境压力测试时执行,在备份机执行
jmap -histo xx进程号 |head -20# jps, [I [B是数组一般不会有问题,可以不断看看哪个类是不断产生的
#还可以dump出来分析,堆转储文件
jmap -dump:format=b,file=xxx.hprof 11988 #进程号 ,=b是二进制文件,后缀名无所谓
#到 java visual vm导入, 抽样:内存 -->看哪个占用多,在 jdk的bin目录有 exe,也可以远程观察,但是生产环境不使用dump,怎么拿到文件
#常用的还是 oom错误后自动生成文件
java -Xms200M -Xmx200M -XX:-PrintGC top.jamsee.aa
#远程连接,必须开另外端口,性能减低10%-20%,1.压测环境压测连接 2.负载均衡取一条机器来分析 3.使用 tcpcopying打到生产环境和测试环境 nb...
#(经常使用)基本arthas可以替代几乎上面大多数命令 ,性能减得不多 10%-15%
1. 选择进程打1
2. help查看 dashboard最常用 #第一个列表查看 进程的占用状态,第二个查看内存可以看新生代老年代
heapdump #替代jmap
thread -h #查看进程 ,这个是帮助可以用直接用 例子
thread -b#查看死锁,!!!好用 blocking thread
jvm #查看jvm默认参数,gc 年轻代 老年代 tenured gen,使用说明垃圾回收器
jad #比较nb 的命令 !!!可以专门追踪方法的调用过程
trace ABC a # ABC类的a方法,a方法调用b方法,sleep 1秒,但是b执行了5秒
trace ABC b #说明b方法有问题
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









