







文章目录
主要进行一些框架小知识的概述~
Spring
控制反转就是依赖倒置原则的一种代码设计的思路。具体采用的方法就是所谓的依赖注入。
Spring的优势

Spring事务管理的隔离级别以及传播特性(TODO)
隔离级别

传播机制:
Spring的API设计很不错,基本上根据英文翻译就能知道作用:
Required:必须的。说明必须要有事物,没有就新建事物。
supports:支持。说明仅仅是支持事务,没有事务就非事务方式执行。
mandatory:强制的。说明一定要有事务,没有事务就抛出异常。
required_new:必须新建事物。如果当前存在事物就挂起。
not_supported:不支持事物,如果存在事物就挂起。
never:绝不有事务。如果存在事物就抛出异常


Spring事务失效场景
比如第3点,一般是一个类的方法调用另一个类的方法,如果同一个类中方法的调用,不会走AOP代理的过程的,事务配置就不会生效。

Spring框架中的单例bean是线程安全的吗

Spring框架中使用了哪些设计模式以及应用场景

Spring中提供配置元数据的方法
常用的3中配置元数据的方法:基于Java、基于注解(annotation)、基于xml(常用)。
在Java中一个类每个属性都具有set和get方法,就认为这个Java对象是个Bean。
而在一个项目中,有那么多的类,是如何知道Bean的呢?这就需要引入Spring的配置元数据概念:向Spring容器提供相关信息,以便实例化Bean,并指定如何对这些Bean进行装配。所提供的信息称为配置元数据(configuration metadata)。
亦及Bean初始化时所需要的配置参数
Bean后置处理器的用法:实现BeanPostProcessor接口:
postProcessBeforeInitialization() 该方法在注入的Bean的init方法执行前执行
postProcessAfterInitialization() 该方法在注入的Bean的init方法执行后执行
解决循环依赖
Java中的循环依赖分两种,一种是构造器的循环依赖,另一种是属性的循环依赖。
构造器的循环依赖就是在构造器中有属性循环依赖,这种循环依赖没有什么解决办法,因为JVM虚拟机在对类进行实例化的时候,需先实例化构造器的参数,而由于循环引用这个参数无法提前实例化,故只能抛出错误。
Spring解决的循环依赖就是指属性的循环依赖。
一句话:Spring通过将实例化后的对象提前暴露给Spring容器中的singletonFactories,解决了循环依赖的问题。
对于循环依赖的场景,构造器注入和prototype类型的属性注入都会初始化Bean失败。因为@Service默认是单例的,所以单例的属性注入是可以成功的。
参考链接
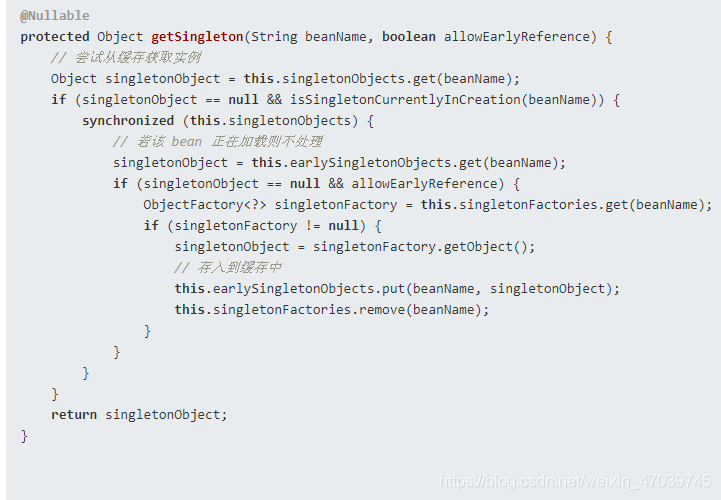
spring解决这个循环依赖问题主要靠巧妙的三层缓存,所谓的缓存主要是指这三个map,singletonObjects主要存放的是单例对象,属于第一级缓存;singletonFactories属于单例工厂对象,属于第三级缓存;earlySingletonObjects属于第二级缓存,如何理解early这个标识呢?它表示只是经过了实例化尚未初始化的对象。Spring首先从singletonObjects(一级缓存)中尝试获取,如果获取不到并且对象在创建中,则尝试从earlySingletonObjects(二级缓存)中获取,如果还是获取不到并且允许从singletonFactories通过getObject获取,则通过singletonFactory.getObject()(三级缓存)获取。如果获取到了则移除对应的singletonFactory,将singletonObject放入到earlySingletonObjects,其实就是将三级缓存提升到二级缓存,这个就是缓存升级。spring在进行对象创建的时候,会依次从一级、二级、三级缓存中寻找对象,如果找到直接返回。由于是初次创建,只能从第三级缓存中找到(实例化阶段放入进去的),创建完实例,然后将缓存放到第一级缓存中。下次循环依赖的再直接从一级缓存中就可以拿到实例对象了。

Spring Bean的生命周期
Spring Bean的生命周期简单分为四个阶段和多个扩展点。扩展点又可以分为影响多个Bean和影响单个Bean。整理如下:
1、四个阶段
实例化 Instantiation( AbstractAutowireCapableBeanFactory.doCreateBean中会调用createBeanInstance()方法)
属性赋值 Populate
初始化 Initialization
销毁 Destruction
spring的BeanPostProcessor处理器:spring的另一个强大之处就是允许开发者自定义扩展bean的初始化过程,最主要的实现思路就是通过BeanPostProcessor来实现的,spring有各种前置和后置处理器,这些处理器渗透在bean创建的前前后后,穿插在spring生命周期的各个阶段
BeanPostProcessor
InstantiationAwareBeanPostProcessor
这两个可能是Spring扩展中最重要的两个接口!InstantiationAwareBeanPostProcessor作用于实例化阶段的前后,BeanPostProcessor作用于初始化阶段的前后。正好和第一、第三个生命周期阶段对应。
InstantiationAwareBeanPostProcessor实际上继承了BeanPostProcessor接口
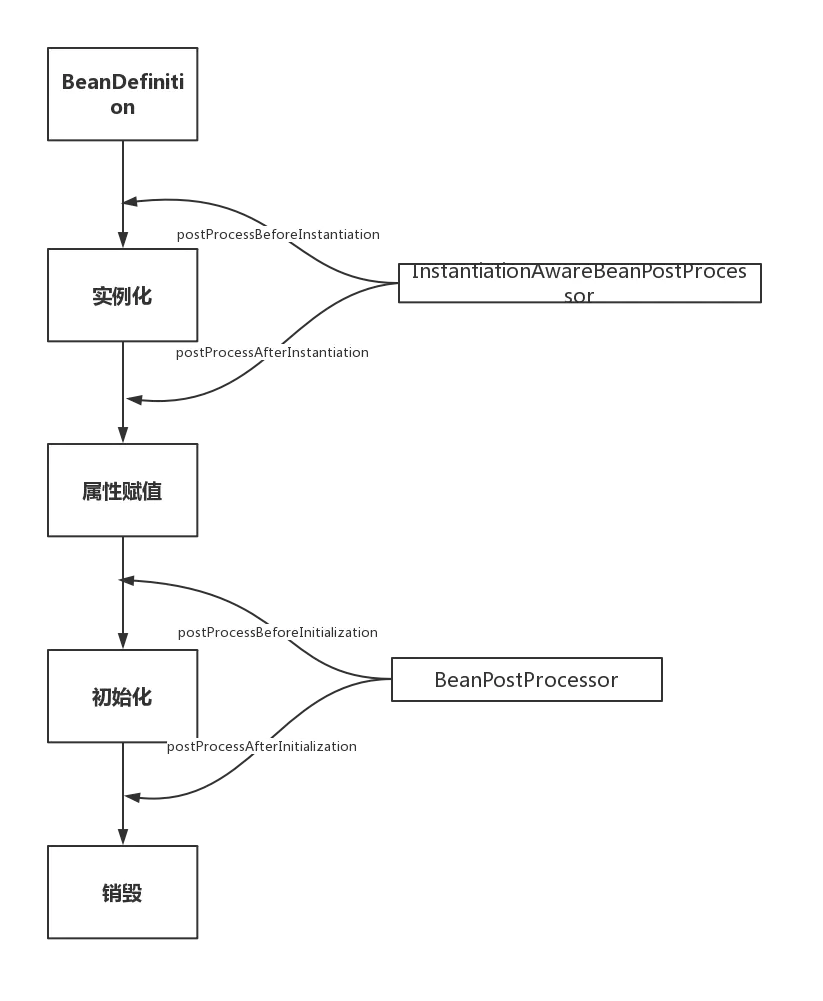
(上图来源https://www.jianshu.com/p/1dec08d290c1)
2、多个扩展点
影响多个Bean
BeanPostProcessor
InstantiationAwareBeanPostProcessor
影响单个Bean
Aware
Aware Group1
BeanNameAware
BeanClassLoaderAware
BeanFactoryAware
Aware Group2
EnvironmentAware
EmbeddedValueResolverAware
ApplicationContextAware(ResourceLoaderAware\ApplicationEventPublisherAware\MessageSourceAware)
生命周期
InitializingBean
DisposableBean
AOP
AOP(Aspect Orient Programming),一般称为面向切面编程,作为面向对象的一种补充,用于处理系统中分布于各个模块的横切关注点,比如事务管理、日志、缓存等等。AOP实现的关键在于AOP框架自动创建的AOP代理,AOP代理主要分为静态代理和动态代理,静态代理的代表为AspectJ;而动态代理则以Spring AOP为代表。静态代理是编译期实现,动态代理是运行期实现,可想而知前者拥有更好的性能。
Spring AOP的两种代理实现机制,JDK动态代理和CGLIB动态代理。
静态代理是编译阶段生成AOP代理类,也就是说生成的字节码就织入了增强后的AOP对象;动态代理则不会修改字节码,而是在内存中临时生成一个AOP对象,这个AOP对象包含了目标对象的全部方法,并且在特定的切点做了增强处理,并回调原对象的方法。
Spring AOP面向切面编程
- Spring AOP的动态代理主要有两种方式实现,JDK动态代理和cglib动态代理。
- JDK动态代理通过反射来接收被代理的类,但是被代理的类必须实现接口,核心是InvocationHandler和Proxy类。
- cglib动态代理的类一般是没有实现接口的类,cglib是一个代码生成的类库,可以在运行时动态生成某个类的子类,所以,CGLIB是通过继承的方式做的动态代理,因此如果某个类被标记为final,那么它是无法使用CGLIB做动态代理的。
SpringMVC运行流程
前端先将请求发送给DispatcherServlet;
DispatcherServlet查询一个或者多个HanderMapping,找到处理请求的controller;
DispatcherServlet再把请求提交到对应的controller;
controller进行业务逻辑处理之后,会返回一个ModelAndView;
Dispatcher查询一个或者多个ViewResolver视图解析器,找到ModelAndView对象指定的视图对象;
视图对象负责渲染返回给客户端。
Mybatis
查询
不可查询数据表中没有的字段,否则会报错!!
分页插件
PageHelper中startPage开启分页方法只对后面的sql查询起作用。
#{}和${}
1.#将传入的数据都当成一个字符串,会对自动传入的数据加一个双引号,#{}表示一个占位符号,通过#{} 可以实现预编译阶段在使用jdbc时的preparedStatement,sql语句中如果存在参数则会使用?作占位符。如:order by #user_id#,如果传入的值是111,那么解析成sql时的值为order by “111”, 如果传入的值是id,则解析成的sql为order by “id”,显然无用。
2.$将传入的数据直接显示生成在sql中,不会当做字符串处理,是什么就是什么。如:order by $user_id $, 如果传入的值是111,那么解析成sql时的值为order by 111, 如果传入的值是id,则解析成的sql为order by id.
3. #方式能够很大程度防止sql注入。
4. $ 方式无法防止Sql注入。
5. $ 方式一般用于传入数据库对象,例如传入表名.
6.一般能用#的就别用$.
xml中sql语句中in的写法
在XML中主要使用foreach标签
传入的参数必须为collection类型的,List 、Map,如果在地址栏接收到的是字符串,那需要转为collection类型
foreach的结果为:(23,46,75,43) 这种形式
foreach元素的属性主要有 item,index,collection,open,separator,close。
<foreach item="item" collection="listTag" index="index" open="(" separator="," close=")">
#{item}
</foreach>
# item表示集合中每一个元素进行迭代时的别名.
# index指 定一个名字,用于表示在迭代过程中,每次迭代到的位置.
# collection 为传进来的collection参数的 *类型*
# open表示该语句以什么开始
# separator表示在每次进行迭代之间以什么符号作为分隔符
# close表示以什么结束
常用sql
<!-- 查询条件 -->
<if test="monthQuery != null and monthQuery != ''">
AND date_format(oi.finish_time,'%Y-%m') = #{monthQuery}
</if>
<!-- 集合查询条件 -->
<i 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 577
577











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









